Sparse Embedding
- Sparse Embedding(희소 임베딩): 고차원 벡터에서 대부분의 값이 0인 형태로 벡터의 크기가 매우 크지만 많은 원소가 0이고, 소수의 원소만이 유의미한 값을 가진다.
- 대표적인 예
- Bag of Words (BoW): 문서에서 등장하는 단어들을 벡터로 변환할 때, 각 단어의 출현 빈도를 기록하여 벡터화하는 방식이다. 벡터 차원은 전체 단어 사전의 크기와 같고, 각 단어의 출현 빈도만 기록되어 대부분의 값은 0이다.
- TF-IDF: 문서에서 특정 단어의 중요도를 계산하는 방식으로, 단어가 특정 문서에서 자주 등장하면서도 전체 문서 집합에서는 드물게 등장하는 단어에 높은 가중치를 부여한다.
- TF (Term Frequency, 단어 빈도): 특정 단어가 한 문서에서 얼마나 자주 등장하는지 계산
- IDF (Inverse Document Frequency, 역문서빈도): 해당 단어가 전체 문서 집합에서 얼마나 드물게 등장하는지 계산
- 장점: 해석이 직관적이고, 특정 단어의 출현 여부나 빈도를 명확히 알 수 있다.
- 단점: 벡터의 차원이 매우 커서 메모리 소모가 크고, 단어 간의 관계를 반영하지 않아 유사한 의미를 가진 단어들이 멀리 떨어져 있을 수 있다.
Bag of Words
Bag of Words는 문서에서 등장하는 단어들을 벡터로 변환하는 방식으로, 각 단어의 출현 빈도를 기록하여 문서를 수치적으로 표현한다.
- 벡터화 예시
- 문서의 단어를 벡터로 표현할 때, 단어의 출현 빈도에 따라 다음과 같은 형태로 변환된다.
- 예를 들어
How are you?에 대한 대답을 벡터로 표현해보자.-
awesome thank you → [1, 1, 1, 0, 0, 0, 0]
awesome thank you great not bad good 1 1 1 0 0 0 0 -
great thank you → [0, 1, 1, 1, 0, 0, 0]
awesome thank you great not bad good 0 1 1 1 0 0 0 -
not bad not good → [0, 0, 0, 0, 2, 1, 1]
awesome thank you great not bad good 0 0 0 0 2 1 1
-
- 문장 간 유사도 비교
- Sentence Similarity of
awesome thank youxgreat thank you:- [1, 1, 1, 0, 0, 0, 0]⋅[0, 1, 1, 1, 0, 0, 0] = 2
- Sentence Similarity of
great thank youxnot bad not good:- [0, 1, 1, 1, 0, 0, 0]⋅[0, 0, 0, 0, 2, 1, 1] = 0
- Sentence Similarity of
- 한계
- 희소성(Sparsity): 벡터 차원은 전체 단어 사전의 크기와 같기 때문에, 단어 사전의 크기가 커질수록 계산량과 메모리 사용량이 증가한다.
- Frequent words has more power: 자주 등장하는 단어의 중요도가 과도하게 높아질 수 있다.
- the man like the girl → [2, 1, 1, 1, 0]
the man girl like love 2 1 1 1 0 - the man love the girl → [2, 1, 1, 0, 1]
the man girl like love 2 1 1 0 1 - the the the the the → [5, 0, 0, 0, 0]
the man girl like love 5 0 0 0 0 the man like the girlxthe man love the girl= 6the man like the girlxthe the the the the= 10
- the man like the girl → [2, 1, 1, 1, 0]
- Ignoring word orders: 단어의 출현 순서를 무시하기 때문에 문맥이 반영되지 않는다.
- home run = run home : 서로 다른 의미의 문장이 같은 문장이 되어버림
- Out of vocabulary
- vocabulary에 없는 단어들(e.g. 오타, 줄임말)은 표현할 수 없다.
n-gram
-
단어의 출현 순서를 무시하는 Bag of Words(BoW)의 한계를 극복
machine learning is fun and is not boring-
Bag of Words
machine fun is learning and not boring 1 1 2 1 1 1 1 not의 위치 정보가 무시되면 전혀 다른 문장의 유사도가 높게 나올 수 있음machine learning is fun and is not boringmachine learning is boring and is not fun
-
Bag of bigram
machine learning learning is is fun fun and and is is not not boring 1 1 1 1 1 1 1 - bigram은 Bag of Words의 ignoring sequence of words 문제를 보완함
-
-
다음에 올 단어 예측
- how are you doing, how are you, how are they라는 문장을 학습했을 때
- Bag of trigram
how are you are you doing how are they 2 1 1 - 그렇다면
how are다음에 올 단어는? →you
-
Spell checker 기능
- quality, quater, quit라는 단어를 학습했을 때
- Bag of bigram
qu ua al li it ty at te er ui 3 2 1 1 2 1 1 1 1 1 qwal이라고 오타가 났을 때 →qual이라고 spell check
TF-IDF
- TF (Term Frequency, 단어 빈도): 특정 문서에서 단어의 등장 빈도를 계산하는 방식
- TF 수식
- t: 특정 단어
- Number of times term t: 문서 내에서 단어 t가 등장한 횟수
- Total number of terms: 문서 내의 모든 단어 수
- TF의 역할
- 단어 중요도 평가: 특정 주제에 대한 문서에서는 그 주제와 관련된 단어가 많이 등장할 것이기에, TF 값이 높을수록 해당 단어는 문서 내에서 더 중요한 역할을 한다고 간주한다.
- TF를 사용하여 서로 다른 문서에서 동일한 단어의 중요도를 비교할 수 있다. 같은 단어라도 문서마다 TF 값이 다르므로, 문서 간의 특성을 분석할 수 있다.
- TF는 IDF와 결합되어 단어의 가중치를 결정한다. TF가 높고 IDF가 낮은 단어는 문서의 특성을 파악하는 데 기여하지 않지만, TF가 높고 IDF가 높은 단어는 문서의 중요한 특징을 나타낸다.
- 정규화
- TF는 문서의 길이에 따라 달라질 수 있으므로, 보통 정규화를 통해 문서 길이에 대한 영향을 줄이는 방법이 사용되는데, 단어 빈도를 단어의 총 수로 나누어 계산하는 것이 일반적이다. 이를 통해 문서 길이가 다르더라도 TF 값의 비교가 용이해진다.
- TF 수식
- IDF (Inverse Document Frequency, 역문서빈도): 해당 단어가 전체 문서 집합에서 얼마나 드물게 등장하는지 계산하는 방식
- IDF 수식
- t: 특정 단어
- N: 전체 문서의 수
- df(t): 특정 단어 t가 등장한 문서의 수 (문서 빈도, document frequency)
- IDF의 역할
- 어떤 단어가 많은 문서에서 등장하면 그 단어는 덜 중요한 것으로 간주되고, 소수의 문서에서만 등장하면 더 중요한 단어로 간주된다. 자주 등장하는 단어는 낮은 IDF 값을 가지고, 드물게 등장하는 단어는 높은 IDF 값을 가진다.
- 'the', 'is', 'and'와 같은 단어들은 대부분의 문서에서 자주 등장하지만, 문서 간 차이를 구별하는 데 기여하지 않으므로 IDF 값이 낮아져 가중치가 줄어든다.
- 반면에 특정 주제에만 관련된 단어들은 적은 문서에서만 등장하므로 높은 IDF 값을 가지게 되어 가중치가 높아진다.
- IDF 수식
- TF-IDF최종적으로 TF-IDF는 TF와 IDF 값을 곱하여 계산된다. 이 수식을 통해 문서 내에서 빈번하게 등장하고, 전체 문서 집합에서는 드물게 등장하는 단어에 높은 가중치가 부여되어 해당 단어가 문서의 특징적인 단어임을 강조할 수 있다.
BM25
BM25는 TF-IDF의 한계를 개선한 정보 검색 모델로, TF-IDF와 비슷하게 단어 빈도와 문서 빈도를 기반으로 하지만, 좀 더 정교한 수식을 사용해 문서와 질의 간의 유사도를 평가한다. 특히, 단어 빈도에 대한 포화 효과와 문서 길이에 대한 보정을 통해 현실적인 검색 결과를 제공한다.
-
BM25 수식
- IDF(t): 전체 문서 집합을 고려했을 때 단어가 제공하는 정보의 양 (역문서빈도)
- TF(t): 문서 내 단어 t의 빈도
- L: 문서의 길이
- avgL: 전체 문서의 평균 길이
- k₁: 단어 빈도의 중요도를 조정하는 매개변수 (saturation parameter)
- b: 문서 길이에 대한 보정 매개변수 (보통 0.75로 설정)
-
특징
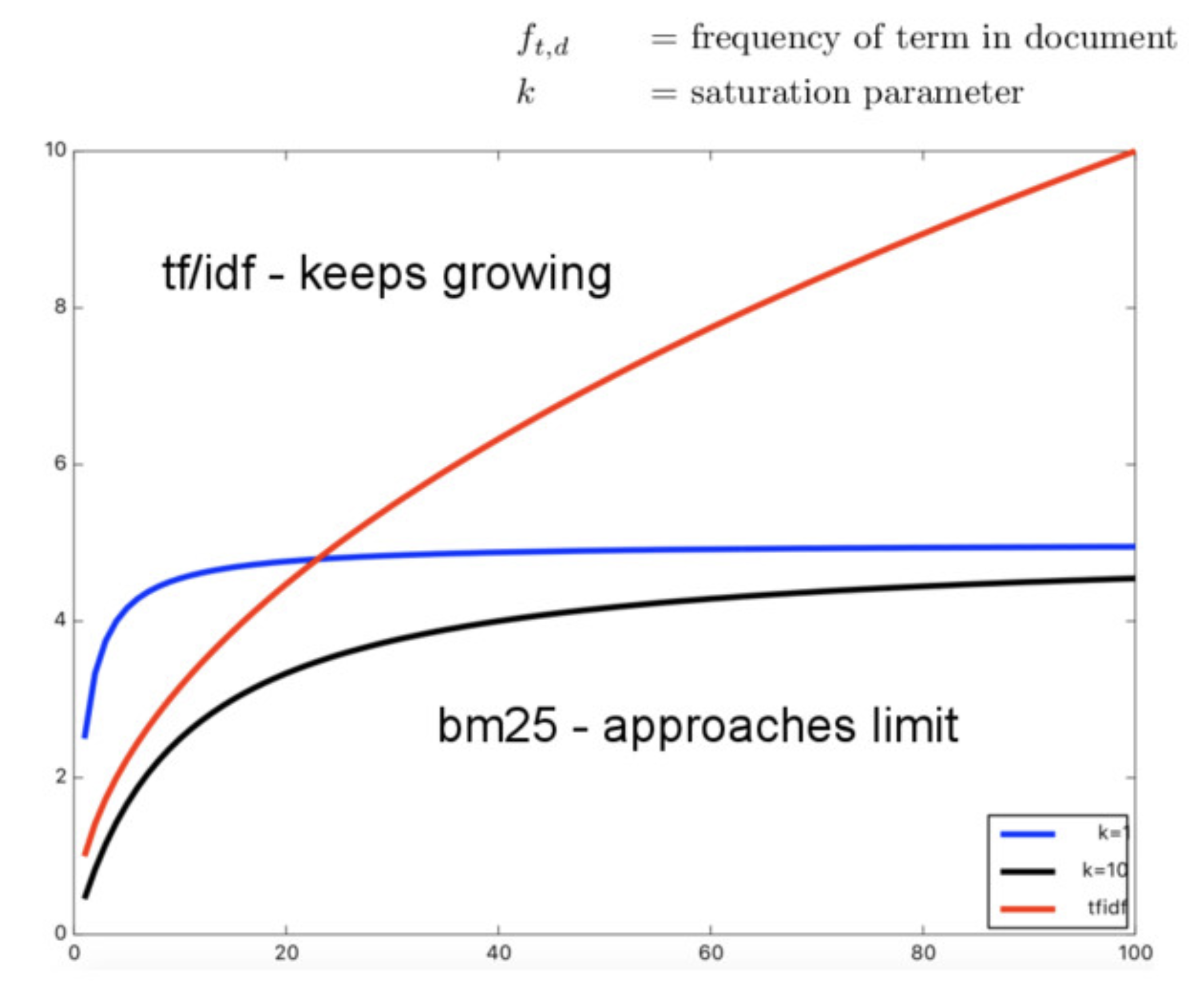
- 포화 효과: 단어 빈도(TF)가 일정 수준을 넘으면 추가적인 TF 증가가 성능에 미치는 영향이 줄어든다. k₁은 단어 빈도가 한계치에 도달하면 더이상의 단어 출현으로 인한 점수를 부여하지 않기 위해 설정하는 파라미터이다. 이를 통해 특정 단어가 지나치게 많이 등장하는 문서가 너무 높은 가중치를 받는 것을 방지할 수 있다.
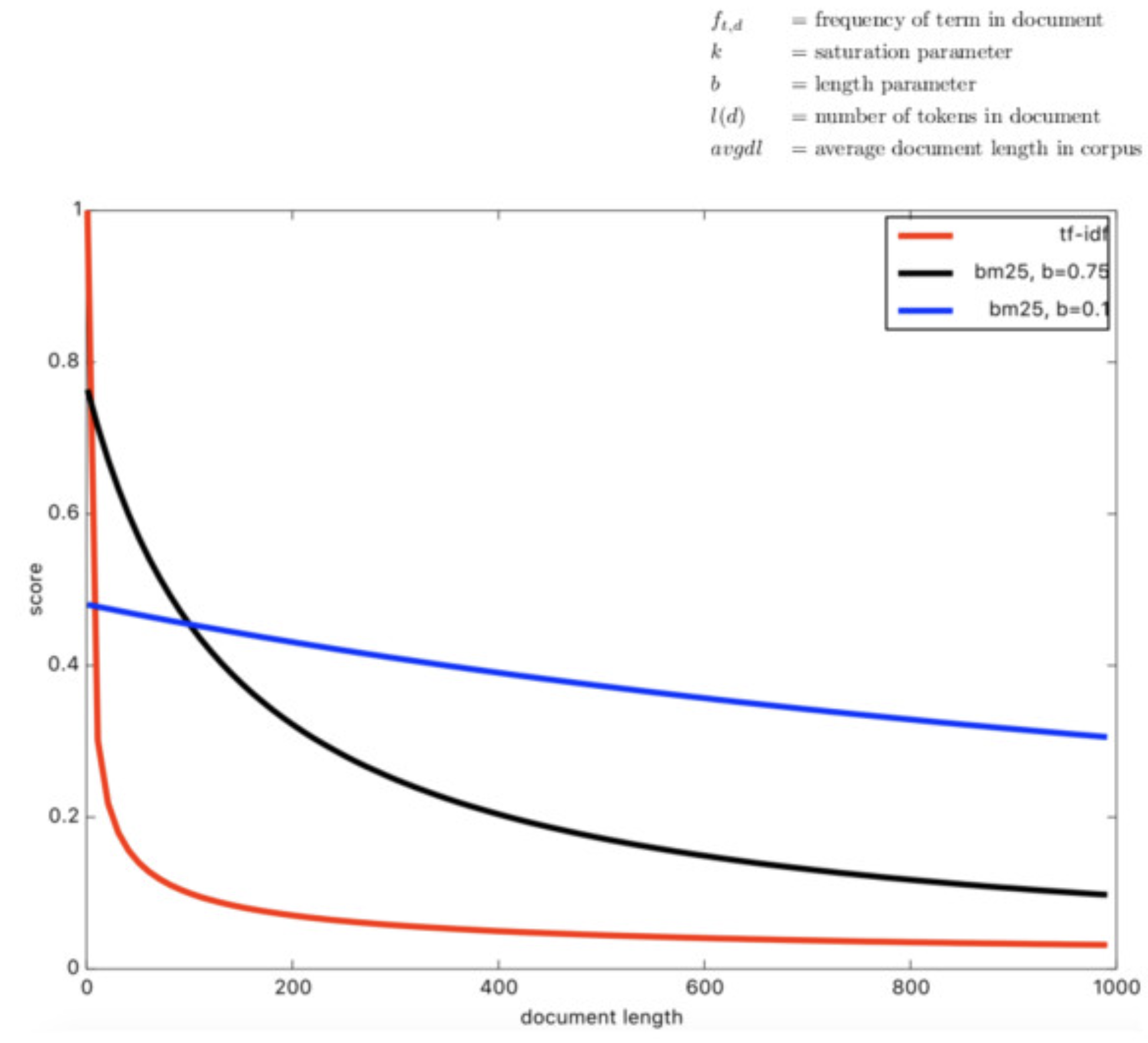
- 문서 길이 보정: 문서가 길어질수록 많은 단어가 등장할 가능성이 높기 때문에, 문서 길이에 따라 가중치를 조정한다. b는 문서 길이에 대한 보정 매개변수로, 긴 문서가 짧은 문서에 비해 높은 점수를 받지 않도록 보정하는 역할을 한다.
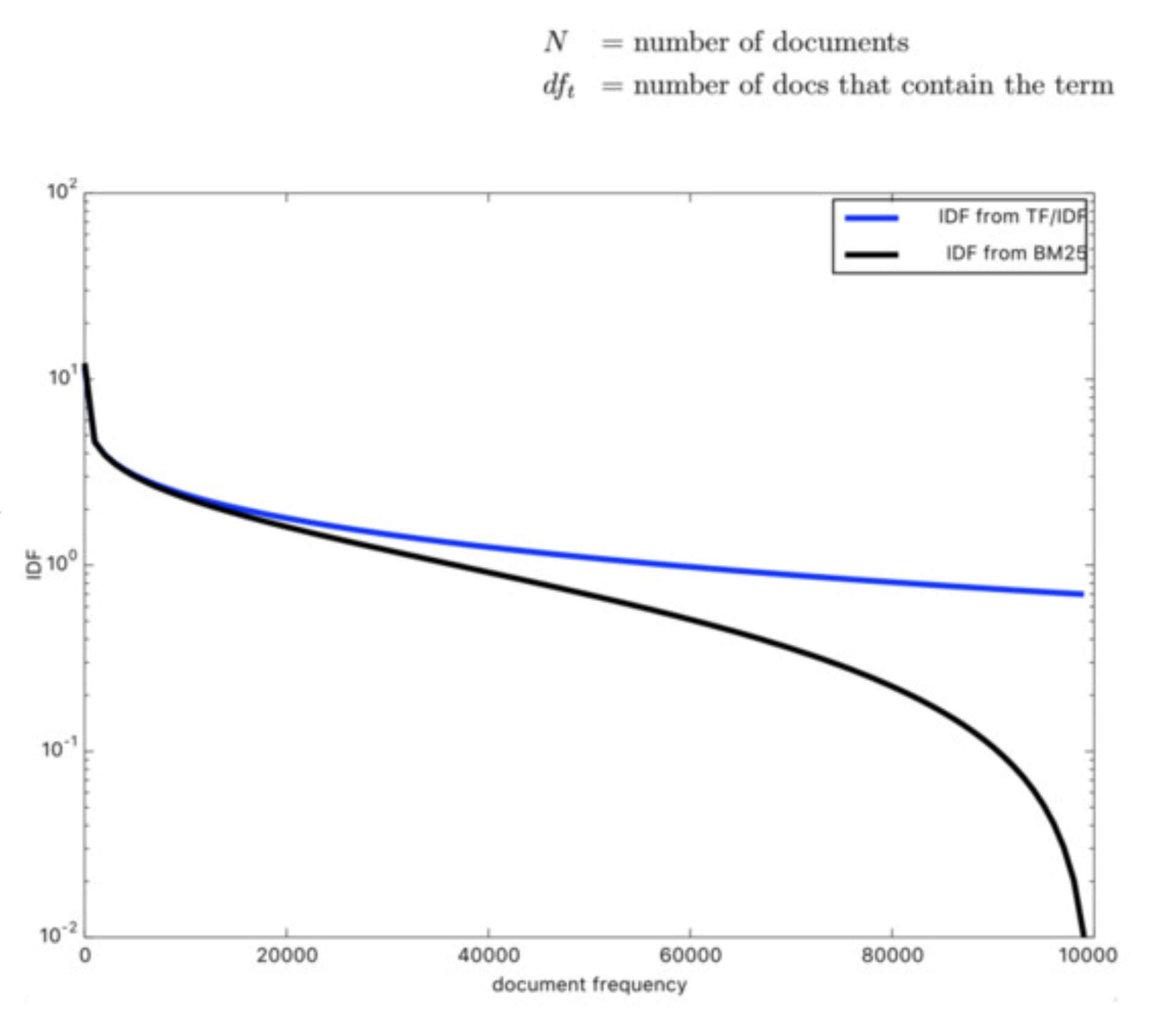
- 패널티 부여: BM25의 IDF는 TF-IDF와 유사하게 특정 단어가 출현한 문서의 수에 따라 가중치를 결정하나, BM25는 다른 문서들에 검색어가 등장하지 않을수록 더 높은 가중치를 부여한다. 반대로, 해당 단어가 많은 문서에서 등장할수록 가중치는 낮아지고 패널티를 부여한다.
TF-IDF와 비교하여 BM25는 일반적인 단어가 주는 정보의 양을 더 낮게 평가하여, 검색어가 드문 문서일수록 해당 문서를 더욱 강조한다.
TF-IDF와 BM25의 차이점
Term Frequency 관점
- TF-IDF
- 한 문서에서 검색어가 많이 등장할수록 그 문서의 점수는 높아짐
- 빈도가 높은 단어일수록 문서의 중요한 feature로 간주됨
- BM25
- 검색어가 많이 등장할수록 점수가 높아지긴 하지만, 일정 빈도 이상에서는 그 가중치가 더 이상 증가하지 않음
- 즉, 한계점에 도달하면 추가 출현 빈도는 큰 영향을 주지 않음
Document Frequency 관점
- TF-IDF
- 검색어가 여러 문서에서 출현할수록 그 단어의 가중치는 낮아짐
- 하지만 일정 문서 수를 넘어서면 더 이상 점수가 크게 변하지 않음
- BM25
- 검색어가 출현한 문서가 많을수록 점수는 더 급격히 낮아짐
- 특히 일정 문서 수를 넘어가면 가중치는 더욱 가파르게 떨어져, 자주 등장하는 단어의 영향력을 더욱 줄임
TF-IDF를 활용한 Sparse Passage Retrieval 실습
- KorQuad 데이터셋을 활용해 질의와 가장 관련있는 passage를 retrieval합니다.
- Sparse embedding의 대표적인 방법인 TF-IDF를 활용해 관련 문서를 retrieval합니다.
데이터셋 및 토크나이저 준비
from datasets import load_dataset
dataset = load_dataset("squad_kor_v1")corpus = list(set([example['context'] for example in dataset['train']]))
len(corpus) # 9606tokenizer_func = lambda x: x.split(' ') # 띄어쓰기 기준으로 token 나눔TF-IDF embedding 만들기
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(tokenizer=tokenizer_func, ngram_range=(1,2)) # unigram, bigram 활용TfidfVectorizer: 텍스트 데이터를 TF-IDF 방식으로 벡터화하는 도구로, 단어들의 중요도를 계산한다.tokenizer: 텍스트를 어떻게 토큰으로 분리할지 정의 (여기서는 띄어쓰기 기준)ngram_range=(1,2): unigram과 bigram을 사용하여 벡터화 수행. 즉, 한 단어 및 두 단어가 조합된 형태의 n-gram을 생성한다.
vectorizer.fit(corpus) # corpus에 대해 TF-IDF 계산에 필요한 정보(TF, IDF) 학습(fit)
sp_matrix = vectorizer.transform(corpus) # 학습된 vectorizer를 사용하여 corpus를 TF-IDF 벡터로 변환(transform)
sp_matrix.shape # (9606, 1272768)sp_matrix: TF-IDF 값을 포함하는 희소 행렬로, 각 문서를 벡터로 변환한 결과. 각 값은 문서 내 단어의 중요도를 나타낸다.
TF-IDF embedding을 활용하여 passage retrieval 실습해보기
Search query로 KorQuAD train 데이터셋의 질문을 활용하여, 실제 context가 잘 나오는지 확인해보기
import random
import numpy as np
random.seed(1)
sample_idx = random.choice(range(len(dataset['train'])))
query = dataset['train'][sample_idx]['question']
ground_truth = dataset['train'][sample_idx]['context'] # 실제 context가 GT가 된다.query를 tf-idf vector로 변환
query_vec = vectorizer.transform([query])
query_vec.shape # (1, 1272768)query와 context들 간의 similarity ranking을 구함
result = query_vec * sp_matrix.T # query_vector와 context들의 vector와 dot product 수행
result.shape # (1, 9606)sorted_result = np.argsort(-result.data) # similarity가 높은 순으로 인덱스 정렬
doc_scores = result.data[sorted_result] # 정렬된 similarity score
doc_ids = result.indices[sorted_result] # 정렬된 indiciesTop-3개의 passage를 retrieve
k = 3
doc_scores[:k], doc_ids[:k]
> (array([0.18985967, 0.03625019, 0.03371167]),
> array([2232, 3742, 5540], dtype=int32))실제 ground_truth와 비교해보기
print("[Search query]\n", query, "\n")
print("[Ground truth passage]")
print(ground_truth, "\n")
for i in range(k):
print("Top-%d passage with score %.4f" % (i + 1, doc_scores[i]))
doc_id = doc_ids[i]
print(corpus[doc_id], "\n")[Search query]
호메로스 찬가를 신통기에 비해 간결한 서사로 간주한 사람은 누구인가?
[Ground truth passage]
고전 시대 신화에서는 티탄들의 패배 이후, 신들의 새로운 판테온이 세워졌다고 설명한다. 주요한 그리스 신들 중에서 올림피안은 올림포스 산 정상에서 제우스의 통치 아래 살아가는 신들을 말한다. 이들의 인원이 열두 명으로 제한된 것은 비교적 최근에 도입된 개념으로 보인다. 올림피안 이외에도 그리스인들은 염소 신 판, 강의 정령 님프, 샘에 사는 나이아드, 나무의 정령 드라이어드, 바다에 사는 네레이드, 강의 신, 사티로스를 비롯한 그 지역의 다양한 신들을 숭배하였다. 여기에는 에리니에스(또는 푸리아이)처럼 혈연 관계에게 범죄를 저지른 죄인을 뒤쫓는 저승의 암흑 세력도 있었다. 시인들은 그리스 판테온의 영광을 기리고자 호메로스 찬가를 지었다.(33편의 노래). 그레고리 나지는 호메로스 찬가를 "각 노래마다 신에 대한 기원을 노래하는(《신통기》에 비해) 간결한 서가"로 간주하였다.
Top-1 passage with score 0.1899
고전 시대 신화에서는 티탄들의 패배 이후, 신들의 새로운 판테온이 세워졌다고 설명한다. 주요한 그리스 신들 중에서 올림피안은 올림포스 산 정상에서 제우스의 통치 아래 살아가는 신들을 말한다. 이들의 인원이 열두 명으로 제한된 것은 비교적 최근에 도입된 개념으로 보인다. 올림피안 이외에도 그리스인들은 염소 신 판, 강의 정령 님프, 샘에 사는 나이아드, 나무의 정령 드라이어드, 바다에 사는 네레이드, 강의 신, 사티로스를 비롯한 그 지역의 다양한 신들을 숭배하였다. 여기에는 에리니에스(또는 푸리아이)처럼 혈연 관계에게 범죄를 저지른 죄인을 뒤쫓는 저승의 암흑 세력도 있었다. 시인들은 그리스 판테온의 영광을 기리고자 호메로스 찬가를 지었다.(33편의 노래). 그레고리 나지는 호메로스 찬가를 "각 노래마다 신에 대한 기원을 노래하는(《신통기》에 비해) 간결한 서가"로 간주하였다.
Top-2 passage with score 0.0363
두 사람은 낙담하고, 밴 하우튼의 집을 떠난다. 리더비히는 대신 사과하며 두 사람과 같이 여행을 한다. 세 사람은 안네 프랑크의 집을 방문한다. 집에 계단이 많기 때문에 헤이즐은 힘들게 올라간다. 안네 프랑크의 집 꼭대기에서 헤이즐은 사랑을 느끼고 어거스터스와 로맨틱한 키스를 한다. 두 사람은 호텔로 돌아와 처음으로 밤을 같이 보낸다. 다음날, 어거스터스는 헤이즐에게 자신의 암이 재발했다고 말한다. 인디애나폴리스에 돌아와서 어거스터스의 상태가 더욱 악화되어 갔다. 어거스터스는 중환자실로 보내지며 죽음이 가까운 것을 깨달았다. 어거스터스는 자신의 생전 장례식에 눈 먼 친구 아이작과 헤이즐을 불러 두 사람은 사전에 적은 추도사를 낭독한다. 헤이즐은 밴 하우튼의 소설을 인용하며, 어거스터스와 함께하는 짧은 시간은 무엇과도 바꿀 수 없는 것이라고 말한다.
Top-3 passage with score 0.0337
고대 그리스에서 신화는 일상의 중심이었다. 그리스인들은 신화를 그들의 역사의 일부로 보았다. 그들은 자연 현상과 문화적 변화, 인습적인 증오와 친교를 설명하는데 신화를 사용하였다. 한 지도자가 신화적 영웅, 또는 신의 후손이라는 증거로 사용할 수 있는 자부심의 원천이기도 했다. 《일리아스》와 《오디세이아》에서 설명하는 트로이아 전쟁의 진실에 대해서 의문을 갖는 사람은 거의 없었다. 군사 역사가, 칼럼니스트, 정치 수필가이자 전 고전학 교수인 빅터 데이비스 핸슨과 고전학 부교수 존 히스에 따르면, 그리스인들에게 호메로스 서사시의 심오한 지식은 그들의 문화 변용의 기저로 간주되었다. 호메로스는 "그리스의 학문"(Ἑλλάδος παίδευσις)이었고, 그의 시는 한 권의 "책"이었다. Sparse Embedding은 검색어와 문서 간의 매칭이 어떻게 이루어지는지 직관적으로 해석할 수 있고, 비교적 빠르고 자원 효율적이기 때문에 대규모의 데이터셋을 다루거나 실시간 검색이 필요한 상황에서 유리하다는 장점이 있다. 하지만 질문에 사용된 용어 기반으로만 문서를 검색하기 때문에 검색어가 포함된 문서만 찾을 수 있으며, 문맥이나 의미를 반영하지 못하는 한계가 존재한다. 이러한 한계를 극복하기 위해, 다음 글에서 설명할 Dense Embedding을 활용할 수 있다. 이는 질문과 문서의 의미적 유사성을 기반으로 검색하므로, 더 정교하고 정확한 검색 결과를 제공한다.
