Summary
기존에는 imagenet과 같은 supervised image dataset을 사용해서 model을 학습하였다. 이러한 방법은 다양한 vision task에서 좋은 성능을 보였지만, 인간이 수동으로 annotation을 만들어줘야 한다는 점에서 scalability가 떨어지곤 했다.
이후에 대량의 unlabeled된 images를 활용해, unsupervised pre-training을 하는 방법이 등장했고 supervised learning을 한 모델과 비슷하거나 뛰어넘기도 하였다. 본 논문은 좋은 visual representation을 얻기 위해 새로운 방법론을 제시한다. 높은 퀄리티의 더 적은 images를 전통적인 classification pretraining에 사용한다는 것이다.
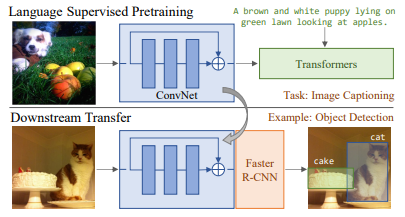
이른바 VirTex라고 불리는 본 논문이 제시한 접근은,
- ConvNet + Transformer로 image에 대한 natural language caption을 생성한다.
- 이로 부터 얻은 visual representation을 down-stream task에 적용한다.
핵심은 caption이 가지는 language supervision을 사용하는 것이 semantic density를 가지기 때문에 효과적이라는 것. caption이 semantically denser learning signal을 제공해서 contrastive learning이나 기존의 classification pre-training에 비해 더 효과적이라고 주장한다.
이와 같은 이유로, textual features를 사용하는 것이, images feature를 학습하는데 도움을 주기 때문에 더 적은 images를 사용하여 효과적으로 학습할 수 있다고 주장한다. 또한 text data는 image label에 비해 더 적은 비용으로 구할 수 있다.
.png)
두 가지 기여
- natural language가 visual representation을 학습하는데 다른 방법에 비해 data-efficiency하게 도움을 준다는 사실을 밝혔다.
- 이러한 방법으로 다양한 visual down-stream task에서 좋은 성능을 보였다.
Method
image-caption pairs가 주어지면, image에 대한 caption을 생성하도록, ConvNet과 transformer가 학습된다. 이때 학습을 마치고 나서, text head부분은 버리고 visual backbone만 사용한다.
BERT에서 사용되는 MLM의 경우, language modeling에 비해 더 느리게 수렴하는 것을 실험을 통해 확인하였고, 낮은 효율성을 이유로 선택하지 않았다.
visual backbone의 경우 resnet-50을 사용하였고, text head로 features를 넘기기 전에, projection layer를 통과하고, down stream task를 수행할 때는 제거한다.
textual head는 transformer를 사용해서 visual backbone에서 features를 받고, caption을 생성한다. 이때 특이한 점은 bidirection으로 caption을 생성하는 것.
.png)
Conclusion
본 논문은 visual representation을 학습하기 위해, textual representation을 함께 사용하는 것이 기존의 supervised, unsupervised pretraining model과 competitive한 성능을 보일 수 있다는 것을 증명했다. 이후에, visual backbone과 textual head 둘다 transfer하는 다른 task에도 적용할 수 있을 것이고, web scale의 image-text pair로 scaling할 수 있을 것이다.
Comments
기존의 pretraining 방식과 다르게 textual feature를 이용해 visual feature를 잘 뽑아내도록 model을 학습 시킨 점이 흥미로웠다. image captioning보다 더 복잡한 VQA 같은 task를 학습 시키면 visual backbone 성능이 올라갈 지 궁금하다.
