에서 Intro to Machine Learning부터 한 주씩 진행하려 한다.
Introduction
먼저 기계 학습 모델의 작동 방식과 사용 방법에 대한 개요를 살펴보자.
다음 시나리오(부동산 가격 예측)를 진행하면서 모델을 구축해보자
상황을 가정해보자.
- 사촌이 부동산 투기로 수백만 달러를 벌었음.
- data science에 대한 나의 관심 때문에 그 사촌이 나와 비즈니스 파트너가 되고싶다는 제안을 받았음.
- 사촌 : 금전 지원 / 나 : 주택의 가치 예측 모델 제공 하기로 함
나 : 과거에 부동산 가치를 어떻게 예측했니?
사촌 : 직관..feel..
이겠냐?
더 많은 질문을 통해
- 사촌이 과거에 본 주택의 가격 패턴을 인지했음
- 이러한 패턴을 사용하여 고민중인 새 주택에 대한 예측을 한다!
는 사실을 알게됨.
머신러닝도 같은 방식으로 작동한다.
Decision Tree(의사결정나무)라는 모델부터 시작해보자.
물론 더 정확한 예측을 제공하는 다른 모델들이 있으나, Decision Tree는
1. 이해하기 쉽고
2. 데이터 과학 분야 최고의 모델 몇몇의 기본 구성(뿌리) 요소
임
이제, 단순하게 가장 간단한 의사결정나무부터 살펴보자.
Sample Decision Tree
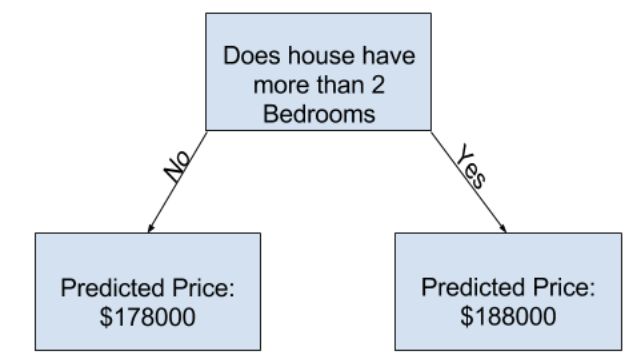
'집'을 두 개의 카테고리로 나누었음.
고려 중인 주택의 예상 가격 = 동일한 카테고리에 있는 주택의 과거 평균 가격
우리는 데이터를 사용하여
- 주택을 두 그룹으로 나누는 방법을 결정한 다음
- 다시 각 그룹의 예측 가격을 결정
데이터에서 패턴을 포착하는 이 단계를 모델 피팅(fitting) 또는 학습(훈련, training the model)이라고 한다.
모델을 맞추는 데 사용되는 데이터를 훈련(학습) 데이터(training data)라고 함.
모델이 어떻게 적합한지에 대한 세부 사항(예: 데이터 분할 방법)은 나중을 위해 저장해 둘 만큼 복잡함.
모델을 적합한 후에는, 이를 새 데이터에 적용하여 또다른 주택 가격을 예측할 수 있다.
Improving the Decision Tree
다음 두 의사 결정 나무 중 부동산 학습 데이터를 fitting한 결과로 나올 가능성이 더 높은 것은 무엇일까?
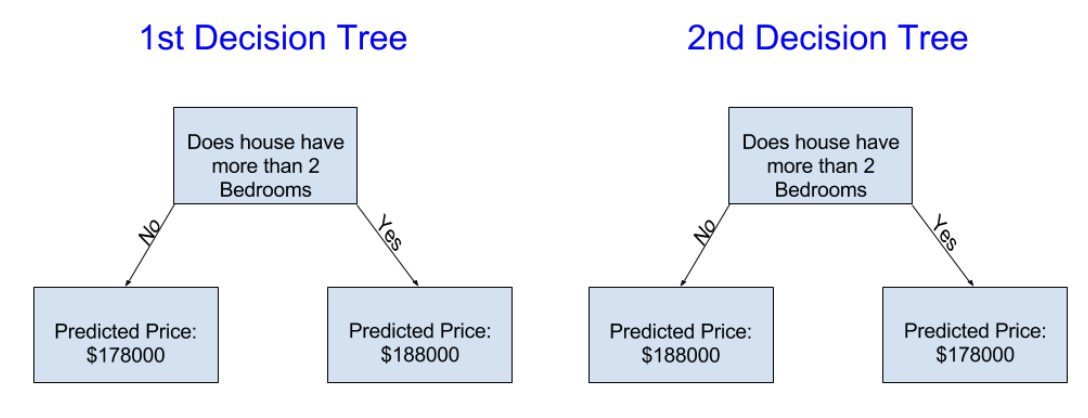
Decision Tree1은 침실이 더 많은 주택이 침실이 적은 주택보다 더 높은 가격에 판매되는 경향이 있다는 현실을 포착하기 때문에 아마도 더 의미가 있을 것임.
이 모델의 가장 큰 단점은 욕실 수, 부지 크기, 위치 등과 같이 주택 가격에 영향을 미치는 대부분의 요소를 포착하지 못한다는 것..
더 많은 "분할(splits)"이 있는 트리를 사용하면 더 많은 요인을 고려할 수 있다.
이러한 나무를 "더 깊은(deeper)" 나무라고 한다.
각 주택 부지의 전체 크기까지 고려하는 의사결정 트리는 다음과 같다 :
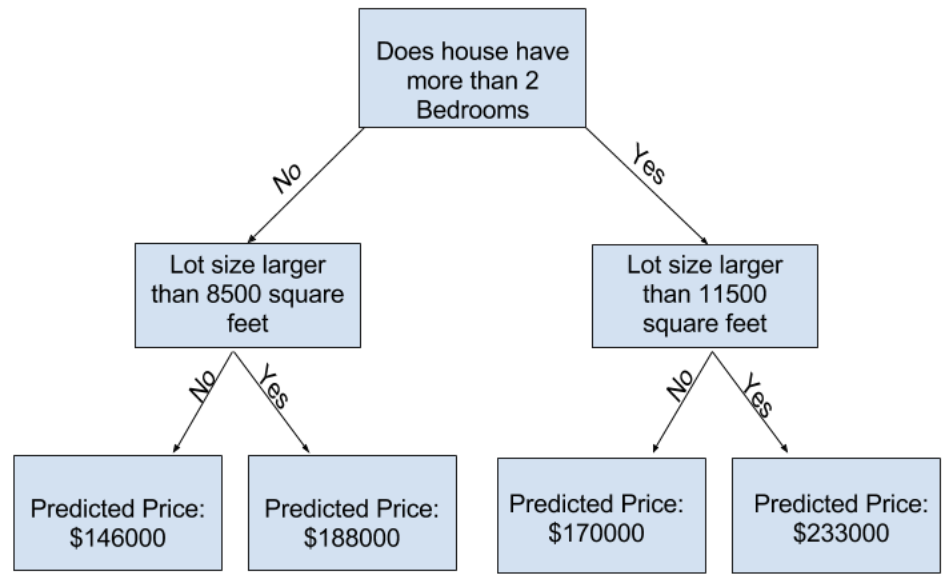
우리는 항상 해당 주택의 특성에 해당하는 경로를 선택하여 의사결정 트리를 추적하여 주택 가격을 예측한다.
집의 예상 가격은 트리 맨 아래에 있음
우리가 예측을 하는 맨 아래 지점을 leaf라고 한다
leaf의 split과 value는 데이터에 따라 결정되므로 작업할 데이터를 반드시 확인해야 함
