Automatic fall detection of human in video using combination of features

학부연구생으로 소속된 연구실에서 진행중인 Fall Detection을 위한 모델을 구현하기 위해 관련 논문을 읽고 이해한 부분에 대해 간단하게 정리하였다.
<논문 정보>
제목: Automatic fall detection of human in video using combination of features
게재일자: 2016
발행기관: IEEE
위 논문에서는 기존에 존재하는 기술들을 결합하여 새로운 기능을 제안한다. Histograms of Oriented Gradients(HOG), Local Binary Pattern(LBP) 그리고 딥러닝 프레임워크인 Caffe를 결합해 사람의 실루엣 영역을 나타내는 확장된 기능인 HLC를 제안하였다.
Introduction
Fall Detection을 위한 시스템은 상황 인식 시스템과 웨어러블 장치라는 두 가지 카테고리로 분류할 수 있다. 웨어러블 장치의 경우 사람이 착용해야하는 소형 전자 센서 장치를 기반으로 하는데, 사람들이 항상 디바이스 착용하는 것을 기억하기 어렵다는 한계가 존재한다. 그에 비해 상황 인식 시스템은 컴퓨터 비전 기술을 사용한 비디오 기반 시스템이 존재하여 비교적 실험이 용이하다는 장점이 존재하기 때문에 필자는 이 방법을 채택해 연구를 진행하였다.
Related Work
관련된 연구로는 단일 이미지에서 사람에 대한 바운딩 박스를 분석하는 것이 있는데, 이는 카메라와 사람의 상대적인 위치가 바뀌면 정확도가 크게 변동될 수 있고, 'Fall'과 'Fall과 유사한' 행동을 정확히 구분할 수 없다는 한계가 존재했다. 이 외에도 모양 기반 방법이 있는데, 사람의 width와 height의 비율을 사용해 Fall을 감지하는 방법이다. 배경을 빼서 피사체의 실루엣을 얻은 다음 이 실루엣 관련 특징들을 기반으로 Fall Detection을 수행하지만, 마찬가지로 앉거나 쪼그리고 앉는 것과 같은 일부 Fall과 유사한 행동을 여전히 Fall로 감지한다는 한계가 존재했다.
Approach
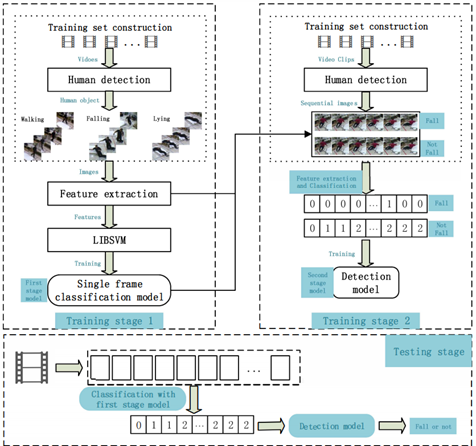
본 논문에서는 Fall Detection을 위해 2개의 low-level feature과 하나의 high-level feature를 사용했다. 그리고 2개의 training stage를 구성하여 결괒거으로 2개의 SVM model을 획득해냈다. 첫 번째 training stage에서는 비디오 시퀀스에서 training image를 추출하였는데, 여기서 training image는 걷기와 넘어지기, 눕기 총 3가지 범주가 존재한다. 이 training image에서 단일 프레임 분류 모델을 얻어냈다. 두 번째 tranining stage에서는 비디오 시퀀스의 연속 프레임 30개마다 예측을 입력으로 사용하여, 이를 기반으로 Fall Detection 모델을 얻어냈다.
Features extraction and combination
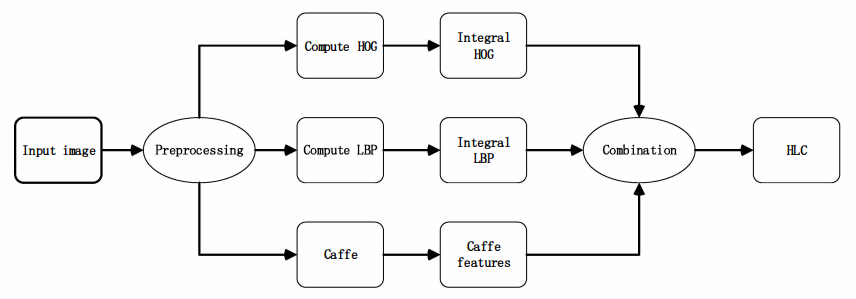
Fall action 분류 성능은 주로 분류기 입력 값의 품질에 따라 달라지기 때문에 Human objects의 특징은 Human Detection의 효과, 견고성의 핵심 요소를 담당한다. Human Detection을 위한 여러 특징 중 HOG, LBP는 이미지 분류 작업에서 잘 수행되긴 하지만, 저수준의 기능이고 보편적이지 않다는 단점이 존재하기 때문에 Fall Detection의 보편성과 성능 유지를 위해 3개의 기능을 결합한 증강 특징 벡터 HLC를 제안하였다. 위의 그림을 통해 그 절차를 확인할 수 있다.
먼저, HOG는 보행자 검출이나 사람의 형태에 대한 검출에 자주 사용된다. 영상의 지역적 gradient를 해당 영상의 특징으로 사용하는 방법이다. 주로 지역 수준 에지 기반 특징을 계산하는 데에 잘 알려진 방법이다. 로컬 이미지 영역의 에지 특징은 해당 영역에 있는 픽셀의 에지 정보를 이산값으로 양자화 하고, 양자화 된 값의 히스토그램에 누적하여 얻게 된다. 이 HOG는 Human Shape의 국부적인 변형에도 어느 정도 적응할 수 있다는 특징이 있다.
두 번째로 LBP의 경우, 이미지의 질감 표현 및 얼굴 인식 등에 활용되는 방법이다. 위 모델에서는 인체의 외양을 묘사하는데 사용된다. 이미지 영역은 해당 영역의 모든 픽셀에서 계산된 LBP의 히스토그램으로 인코딩된다. 위 방법은 조명 변화에 대한 견고성, 식별력 및 계산의 단순성으로 잘 알려져있다.
마지막으로 Caffe는 관심 데이터에서 high-level feature를 학습하고 더 나은 일반성을 제공하는 최첨단 딥러닝 프레임워크이다. Blob, Layer, Net의 구조로 구성되어 있다. 간략히 설명하면, Blob의 경우 Caffe에서 처리 및 전달되고 CPU와 GPU 사이의 동기화 기능을 제공하는 4차원 배열이다. Layer은 CNN을 통해 흔히 접해보았던 convolution, pooling과 같은 모델의 본질이자 계산의 기본 단위를 의미한다. Net 또한 흔히 접해보았듯, 디스크에서 로드되는 데이터 레이어로 시작해 loss 레이어로 끝나는 하나의 구조를 의미한다. 아래의 그림은 Caffe 네트워크의 MNIST 숫자 분류의 예시이다. 파란색 상자는 Layer, 노란색 팔각형은 레이어에 의해 생성되거나 레이어에 공급되는 데이터 Blob을 의미한다.

Fall Detection
SVM용 라이브러리인 LIBSVM은 사용자가 SVM을 어플리케이션에 쉽게 적용할 수 있도록 도와주는 간단하고 효율적인 도구이다. 본 논문에서 제안한 아키텍처에서는 단일 프레임 분류 모델과 Fall Detection 모델, 이렇게 두 가지 선형 SVM 모델을 훈련시킨다.
Experiments
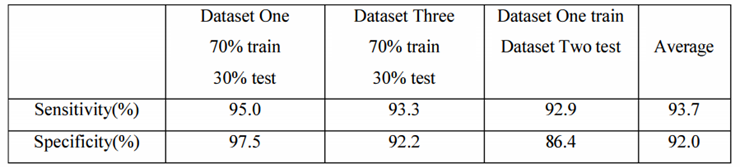
앞서 설명한 방식에 따라 Fall Detection의 train과 test가 구현되었다. 간략히 다시 요약해보면, 먼저 Human Detection and Extraction을 수행하고 Human Object를 담을 수 있는 새로운 이미지를 얻어냈다. 이후 이를 64 x 64 픽셀 해상도로 정규화하고, HLC를 얻어 이를 기반으로 예측된 라벨을 얻어내었다. 이 라벨을 분석하여 Fall Detection의 최종 결과를 구하였다.
위의 표는 실험 결과를 나타낸다. 첫 번째 실험의 경우, MCFD 데이터셋만을 사용하였고, 두 번째 실험은 필자가 직접 제작한 데이터셋만을 사용하여 실험을 진행하였다. 마지막 실험은 MCFD는 train 용으로, 나머지 데이터셋은 test 용으로 사용하였다. 세 번째 실험을 통해 필자의 접근 방식의 보편성을 어느 정도 입증할 수 있었다.
