[Paper Review] – FlowSep: Fast and Accurate Language-Queried Sound Separation via Rectified Flow Matching
Speech & Audio
전반적인 느낀 점 : 방법론 자체는 Flow Matching 모델에 text embedding을 조건으로 넣은 구조로, 새롭지는 않지만 코드가 공개되어 있어 관련 연구나 실험에 활용하기 좋을 것 같습니다.
아래는 논문을 간단히 요약한 내용입니다.
This post was written with the help of ChatGPT to better understand and summarize the paper😊
📄 Paper Info
-
Title: FlowSep: Language-Queried Sound Separation with Rectified Flow Matching
-
Authors: Yi Yuan, Xubo Liu, Haohe Liu, Mark D. Plumbley, Wenwu Wang
-
Affiliation: CVSSP, University of Surrey, UK
-
Conference: ICASSP 2025
-
Keywords: Language-Queried Audio Source Separation, Rectified Flow Matching, Audio Generation, VAE, BigVGAN, Multimodal
⭐ 요약 TL;DR

기존 마스킹 기반 오디오 분리 모델의 한계를 넘어서기 위해, Rectified Flow Matching 기반의 생성 모델 FlowSep을 제안 — 빠르고 정확하며 자연어 쿼리로 원하는 소리를 분리 가능!
이 논문은 하나의 오디오에 여러 소리가 섞여 있을 때, 예를 들어 "사람 말소리만 들려줘" 같은 문장을 입력하면 그 소리만 뽑아서 들려주는 인공지능 모델인 FlowSep을 제안합니다.
기존에는 소리의 스펙트로그램을 부분적으로 가려서 필요한 소리를 분리했지만, 이런 방식은 소리들이 겹치거나 복잡할 때 품질이 떨어지고, 소리가 찢어지거나 일부만 들리는 문제가 있었어요.
FlowSep은 이런 한계를 극복하기 위해 Rectified Flow Matching(RFM)이라는 새로운 생성 방식(generative method)을 사용합니다. 이 방법은 노이즈에서 시작해 원하는 소리 특징으로 가는 선형 경로를 학습해서, 빠르고 자연스럽게 소리를 생성해냅니다. 그 결과, 이전 모델들보다 더 좋은 품질로, 더 빠르게, 그리고 새로운 상황에서도 잘 작동하는 소리 분리가 가능해졌습니다.
🎯 Main Problem and Key Approach
- LASS (Language-Queried Audio Source Separation) 문제 해결
- 기존 마스킹 방식 대신, RFM 기반 생성 모델 사용
- 노이즈 → 타겟 오디오 특징으로 가는 선형 경로 학습
- 텍스트 쿼리(FLAN-T5)와 혼합 오디오를 조건으로 활용
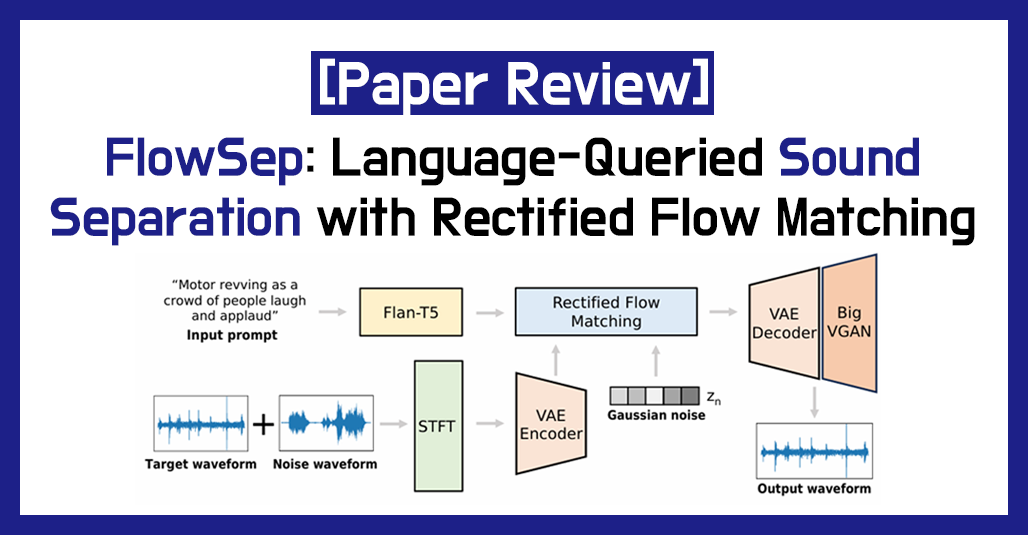
🧠 Architecture & Mehod
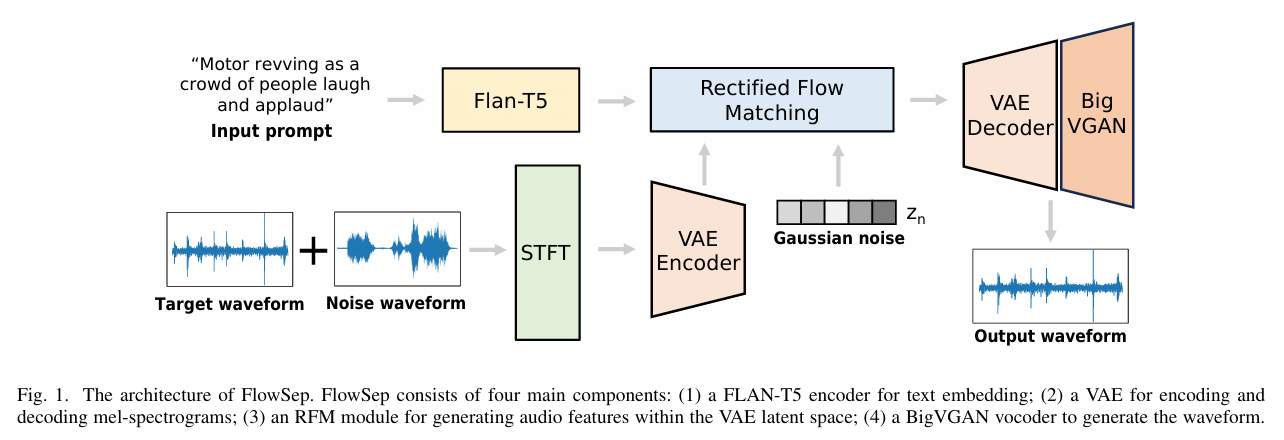
1. Text Encoder
- 기존 AudioSep에서 사용한 CLAP 대신, FLAN-T5를 사용하여 쿼리 텍스트 임베딩.
- 오디오 합성 분야에서 FLAN-T5가 더 나은 성능을 보였기 때문.
2. Latent Feature Generator
A. Rectified Flow Matching (RFM)
- RFM은 일반적인 diffusion model처럼 데이터를 점진적으로 정제하는 대신, 노이즈 → 타겟 오디오 간 선형 경로(linear path)를 학습합니다.
- 훈련과정
- 선형 혼합 방식으로 중간 노이즈 벡터
z_t를 생성 - 목표는 벡터 필드
mu(z_t, E, z_m)가z_1로 향하는 최적 경로를 예측하도록 학습하는 것
- 선형 혼합 방식으로 중간 노이즈 벡터
- 손실 함수
B. Channel-Conditioned Generation
- 혼합 오디오의 mel-spectrogram을 조건 채널로 사용하여 RFM 입력에 포함시킵니다.
- 즉,
z_t와z_m을 채널 방향으로 concat하여, RFM이 조건부 생성이 가능하도록 합니다.
3. VAE & GAN Vocoder
- VAE는 mel-spectrogram을 잠재 공간으로 압축 및 복원.
- BigVGAN vocoder를 이용하여 mel-spectrogram을 최종 waveform으로 변환.
🎧 Dataset & Evaluation
Training Set
- 총 1,680 시간의 오디오: AudioCaps, VGGSound, WavCaps 사용.
- 다양한 캡션/레이블 형식의 멀티모달 오디오.
Test Set
- 5개의 벤치마크 데이터셋:
- AudioCaps (AC), VGGSound, ESC50
- DCASE2024 Task 9의 DE-S (합성), DE-R (실제)
| 약어 | 전체 이름 | 설명 |
|---|---|---|
| AC | AudioCaps | 실제 오디오에 사람이 작성한 자연어 설명이 달린 데이터셋. 예: "a man is playing piano" 다양한 일상 소리 포함 (928개 테스트 샘플 사용) |
| DE-S | DCASE-Synthetic | DCASE 2024의 합성 테스트 세트. 두 개 이상의 소리를 섞어서 만듦 SNR: -15dB ~ 15dB |
| DE-R | DCASE-Real | DCASE 2024의 실제 환경 녹음 데이터셋. 실제 환경에서 녹음된 소리 각 소리에 텍스트 쿼리로 주석이 달림 |
| VGG | VGGSound | 유튜브 영상 기반의 대규모 오디오 데이터셋. 309개의 사전 정의된 라벨 포함 테스트에 200개 샘플 사용 |
| ESC | ESC-50 | 환경 소리 분류용 공개 데이터셋. 동물, 자연, 기계, 인간 활동 등 50개 클래스 포함 2,000개 테스트 샘플 사용 (SNR 0dB) |
Evaluation Metrics
기존 SDR 등의 정렬 기반 지표보다 생성 품질 평가에 적합한 지표 사용
- FAD (Fréchet Audio Distance) ↓
- CLAPScore, CLAPScoreA ↑
- REL, OVL: 주관적 평가 (Likert Scale)
📊 Results
Objective Evaluation
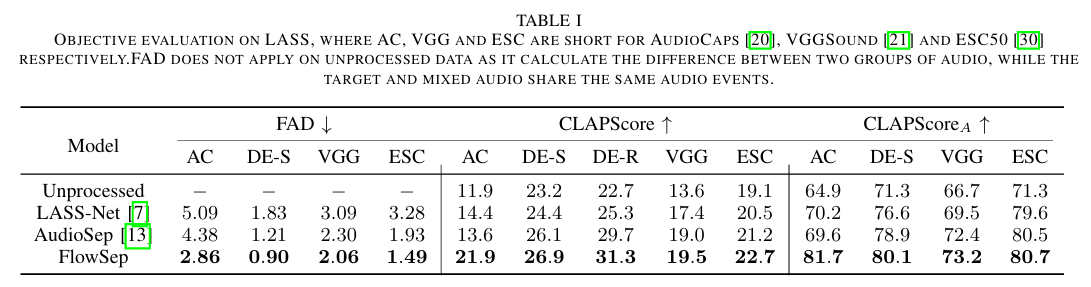
- FAD (Fréchet Audio Distance): 낮을수록 원본에 가까운 자연스러운 오디오
- CLAPScore: 분리된 오디오가 쿼리 텍스트와 얼마나 잘 맞는지 측정
- CLAPScoreA: 분리된 오디오가 타겟 오디오와 얼마나 비슷한지 측정
➡ FlowSep은 모든 지표에서 기존 모델보다 우수한 품질을 보임
Subjective Evaluation
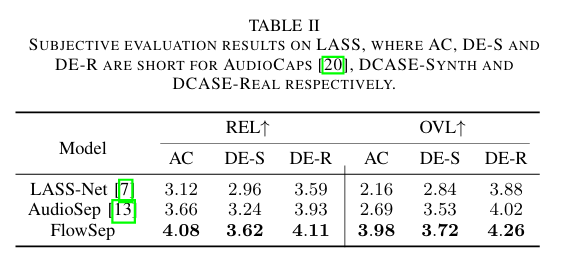
- REL: 텍스트 쿼리에 얼마나 잘 맞는지 (1~5점 척도)
- OVL: 들었을 때 오디오가 얼마나 자연스럽고 좋게 느껴지는지 (1~5점)
➡ FlowSep이 사용자 평가에서도 가장 높은 점수를 받음
Efficiency
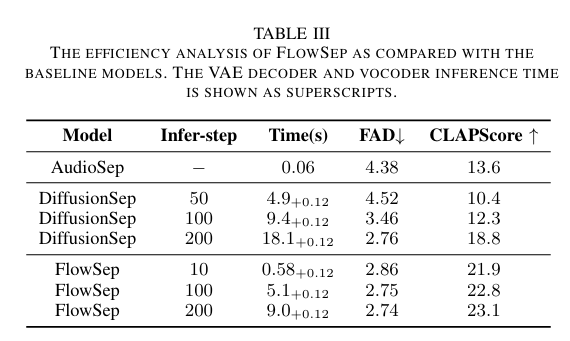
➡ FlowSep은 단 10단계로도 Diffusion 200단계보다 더 나은 성능
➡ 빠르고 경량화된 시스템에서도 고품질 오디오 분리 가능
🔗 Resources
