Titanic에 이어 Spaceship Titanic 데이터셋으로 학습을 진행했다.
지난 번 Titanic은 scikit-learn의 Random Forest Model을 이용했는데, 이번엔 Tensorflow의 Decision Forests(Random Forest model)를 이용한다.
참고 코드 :
Spaceship Titanic Dataset with TensorFlow Decision Forests
대략 코드는 이런식으로 진행될 예정 :
import tensorflow_decision_forests as tfdf
import pandas as pd
dataset = pd.read_csv("project/dataset.csv")
tf_dataset = tfdf.keras.pd_dataframe_to_tf_dataset(dataset, label="my_label")
model = tfdf.keras.RandomForestModel()
model.fit(tf_dataset)
print(model.summary())Random Forest Model은 scikit-learn과 tensorflow에서 모두 제공하는데, 이 둘은 갤럭시와 아이폰의 차이라고 생각할 수 있다.
Import Library
학습에 필요한 라이브러리들을 불러오자
import tensorflow as tf
import tensorflow_decision_forests as tfdf
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt버전 확인 :
print("TensorFlow version"+tf.__version__)
print("TensorFlow Decision Forests version"+tf.__version__)[결과]
TensorFlow version2.13.0
TensorFlow Decision Forests version2.13.0
Load the Dataset
Pandas의 dataframe을 이용해 데이터셋을 불러온다.
shape으로 dataset의 크기도 확인을 해보면
dataset_df = pd.read_csv('/kaggle/input/spaceship-titanic/train.csv')
print("Full Train dataset shape is {}".format(dataset_df.shape))[결과]
Full Train dataset shape is (8693, 14)
14개의 열(얘네가 feature)에 8693개의 엔트리(값)가 있음.
14개의 열 -> 14차원
head(5)로 상위 5개씩의 엔트리를 전부 살펴볼 수 있다.
dataset_df.head(5)[결과]
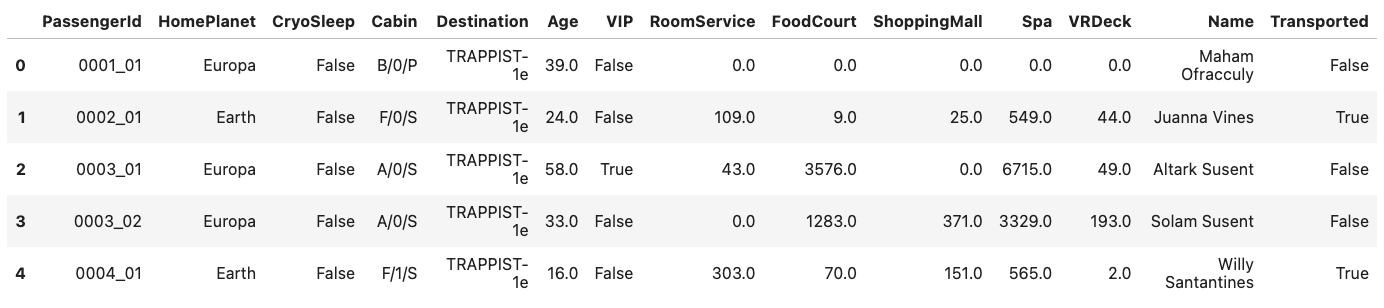
12개의 feature columns (첫 번째 index열과 마지막 label인 Transported 제외)
이 특징들을 이용해서 승객이 구조됐는지 안됐는지를 예측해야 함
basic exploration of the dataset (데이터 슬쩍 까보기)
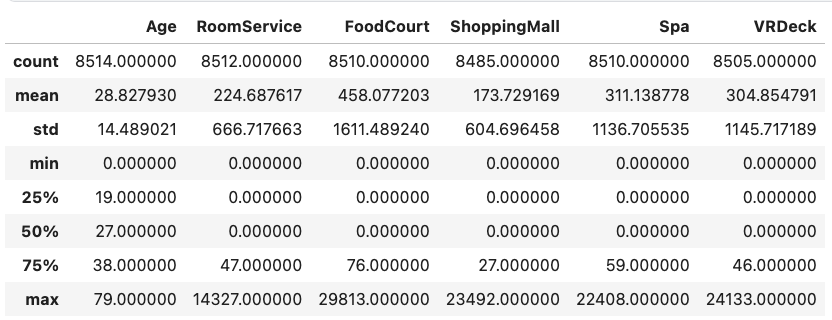
- df.describe() : 수치형 데이터의 기초통계량 값
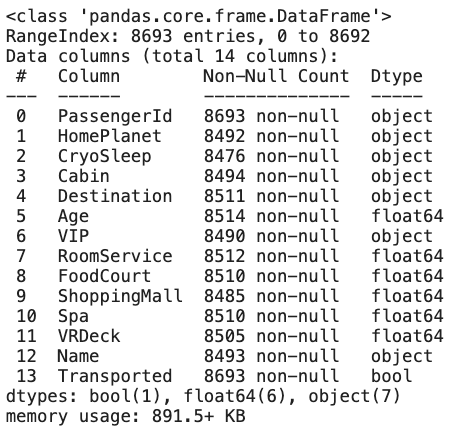
- df.info() : 데이터프레임의 메타 정보(각 column별 데이터 타입, 존재하는 값의 개수)를 알려준다. (이 때, object 타입은 대부분 문자열 형태를 가리킨다)
를 이용해 데이터를 살펴보자.
dataset_df.describe()[결과]
dataset_df.info()[결과]
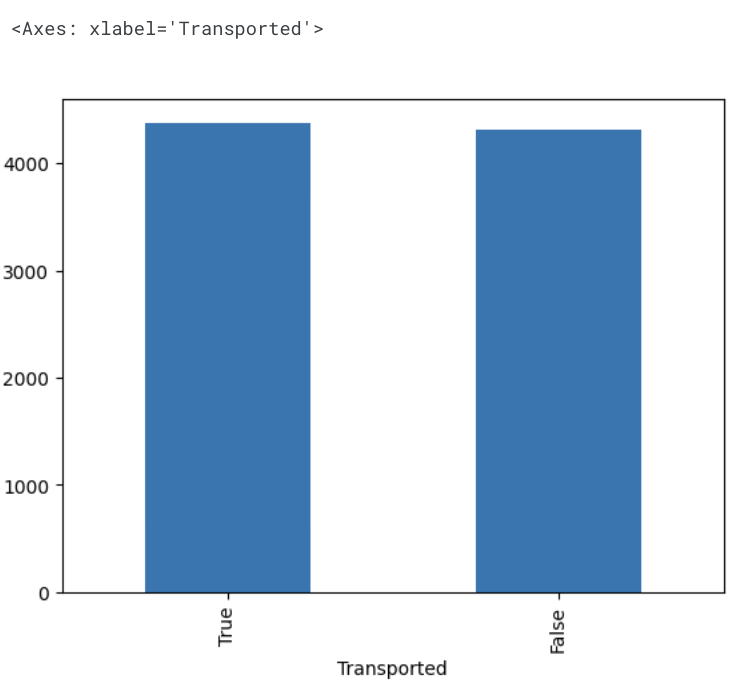
Bar chart for label column(Transported)
label column 인 Transported의 True / False 데이터 개수를 막대그래프(bar chart)로 그려보면,
plot_df = dataset_df.Transported.value_counts()
plot_df.plot(kind="bar")[결과]
수치형 데이터 분포
모든 수치형 열과 값을 세서 plot해보자.
수치형 데이터는 아까 df.info() 에서 Dtype이 float이었던 6개의 column(Age, FoodCourt, ShoppingMall, Spa,VRDeck)들이다.
fig, ax = plt.subplots(5,1, figsize = (10,10))
plt.subplots_adjust(top=2)
# ; 붙이면 설명문들이 안 뜨고 그림만 볼 수 있음 (adding a semicolon also prevents the return value to be printed)
sns.histplot(dataset_df['Age'], color='b', bins=50, ax=ax[0]); # bins : 막대 개수
sns.histplot(dataset_df['FoodCourt'], color='b',bins=50, ax=ax[1]);
sns.histplot(dataset_df['ShoppingMall'], color='b', bins=50, ax=ax[2]);
sns.histplot(dataset_df['Spa'], color='b',bins=50, ax=ax[3]);
sns.histplot(dataset_df['VRDeck'], color='b', bins=50, ax=ax[4]);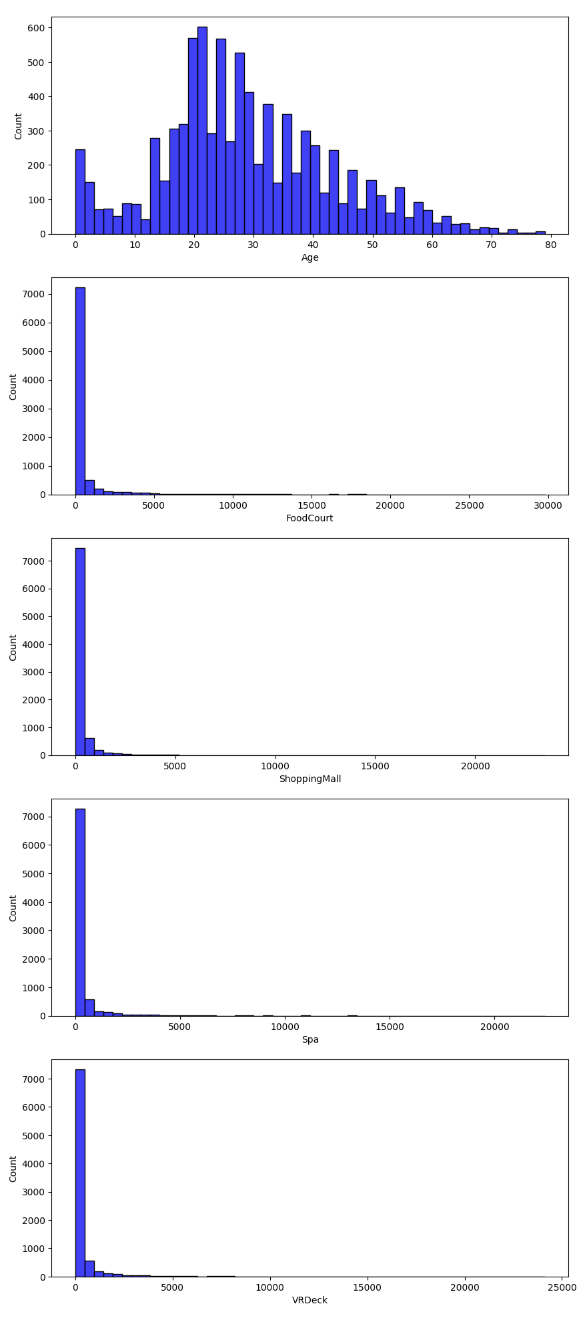
python은 세미콜론(;)을 사용하지 않아도 되는데 왜 matplotlib에서는 plotting 하며 세미콜론을 사용할까?
파이썬에서 세미콜론은 결과를 숨기기위해서 사용한다. 문법적 오류가 생기지는 않지만 matplotlib 처럼 시각화 할 때 불필요한 결과를 숨길 수 있다.
(참고 : stackoverflow)
Prepare the dataset
이제 진짜 학습을 위해 필요한 데이터만 뽑아오자.
df.drop([제거할 columns], axis)
이 학습에서 passengerId 와 Name 은 필요없으므로 제거(drop)해준다
axis=0 이면 행 방향(가로)으로 제거하고,
axis=1 이면 열 방향(세로)으로 제거한다.
dataset_df = dataset_df.drop(['PassengerId', 'Name'], axis=1)
dataset_df.head(5)[결과]

isnull() 메소드를 이용해 결측치(값이 없는 NaN값들)를 찾아보자.
isnull() 개수는 sum()을 통해 세고, sort_values(ascending=False) 로 내림차순으로 정렬해서 확인할 수 있다.
dataset_df.isnull().sum().sort_values(ascending=False)[결과] :
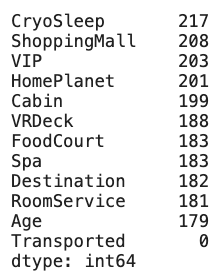
df.fillna(value=0)
보면 이 데이터셋은 수치형, 범주형, 그리고 없는(?,missing) 특징들이 섞여있는 데이터셋임
Tensorflow의 Decision Forests(이하 TF-DF)는 이러한 feature type들을 지원하고, 전처리가 필요 없음!
BUT 이 데이터셋은 값이 없는 boolean field들도 있는데, 얘네는 지원을 안해줌.
그래서 boolean의 없는 값들은 0으로 대체할 것임
- boolean columns : null -> 0
- 수치형 columns : null 값 -> 0
- TF-DF가 범주형 columns들의 null 값만 다룰 수 있도록
(Note : 필요하면 TF-DF가 수치형 column들도 다룰 수 있게 해도 됨)
dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']] = dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']].fillna(value=0)
# dataset_df[['VIP', 'CryoSleep', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']].fillna(value=0, inplace=True)
dataset_df.isnull().sum().sort_values(ascending=False)[결과]
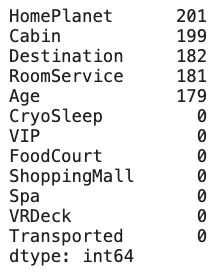
(주의) inplace=True : 사용하지 말 것
여기서 새로운 변수로 데이터프레임을 만들지 않고, fillna(inplace=True)를 사용하면 제대로 적용이 되지 않고 오류가 발생한다.
inplace=True 는 마치 '덮어쓰기' 기능과 유사한데,Pandas 자체가 벡터화를 통해 데이터를 수정하고, 성능을 개선하기 때문에 slice를 데이터 프레임에 inplace로 수정하는 것을 지양한다. 그러므로 default 값인 inplace=False를 통해 새로운 데이터프레임(기존과 동일한 데이터프레임이어도 상관 없다)에 덮어씌운다.
(참고 : stackoverflow)
inplace = True를 사용하게 되면 원래있던 데이터 프레임의 형태 자체에 변형이 생기기 때문에 부작용(버그)이 생길수도 있다.
Pandas 개발팀도 inplace 매개변수는 사용하지 않는 것을 권장했고, 추후 이 기능을 삭제할 예정이라 발표했다.
새로운 변수를 만들면 복잡도가 올라가서 성능면에서 나쁘지 않나? 생각할 수도 있으나, 성능에 큰 차이가 있지 않다.
inplace=True를 사용하면 아무것도 반환되지 않아 코드를 이어 쓰는데 방해가 된다.
메모리 사용량을 아끼는 데에도 별 영향을 주지 않음. 차라리 함수로 만드는 것이 나음.
또한, 가독성 측면에서도 사용하지 않는 것이 좋다.
df.astype()
boolean은 못다루기 때문에, Transported 열의 label(True/False 값)을 integer로 조정해줄 필요가 있음
마찬가지로 boolean인 VIP와 CryoSleep도 integer로 바꿔주자
label = "Transported"
dataset_df[label] = dataset_df[label].astype(int)
dataset_df['VIP'] = dataset_df['VIP'].astype(int)
dataset_df['CryoSleep'] = dataset_df['CryoSleep'].astype(int)데이터를 확인해보면,
Cabin 열의 값들의 구성은 Deck/Cabin_num/Side 순으로 쓴 것임.
그래서 Cabin이라는 하나의 열을 Deck, Cabin_num, Side 세 개의 열로 쪼개줄 것임
(이 각각의 데이터들로 학습하는게 더 쉬움)
dataset_df[["Deck", "Cabin_num", "Side"]] = dataset_df['Cabin'].str.split('/', expand = True)이제 필요없는 기존의 Cabin 열은 제거해준다. (df.drop)
try:
dataset_df = dataset_df.drop('Cabin', axis=1)
except KeyError:
print("Field does not exist")~ 확인 ~
dataset_df.head(5)[결과]

Cabin 열은 사라지고,
마지막에 Deck, Cabin_num, Side 세 개의 열이 추가된 것을 확인할 수 있다.
Train/Test로 데이터셋 나누기
전체 데이터셋을 학습용: 검증용 8:2 비율로 나눈다.
def split_dataset(dataset, test_ratio=0.20):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
print(f"{len(train_ds_pd)} examplies in training, {len(valid_ds_pd)} examples in testing")[결과]
7006 examplies in training, 1687 examples in testing
dataset을 Pandas에서 Tensorflow로 바꾸기
TensorFlow Dataset이 신경망 학습할 때 GPU나 TPU 쓰면 Pandas보다 더 성능이 좋은 라이브러리임.
때문에 Tensorflow dataset으로 바꿔준다.
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label)
valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(valid_ds_pd, label=label)학습 모델 선택 - Random Forest
tree기반 모델은 여러 가지가 있음
- Random Forest Model
- Gradient Boosted Trees Model
- Cart Model
- Distributed Gradient Boosted Trees Model
다음의 코드를 통해 사용할 수 있는 TensorFlow Decision Forest 모델들을 다 뽑아볼 수 있음
tfdf.keras.get_all_models()[결과]
[tensorflow_decision_forests.keras.RandomForestModel,
tensorflow_decision_forests.keras.GradientBoostedTreesModel,
tensorflow_decision_forests.keras.CartModel,
tensorflow_decision_forests.keras.DistributedGradientBoostedTreesModel]
우리는 랜덤 포레스트 이용 :: 가장 유명한 Decision Forest 학습 알고리즘
Random Forest란?
- Decision Tree 모음집 느낌. 학습 데이터셋에서 데이터를 랜덤하게 뽑아서 각각 독립적으로 학습시킨다.
- overfitting에 강건(robust)하고 사용하기 쉽다는 면에서 유니크한 알고리즘
Configure the model
TF_DF는 default 설정으로도 성능이 꽤 좋음!
(코드 작성자의 벤치마크의 탑 랭킹 하이퍼파라미터이고, 합리적인 시간동안 돌아가도록 약간 수정된 것임)
만약 이 학습 알고리즘을 구성하고 싶으면 정확도를 높이기 위해 여러 옵션을 설정할 수 있음.
템플릿을 고르거나 파라미터 설정하려면 아래처럼 하면 됨!
rf = tfdf.keras.RandomForestModel(hyperparameter_template="benchmark_rank1")Create a Random Forest
디폴트 값들로 Random Forest Model 만들 것임 : 분류 문제에 적합하도록 학습
rf = tfdf.keras.RandomForestModel()
rf.compile(metrics=["accuracy"]) # 선택사항[결과]
Use /tmp/tmpj4yyscdo as temporary training directory
Train the model
one-linear로 학습할 것임
(아래의 코드를 실행하면 Autograph 관련한 경고 뜰텐데 무시해도 됨 (다음진행에서 고칠거라))
rf.fit(x=train_ds)[결과]
Visualize the model
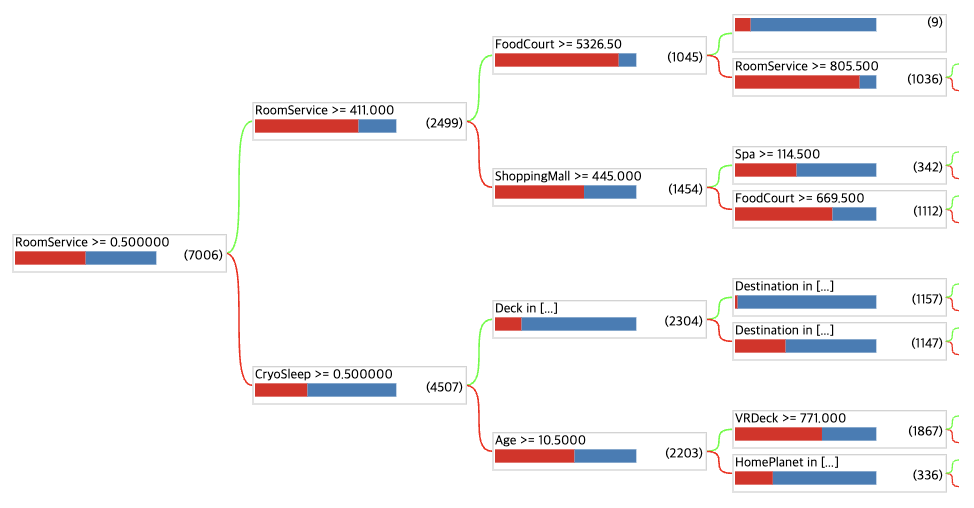
트리 기반 모델의 장점 중 하나는 우리가 쉽게 시각화 할 수 있다는 것임.
랜덤 포레스트에서 디폴트로 사용되는 트리 수는 300개임. 보고싶은 트리 고를 수 있음
tfdf.model_plotter.plot_model_in_colab(rf, tree_idx=0, max_depth=3)[결과]
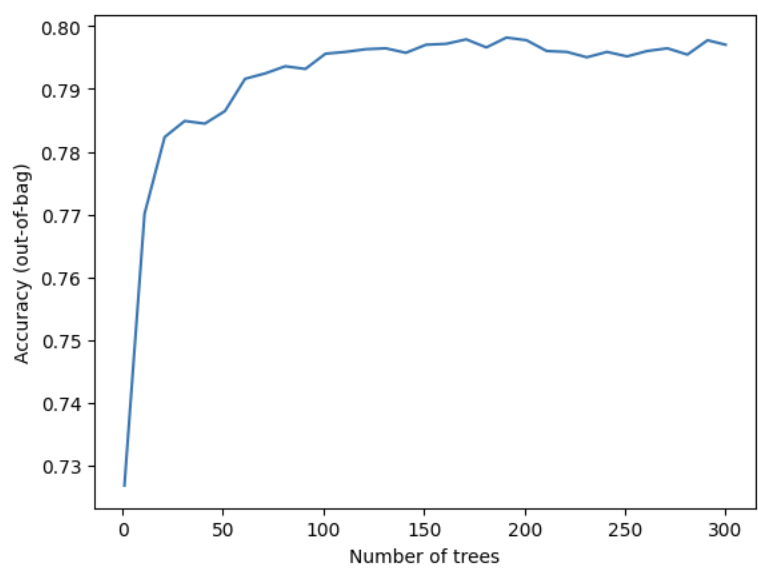
Evaluate the model on the Out of bag(OOB) data and the validation dataset
Out of bag data(OOB)
학습하기 전에, 데이터셋의 20%는 평가용으로 쪼개놨음(valid_ds)
Out of bag(OOB) 점수로 우리의 랜덤포레스트모델을 평가할 수도 있음.
Random Forest Model은 알고리즘에 따라 training set에서 랜덤으로 샘플들을 뽑아서 모으고, 나머지 샘플들은 모델을 fine tuning 하는 데 사용됨.
뽑히지 않은 사용되지 않은 데이터를 Out of bag data(OOB)라고 함.
OOB 점수는 OOB data를 기반으로 계산됨.
학습 로그는 모델의 트리 수에 따라 OOB 데이터셋에서 평가된 정확도를 보여줌
(Note : 이 hyperparamer에는 더 큰 값일수록 성능이 좋다)
import matplotlib.pyplot as plt
logs = rf.make_inspector().training_logs()
plt.plot([log.num_trees for log in logs],
[log.evaluation.accuracy for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("Accuracy (out-of-bag)")
plt.show()[결과]
make_inspector().evaluation()
OOB 데이터셋의 기초 결과값(정확도, loss 등)도 볼 수 있음
inspector = rf.make_inspector()
inspector.evaluation()[결과]
Evaluation(num_examples=7006, accuracy=0.7970311161861262, loss=0.5455431430022993, rmse=None, ndcg=None, aucs=None, auuc=None, qini=None)
Validation dataset
이제 validation dataset으로 시험해보자
evaluation = rf.evaluate(x=valid_ds, return_dict=True)
for name, value in evaluation.items():
print(f"{name}: {value:.4f}")[결과]
2/2 [==============================] - 1s 71ms/step - loss: 0.0000e+00 - accuracy: 0.7973
loss: 0.0000
accuracy: 0.7973
꽤 좋은 성능이 나옴
Variable importances
변수의 중요도는 보통 feature가 모델의 예측과 퀄리티에 얼마나 기여하는지 알려줌.
TF-DF에서는 많은 방법이 있는데, 그 중 우리는 의사결정 트리에 사용 가능한 Vriable Importances 를 나열할 것
print(f"Available variable importances:")
for importance in inspector.variable_importances().keys():
print("\t", importance)[결과]

위의 예시처럼, NUM_AS_ROOT로 중요한 feature를 나타내자.
NUM_AS_ROOT의 값이 클수록, 모델의 결과에 더 많은 영향을 주는 것이다.
(디폴트) 이 리스트는 가장 중요한 것부터 순서대로 정렬됨.
결과에서 목록의 상단에 있는 feature들이 다른 기능보다 Random Forest에 있는 대부분의 트리에서 root node로 사용됨을 추론할 수 있음.
# 각각의 line : (특징 이름, 특징의 인덱스 번호, 중요도)
inspector.variable_importances()["NUM_AS_ROOT"][결과]
[("CryoSleep" (1; #2), 110.0),
("Spa" (1; #10), 75.0),
("RoomService" (1; #7), 40.0),
("VRDeck" (1; #12), 39.0),
("ShoppingMall" (1; #8), 16.0),
("FoodCourt" (1; #5), 14.0),
("Deck" (4; #3), 4.0),
("HomePlanet" (4; #6), 2.0)]
Submission
test dataset으로 위의 내용을 빠르게 진행한다.
-
test dataset 불러오기
test_df = pd.read_csv('/kaggle/input/spaceship-titanic/test.csv') submission_id = test_df.PassengerId -
NaN값(결측치) 0으로 채워주기
test_df[['VIP','CryoSleep']] = test_df[['VIP','CryoSleep']].fillna(value=0) -
Cabin 열 Deck, Cabin_num, Side 로 쪼개서 새로운 열로 추가하고, Cabin 열 제거
test_df[["Deck", "Cabin_num", "Side"]] = test_df["Cabin"].str.split("/", expand=True) test_df = test_df.drop('Cabin', axis=1) # Cabin "열"(axis=0) 지우기 -
boolean 값 0과 1 (integer)로 바꾸기
test_df['VIP'] = test_df['VIP'].astype(int) test_df['CryoSleep'] = test_df['CryoSleep'].astype(int)
-
pandas 데이터프레임 tensorflow dataset으로 바꾸기
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df) -
test data에 대한 예측값 구하기
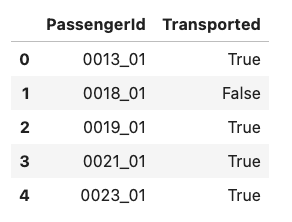
predictions = rf.predict(test_ds) n_predictions = (predictions > 0.5).astype(bool) output = pd.DataFrame({'PassengerId': submission_id, 'Transported': n_predictions.squeeze()}) output.head()[결과]
sample_submission_df = pd.read_csv('/kaggle/input/spaceship-titanic/sample_submission.csv')
sample_submission_df['Transported'] = n_predictions
sample_submission_df.to_csv('/kaggle/working/submission.csv', index=False)
sample_submission_df.head()[결과]