Vision-Based Fall Detection with Convolutional Neural Networks

학부연구생으로 소속된 연구실에서 진행중인 Fall Detection을 위한 모델을 구현하기 위해 관련 논문을 읽고 이해한 부분에 대해 간단하게 정리하였다.
<논문 정보>
제목: Vision-Based Fal Detection with Convolutional Neural Networks
게재일자: 2017
발행기관: Wireless Communications and Mobile Computing
위 논문에서는 Fall Detection을 위한 비전 기반 접근 방식에 중점을 둔 CNN 아키텍처를 제안하였다.
Introduction
본 논문에서는 Fall Detection을 위해 Convolutional Neural Networks(CNN)을 활용하는 방식을 제안한다. 보다 정확하게는, optical flow 이미지에서 어떻게 CNN을 통해 Fall을 감지하는지를 소개한다. 여기서는 전이 학습 모델을 사용하여 비교적 적은 수의 데이터를 가지고 딥러닝 모델을 훈련시켰다. 사용한 데이터셋은 ImageNet dataset과 UCF101 action dataset외에 UR fall dataset, Multiple cameras fall dataset, Fall detection dataset이 있다.
Materials and Methods

위 그림은 본 논문에서 제안하는 아키텍처이다. RGB 영상이 optical flow 영상으로 변환되고, 이를 스택처럼 쌓아서 CNN에 입력으로 넣는다. CNN에서는 영상의 특징들에 대한 배열을 추출하고, FC-NN에서 Fall/Non Fall을 최종적으로 결정한다. Fall Detection에서는 time management가 매우 중요하기 때문에 시간과 움직임에 대처하는 방법이 추가된 것이다.
한편, 위 아키텍처의 설계는 3가지 목표에 따라 이루어졌다. 첫 번째는 시스템을 환경적인 특징들로부터 독립적으로 만들고자 하였다. 즉, 입력으로 들어오는 영상의 모양에 의존하지 않고 사람의 움직임에 따라 작동하는 시스템을 설계하기 위해 두 프레임 사이의 변위 벡터를 설명할 수 있는 optical flow 알고리즘이 사용되었다. 두 번째는 수작업으로 이미지를 처리하는 과정을 최소화하고자 하였다. 그래서 자돋 특징 추출기로써의 성능이 어느정도 입증된 CNN을 사용했다. 마지막으로 시스템을 일반화하여 다양한 시나리오에서 작동할 수 있기를 원했다. 따라서 optical flow 스택 기반의 CNN에 대해 세 단계의 훈련 프로세스를 사용하였다.
Optical Flow Images Generator
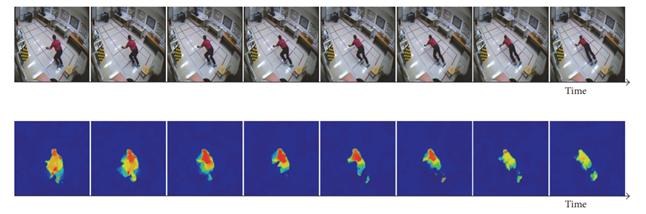
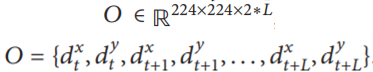
스택된 이미지에서 motion pattern을 감지하는 방식인데, 이는 Fall Down과 같은 짧은 이벤트를 분별해내는 데 유용하다. 위 그림과 같이 배경은 고려 사항에서 배제되기 때문에 어떠한 배경의 데이터셋이더라도 검출이 가능하다. L개의 연속적인 이미지 쌍을 받아와서 TVL-1 optical flow 알고리즘에 적용한다. 이 알고리즘은 주변 밝기 변화에 가장 성능이 좋다.
Neural Network Architecture and Training Methodology

제안하는 모델은 Keras 프레임워크를 사용해 구현하였으며, 전이 학습의 대표적인 모델인 VGG16을 약간 수정한 형태이다. optical flow 이미지를 수용할 수 있도록 VGG16의 기존 input 레이어를 대체하였다. 조정 가능한 매개변수인 L값을 10으로 설정하여 짧은 시간동안의 이벤트를 정확히 감지할 수 있도록 하였다.
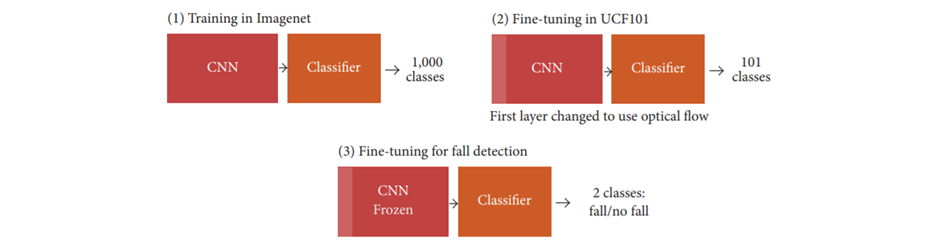
모델의 트레이닝 과정은 위 그림과 같이 3단계로 나눌 수 있다. 먼저, 일반적인 특징 추출기를 학습하기 위해 ImageNet 데이터셋을 활용하여 full training을 실시한다. 다음으로, 사람의 motion을 학습하기 위해 13320개의 영상과 101개의 클래스로 이루어진 UCF101 action 데이터셋으로 재훈련한다. 이때 인간의 움직임을 나타내는 특징들을 배우게된다. 마지막으로, fine-tuning 과정을 거친다. 프로세스 속도를 높이기 위해 컨볼루션 레이어에서 추출한 특징을 fully-connected(FC) 레이어에 저장함으로써 각 입력 스택에 대해 4096 크기의 특징 배열을 갖도록 한다. 2개의 FC 레이어를 사용하는데, 드롭아웃 비율을 각각 0.9, 0.8로 설정한 후 모델을 훈련시켰다.
이 외에도 데이터셋의 fine-tuning을 위해 슬라이딩 윈도우 방식을 사용하고, 이진 크로스 엔트로피 함수를 채택하여 loss 값을 최소화하고자 하였다.
Results and Discussion
Best Configuration Results
우선, 성능을 측정하는 데 사용되는 3개의 데이터셋(UR fall dataset, Multiple cameras fall dataset, Fall detection dataset)을 각각 8:2의 비율로 train set과 test set으로 분할한다. Learning rate의 경우 0.001 ~ 0.00001 사이의 값으로 지정했을 때 네트워크가 훌륭하게 동작한다. Minibatch 사이즈의 경우 1024로 설정했을 때 가장 최상의 결과를 도출해냈으며, Class weight의 경우 2.0일 때 가장 적합했다. 마지막으로, 배치 정규화시 사용할 활성화 함수로는 ReLU가 안정적인 결과값을 도출해냈다.
Generality Test
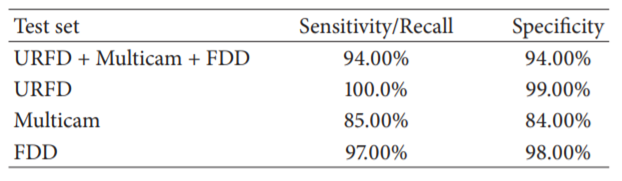
3개의 데이터셋 모두에 동일한 가중치를 부여하기 위해 가장 크기가 작은 데이터셋인 URFD의 크기 및 클래스 분포에 맞게 나머지 2개의 데이터셋을 샘플링하였다. 이러한 조정으로 인해 3개의 데이터셋은 동일한 샘플의 양을 가지고 두 클래스(Fall/Non Fall)가 균형을 이루었다. 5-fold cross-validation을 적용한 후 1000 만큼의 에폭을 통해 성능을 평가한 결과는 위의 표와 같다. 3개의 데이터셋에 전반적으로 훌륭한 결과를 얻어내었다.
Conclusions
본 논문에서는 전이 학습을 적용하여 URFD, Multicam, FDD이라는 3가지 데이터셋에서 Fall Detection을 수행하기 위한 비전 기반 시스템을 제안하였다. 테스트에 사용한 모든 데이터셋에서 전반적으로 높은 성능을 보임으로써 제안한 시스템의 일반성을 보여준 논문이였다.
