
✏️ 12. 선형 회귀
LinearRegression 클래스
sklearn.linear_model.LinearRegression(fit_intercept=True,normalize=False)-
LinearRegression 클래스는 예측값과 실제값의 RSS를 최소화하는 OLS(Ordinary Least Squares) 추정 방식으로 구현한 클래스이다.
-
LinearRegression 클래스는 훈련(fit) 시에 회귀 계수(Coefficients)인 W를 coef_ 속성에 저장한다.
- 단, 절편(bias, intercept)는 intercept_ 속성에 저장된다.
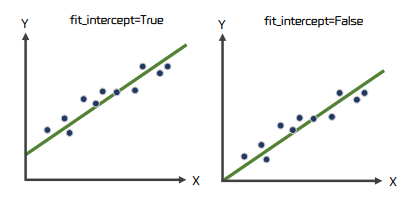
fit_intercept
-
절편 값을 계산할 것인지 여부 결정한다.
-
False로 설정 시 intercept가 0으로 지정된다.
normalize
-
fit_intercept가 False인 경우엔 무시된다.
-
True로 설정하면 회귀를 수행 하기 전 입력 데이터 세트를 정규화(Standard Scaling)한다.
-
대체로 사용하지 않는 것을 추천한다.
선형 회귀의 다중 공선성 문제
-
일반적으로 선형 회귀는 입력 Feature의 독립성에 많은 영향을 받는다.
-
Feature간의 상관관계가 매우 높은 경우 분산이 매우 커져서 오류에 매우 민감해지는 현상을 다중공선성(multi-collinearity)라고 한다.
-
일반적으로 상관관계가 높은 Feature가 많은 경우 독립적인 중요한 Feature만 남기고 제거하거나 규제를 적용한다.
-
EX
-
평수(25평, 34평), 제곱 미터(59𝑚2, 84𝑚2)
-
자동차 무게와 연비
-
사이킷런 LinearRegression 클래스
| 파이썬 Wrapper | 사이킷런 Wrapper | 하이퍼 파라미터 설명 |
|---|---|---|
| lambda | reg_lambda | L2 규제(regularization) 적용 값. 기본값은 1로서 값이 클 수록 규제 값이 커진다. 과적합 제어 |
| alpha | reg_alpha | L1 규제(regularization) 적용 값. 기본값은 0으로서 값이 클 수록 규제 값이 커진다. 과적합 제어 |
| early_stopping_round | early_stopping_rounds | 학습 조기 종료를 위한 early stopping interval 값 |
| num_leaves | num_leaves | 최대 리프 노드 개수 |
| min_sum_hessian_in_leaf | min_child_weight | 결정트리의 min_child_leaf와 유사. 과적합 조절용 |
선형 회귀를 위한 데이터 변환
-
선형 회귀 모델은 일반적으로 피처와 타겟값 간에 선형의 관계가 있다고 가정하고 이러한 최적의 선형 함수를 찾아내
결과 값을 예측한다. -
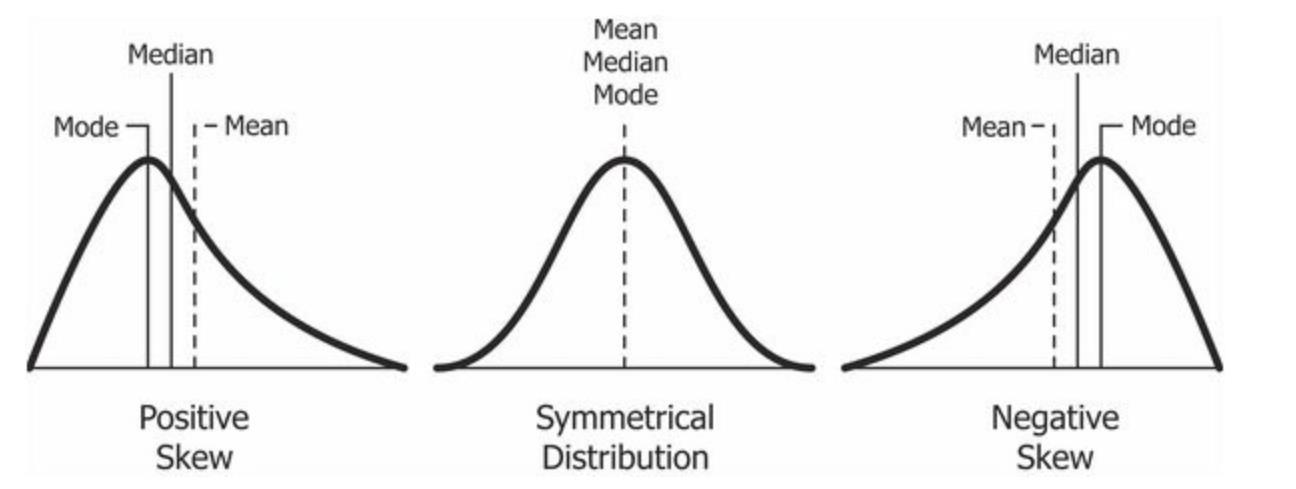
선형 회귀 모델은 피처값과 타겟값의 분포가 정규 분포인 형태를 선호한다
데이터 변환 방법
| 변환 대상 | 설명 |
|---|---|
| Target 변환 | 타겟값은 정규 분포를 선호한다. Skew 되어 있을 경우 주로 로그 변환을 적용한다 |
| Feature 변환 – Scaling | Feature들에 대한 균일한 스케일링 / 정규화를 적용한다. StandardScaler를 이용하여 표준 정규 분포 형태 또는 MinMaxScaler를 이용하여 최솟값 0, 최댓값 1로 변환한다. |
| Feature 변환 – 다항 특성 변환 | 스케일링 / 정규화를 수행한 데이터 세트에 다시 다항 특성(Polynomial Feature)을 적용하여 변환한다. |
| Feature 변환 – 로그 변환 | 왜도(Skewness)가 심한 중요 Feature들에 대해서 로그 변환을 적용한다. 일반적으로 많이 사용된다 |
📌 참고 문헌
-
책
- 📕 파이썬 머신러닝 완벽 가이드 / 권철민
-
참조 자료
-
해당 챕터의 실습 및 예제 코드는 아래 링크의 Machine Learning 참조 해주시면 됩니다.

My path to becoming contributor from user