Summary
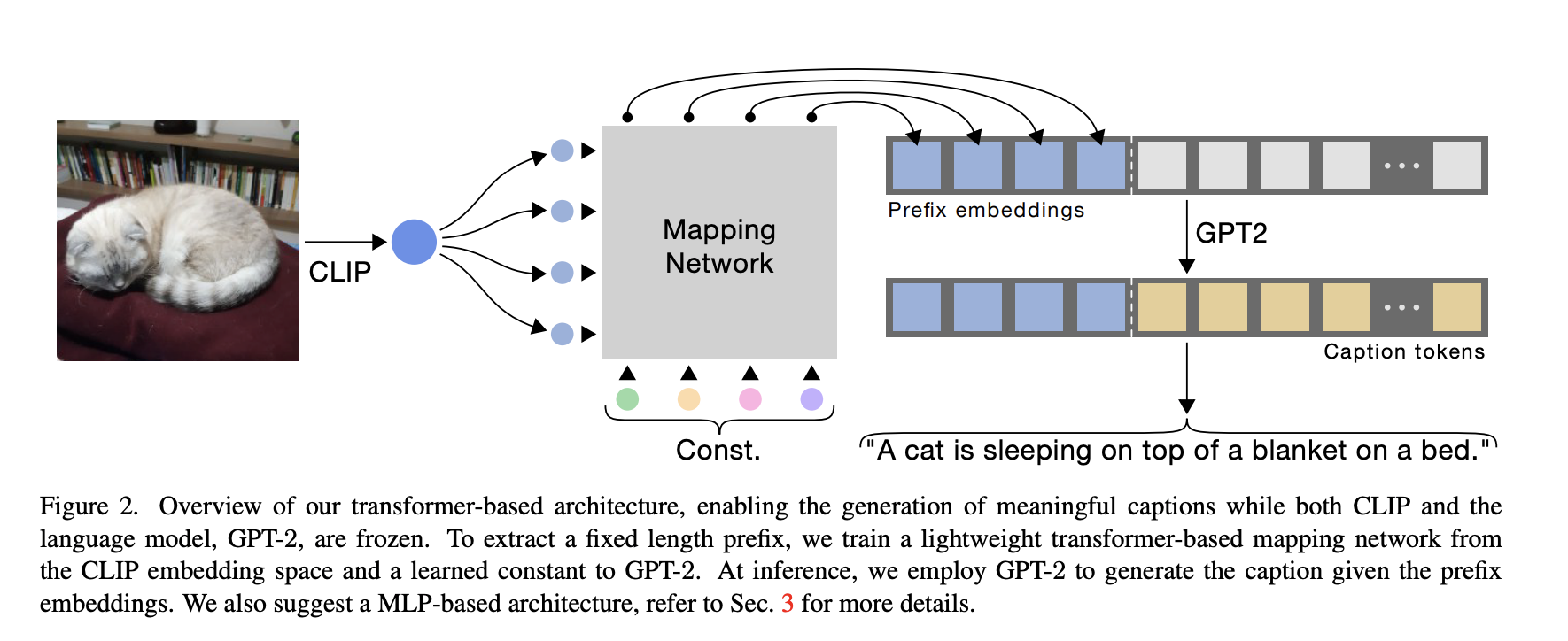
vision-language model인 clip과 Language model인 GPT-2를 활용하여 적은 cost, 빠른 training으로 image captioning task에서 SOTA model과 비슷한 성능을 내었다. 다음과 같은 과정을 거친다.
- 우선 CLIP의 visual encoder로 image input을 받고, visual information을 추출한다.
- light mapping network를 통과시켜 embedding vector를 뽑아낸다.
- 2에서 만들어진 embedding vector가 일종의 prefix로 작용하여 caption의 앞쪽에 붙여진다.
- GPT-2를 통과하여 caption을 생성하고, cross entropy loss를 구한다.
- back-propagation으로 mapping network를 optimzing 한다.
내가 생각하는 이 논문이 나오게 된 배경은, fine-tuning의 어려움이다. 최근에 나오는 모델들은 대부분 사이즈가 큰데, 이 경우에는 pre-training된 model을 fine-tuning하는 것 조차도 쉽지 않다. 전체 모델의 파라미터를 어쨋든 거쳐야 하기 때문에.
따라서 in-context learning이나, few-shot, zero-show learning등 처음 학습을 할 때부터 down-stream task를 수행할 수 있도록 학습되는 경우가 많다. 특히 vision-language model은 모델 사이즈가 정말 큰데, visual-language data간의 데이터의 분포나 특성이 다르기 때문에 둘 사이의 차이를 좁히기 위해 많은 학습 시간, 데이터가 필요로 하기 때문에 그에 맞게 성능을 올리기 위해서는 모델의 사이즈도 커질 수밖에 없었다.
ClipCap은, 미리 학습된 모델 두 개(CLIP visual encoder, GPT-2)의 파라미터는 고정시켜 놓고, 그 둘 사이를 이어주는 아키텍쳐만 학습하도록 하여 효율성을 높였다.
여러 가지 ablation study를 진행했다.
LM fine-tuning
- 복잡한 dataset인 conceptual captions dataset의 경우, fine-tuning이 성능이 더 잘 나왔지만, nocaps의 경우는 비슷했다. 비슷하면 사실 fine-tuning 안 한게 더 좋다고 말할 수 있다 (효율성 측면)
Prefix Interpretability
- 내가 가장 흥미로웠던 부분 중 하나인데, prefix를 실제로 어떻게 나타나는지, 보여주었다.

- GPT-2를 fine-tuning 했을 때, prefix가 좀 더 해석 가능한 형태임을 확인할 수 있다.
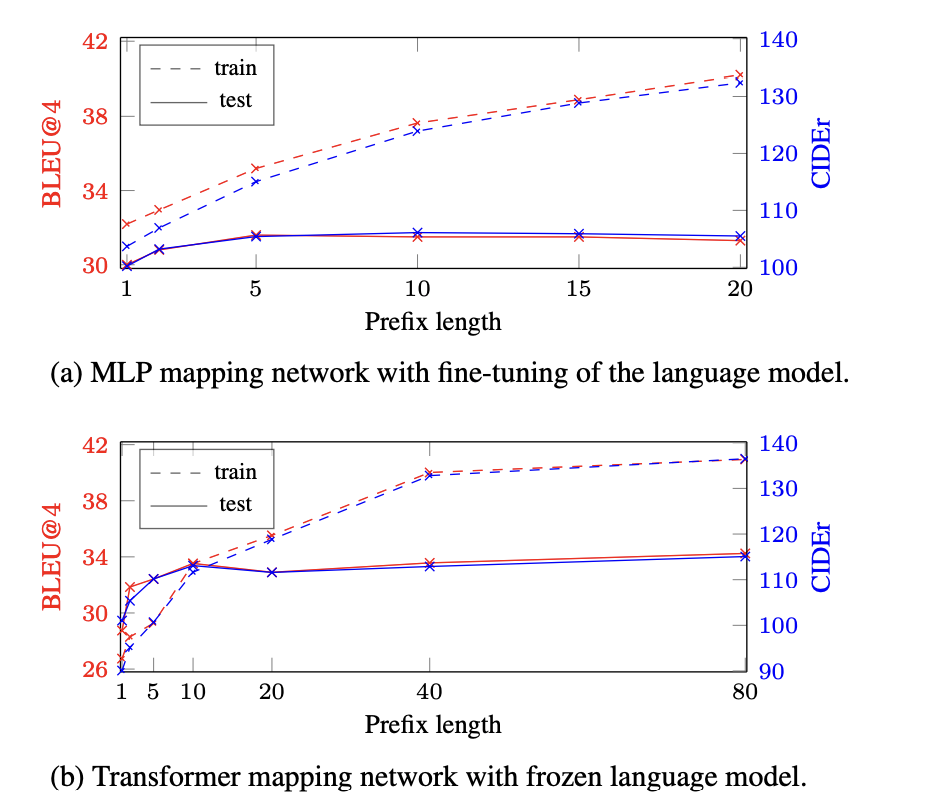
Prefix length
- 어쨋든 prefix가 길어지면 성능은 향상된다.
- language model을 freeze하고, transformer를 mapping architecture로 사용하는 경우가 길 수록 좀 더 효과가 좋았다.
Question
- 왜 prefix가 길어지면 성능이 좋아지는것일까?
- CLIP말고 ViT를 쓰면 어떻게 될까?
Comments
prompt based learning이 떠오른다. 고성능 GPU가 고픈 학부생에게 효율적인 모델은 가뭄에 단비와도 같다. 요즘 모델들의 사이즈를 감안하면 도저히 학부생에게 주어진 single GPU로는 감당히 안되는 크기이다.. 그런 상황에서 fine-tuning없이 prefix를 학습하는 것만으로 성능이 어느 정도 나오는 ClipCap은 참 반가운 모델이다. 다시금 CLIP이 image-text pair의 관계를 잘 학습하고 있다는 것을 느꼈고, GPT-2로 caption을 generation하는 것도 신기했다.
