Abstract
기존의 sequence transduction model은 attention mechanism을 사용하여 복잡한 CNN, RNN 모듈이 들어간 Encoder+Decoder 구조로 이루어져 있다.
본 논문에서는 이러한 복잡한 모듈들을 전혀 사용하지 않고 오로지 attention 기반으로 동작하는 Transformer를 제안한다.
더 짧은 학습 시간으로 더 좋은 성과를 보였다. (이 논문에서는 기계 번역)
Introduction
RNN, LSTM, GRU는 LM, Machine Translation task와 같은 sequence modeling에서 SOTA를 차지 했다. 이러한 구조는, t-1시점의 hidden state가 현재 t시점의 input으로 들어가는 recurrent한 구조를 가지게 된다. 이는 병렬화 연산을 막게되는데 이것은, 긴 시퀀스의 경우 메모리가 한계를 가지기 때문에 중요하게 작용한다. (그래서 느림)
Attention mechanism은 seq를 다루는 task에서 특히나 유용한데, input, output 속의 단어, token끼리의 거리와 상관없이 그 사이의 의존성을 다룰 수 있게 하기 때문이다. 그런데 이러한 attention mechanism이 여전히 recurrent model에서 사용된다는 점은 한계로 남게 되었다.
그래서 본 논문은, recurrence를 제거하고 오로지 attention mechanism을 기반으로 하여 input과 output 사이의 global한 dependencies를 얻고자 하는 Transformer를 제안한다. Transformer는 병렬화를 가능하게 하여, translation task에서 SOTA를 차지하게 된다.
Model Architecture
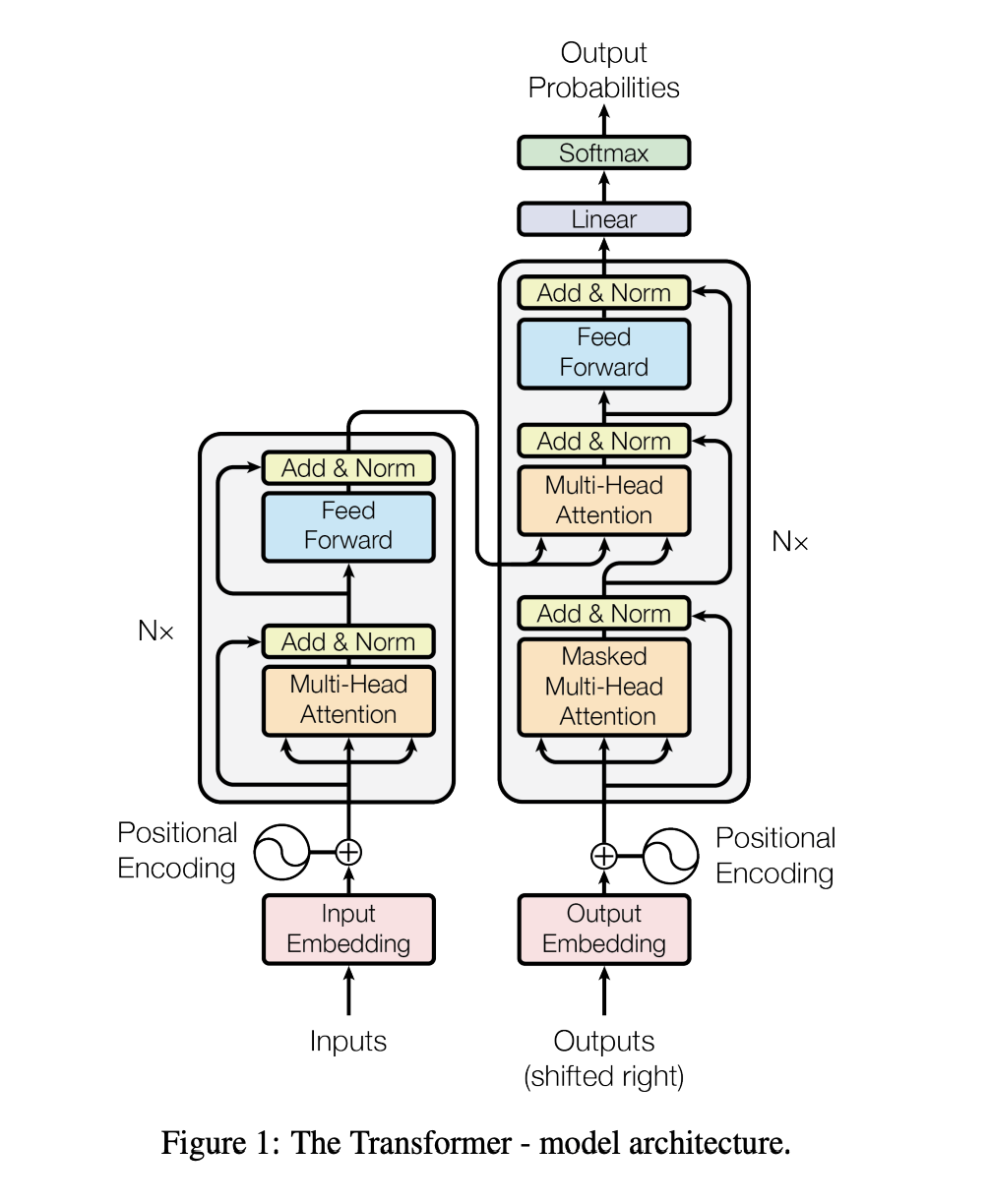
Attention
attention function은 query와 key-value pair를 mapping하여 output으로 내보내는 것으로 표현될 수 있다. q, k, v는 모두 벡터 형태. output은 weighted sum of the values. values에 매핑되는 weights들은 query와 key가 얼마나 비슷한 지로 결정된다.
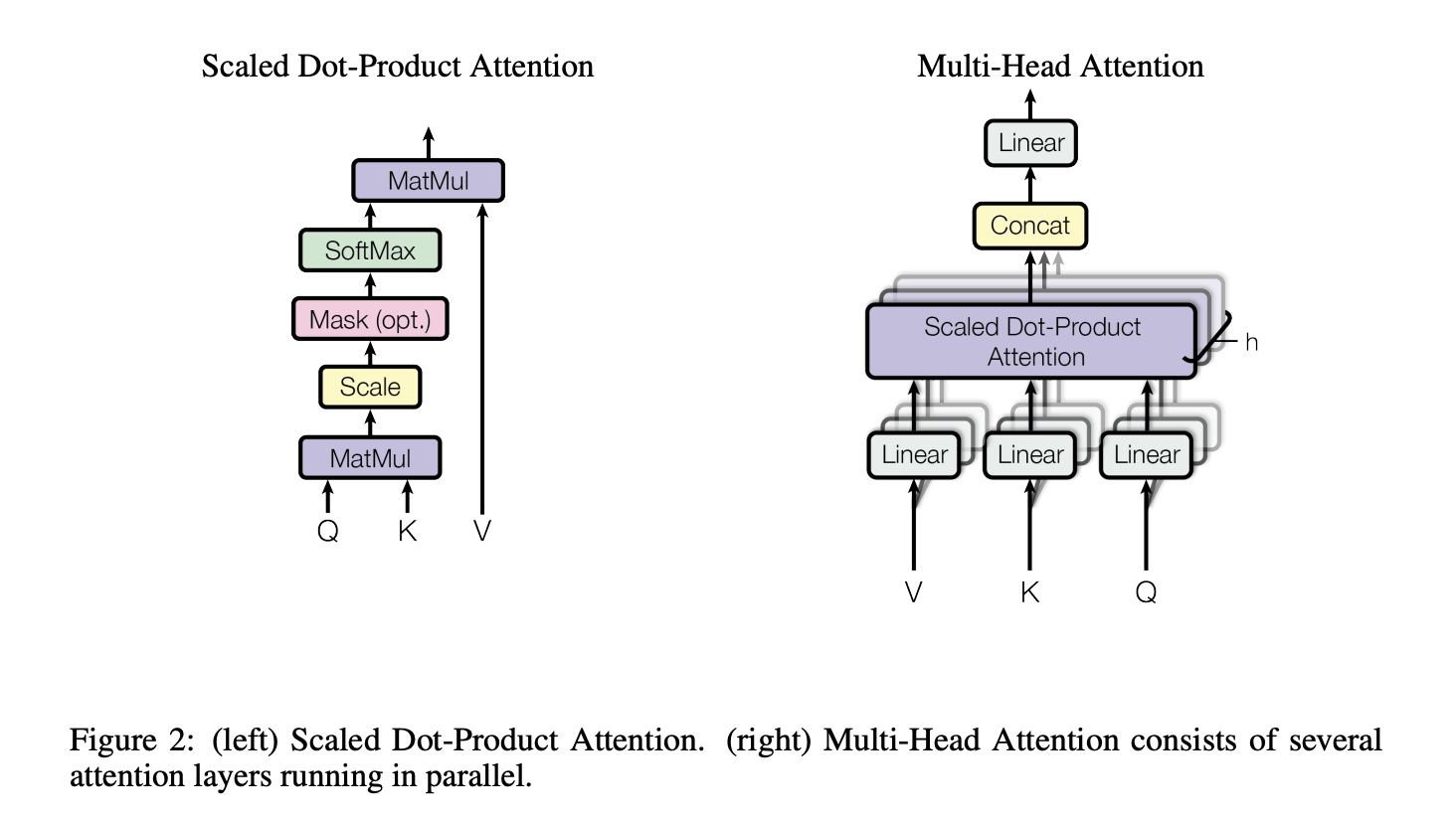
Scaled Dot-Product Attention
q, k를 dot-products하고, 이를 로 나눠주면서 scaling 해준다. 그 후 softmax를 취하고, v와 dot-product를 하면서 values에 대한 weights를 얻는다.
일반적으로 q, k, v 각각은 matrix 형태로 나타낸다
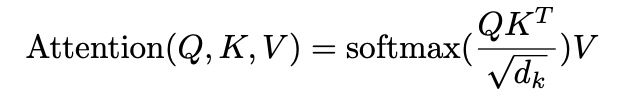
Multi-Head Attention
q, k, v가 h개로 나눠서 Scaled Dot-Product Attention을 병렬적으로 계산해서 dimensional output values를 가지도록 한다. 이것은 다시 concat 된 후 project된다.

Multi-head attention은 model로 하여금 다른 포지션의 다른 representations subspaces의 information에 대해 한꺼번에 attend 하도록 한다. 본 논문에서는 h=8, 로 맞추었다. 각각의 head의 줄어든 dimension때문에, 전체 computational cost는 full-dimension을 가진 single-head attention과 비슷하다
Applications of Attention in our Model
transformer에서는 3가지 방식으로 multi-head attention을 사용한다
- encoder-decoder attention layer에서는 decoder내의 이전의 layer에서 query가 들어오고 encoder의 output으로부터 key, value가 오게된다. 이것은 decoder에 있는 모든 포지션이 input sequence에 있는 모든 포지션에 attend할 수 있도록 한다.
- encoder는 self-attention layers를 가지고 있다. encoder의 self-attention layer 이전의 output이 key, query, value로 들어오게 된다. encoder의 각각의 포지션은 encoder의 이전 layer에서의 모든 포지션을 attend 하도록 한다
- 비슷하게, decoder의 self-attention layer는 decoder의 position에 attend하도록 돕는데, 이 때, auto-regressive property를 보존하기 위해, decoder에서는 leftward information flow를 유지한다. 이것을 구현하기 위해, scaled dot-product attention을 illegal connections에 대응하는 softmax의 input에서의 모든 values를 masking out 했다 (-inf로 설정).
- 이 부분이 잘 이해가 안갔는데, 내가 이해한 바로는, self-attention은 원래 모든 token 끼리의 attention을 구하는 것인데, decoder에서의 self-attention에서는 leftward information flow를 유지해야 하기 때문에, rightward information flow는 없애야 할 필요가 있는 것이다. 그래서 그러한 rightward information flow같은 illegal connections를 -inf로 설정해서 softmax 함수를 통과시킬 때, 선택되지 않도록 하는 것이다.
Position-wise Feed-Forward Networks
attention layer들을 지나고 fully-connected feed-forward network를 지나게 되는데, 이것은 각각의 position들에 separately, identically하게 적용된다. 이것은 ReLU를 포함한 두개의 linear transformations로 구성되어 있다.
linear transformations는 다른 positions를 넘어 똑같이 적용이 되는데, 레이어 마다 다른 파라미터를 사용한다.
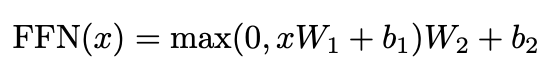
input, output dimension = 512, inner-layer dimension = 2048
Embeddings and Softmax
다른 sequence transduction models와 비슷하게, 학습된 embeddings를 사용한다. transformer는 embedding layer간에 같은 weight matrix를 공유한다
Position Encoding
transformer는 CNN, RNN을 사용하지 않기 때문에, token의 위치정보를 따로 넣어줘야 한다. 이를 구현하기 위해, encoder, decoder stack의 bottom에 input embeddings으로 position encodings를 추가한다.
다른 주파수를 가지는 sine, cosine functions을 사용한다
Why Self-Attention
그렇다면 왜 CNN, RNN보다 self-attention을 사용하는 것이 좋을까?
- layer당 total computational complexity가 감소하기 때문에
- 병렬적으로 computation이 수행되므로, 최소한의 계산이 필요하다
- long-range dependencies 사이의 path length
- 이 부분도 잘 이해가 가지 않았는데, 내가 나름대로 이해한 부분은, long-range dependencies를 학습하는 것은 seq모델에서 중요한 부분인데, path length를 짧게 만들면 만들수록, long-range dependencies를 학습하기 쉬워진다. 그래서 이 논문에서는 maximum path length를 비교하게 되었다
self-attention은 recurrent 모델과 다르게 constant time안에 모든 position을 연결할 수 있다. 왜냐하면 multi-head attention이 병렬적으로 계산되기 때문에
이러한 관점에서 computation cost가 감소할 수 있는 것이고, CNN, RNN에 비해 더 빠르다는 것. path-length도 감소
side benefit으로 self-attention은 좀 더 설명 가능한 모델인데, transformer의 attention distributions를 보게되면, task를 수행할 때, 어떤 token의 attention score가 높은지를 비교하고, 영향력을 조사할 수 있게된다.
Conclusion
sequence transduction task에 대해 recurrent layer를 제거하고 오로지 attention만을 사용한encoder-decoder model, transformer를 소개했다. translation tasks에서 transformer는 기존 방식보다 빠르게 학습하고 더 좋은 성능을 보였다.
