Detection of Human Falls on Furniture Using Scene Analysis Based on Deep Learning and Activity Characteristics

학부연구생으로 소속된 연구실에서 진행중인 Fall Detection을 위한 모델을 구현하기 위해 관련 논문을 읽고 이해한 부분에 대해 간단하게 정리하였다.
<논문 정보>
제목: Detection of Human Falls on Furniture Using Scene Analysis Based on Deep Learning and Activity Characteristics
게재일자: 2018
발행기관: IEEE
위 논문에서는 가구에서의 추락과 같이 복잡한 환경에서 매우 정확한 추락 감지를 달성하는 것을 목표로 Faster R-CNN 기반 모델을 구성하여 실험을 설계하였다.
Overview of Proposed Method
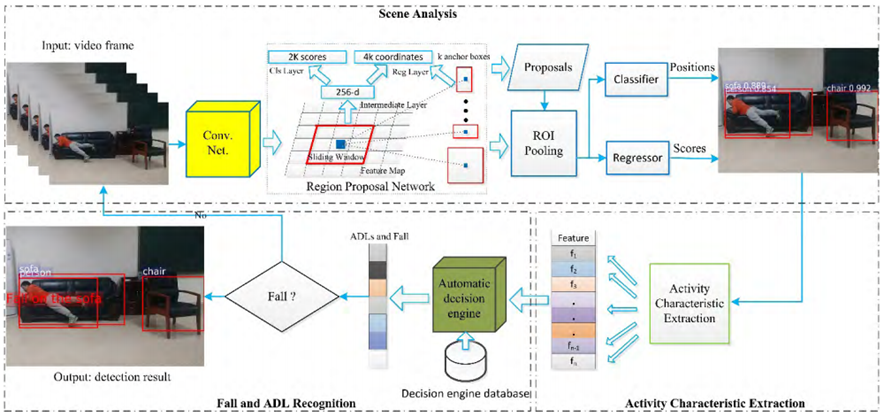
필자가 제안하는 방법에 대한 간략한 개요이다. 그림에서 볼 수 있듯 크게 세 부분으로 구성되어 있다. 첫 번째 부분은 장면 내 위치 및 객체 정보를 얻기 위한 Faster R-CNN 기반 장면 분석 모듈이다. 복잡한 환경에서 Fall을 감지하기 위해 먼저 사람과 가구 사이의 공간 관계를 측정하기 위해 딥 러닝 방법 Faster R-CNN을 사용하여 장면 분석을 진행했다. 두 번째 부분은 사람을 감지하고 추적하는 동안 사람 모양 종횡비, 중심, 동작 속도와 같은 감지된 사람의 활동 특성을 계산하는 Activity Characteristics Extraction 모듈이다. 세 번째 부분은 Fall 및 ADL 인식 모듈이다. 두 번째 부분에서 추출한 특징에 따라 이 모듈은 자동 결정 엔진(automatic decision engine)과 일련의 기준을 사용하여 이러한 특성의 변화를 측정하고 사람과 가구 간의 관계를 판단하여 ADL과 Fall을 구분한다.
Fall Detection Using Scene Analysis
Scene Analysis Using Faster R-CNN

장면 분석은 Detection 프레임워크에서 중요한 절차이다. 장면에서 정확한 위치 및 객체 정보를 추출하기 위해서는 우수한 객체 감지 알고리즘을 선택하는 것이 필수적이다. Faster R-CNN은 R-CNN, Fast R-CNN 및 기타 방법에 비해 객체 감지의 정확도와 속도가 더 빠르다.
객체 감지 방법 Faster R-CNN은 크게 두 개의 모듈로 구성된다. 첫 번째 모듈은 제안된 영역을 사용하는 Fast R-CNN 검출기이다. 두 번째 모듈은 영역을 제안하는 deep full convolutional network이다. 따라서 Faster R-CNN은 간단하게 region proposal network와 Fast R-CNN을 결합한 방법이라고 볼 수 있다. 즉, Fast R-CNN에서 선택적인 탐색 방식을 대체하기 위해 region proposal network를 사용한다. 그림과 같이 R-CNN에서 Fast R-CNN으로, Faster R-CNN으로 4단계(후보 영역 생성, 특징 추출, 분류, 위치 세분화)가 최종적으로 심층 네트워크 프레임워크로 통합된다.
설명을 위해 다시 첫 번째 그림으로 돌아가보면, region proposal network는 n x n 컨볼루션 피처 맵 위에 작은 네트워크를 슬라이드하고 작은 슬라이딩 윈도우를 작은 네트워크의 입력으로 선택한다. 각 슬라이딩 윈도우는 2개의 슬라이딩 FC 레이어, 즉 회귀 레이어(reg 레이어)와 분류 레이어(cls 레이어)에 포함된 256차원 특징으로 축소된다. 각 위치에 대해 가능한 최대 제안 수(k로 표시)를 찾기 위해 각 슬라이딩 윈도우를 찾고 여러 지역 제안을 예측한다. 따라서 4k 출력은 reg 레이어에서 k 상자의 좌표를 인코딩하고 2k 출력은 cls 레이어에서 각 제안에 대한 객체 확률을 추정한다. k 제안은 앵커로 정의되는 k reference boxes에 상대적이다. 앵커는 해당 슬라이딩 윈도우의 중앙에 위치하며 그림의 Region Proposal Network와 같이 크기 및 종횡비와 연결된다. RPN은 정확한 지역 제안을 생성하기 위해 end-to-end로 학습된다. 이 내용에 대한 loss function은 다음과 같다.
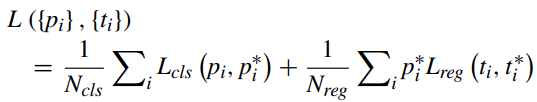
여기서 pi는 앵커 i를 객체로 판단할 예측 확률이다. pi 스타는 앵커가 양수 또는 음수임을 의미하는 1 또는 0과 같다. 예측된 경계 상자의 4개의 매개변수화된 좌표는 ti로 표시되고 ti 스타는 양의 앵커와 관련된 경계 상자이다. 분류 loss Lcls는 이 객체와 이 객체가 아닌 사이의 로그 로스이다. 우리는 Lreg = (ti, ti 스타) = R(ti - ti 스타)를 사용하는데 여기서 R은 회귀 로스를 나타내는 강력한 로스 함수(smooth L1)이다. 두 항은 Ncls 및 Nreg에 의해 정규화되고 균형 매개변수 λ에 의해 가중치가 부여된다.
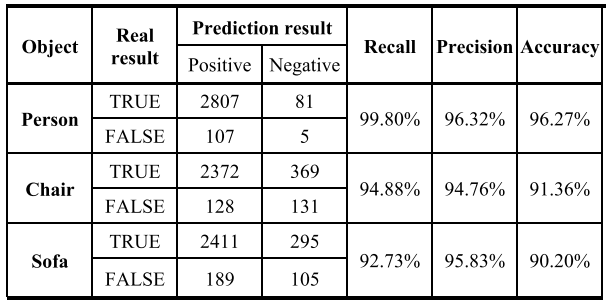
가구에서 사람이 떨어지는 것을 감지하려면 장면의 물체를 분석해야 한다. 따라서 의자, 소파와 같은 일상 생활 활동과 관련된 일부 물체를 감지하는 것이 필요하다. 각각 600프레임을 포함하는 5개의 비디오로 물체 감지를 수행한다. 표와 같이 사람, 의자, 소파에 대한 알고리즘의 리콜, 정밀도, 정확도를 분석하였다. 이는 Faster R-CNN이 객체를 감지할 수 있음을 보여준다.
Activity Characteristics of Human Falls
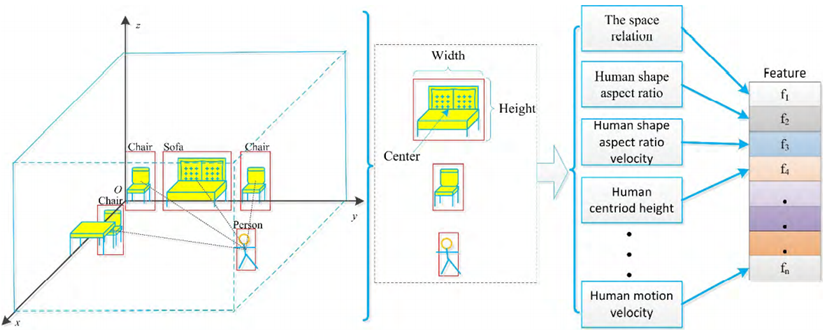
Fall 행동은 걸을 때 주로 발생하지만 소파와 같은 가구에 앉거나 누워있을 때 발생하기도 한다. 소파에서 넘어지는 것과 같은 Fall Down의 특성은 ADL 특성과 유사해서 기존의 방법으로는 이 둘을 구별하는 데 어려움이 있다. 이런 문제를 해결하기 위해 인간과 사물 사이의 공간 관계를 고려한다. 그런 다음 공간적 관계를 측정하기 위해 새로운 특징(Dn으로 표시)을 제안한다.
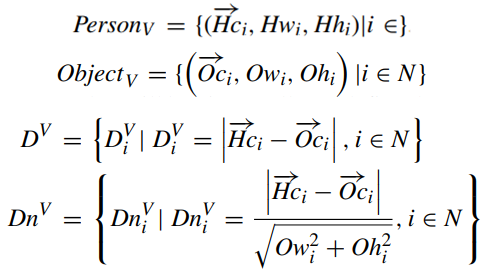
장면 분석에서 정확한 위치와 객체 정보를 추출한다. 주어진 비디오를 V로 표현하고, N(n|n ∈ Z)은 V의 전체 프레임을 나타낸다고 가정한다. 사람의 중심(Hc), 사람의 너비(Hw), 사람의 높이(Hh), 각 사람의 위치 정보는 PersonV로 나타낼 수 있다. 물체의 중심(Oc), 물체의 폭(Ow), 물체의 높이(Oh), V 내의 각 물체의 위치 정보는 ObjectV로 나타낼 수 있다. 객체가 없으면 값이 null로 지정된다. 사람과 가구 사이의 공간적 거리(D)를 세 번째 수식과 같이 정의한다. 각 가구의 크기가 다르므로 거리를 직접 사용하는 것은 통일된 측정이 될 수 없어서 사람과 가구 사이의 거리를 정규화해야 한다. 사람과 가구의 공간관계(Dn)는 맨 마지막 수식과 같이 정의된다.
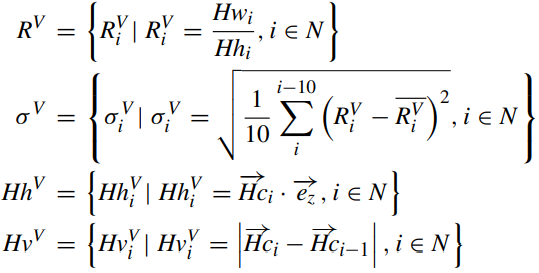
Human shape 종횡비(R), 인접한 10개 프레임 각각의 표준편차, shape 종횡비(σ), Human centroid(Hc), 높이(Hh) 및 인간의 운동 속도(Hv)에 관한 수식이다. 위 공식에 따라 일부 활동 특징을 추출한다. 수직 방향의 방향 벡터는 ez로 표시된다.
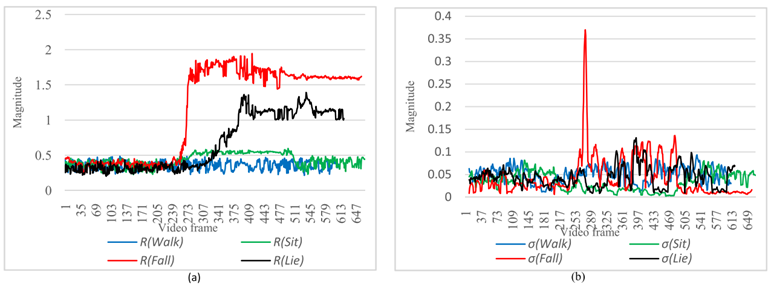
그다음으로 Fall Down 활동 특징을 추출한다. 걷기, 앉기 위해 걷기, 누워서 걷기, 넘어지기까지 걷기와 같은 4가지 활동이 테스트 비디오에 포함되어 있다. 비디오의 각 프레임에 대한 Dn, R 및 σ의 크기 추세가 그림처럼 표시된다. 그림 (b)에서 R의 크기가 순간적으로 변화함에 따라 σ의 크기도 변한다. R의 크기가 사람들이 정상적으로 걸을 때 매우 작고 매끄럽고 사람들의 활동이 변화할 때 R의 크기가 큰 변화를 겪었음을 분명히 알 수 있다. 분명히 특징은 다른 동작에서 다른 값을 보여주고 좋은 구별을 하고 있다.
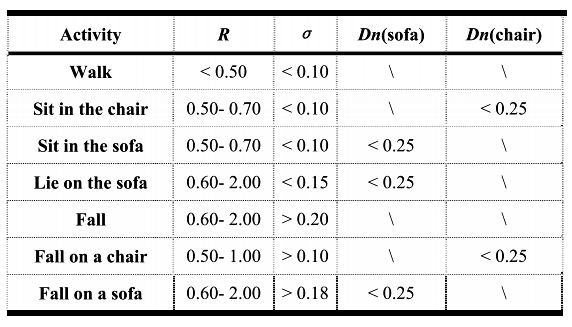
위의 실험에 따르면 각 행동의 특징은 고정된 범위 내에 있다. 그래서 표와 같이 서로 다른 활동에 대한 세 가지 매개변수의 범위를 요약할 수 있다.
그림과 같이 Fall을 인식하고 ADL을 분류하는 알고리즘을 설계한다. 다양한 행동 특징을 통해 본 논문에서 제시한 방법은 행동 분류 및 Fall Detection에서 잘 수행된다.
Algorithm of Fall and ADL Recognition
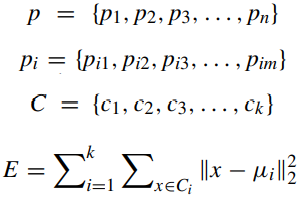
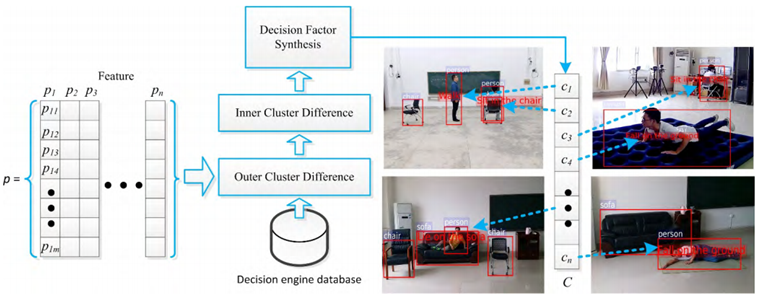
활동에서 추출한 특징과 Fall 활동 특성에 대한 타당성 분석을 기반으로 장면에 n명의 사람이 있다고 가정할 때 Fall을 구분하는 자동 엔진을 제안했다. p를 샘플 컬렉션으로 사용하고 각 샘플은 pi로 표현되는 m개의 특성을 가진다. 여기서 pij는 i번째 샘플의 j번째 특징을 나타낸다. n개의 샘플은 C로 표시되는 k개의 클래스로 나뉜다. k 클래스의 최소 제곱 오차는 아래 수식으로 표시된다. 여기서 µi는 ci의 평균 벡터다. µi는 내부 클래스 평균 벡터의 간결함을 나타낸다. E의 값이 작을수록 외부 클래스의 유사도가 높음을 의미한다.
Experiments
Qualitative Analysis

알고리즘의 성능을 테스트하기 위해 UR Fall Detection Dataset을 선택했다. 또한 HIKVISION DS2D3304IW-D4 웹캠을 사용하여 자체 데이터셋을 수집했다. 자체 수집한 데이터셋은 주로 걷기, 땅에 떨어지기, 소파나 의자와 같은 가구에 떨어지기, 앉기, 눕기, 곧 등 7가지 동작을 포함하고, 다양한 장면에서 200개의 비디오를 수집했다. 각 비디오에는 400~800개의 프레임이 포함되어 있다. 총 100개의 Fall 영상(바닥에 떨어지는 영상 50개, 가구에 떨어지는 영상 50개)과 총 100개의 Fall 방지 영상(걷는 영상 25개, 의자에 앉는 영상 25개, 소파에 앉는 영상 25개, 눕는 영상 25개)이 있다.
질적 분석은 필자의 실험에서 먼저 수행되었다. 사람만을 탐지하는 기존의 접근 방식과 달리 제안된 방법은 먼저 장면 분석에서 탐지된 인간과 가구 간의 공간적 관계를 결정한다. 결과는 그림과 같다. (a)와 (b)에서 볼 수 있듯, 소파에 눕는 것과 넘어지는 것을 분류하는데 좋은 성능을 보이지만, 기존의 다른 방법들은 조건에서 잘 작동하지 않아 오탐지와 오판정이 발생하였다. (c)와 (d)는 의자에 앉거나 넘어지는 행동을 구분하는 데 필자의 방법은 구별에 성공했다. 따라서 제안하는 방법은 다른 방법에 비해 Fall과 유사한 일부 행동과 가구에 떨어지는 것과 같은 특수한 Fall 행동을 구별하는 능력이 더 우수하다.
Quantitative Analysis
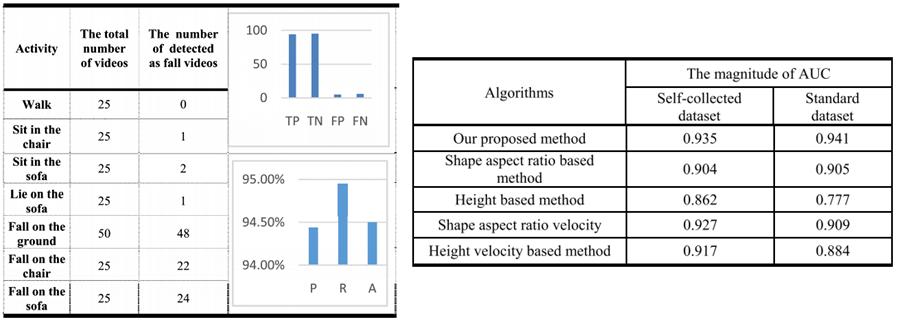
다음으로 양적 분석에 대한 실험 결과이다. 왼쪽의 표는 다양한 행동에 대한 실제 탐지 횟수를 기록한 것이다. 오른쪽 표에서 볼 수 있듯 모든 실험 결과는 필자의 방법이 훨씬 더 좋음을 보여준다.
