
전반적인 느낀 점 : 반복 재생되는 쇼츠나 릴스 같은 콘텐츠가 많아지면서, 끊김없이 자연스럽게 이어지는 배경음악에 관심이 생겨 이 논문을 읽게 되었습니다. LoopGen은 학습 없이도 루프 가능한 음악을 생성할 수 있는 training-free 방식을 제안하며, circular padding과 beat alignment를 통해 루프 경계의 부자연스러움을 해결합니다. 실제 데모를 들어보면 전환이 꽤 자연스러운 것 같습니다.
아래는 논문을 간단히 요약한 내용입니다.
This post was written with the help of ChatGPT to better understand and summarize the paper😊
📄 Paper Info
- Title: LoopGen: Training-Free Loopable Music Generation
- Authors: Davide Marincione, Giorgio Strano, Donato Crisostomi, Roberto Ribuoli, Emanuele Rodolà
- Affiliation: Sapienza University of Rome
- Conference: ___
- Keywords: Loopable Music, Non-Autoregressive Transformer, MAGNeT, Seam Perplexity, Music Generation
⭐ 요약 TL;DR
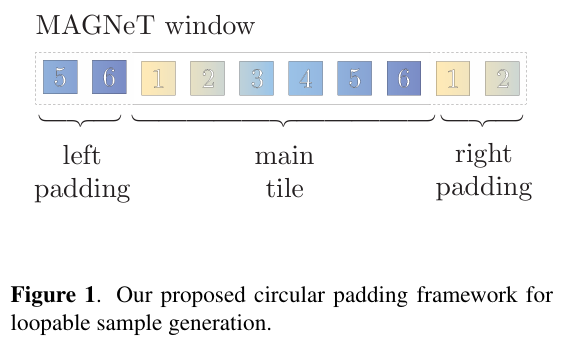
반복 재생되는 음악에서 전환의 부자연스러움을 해결하기 위해, circular padding과 beat alignment를 활용한 training-free 루프 생성 방식인 LoopGen을 제안
최근 쇼츠, 릴스, 게임 사운드 등에서 끊김 없는 반복 음악이 필요한 경우가 많아지고 있지만, 기존 오디오 생성 모델은 반복 재생 시 전환 경계의 이질감으로 루프 음악 생성에 적합하지 않았습니다.
이를 해결하기 위해 LoopGen은 별도의 학습 없이도 자연스러운 루프를 생성할 수 있는 추론 기반(training-free) 접근을 제안합니다.
→ 중앙 루프 구간을 기준으로 앞뒤에 일부를 복제하는 Circular Padding과, 일정한 박자 단위로 길이를 조정하는 Beat Alignment Algorithm을 통해
시작과 끝이 부드럽게 이어지고 음악적으로 구조화된 루프 생성이 가능해집니다.
특히 MAGNeT의 비자기회귀(bidirectional NAR) 구조를 활용해 루프 경계를 동시에 참조하며 자연스러운 전환을 구현했습니다.
🎯 Main Problem and Key Approach
- Circular Padding 기법 도입 → 생성 시 오디오 시작/끝을 함께 참고
- MAGNeT 기반의 비자기회귀 모델 사용
- Beat Alignment → 생성된 루프가 마디(bar) 기준으로 자연스럽게 반복되도록 길이 조절
🧠 Architecture & Mehod
-
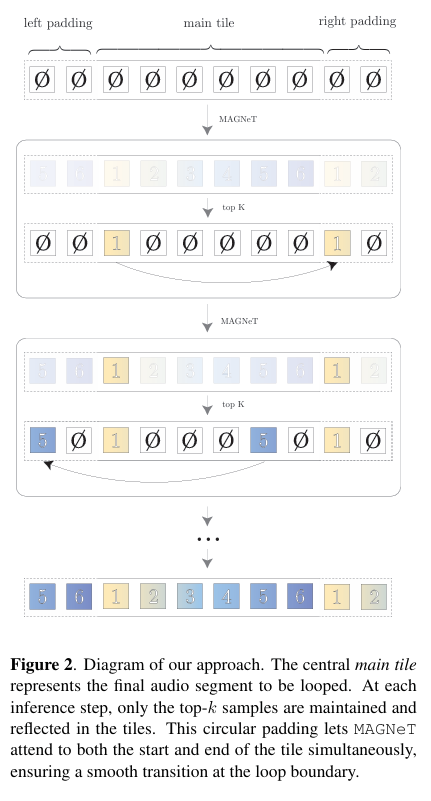
Circular Tiling with MAGNeT
- Loop 타일을 중심으로 좌우에 시작/끝 부분을 복사하여 MAGNeT이 양쪽 경계를 동시에 참고하며 생성.
- 이로써 루프 시작과 끝 사이의 자연스러운 연결이 가능해짐.
-
Signature-aware Length Control
- 음악적으로 자연스러운 루프를 위해 박자(beat)와 마디(bar)에 맞춘 길이 제어 알고리즘을 제안.
-
추론 과정 요약
-
중앙 루프 타일 설정: 생성 창에서 루프가 될 중심 구간 지정
-
Circular Padding:
루프 타일의 끝 → 왼쪽, 시작 → 오른쪽에 복사
양방향 attention으로 MAGNeT이 루프 경계를 동시에 인식 -
반복 생성:
MAGNeT으로 생성 → 확률 높은 토큰만 고정
남은 영역은 비우고 다음 iteration으로 반복 -
완성된 루프 추출: 루프 타일 구간만 잘라내 최종 루프 클립으로 사용
-
🎧 Dataset & Evaluation
-
Text Prompt 기반 생성 (총 100개 프롬프트 사용)
-
평가 지표:
- FAD (Fréchet Audio Distance) ↓
- Seam Perplexity ↓
→ 루프 경계의 부자연스러움을 정량적으로 측정 - Blind Listening Test (Likert Scale)
📊 Results
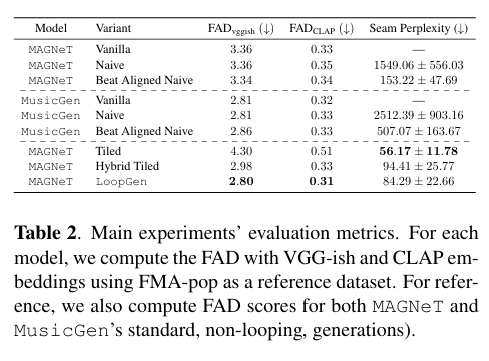
- FAD (lower is better): LoopGen 이 가장 작음.
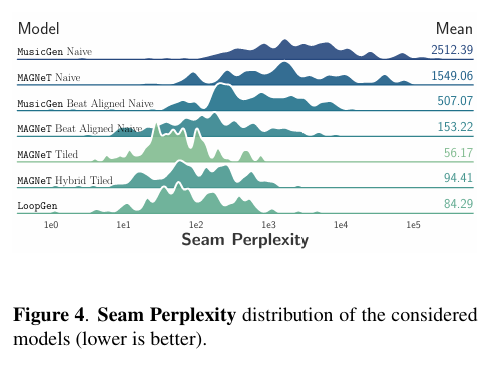
- Seam Perplexity (lower is better): LoopGen 이 가장 작음.
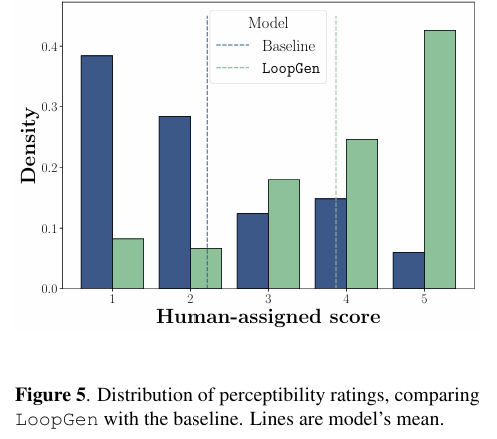
- 블라인드 청취 실험: LoopGen > MAGNeT Hybrid Naive (w/o Tiling-generation)
🔗 Resources
+) 🔍 Related work
1. Transformer 계열 음악 생성 모델
예: MuseNet, Jukebox, 그리고 MusicGen 계열 (MusicGen은 “Transformer + audio tokenizer” 기반)
구조와 작동 방식
- 일반적으로 autoregressive Transformer 구조를 사용해서, 과거 토큰(음악 노트, 또는 오디오 토크 등)을 입력으로 받아 다음 토큰을 예측하는 방식
- 긴 시퀀스의 종속성(long-range dependency)을 캡처하는 데 유리 (attention이 모든 이전 위치를 참조 가능)
- 텍스트, 스타일, 멜로디 등의 조건을 추가 입력(input embedding 또는 조건 토큰)으로 삽입 가능
장점
- 음악의 구조적 일관성 (예: 멜로디, 화성 진행 패턴 등)을 잘 유지할 가능성
- 다양한 조건 (예: 텍스트 프롬프트, 스타일, 장르)을 모델에 쉽게 통합할 수 있음
- Transformer가 이미 자연어 쪽에서 강점을 보여 왔기 때문에, 동일한 아키텍처적 이점을 음악 생성에도 적용 가능
단점 / 한계
- 속도 문제: autoregressive 방식은 한 토큰씩 순차적으로 생성해야 하므로 긴 오디오·음악 생성에는 시간이 많이 걸림
- 전환 경계 처리의 어려움: 루프(loop) 같은 반복 구조를 고려한 연결성을 직접 반영하기는 어려움
- 대규모 학습 데이터와 계산 자원이 필요
예를 들어, MuseNet은 MIDI 형식의 데이터를 학습해 여러 악기를 조합한 음악을 생성할 수 있는 모델이고, Transformer를 기반으로 이전 토큰 예측 방식으로 작동합니다.
Jukebox는 오디오 파형까지 생성 가능한 모델로, 조건 (장르, 가사, 아티스트 등) 기반 음악 생성을 목표로 하지만, 큰 구조 반복성이나 루프 전환 연결성 문제는 여전히 도전 과제로 남아 있습니다.
2. Diffusion 모델 기반 음악 / 오디오 생성
예: AudioLDM, Moûsai, Riffusion
구조와 작동 방식
- Diffusion 모델은 일반적으로 노이즈 상태 → 점진적 정제 (denoising 과정) 과정을 거쳐 목표 오디오를 생성
- 특히 Latent Diffusion Model (LDM) 방식: 오디오 신호를 직접 다루기보다는, 오디오를 잠재 공간(latent space)으로 압축한 뒤 그 공간에서 diffusion 과정을 수행 → 다시 오디오 공간으로 복원
- 텍스트 조건(token embedding이나 CLAP embedding 등)을 조건으로 삽입하여 텍스트-오디오 연관을 학습
예: AudioLDM
- CLAP (contrastive language–audio pretraining) 임베딩을 사용하여 텍스트와 오디오 정보를 함께 표현
- 오디오를 mel-spectrogram + VAE 등의 인코더/디코더 체계를 통해 latent 공간으로 매핑
- latent 공간에서 diffusion 과정을 거쳐 생성하고, 이후 vocoder나 디코더로 오디오 복원
장점
- 고품질 생성: 노이즈 정제 방식이 복잡한 음향 구조도 깨끗하게 생성할 수 있는 장점
- 텍스트-오디오 조건 통합이 유연: 텍스트와 오디오 임베딩을 함께 매핑 가능
- 잠재 공간에서의 작동 덕분에 원시 오디오에 비해 계산 부담이 줄어들 가능
단점 / 한계
- 생성 속도: diffusion 모델은 여러 스텝 (수십 ~ 수백 단계)의 반복 정제 과정을 거쳐야 함 → 시간이 많이 걸림
- 루프 경계 처리 미고려: 반복 가능한 구조를 명시적으로 보장하지 않음
- 복원 오차: latent → 오디오 공간 복원 시 디코더/버코더의 한계로 인해 세밀한 디테일 손실 가능
3. 비자기회귀 (Non-Autoregressive) 모델
예: MAGNeT, VampNet, SoundStorm
구조와 작동 방식
- Masked generative modeling 방식: 일정 부분을 마스킹(mask)하고, 마스크된 부분을 동시에 또는 점진적으로 예측
- 비자기회귀 방식을 채택해 전체 시퀀스를 병렬로 예측하거나 일부 병렬 처리를 허용
- Transformer 구조이지만, autoregressive 제약을 벗어나 속도와 병렬성을 확보
예: MAGNeT
- 하나의 non-autoregressive Transformer로 여러 오디오 토큰 코드를 동시에 생성
- masking scheduler를 통해 마스크를 점점 줄여가며 완성하는 방식
- inference 단계에서는 점진적 Decoding step을 통해 마스크된 토큰을 채워 나감
장점
- 생성 속도 우수: 병렬 처리 가능 → 오디오나 음악 생성 속도를 크게 줄일 수 있음
- 구조적 유연성: 비자기회귀 구조 덕분에 미래 부분과 과거 부분을 동시에 참조할 수 있는 attention 구조 가능
- 반복 구조(loop)의 경계 연결성에도 유리할 수 있음
- 조건 입력을 다양하게 결합하기 유리
단점 / 한계
- 모델이 복잡한 패턴을 예측하는 데 어려움이 있을 수 있음 (autogressive 모델만큼 세밀한 조정이 힘들 수 있음)
- 마스킹 스케줄, decoding 전략 설계가 중요하고 복잡
- 일부 조건에서는 품질 저하 가능성
VampNet, SoundStorm 등도 비자기회귀 접근을 활용해 음악 또는 오디오 생성 속도를 개선하려는 시도들이며, 반복 구조나 경계 연결성 측면에서 더 유리한 특성을 가질 수 있습니다.
4. 기존 루프 생성 모델
예: LoopNet 및 MIDI 기반 루프 생성
구조와 특징
- LoopNet: 루프 생성에 특화된 모델로, 주로 루프 오디오 데이터셋을 이용해 반복 가능한 패턴을 학습
- MIDI 기반 루프 모델: MIDI 데이터 (심볼릭 음표/박자 정보) 위주로 루프를 생성하고, 필요시 이를 오디오로 합성
장점
- 루프 중심의 데이터에 특화되어 있음 → 반복 구조 학습에 강점
- MIDI 형식이면 구조적 음악 패턴 제어가 직관적 (박자, 화음, 반복 패턴 등)
단점 / 한계
- 데이터 제약성: 루프 오디오 전용 데이터셋에만 의존할 경우, 범용성 낮음
- 오디오 품질 / 디테일 부족: MIDI 기반 생성은 오디오 단계 합성(악기 음색 등)에서 손실 또는 단순화가 발생하기 쉬움
- 텍스트 조건 통합 어려움: 자연어 쿼리 기반 루프 생성에는 한계
5. LoopGen의 차별점
- LoopGen은 MAGNeT 기반의 비자기회귀 구조를 활용하면서, 추론(inference) 단계에서만 구조 변경 (circular padding, beat alignment 등)으로 루프 가능성을 부여
- 즉, 추가 학습 없이도 루프 가능한 오디오를 생성할 수 있게 설계됨
- 루프의 경계(start-end)가 자연스러워야 하므로, 생성 시 시작/끝 부분을 함께 고려하는 방식이 핵심
- 반복 구조가 중요한 응용(배경음악, 게임음악 등)에 실용성을 지님
