Summary
NLP에서 성능 향상에 도움이 되는 prompt learning을 다양한 vision-language task를 수행하는 CLIP-like model에 도입하였다. CoOp은 pre-trained 된 parameter는 고정시킨 채로, prompt의 context words를 학습 가능한 vector로 모델링한다.
image recognition task에서 학습을 편하게 하기 위해, image를 discrete한 label로 분류하였다. 이러한 경우, label 집합 안에 존재하는 image만 분류할 수 있기 때문에, 일반적인 성능으로 확장되기 힘들다.
새로운 image recognition paradigm으로, CLIP이나 ALIGN이 제안되었는데, image-raw text를 align하고, 각각의 modality에 맞는 encoder를 사용하고 contrastive loss로 학습을 진행한다.]
이러한 모델들은 다양하고 방대한 dataset으로 pre-trained되어, 충분한 visual concept을 가질 수 있게되었고, prompt learning을 통해, down-stream에 좋은 성능을 올릴 수 있었다.
하지만, prompt learning의 경우, prompt에 따라 성능이 크게 차이가 나는 것을 확인할 수 있었다. 이를 위해 prompt engineering이 등장하게 되었고 이는 manual 하므로 많은 cost가 발생한다.
본 논문은 pretrained된 vision-language model에 자동으로 prompt engineering을 도와주는 Context optimization (CoOp)을 제안한다.
CoOp은 random or pre-trained word embedding으로 learnable vector를 초기화 하고, class와 함께 text encoder에 넣는다. 이때 다른 parameter들은 고정된 채로 learnable vector만 바뀌도록 학습이 진행된다.
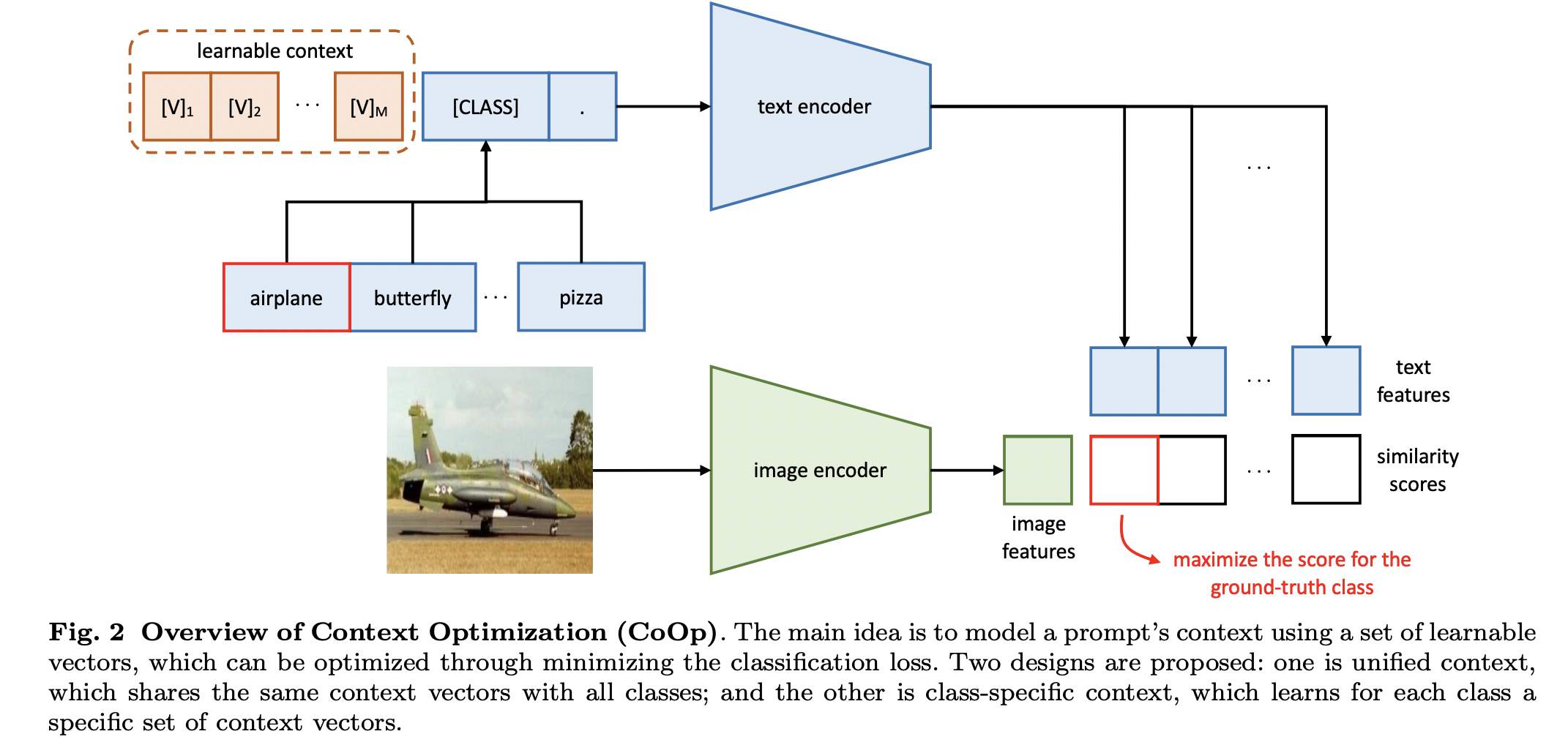
두 가지로 context learning을 진행했다.
- Unified Context 클래스에 상관없이 모든 클래스가 learnable vector를 공유한다. 클래스가 vector 맨 뒤에 concat될 수도 있고, 가운데 위치할 수도 있다. 가운데 위치한 경우, 좀 더 학습에 있어 유연함을 가지게 된다.
- Class-Specific Context 클래스마다 vector들을 다르게 하여 학습하는 방식
Strength
- vision-language model에 input으로 들어가는 prompt를 optimization하는 방법을 제안하여, few-shot 성능을 올렸다.
Weakness
- interpretability가 작다는 것. 이건 continuous prompt 계열을 사용하는 것의 단점이기도 한데, discrete와는 달리 embedding vector를 연결하는 거라, 단순히 nearest neighbor를 사용하면 인간이 해석하기 힘든 단어들이 등장한다.
Comments
- Discrete prompt로 학습했을 때도 궁금하다.
- prompt자체를 학습해서 가장 최적의 prompt를 생성하고 이것이 실제로 성능 향상에 도움이 되었다는 것이 참 놀랍고 신기하다. 더 짧은 prompt가 robustness가 높아서 더 좋은 성능을 보였다는 사실도 신기하다. 무엇보다, fine-tuning이 아닌, few-shot learning으로 학습한다는 사실이, 고성능 gpu를 가지고 있지 않은 학부생으로서 반가운 논문.
