
이 화면에서 네이버 쇼핑에서 리뷰를 분석하고 싶은 상품의 주소를 입력하면, /search url을 호출한다.
그리고 아래와 같이, urls.py 에서 설정해둔 View와 연결하여 view.py의 search 메소드를 실행한다.
path('search/', views.search, name='search')search 메소드에서는 먼저 입력받은 상품페이지 url에서 상품번호를 가져온다.
product_num = url.split('/')[-1].split('?')[0]
만약 상품 페이지 주소가 shopping.naver.com/window-products/necessity/4634683875?NaPm=ct%3Dlck6pqot%7Cci%3Dshoppingwindow%7Ctr%3Dnct%7Chk%3D8a14bfa931bf4aed8a5246f0f8ffa2371de530bc%7Ctrx%3D&tr=nct
이라면,4634683875가 상품번호가 된다.
네이버 쇼핑은 네이버쇼핑, 스마트쇼핑, 브랜드쇼핑 으로 3가지 종류가 있기 때문에 케이스에 따라 모두 다른 크롤링을 해주어야 했다.
주소게어 상품 번호의 위치는 모두 동일했기 때문에 위 코드로 3가지 쇼핑몰 모두 상품번호를 얻어올 수 있었다.
다음으로, 본격적인 크롤링을 진행하여 준다.
if 'naver' in url:
temp,product_name,img_src=start_crawling(product_num, url)만약 입력받은 url 주소에 'naver'이 포함되면, 크롤링을 진행한다는 것이다. start_crawling 메서드는 functions.py 파일에 정의되어 있다.
from RIverVIEW.MakeData.functions import *
이렇게, 다른 파일인 functions.py에 있는 메서드를 사용할 수 있다. start_crawling은 temp(리뷰를 저장한 리스트), 상품 이름, 상품 이미지를 반환한다.
def start_crawling(product_num, url=None):
#url 쪼개서 원하는 정보 얻기
url_basic = url
store = url_basic.split('//')[1].split('.')[0] # 네이버 쇼핑, 스마트스토어, 브랜드스토어 구별
data = requests.get(url_basic, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
product_detail = soup.find_all('script')[1].text.split(',')
#판매자 번호 얻기
for detail in product_detail:
if '"payReferenceKey"' in detail:
merchant_num = detail.split(':')[1].replace('"', '')
break
else:
merchant_num = ''
#상품 번호 얻기
for detail in product_detail:
if '"originProductNo"' in detail:
product_num = re.sub('[^0-9]', '', detail.split(':')[1].replace('"', ''))
if product_num == '':
continue
break
elif '"sellerImmediateDiscountPolicyNo"' in detail:
product_num = re.sub('[^0-9]', '', detail.split(':')[2].replace('"', ''))
if product_num == '':
continue
break
product_name = soup.find('h3', attrs={'class': '_22kNQuEXmb _copyable'}).text.strip()
img_src = soup.find('div', attrs={'class': '_23RpOU6xpc'}).find('img')['src']
pool = Pool(4)
func = partial(Crawling, product_num,merchant_num,store)
temp= pool.map(func, range(1, 40))
pool.close()
pool.join()
temp = list(filter(None, temp))
# for page in tqdm(range(1,21)):
# temp=Crawling(product_num,merchant_num,store,page,temp)
# pool.map을 사용하기위해 매개변수가 하나인 함수로 만들기 위해 새로 함수 생성
# 네이버쇼핑 페이지에서는 한페이지에 리뷰 20개, JSON은 한페이지에 리뷰 10개 저장
#그래서 리뷰 10페이지까지 보고싶다하면 20페이지까지로 설정해야 다 가져올수 잇음
temp=sum(temp,[])
review_data = pd.DataFrame(temp,columns=['review'])
return review_data,product_name,img_src리뷰를 얻어오기 위해서는 2가지 방법이 있었다. 첫번째로는, 페이지 소스를 통해 html 파일의 태그 위치를 찾아 긁어오는 방법, 두번째 방법으로는 웹페이지에 json 형태로 반환되는 데이터를 크롤링 하는 것이다.
우리 프로젝트는 두번째 방법을 사용했다.
json 데이터를 요청하기 위해서는 요청 url을 알아야 한다.
크롤링을 처음 해보는 입장에서는 이부분이 조금 어려웠다.

일단 리뷰를 하나 찾는다.
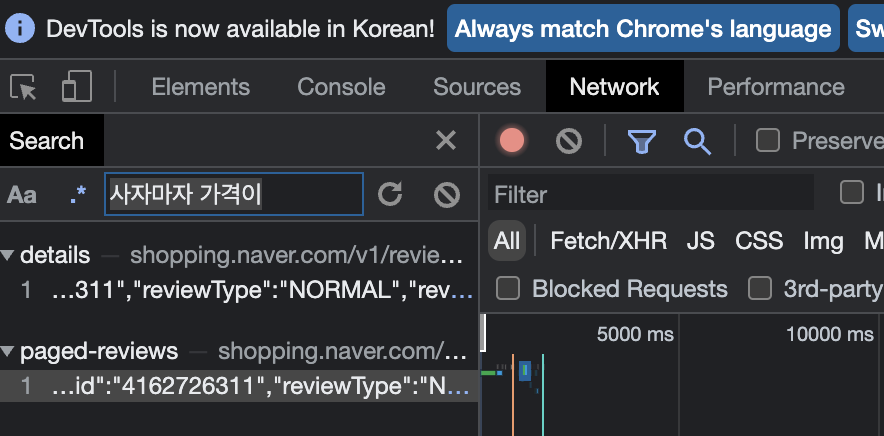
그리고, 개발자 도구의 들어가 Network에서 이 리뷰를 검색하여 주면, paged-reviews 라는 부분이 나온다. 이 부분이, 페이지당 리뷰 데이터가 있는 부분이다.
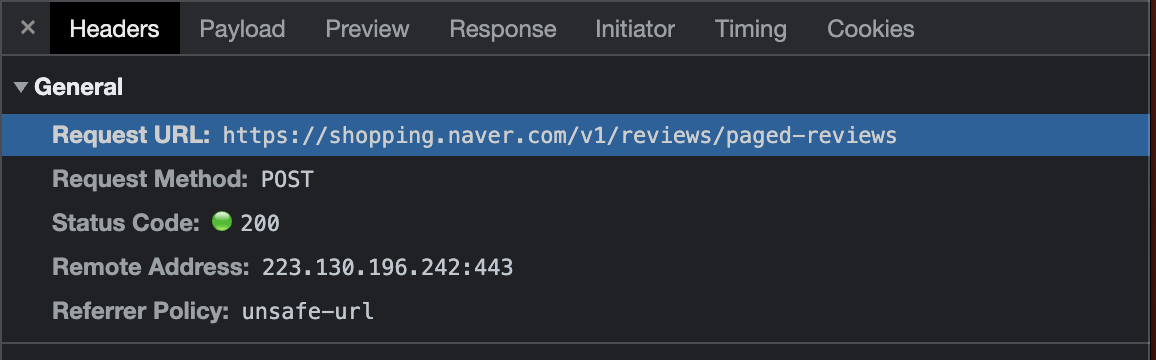
paged-reviews의 Headers를 확인하면 , 요청 URL과 통신방식을 확인할 수 있고,
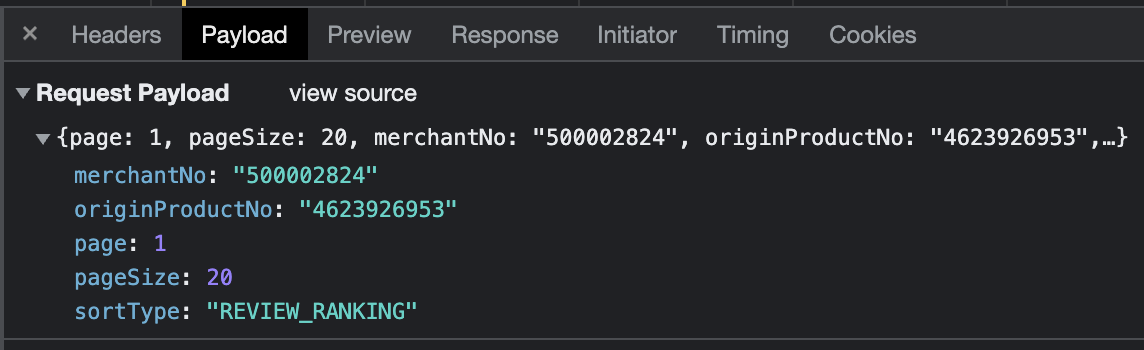
Payload를 확인하면, 요청시 필요한 키-값을 확인할 수 있다.
즉, 위 리뷰가 포함된 페이지의 모든 리뷰를 저장한 json 파일을 요청하기 위해서는, https://shopping.naver.com/v1/reviews/paged-reviews?merchantNo=500002824&originProductNo=4623926953&page=1&pageSize=20&sortType='REVIEW_RANKING'
위와같은 url을 통해 json데이터를 얻어올 수 있다. 실제로 주소창에 위 url을 직접 입력하면,아래와 같이 데이터를 직접 확인할 수 있다.

json을 요청하기 위해서는 해당 상품의 merchantNo와 originProductNo를 알아야 했는데, 이부분은 아래 코드같이 페이지 소스에서 직접 태그를 찾아 가져왔다.
for detail in product_detail:
if '"originProductNo"' in detail:
product_num = re.sub('[^0-9]', '', detail.split(':')[1].replace('"', ''))
if product_num == '':
continue
break
elif '"sellerImmediateDiscountPolicyNo"' in detail:
product_num = re.sub('[^0-9]', '', detail.split(':')[2].replace('"', ''))
if product_num == '':
continue
break크롤링을 직접적으로 실행하는 함수는, Crawling()이라는 메서드이다. Crawling() 메서드는 상품번호, 판매자번호, 쇼핑몰 종류, 크롤링할 리뷰 페이지를 파라미터로 갖는다.
메서드를 나누어 준 이유는, 멀티프로세싱을 사용해보고자 하였기 때문이다.
pool = Pool(4)
func = partial(Crawling, product_num,merchant_num,store)
temp= pool.map(func, range(1, 41))
pool.close()
pool.join()위 코드를 간략히 설명하면, 4개의 cpu core을 사용하여 Crawling() 를 40번 호출하는데 이는 1~40 페이지의 리뷰를 멀티프로세싱을 사용해 크롤링 한다는 뜻이다.
temp에는 리뷰 데이터를 계속해서 이어 붙힌다.
Crawling()메서드는 다음과 같다.
def Crawling(product_num, merchant_num, store, pageNo):
#REVIEW_CREATE_DATE_DESC, REVIEW_RANKING
sort_type = 'REVIEW_RANKING'
if pageNo %2== 0:
sort_type = 'REVIEW_RANKING'
elif pageNo %2== 1:
sort_type = 'REVIEW_CREATE_DATE_DESC'
try:
if store == 'shopping':
url = ('https://smartstore.naver.com/i/v1/reviews/paged-reviews?page={}&pageSize=10&merchantNo={}&originProductNo={}&sortType='+sort_type).format(
pageNo, merchant_num, product_num) # REVIEW_RANKING
elif store == 'smartstore':
url = ('https://{}.naver.com/i/v1/reviews/paged-reviews?page={}&pageSize=10&merchantNo={}&originProductNo={}&sortType='+sort_type).format(
store, pageNo, merchant_num, product_num) # REVIEW_RANKING
elif store == 'brand':
url = ('https://{}.naver.com/n/v1/reviews/paged-reviews?page={}&pageSize=10&merchantNo={}&originProductNo={}&sortType='+sort_type).format(
store, pageNo, merchant_num, product_num) # REVIEW_RANKING
else:
url = ''
response = urlopen(url)
json_data = json.load(response)['contents']
temp=[]
for rev in json_data:
if rev['reviewContent']:
review = rev['reviewContent'].replace("\n", " ")
temp.append(review)
return temp상품번호, 판매자 번호, 쇼핑몰 종류, 페이지 를 파라미터로 입력받아, 쇼핑몰 종류마다 다른 형식의 url을 새로 만들어 준다.
이 url을 호출하여 json 데이터를 얻어와, 리뷰를 temp 리스트에 이어 붙힌다.
이렇게 크롤링이 끝나면, View에 있는 search()메서드로 돌아와, db에 상품을 저장한 후에, 크롤링 한 데이터를 분석(딥러닝 모델 사용)하여 ai score, keyword score등의 분석결과를 만들어 낸다.
temp,url,product_name,img_src=start_crawling(product_num, url)
product=ProductModel(product_url=url,
product_name=product_name,
product_num=int(product_num),
img_src=img_src)
product.save()
keyword, keyword_example, key_score, key_freq = make_final_data(total_data=temp, col_name='review',
limit_size=250, product_name=product_name, T_DEBUG=1)make_final_data()메서드에서 리뷰 데이터를 분석하는데, 이 부분부터는 다음 포스팅에서 다루도록 하겠다.
프로젝트 역할 분담에서, 같이 진행한 팀원이 딥러닝 모델과 리뷰 데이터 분석 부분을 전담해서 하였기 때문에, 같이 했다 하더라도 내가 완전히 이해하지는 못했다. 하지만 최대한 이해한 만큼 리뷰 분석 부분에 대해서 포스팅 해보도록 하겠다.
