Summary
생성 모델의 새로운 시대를 연 GAN은 discriminative model D와 generative model G로 이뤄져 있다. 그런데 image와 같은 continuous data는 잘 생성해내는 반면에, discrete한 tokens의 sequence를 생성하는 것에는 한계를 가지고 있었다. 왜냐하면 discrete output의 경우, D에서 G로 gradient가 전달되기 어려웠기 때문이다.
본 논문에서는, RL에서 사용되는 stochastic policy로 직접 gradient policy update를 진행하여 위 문제를 해결한 SeqGAN을 제안한다.
GAN, which opened a new era of generative models, consists of a discovery model D and a generative model G. However, while continuous data such as image were well generated, there was a limit to generating a sequence of discrete tokens. This is because in the case of discovery output, it was difficult to transfer gradient from D to G.
This paper proposes SeqGAN, which solves the above problem by directly proceeding with gradient policy update with stochastic policy used in RL.
Strength
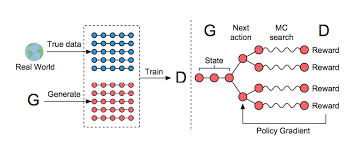
- generative model을 reinforcement learning의 agent로 여기고 gradient policy update을 진행하여, discrete output에 대한 gradient update를 쉽게 할 수 있었다.
- oracle evaluation mechanism을 사용하여 SeqGAN의 성능을 explicitly하게 보여줄 수 있었다.
- Considering the generative model as the agent of reinforcement learning, the gradient policy update was carried out, making it easy to update the gradient for the discovery output.
- The performance of SeqGAN could be shown externally using the oracle evaluation mechanism.
Weekness
- Reinforcement Learning은 action에 맞는 적절한 reward가 주어져야 하는데, 이것은 쉽지 않다.
- GAN’s Instability
- Reinforcement learning should be given an appropriate reward for the action, which is not easy.
Questions
- ‘Monte Carlo (MC) search’에 대해 간략하게 설명해주실 수 있나요?
- Table 2에서 MLE라고 되어있는 부분은 기존에 text data generation에 사용되는 LSTM, RNN같은 모델들을 가리키는 건가요?
- Can you briefly explain ‘Monte Carlo (MC) search’?
- Does the MLE part in Table 2 refer to models such as LSTM and RNN used for text data generation?
Comments
- 왜 GAN이 text와 같이 discrete한 output을 가지는 data에는 잘 동작하지 않는 지에 대해 어느 정도 알 수 있었다.
- I could see to some extent why GAN does not work well on data with discrete outputs such as text.
