Summary
visual-language pretraining은 대부분 image-text alignment를 contrastive loss를 통해 진행되었다. alignment하면서 생기는 이득은 image와 그에 매칭되는 text들간의 상호간의 정보 (Mutual Information, MI)를 극대화 하는 것으로부터 얻어진다.
그러나 단순하게 image-text pair를 alignment하는 것 (cross-modal alignment, CMA)은 각각의 modality 내부의 data potential을 무시하게 된다. (즉 서로 다른 modality를 가진 데이터들간의 상호 유사도에 관한 정보만을 학습하느라, 각각의 modality 내부의 데이터 끼리의 관계는 잘 학습하지 못했다는 말) 이러한 문제는 dataset이 noisy할 수록 더 큰 문제가 된다.
따라서 본 논문에서는 이와 같은 문제를 해결하기 위해, Triple Contrastive Learning, TCL을 소개한다. TCL은 intra-modal contrastive를 소개하는데, 이는 image-text pair의 local region, global summay사이의 평균 MI를 극대화하도록 도와준다. 이러한 방법으로 VQA, image-text retreival을 포함한 다양한 V-L downstream task에서 SOTA를 차지하였다.
self-supervised learning은 visual-language model이 학습하는데 효과적인 것으로서, 활발한 연구가 이뤄지는 분야이다. 주로 self-supervised learning은 많은 양의 unlabeled된 data으로 학습하고 zero/few shot, transfer learning하여 down-stream task에 fine-tuning 하는 것이 일반적인 학습 방향이다.
vision 분야에서는 jigsaw puzzle을 푼다거나, 두개의 무작위 이미지 패치 사이의 상대적 위치를 맞추는 것으로 SSL을 진행하고, language 쪽에서는 BERT에서 사용하는 것으로 유명한 MLM으로 SSL을 진행한다.
이러한 두 분야에서의 SSL이 좋은 성능을 내는 것에 영감을 받아 VLP에도 SSL을 적용하기 시작했는데, multi-modal task는 필연적으로 여러 modality를 가지는 데이터 사이의 상호작용을 잘 학습하는 것이 필수적이다. 이러한 목적을 달성하기 위해, 최근 몇 년간 image-text사이의 정보를 잘 학습하도록 고안된 fusion encoder를 많은 양의 image-text로 모델을 학습하곤 했다.
이러한 간단하고 효과적인 방법에도 불구하고, vision, language feature가 서로 다른 embedding space에 위치하여 서로의 상호 관계가 잘 학습되지 않는 문제가 발생하곤 했다. 이러한 문제를 해결하기 위해 더 최근의 SOTA 모델은 contrastive loss를 사용해 cross-modal feature를 align하여 서로 비슷한 image-text pair는 가깝게, 반대는 멀게 보내면서 미리 데이터들간의 관계를 학습한 뒤, fusion encoder에 집어넣는 방식으로 joint embedding을 잘 학습할 수 있게 되었다.
CMA는 multi-modal representation learning에서 풍부한 정보를 학습하기 힘들다. 그 이유는 image와 text가 서로를 잘 설명하기 힘들기 때문이다. CMA는 오직 image-text에 둘다 존재하는 co-occurence한 정보만을 catch하기 때문이다.
최근에 transformer 아키텍쳐의 유행으로 VLP에도 transformer를 사용하는데, 이 경우 transformer는 global한 feature를 잘뽑아내곤 한다. 그러나 이는 역설적으로 local, structural한 정보를 고려하는데 실패하곤 한다.
이와 같은 이유로 본 논문은 TCL을 제안한다. TCL은 intra modal, cross modal 사이의 차이를 완화하면서 fusion encoder가 multi-modal interation을 더 쉽게 학습되도록 돕는다. 이와 같은 목표를 달성하기 위해, TCL은 세가지 contrastive module을 제안한다. CMA, intra-modal contrastive (IMC), local MI maximization (LMI) 이는 모두 MI maximization에 의존한다.
CMA는 global MI를 향상시키고 IMC는 local MI를, LMI는 global representation, local region사이의 높은 MI를 얻도록 한다. 따라서 cross-modal뿐만 아니라 intra-modal의 의미있는 정보를 학습하고, structural, local한 information을 학습한다.
Method
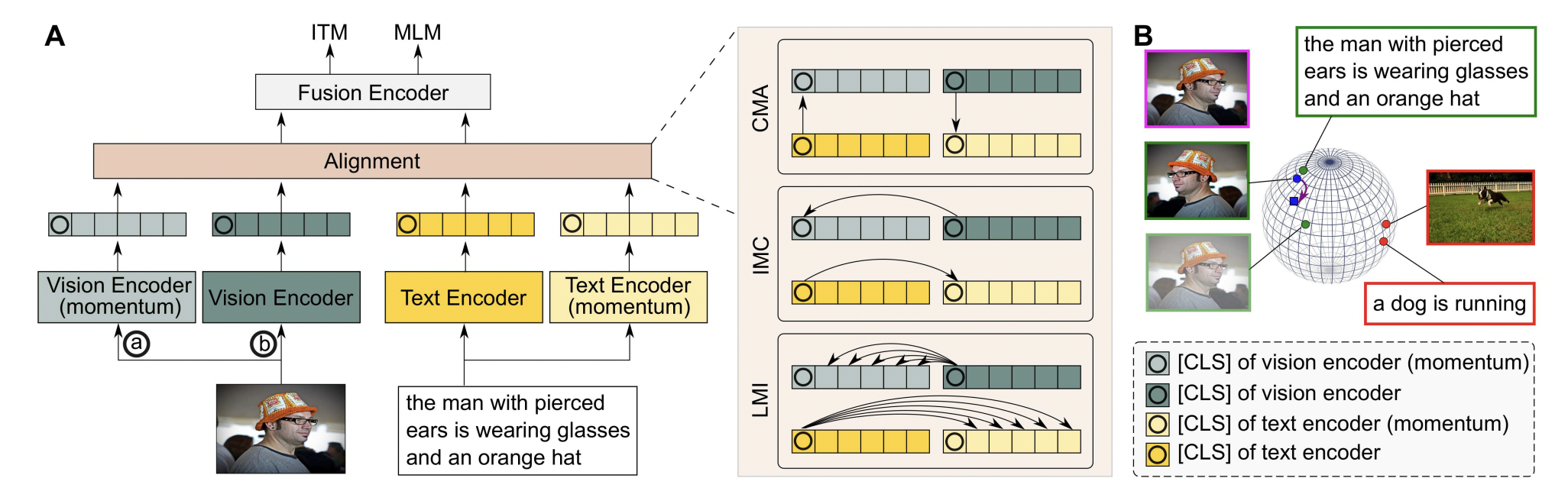
각각의 data의 feature를 extract할 encoder가 모델에 존재하고, 그와 더불어 momentum을 사용한 encoder도 모델에 있는 것을 확인할 수 있다. fusion encoder에 align된 데이터를 입력하기 전에 alignment layer가 존재하여 TCL을 진행한다.
위에서도 계속 언급한 바와 같이, 이전의 VLP model은 각각의 modality specific encoder를 통과한 feature들은 그대로 concat되어 fusion encoder로 들어갔지만 이 경우, visual-linguistic data가 서로 다른 embedding space에 놓이기 때문에 fusion encoder가 이 둘 사이의 관계를 학습하기 어렵게 된다. 따라서 TCL은 데이터가 그대로 fusion encoder에 들어가기 전에 세가지 loss를 통해서 학습한 뒤 들어가게 된다.
CMA
CMA의 목표는 matched된 image-text pair의 embedding을 잘 유도해 내는 것이다. (즉 서로 같은 semantic information을 가지고 있는 image-text pair를 더 가깝게 만드는 것, mutual information을 maximize하는 것)
IMC
IMC는 CMA와 다르게 같은 modality안에서 positive, negative samples의 semantic difference를 학습하려고 시도한다. vision의 경우 하나의 image를 random augmentation을 진행하여 두 개의 이미지를 만들어내고, 그 이미지를 서로 다른 view로 바라보게 된다. 그래서 original image I와 I1, I2의 contrastive loss를 사용해서 I1, I2사이의 agreement를 극대화한다.
text의 경우에는, dropout을 통해서 일종의 data augmentation을 진행하게 된다. text도 image와 마찬가지로 negative, positive sample과의 contrastive loss를 구하여 학습한다.
CMA와 IMC는 상호 보완적 관계로, CMA는 다른 modality를 가진 데이터 간의 관계를, IMC는 같은 modality를 가진 데이터 사이의 관계를 잘 학습하게된다. 둘을 함께 사용하면 학습된 representation을 향상시키고 fusion encoder에서 multi-modal learning을 더 쉽게 하게 도와준다.
IMC도 하나의 단점을 가지고 있는데, data의 CLS token을 가지고 loss를 계산한다는 것이다. CLS token은 global한 feature를 가지고 있기 때문에, local, structural한 information은 잘 학습하지 못한다는 것이고, 확실히 관련없는 정보를 높게 평가하여 모델로 하여금 잘못된 판단을 하게 유도할 수 있다. (local한 정보를 제대로 파악하지 못해서 중요한 부분을 놓칠 수 있다는 이야기) 이를 해결하기 위해 LMI를 추가로 도입함
LMI
위에서 언급한 것과 같이 LMI는 local region과 global representation 사이의 높은 MI를 가지도록 한다. LMI는 하나의 augmented data의 CLS token과 또 다른 augmented data의 image patches를 비교한다. (cls token은 global representation을 가리키고, image patches는 local region을 가리키는데 이것을 pair로 묶는다는 것). 이 같은 과정을 통해, global representation으로 local을 예측할 수 있도록 하고, 모델이 local region에만 집중되지 않도록 돕는다.
ITM & MLM
세 가지 학습으로 data를 fusion encoder에 넣을 준비가 되면, fusion encoder는 ITM과 MLM으로 학습하게 된다. ITM의 경우, image-text가 주어졌을 때 둘이 match되는지 아닌지를 binary classification으로 학습하는 것이다.
MLM의 경우 BERT에서 사용되는 것으로 유명한데, text token의 일부를 mask token으로 바꾸고 이를 예측하는 것으로 학습하는 것이다. 보통 전체 text의 15%에 적용하는데 적용하는 80%를 마스크로 교체하고, 10%는 그대로 놔두고 나머지는 아예 다른 단어로 바꾸곤한다. 모델의 최종 loss는 다음과 같다.
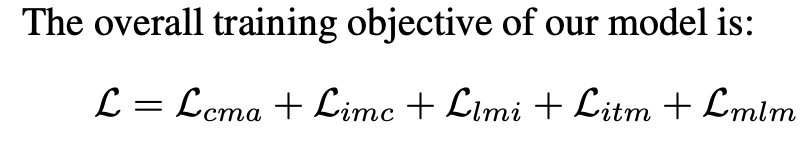
Conclusion & Comments
cross-modal에 intra-modal의 관계를 학습할 수 있는 Loss를 추가하여, 많은 vision-language task에서 SOTA를 차지한 TCL을 소개한다. 이전의 모델들이 단순히 cross-modal data를 align하여 fusion encoder에 넣었다면, TCL은 같은 modality 내의 데이터들 사이의 관계도 잘 학습할 수 있도록 하였고 이것이 의미있는 것임을 보여주었다. 또한 localized, structural information을 포함하면서 TCL이 global representation, local region 사이의 mutual information을 극대화 하는 것을 소개했다.
개인적으로 뭔가 같은 말을 정말 너무 많이 반복하는 느낌. 물론 loss 두개 추가한 것 만으로 성능이 잘 나왔다는 것은 놀라운 사실. 솔직히 말하자면 뭔가 개념이 붕 뜬 느낌이다. 결국 local region, global representation사이의 상호작용을 학습하는 것, 같은 modality내의 data사이의 상호작용을 학습하는 것이 중요하다 라는 것인데, 이해는 되는데 공감이 안되는 느낌. 아무튼 대단한 것 같다.
