https://arxiv.org/pdf/2509.23630v1
요약
- 게임처럼 특수 환경을 위한 연구
- GO-AEC는 여러 개의 ASR 시스템(Tencent, Alibaba, ByteDance)에서 출력된 N-best 후보 문장들을 수집한 뒤,
- 이 후보 문장들을 게임 상황 정보 및 동적 지식베이스(RAG)와 함께 prompt로 구성합니다.
- 그런 다음, 게임 도메인에 특화되어 supervised fine-tuning된 LLM (Qwen2.5-1.5B)이 이 prompt를 기반으로 최종 교정된 문장을 생성합니다.
Paper Info
- Title: Game-Oriented ASR Error Correction via
RAG-Enhanced LLM - Authors: Yan Jiang, Yongle Luo, Qixian Zhou, Elvis S. Liu
- Affiliation: Tencent Games
- Conference: ___
- Keywords: ASR Error Correction, Large Language Models (LLMs), Retrieval-Augmented Generation (RAG), Data Augmentation, Game-specific Speech Recognition, Supervised Fine-Tuning (SFT), N-best Hypotheses, Domain Adaptation
요약 TL;DR
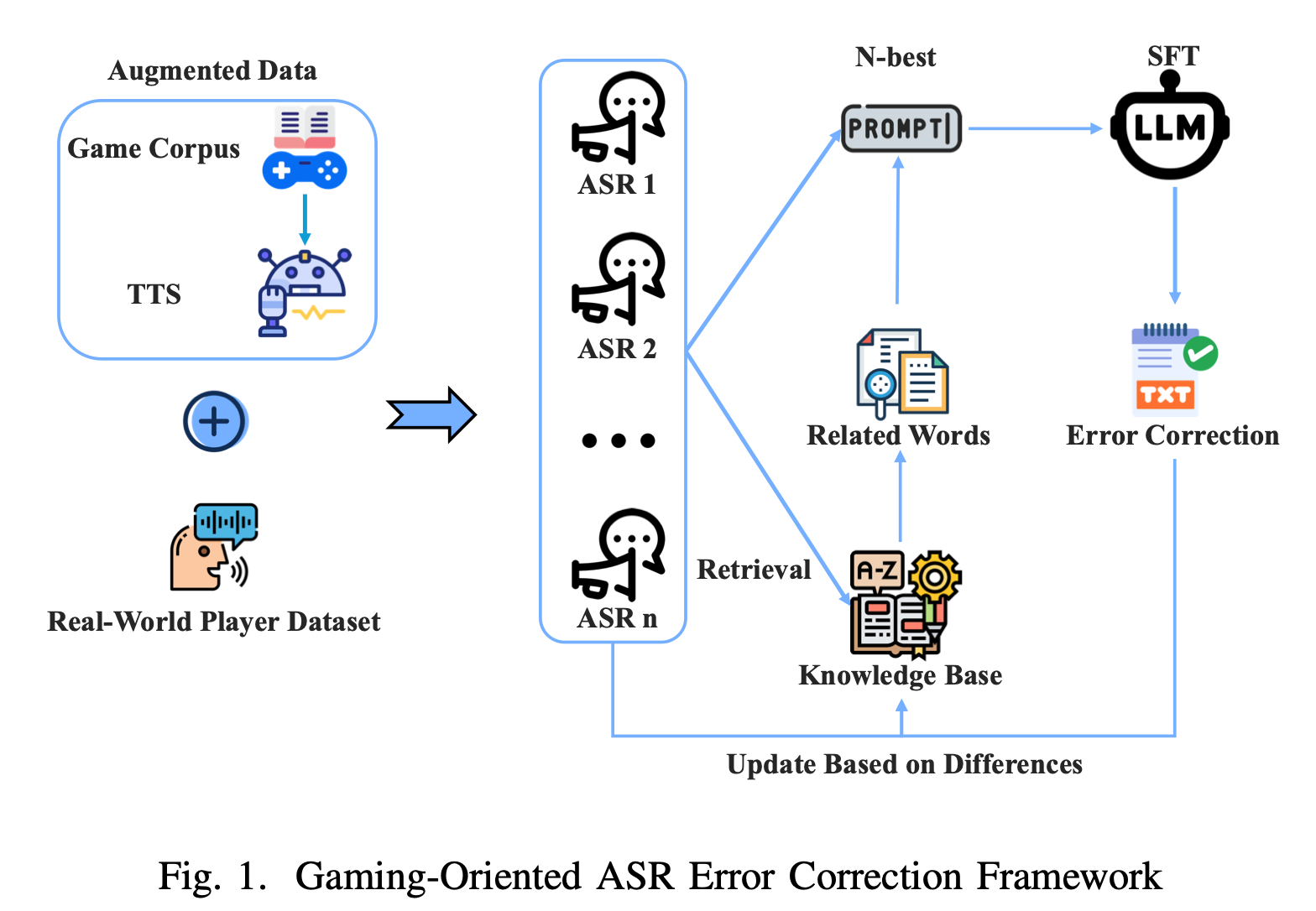
게임 환경에서 음성 인식(ASR)이 자주 오류를 내는 문제를 해결하기 위해, 대형 언어 모델(LLM)과 RAG(Retrieval-Augmented Generation)을 결합한 GO-AEC 프레임워크를 제안
요즘 온라인 게임에서는 실시간 음성 채팅이 전략과 협동의 핵심입니다. 하지만 문제는, 기존의 자동 음성 인식(ASR) 시스템이 게임 환경에 잘 맞지 않는다는 점입니다.
짧고 빠른 말, 게임에서만 쓰는 용어, 그리고 총소리나 발소리 같은 배경 소음 때문에 인식 오류가 잦고, 그 결과 대화의 흐름이나 의사전달에 방해가 생깁니다.
게다가, 게임 장르마다 언어 스타일이 다르고, 관련 음성 데이터를 충분히 확보하기도 어려워서 기존 ASR 모델을 그대로 쓰기엔 한계가 많습니다.
-->
이 논문에서는 이러한 문제를 해결하기 위해 GO-AEC (Gaming-Oriented ASR Error Correction)라는 새로운 프레임워크를 제안합니다. 핵심은 단순한 음성 인식이 아니라, 이미 인식된 결과(N-best 후보)를 기반으로 더 정확하고 자연스러운 문장을 다시 만들어내는 것입니다.
Main Problem and Key Approach
GO-AEC는 크게 세 가지 요소로 구성됩니다:
1. 데이터 증강 (Data Augmentation)
게임 대사에 특화된 텍스트를 기반으로, TTS(Text-to-Speech) 기술과 LLM(Large Language Model)을 활용해 다양한 음성 데이터를 가상으로 생성합니다. 다양한 발음, 억양, 소음 조건까지 반영해 실제 게임 상황과 유사한 학습 데이터를 확보합니다.
2. N-best 후보 기반 교정 (N-best Hypothesis Correction)
하나의 음성에 대해 여러 ASR 시스템이 출력한 문장 후보들을 LLM이 비교 분석하여, 가장 의미 있고 자연스러운 문장을 선택합니다. 이때 게임 배경 정보도 함께 참고합니다.

3. RAG 기반 동적 지식베이스 (Retrieval-Augmented Generation)
최신 게임 용어나 자주 발생하는 오인식 패턴을 담은 지식베이스(knowledge base)를 실시간으로 검색해 교정에 반영합니다. 새로운 단어나 표현이 등장하더라도 즉시 대응할 수 있는 구조입니다.
Dataset & Evaluation
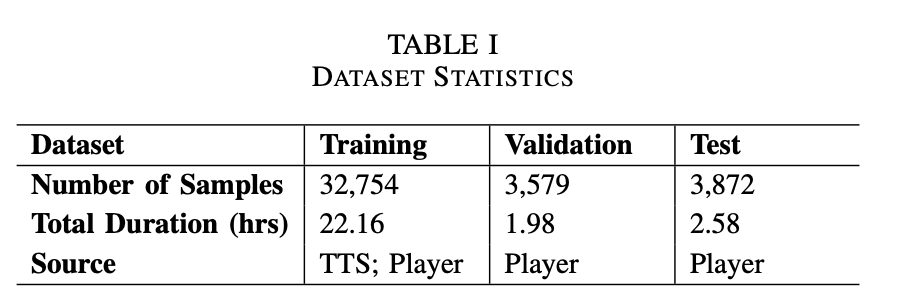
GO-AEC 모델이 실제로 효과가 있는지 확인하려면, 게임 상황을 잘 반영한 음성 데이터를 가지고 테스트해야 합니다.
그래서 연구진은 두 가지 데이터를 합쳐서 만든 ‘하이브리드 데이터셋’을 구성했습니다
① 합성 음성 데이터 (TTS로 만든 가짜지만 리얼한 음성)
- 중국 FPS 게임 Arena Breakout에 나오는 실제 전략 대사(예: “후퇴해”, “정찰해”, “공격해”, “보급품 챙겨”)들을 바탕으로 텍스트를 만들고,
- 이를 TTS(Text-to-Speech) 기술로 음성으로 변환했습니다.
- 목소리의 억양, 속도, 발음, 그리고 총소리나 발소리 같은 배경 소음을 다양하게 조합해서, 실제 게임처럼 들리는 음성 데이터를 만들어낸 거죠.
② 실제 플레이어 음성 데이터 (게임 테스트 중 녹음한 진짜 음성)
- 실제 플레이어들이 게임을 하면서 말한 진짜 전술 대화를 녹음했습니다.
- 이 녹음에는 총소리, 주변 소음, 마이크 잡음, 말이 겹치는 상황까지 다 포함되어 있어요.
- 연구진은 이 음성들을 일일이 직접 듣고 정확하게 받아적어, 모델을 훈련시키는 데 쓸 수 있도록 준비했습니다.
그리고 이를 평가하기 위해 다음의 평가 방식을 활용했습니다.
① CER (Character Error Rate, 문자 오류율)
- 말 그대로, 전체 글자 중에서 틀린 글자의 비율입니다.
- CER = (바꾼 글자 수 + 빠진 글자 수 + 잘못 추가된 글자 수) / 전체 글자 수 × 100
② SER (Sentence Error Rate, 문장 오류율)
- 이건 좀 더 까다로운 기준입니다.
- 문장 안에 글자 오류가 하나라도 있으면 그 문장은 오류로 간주합니다.
- 특히 게임처럼 명령이 빠르고 간결한 상황에서는 한 글자만 틀려도 전혀 다른 의미가 될 수 있기 때문에, SER이 중요한 지표가 됩니다.
- SER = 오류가 있는 문장 수 / 전체 문장 수 × 100
Results
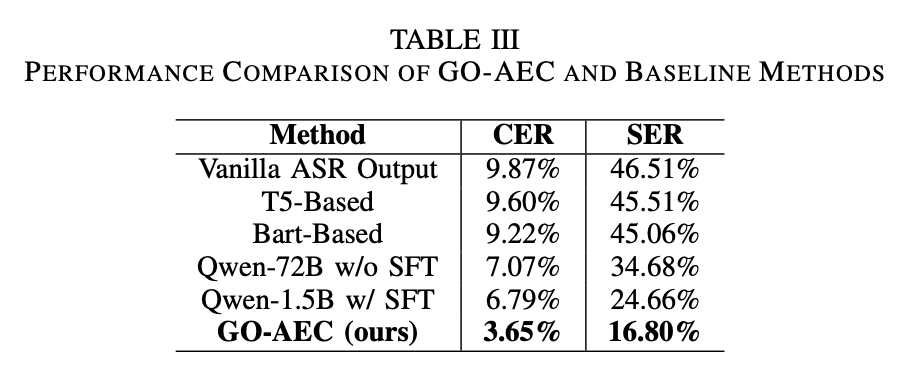
베이스라인 모델로 Qwen2.5-1.5B 모델 선택하였습니다.
→ 비교적 가볍고 빠르면서도 성능이 좋은 모델을 선택해 실시간 게임 환경에도 적합
GO-AEC는 모든 방법 중 가장 낮은 CER, SER을 보였습니다.
→ SFT(supervised fine-tuning) + RAG + N-best
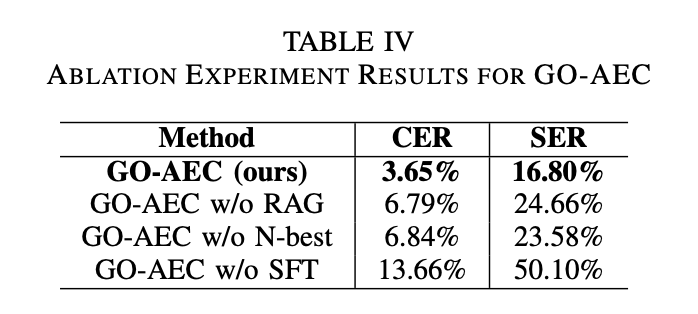
ablation 표를 보면 SFT가 없을 때 가장 크게 성능저하가 됩니다.
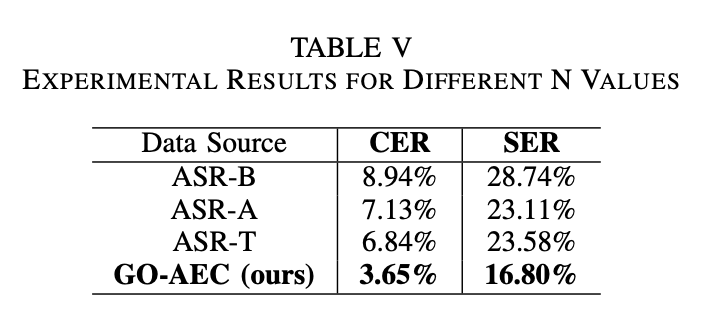
N-best 후보 사용
→ 하나의 음성 입력에 대해 ByteDance, Alibaba, Tencent 등 여러 ASR 서비스가 내놓은 서로 다른 인식 결과들을 모두 받아서,
→ 그 중 가장 정확한 문장을 고르는 방식으로 오류 교정 성능을 극대화했습니다.
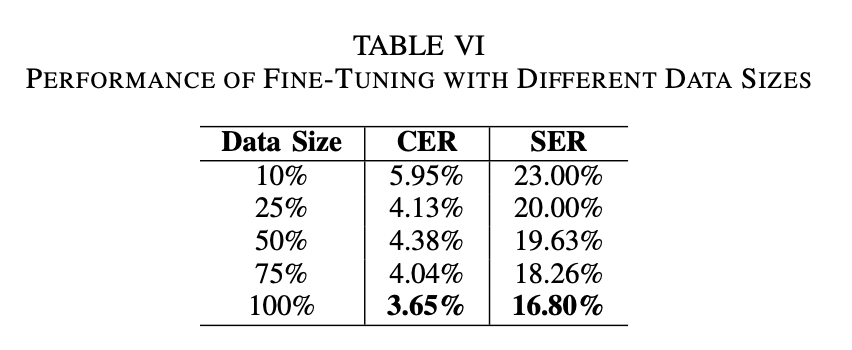
데이터 25%만 써도 꽤 괜찮은 성능을 냅니다.
→ 즉, 적은 데이터로도 잘 배울 수 있는 구조라는 것.
실제 게임마다 데이터를 많이 만들기 어려운 점을 생각하면, 현실적으로 매우 유리한 구조입니다.
🔗 Resources
