데이터 분석 방법론

CRISP-DM
- Business Understanding
- 문제를 정의하고 요인을 파악하기 위해서 가설을 수립
- Data Understanding
- 가설에서 도출된 데이터 식별 및 취득
EDA와 CDA
- EDA(Exploratory Data Analysis) : 개별 데이터의 분포, 이상치 파악
- CDA(Confirmatory Data Analysis) : 통계적 분석 도구 사용
- Data Preparation
- 결측치 조치, 가변수화, 스케일링, 데이터 분할 등
- Modeling
- 주요 변수들을 선택하고, 적절한 알고리즘을 통해 예측 모델 생성
- 데이터로부터 패턴을 찾는 과정, 오차를 최소화 하는 패턴
- Evaluation
- 모델에 대한 목표 달성에 대한 평가
- Test Set 이용
- Deployment
- 데이터 수집부터 모델 배포 관리까지 파이프라인 구성
시각화 라이브러리 (matplotlib & seaborn)
많은 데이터들을 시각화, 수치화를 통해 한 눈에 파악하는 방법
비지니스의 인사이트를 파악하는 것이 목표
요약된 정보가 표현되기 때문에 정보의 손실이 발생한다
라이브러리 불러오기
import matplotlib.pyplot as plt
import seaborn as sns그래프 그리기
plt.plot(data['temp'])
# 그래프 출력
plt.show()제목 붙이기
plt.plot(data['x'], data['y'])
# x축의 값을 조정 (rotation = 각도)
plt.xticks(rotation = 30)
# 각 축에 레이블 출력
plt.xlabel('x')
plt.ylabel('y')
# 그래프 타이틀 출력
plt.title('Graph')
plt.show()라인 스타일 조정
plt.plot(data['x'], data['y’],
color='green’,
linestyle='dotted’,
marker='o')
plt.show()
color = 'red', 'green', 'blue', 'r', 'g', 'b' 등
linestyle = 'solid', 'dashed', 'dashdot', '-', '--', '-.' 등
marker = '.', ',', 'o', 'v', 등
참고 : https://matplotlib.org/2.1.2/api/_as_gen/matplotlib.pyplot.plot.html
여러 그래프 그리기
plt.plot(data['Date'], data['Ozone’]
, marker='o')
plt.plot(data['Date'], data['Temp’]
, marker='s')
plt.legend()
plt.grid()
plt.show()차트를 겹쳐서 표현 가능
legend()를 통해 범례 출력
gird()를 통해 그리드 출력
데이터프레임.plot()
df.plot(x = 'x', y = ['y1','y2']
, title = 'Graph’)
plt.show()데이터프레임.plot() 함수를 사용하면 순쉽게 차트를 그릴 수 있다
plt.plot()를 그릴 때 지정해야 하는 설정이 기본적으로 제공
추가적인 옵션을 지정할 수 있다
참고 : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.plot.html
숫자형 변수 분석
숫자로 요약하기
- 평균 : 산술 평균, 기하 평균, 조화 평균 등
- 중위수 : 자료의 순서상 가운데 위치한 값
- 최빈값 : 자료 중에서 가장 빈번한 값
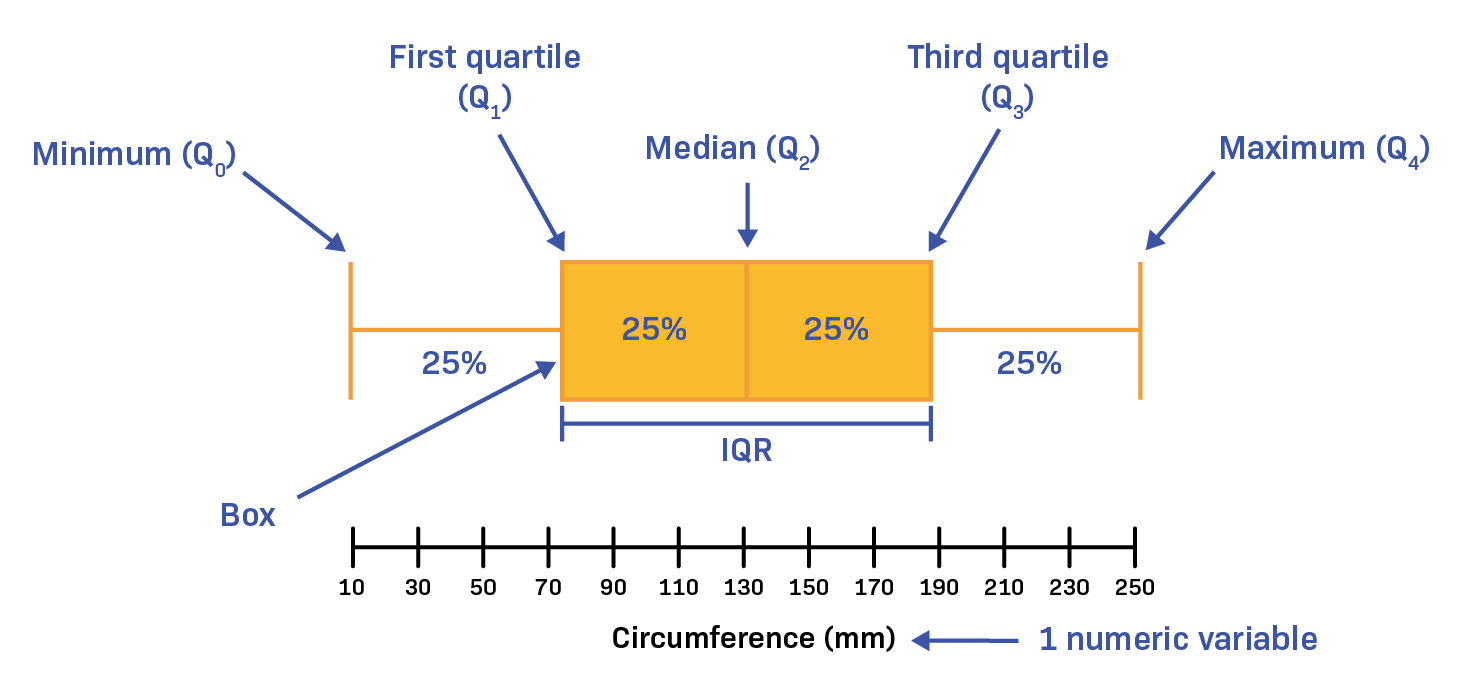
- 사분위수 : 데이터를 4등분하고, 각 경계에 해당하는 값(25%, 50%, 75%)
# 넘파이 함수 이용
np.mean(data['변수'])
np.median(data['변수'])
np.mode(data['변수'])
# 판다스의 메소드 이용
data['변수'].mead()
data['변수'].mdian()
data['변수'].mode()df.describe() : 데이터 프레임의 숫자형 변수들에 대해 기초 통계량 출력
data.describe()숫자형 변수 시각화
- Histgram
plt.hist(data.변수, bins = 30
, edgecolor = 'gray')
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.show()bins : 구간 수
- Density Plot (KDE Plot)
sns.kdeplot(data['변수'])
plt.show()밀도함수 그래프 출력
- Box Plot
plt.boxplot(data['변수'], vert = False)
plt.grid()
plt.show()plt.boxplot()은 반드시 NaN을 제외 (sns에서는 자동으로 제외)
vert 옵션으로 가로(False) 세로(True)로 그래프를 그릴 수 있음
범주형 변수 분석
범주별 빈도수
data['변수'].value_counts()
범주별 비율
data['변수'].value_counts() / data.shape[0]범주형 변수 시각화
sns.countplot(titanic['data['변수']'])
plt.grid()
plt.show()범주별 빈도수를 계산하고 bar plot으로 나타냄
데이터 전처리
전처리 3가지 요건
- 모든 셀에 값이 있어야 한다.
- 모든 값은 숫자여야 한다.
- (옵션) 값의 범위를 일치시켜야 한다.
결측치 처리
- 결측치 제거
df.dropna(inplace=True)결측치가 포함된 행 제거
- 결측치 채우기
df.fillna(value=None, method=None, axis=None, inplace=False,)value : 결측치를 채울 값을 설정
method : 결측치를 채울 방식 설정('ffill', 'bfill'... 등)
참고 : https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html
추정해서 채우기
- knnimputer()를 사용하거나 예측해서 적절한 값을 채우는 방식 사용
가변수화
컴퓨터가 이해할 수 있도록 범주형 데이터를 숫자려 변환
이를 가변수화 혹은 One-Hot-Encoding라고 함
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
X_train = encoder.fit_transform(X_train)
X_test = encoder.transform(X_test)스케일링
거리를 계산하는 알고리즘(KNN, SVM, K-mearns등)
범위가 큰 변수가 거리에 영향을 미치기 때문에 값의 범위를 조절한다
- Normalization(정규화)
- 모든 값의 범위를 0~1로 변환
- Standardization(표준화)
- 모든 값을 평균 = 0, 표준편차 = 1로 변환