Classification of Indoor Human Fall Events Using Deep Learning

학부연구생으로 소속된 연구실에서 진행중인 Fall Detection을 위한 모델을 구현하기 위해 관련 논문을 읽고 이해한 부분에 대해 간단하게 정리하였다.
<논문 정보>
제목: Classification of Indoor Human Fall Events Using Deep Learning
게재일자: 2021
발행기관: mdpi
위 논문에서는 2DCNN모델과 GRU모델을 통합하여 입력 데이터셋에 대해 시간적 특징 뿐만 아니라 공간적 특징을 고려해 Fall/Non Fall을 분류하는 아키텍처를 제안하였다.
Introduction
본 논문에서는 CNN과 RNN을 통합하여 실내 환경에서 노인을 모니터링할 수 있는 Human Fall Detection and Classification을 위한 딥러닝 및 컴퓨터 비전 기반 프레임워크를 제안한다. 다양한 유형의 RNN 중에서 Gated Recurrent Unit(GRU)를 이용해 아키텍처를 구현하였다.
VGG16, VGG19 같은 CNN 모델을 구현할 때 흔히 사용되는 전이 학습 모델을 사용하여 Fall/Non Fall을 분류하기 위한 실험을 진행하였다. 사용한 데이터셋은 UR fall detection dataset과 Multiple cameras fall dataset이다.
Workflow of Proposed Architecture
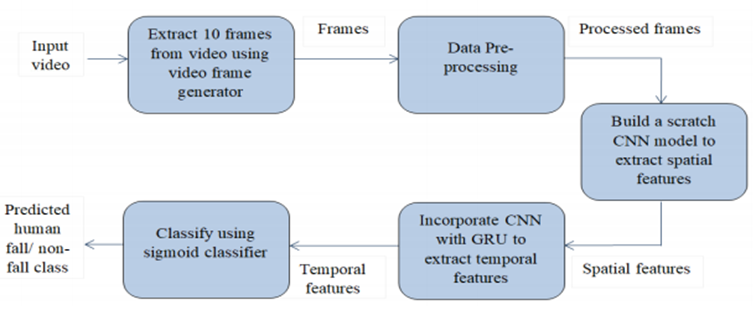
본 논문에서 제안하는 모델 네트워크의 개요를 보여주는 그림이다. Video frame generator를 이용하여 가변 길이의 비디오에서 10개의 순차 프레임을 추출한다. 전처리 과정을 거친 추출된 프레임들을 컨볼루션 신경망으로 전달하여 주요 특징을 추출해낸다. 여기서 추출된 공간적 특징은 GRU로 전달되어 시간적 특징을 추출하게 되고, 최종적으로 GRU의 출력은 시그모이드 분류기로 전달되어 클래스를 예측한다. 네크워크의 첫 번째 과정인 비디오에서 프레임 시퀀스를 생성하는 것과 관련된 알고리즘은 다음과 같다.
Frame Generation from Video

Introduction에서 언급한 두 개의 데이터셋에 다양한 duration의 약 300개의 비디오가 있다. 앞서 설명했듯, 하나의 비디오에서 10개의 분산된 이미지만을 선택해 Fall과 Non Fall을 분류하고, 그 외의 다른 모든 프레임은 고려하지 않는다.
Preprocessing
프레임 크기 조정, 데이터셋 확대, 정규화 이렇게 세 단계로 전처리를 수행한다. 프레임 크기는 150 x 150으로 조정하고, 이후 augmentation이 수행되어 각 train epoch에서 프레임을 변환한다. Augmentation 과정에서는 확대 및 축소, 수평 뒤집기, 회전, 너비 이동 및 높이 이동을 수행한다.
Custom 2DCNN-GRU Architecture
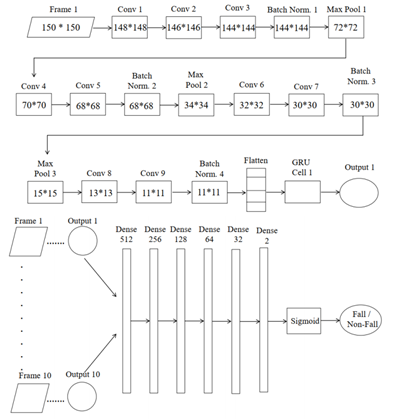
제안한 모델을 크게 CNN과 관련된 구현 부분, GRU와 관련된 구현 부분으로 구분할 수 있는데, 먼저 CNN 관련 부분에 대해 요약하여 설명해보겠다. 본 논문에서는 16, 32, 64, 128, 256 및 512개의 커널이 컨볼루션 레이어에서 순차적으로 사용되어 이미지에서 공간적 특징을 추출한다. 제안한 모델에서는 he_uniform 커널 이니셜라이저를 사용해 초기 커널을 선택하고 ReLU 함수로 가중치 업데이트를 수행한다. 0.9 모멘텀으로 배치 정규화를 진행함으로써 학습이 안정적으로 진행되도록 하였다. Max pooling시에는 (2, 2) 간격의 stride를 사용해 강한 에지를 추출할 수 있도록 하였다.
다음으로 GRU을 위한 데이터를 준비하기 위해 512개의 노드와 함께 time-distributed 레이어를 사용한다. 이후 GRU cell을 사용해 비디오 프레임의 시간적 종속성을 고려해 출력값을 계산하고 이를 Dense 레이어에 전달한다. 이때, 과적합을 제거하기 위해 0.5 비율의 드롭아웃을 사용하고, 학습률 0.0001인 Adam optimizer를 사용하였다.
Gated Recurrent Unit (GRU)
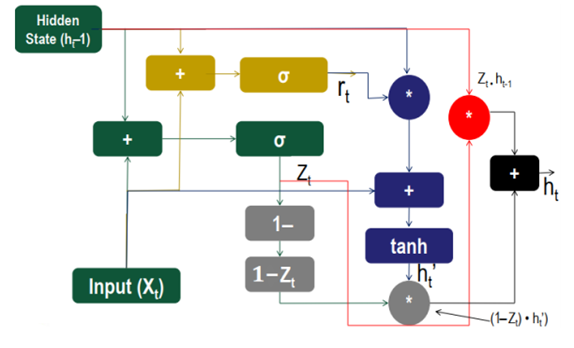
2DCNN-GRU 아키텍처에서 GRU Cell을 자세히 나타낸 그림이다. RNN은 gradient vanishing, exploding이 존재한다는 단점이 있는데, 이를 해결한 것이 GRU이다. GRU를 구성하는 게이트들은 새로운 입력을 지우지 않으면서 과거의 정보를 보유하고 예측을 위해 다음 time step에 관련 정보를 전달하도록 훈련된다. GRU에는 3개의 게이트가 존재하는데, 먼저 업데이트 게이트(위 그림의 초록색 부분)는 과거와 현재 정보의 업데이트 비율을 결정한다. 리셋 게이트(위 그림의 노란색 부분)는 얼마나 많은 과거 정보를 잊을지를 결정한다. 마지막으로 후보 게이트(위 그림의 파란색 부분)는 과거의 관련 정보와 함께 현재 상태 정보를 결정한다. 아래의 내용은 그림으로 나타낸 GRU Cell의 아키텍처를 수식으로 표현한 것이다.
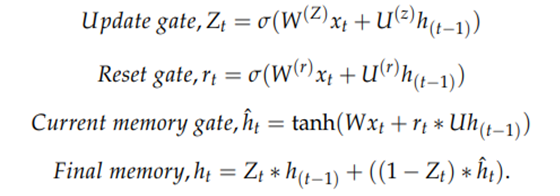
위 수식에서 x는 미니 배치 Input을 나타낸다. W는 현재 가중치 파라미터를, U는 업데이트된 가중치 파라미터를 의미한다.
Experiments
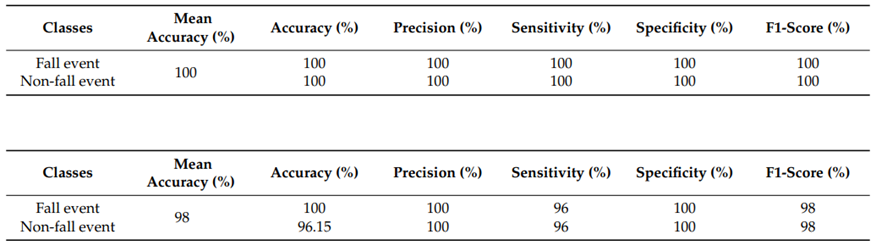
Training data 40%, Validation data 35%, Test data 25% 비율로 실험을 진행하였을 때 최상의 학습 및 검증 정확도를 달성하였다. 이 외에도 프레임 개수에 따른 실험 소요 시간, 데이터 정규화 유무, 드롭아웃 비율에 따른 성능 차이를 모두 고려하여 최종적으로 10개의 프레임, 배치 정규화 수행, 50%의 드롭아웃의 조건에서 실험을 진행하였다. 각각의 평가 지표 클래스별 성능은 위의 표에 자세히 기재되어있다. 표에는 대부분의 수치가 정수로 기재되어 있지만, 결과적으로 UR fall detection 데이터셋에 대해서는 99.8%, Multiple cameras fall 데이터셋에 대해서는 98%의 정확도를 달성하여 평균 99%의 정확도를 얻어내는 데 성공했다.
Conclusions
본 논문에서는 CNN과 GRU가 통합된 아키텍처를 제안했다. 이외에도 경보 시스템을 포함해 필요한 조치를 제시간에 수행할 수 있도록 하는 것, 한 프레임 내에서도 두드러진 영역만 고려하여 계산 시간을 줄이는 것, 프레임 내의 사람들 각각의 행동을 식별하기 위한 피플 카운팅 기술과의 협력을 언급하며 논문을 마무리지었다.
