Summary
기존의 VLP model들은 대부분 visual feature extraction을 하기 위해, CNN architecture나 region supervision (object detector)를 사용했다. 본 논문에서는 image를 patch 단위로 자르고, ViT를 사용하여 visual feature를 extraction했다. 그 결과, 속도나 효율적인 부분에서 좋은 성능을 보였다. (10배 이상 빠름)
Region, Grid feature (X) → Patch Projection (O)
BERT 대신 ViT로 transformer를 initializing 했다.
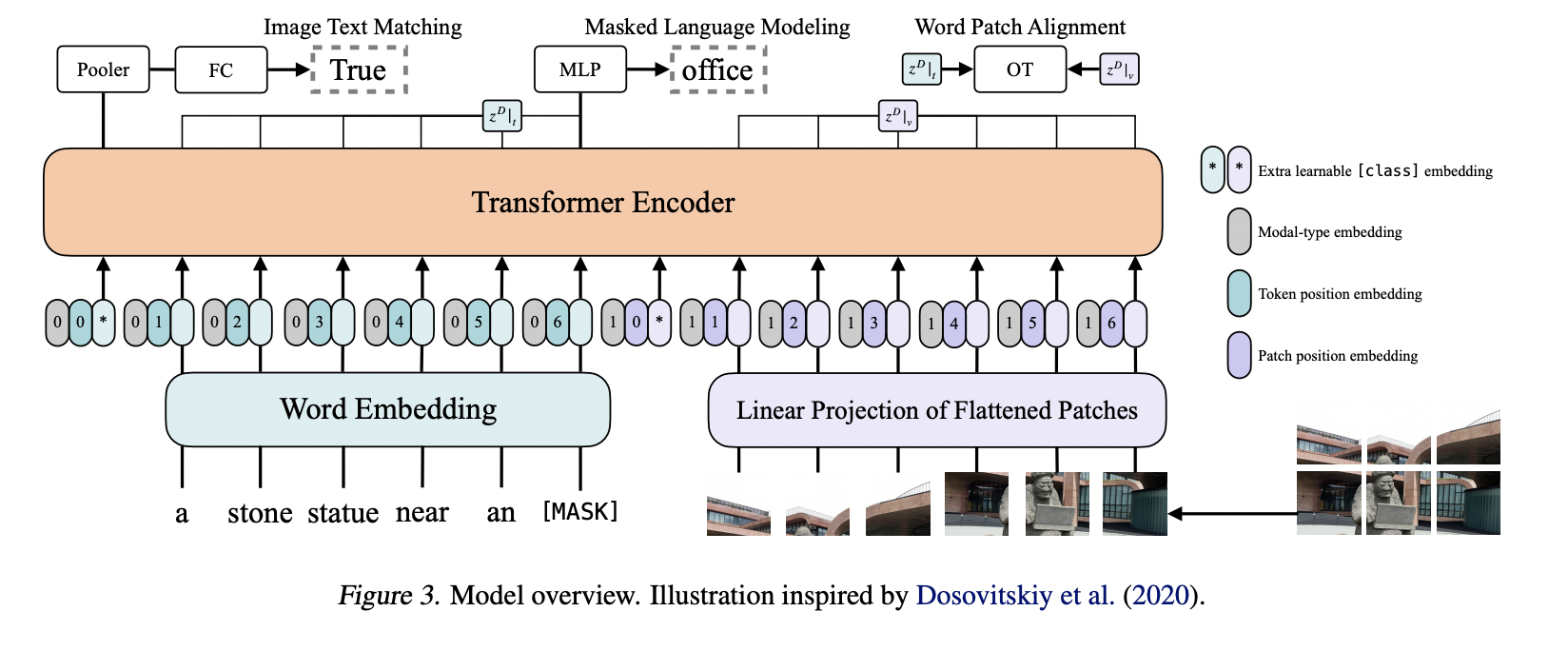
Pretraining 방법으로 ITM, MLM을 사용했고, 추가적으로 Word region alignment objective에 영감을 받아 Word Patch Alignment (WPA)를 만들었다. 이게 뭐냐면, IPOT을 사용해서 text data와 visual data 사이의 alignment score를 계산하는 거라고 하는데, IPOT이 뭔지 잘 몰라서 찾아봐야 할 것 같다.
추가적으로 Whole Word Masking을 사용했다. Chinese BERT에서 사용한 방법인데, subword token에 masking을 씌우는 기법. 예를 들어 “giraffe”라는 단어를, [”gi”, “##raf”, “##fe”]로 쪼갤 수 있는데, ##raf를 [mask]로 대체하고 그걸 예측하는 학습 방법
Ablation study 결과, word masking과 RandAugment는 효과가 있었지만, Maked Patch Prediction (MPP)는 그닥 효과가 없었다.
Strength
ViLT는 정말 간단한 아키텍쳐로 이뤄져 있다. tranformer module을 image feature를 extraction하는데 사용하였고, runtime/parameters efficiency를 달성할 수 있었다
region/convolution 없이 VL task를 수행한 첫번째 모델이다
Also, for the first time, we empirically show that whole word masking and image augmentations that were unprecedented in VLP training schemes further drive downstream performance.
Weakness
학습을 64개의 NVIDIA V100 GPU로 200번 진행했는데, 학습에 드는 cost가 너무 크다. 그냥 image extractor만 ViT로 바꾼 느낌
Question
- Epoch를 상당히 많이 돌려서 학습을 진행했는데, 그 보다 적게 학습한 모델과 같은 선상에서 성능을 비교할 수 있는지?
Comments
왜 안나오나 했던 ViT를 visual feature extractor로 사용한 VLP model. CNN, OD model을 사용한 것에 비해 훨씬 빠르고 효율적으로 동작하며, 성능도 얼추 비슷하게 잘 나온다. 다만, 이렇게 많은 연산자원을 사용하면서 오래 학습을 진행한 모델이 과연, 다른 모델과 같은 선상에서 비교할 수 있는지에 대해서는 조금 의문이 드는 것이 사실이다. 내가 느끼기에는 단지 ViT로 바꿨는데 잘 됐다 정도로 여겨지는데, 잘 모르겠다. 하지만, 꾸준히 내가 관심을 가지고 지켜보던, ‘VLP model에서의 효율성'을 잘 설명해준 논문이었다. 새삼 Transformer가 대단하다고 느껴지는 또 한번의 순간.
