생성기반으로 기계독해를 푸는 방법
Generation-based MRC
- Generation-based MRC 문제 정의
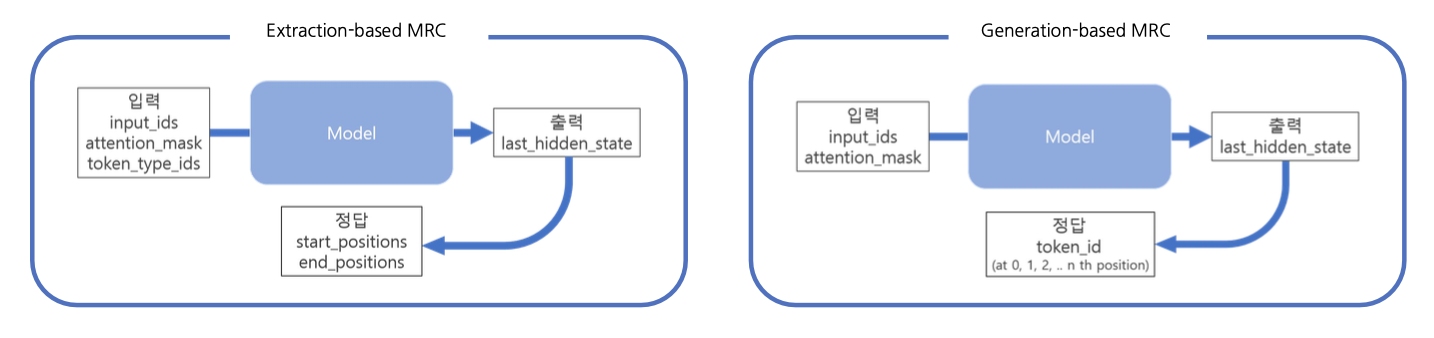
- Extraction-based mrc: 모델이 지문 내 답의 위치(start token, end token)를 예측 ⇒ 분류 문제(classification)
- Generation-based mrc: 주어진 지문과 질의를 보고, 모델이 답변을 생성 ⇒ 생성 문제(generation)
- Generation-based MRC 평가 방법
- 동일한 extractive answer datasets ⇒ Extraction-based MRC와 동일한 평가 방법을 사용
- Exact Match(EM) Score
- F1 Score
- 동일한 extractive answer datasets ⇒ Extraction-based MRC와 동일한 평가 방법을 사용
- Generation-based MRC & Extraction-based MRC 비교
- MRC 모델 구조
- generation: Seq-to-Seq PLM(Pretrained Language Model)
- extraction: PLM + Classifier
- Loss 계산을 위한 답의 형태 (Prediction의 형태)
- generation: Free-form text 형태
- extraction: 지문 내 답의 위치 ⇒ F1 계산을 위해 text로의 별도 변환 과정이 필요
- MRC 모델 구조
Pre-processing
- Tokenization
- 텍스트를 의미를 가진 작은 단위로 나눈 것
- Extraction-based MRC와 같이 Word Piece Tokenizer를 사용
- 먼저 학습에 사용한 전체 데이터 집합(코퍼스)에 대해서 구축되어 있어야 함
- 구축 과정에서 미리 각 단어 토큰들에 대해 순서대로 번호(인덱스)를 부여해 둠
- Tokenizer는 입력 텍스트를 토큰화한 뒤, 각 토큰을 미리 만들어둔 단어 사전에 따라 인덱스로 변환함
- Special Token
- 학습시에만 사용되며 단어 자체의 의미는 가지지 않는 특별한 토큰
- SOS(Start Of Sentence), EOS(End Of Sentence), CLS, SEP, PAD, UNK.. 등
- Extraction-based MRC에선 CLS, SEP, PAD 토큰을 사용함.
- Generation-based MRC에서도 PAD토큰은 사용됨. CLS, SEP 토큰 또한 사용할 수 있으나, 대신 자연어를 이용하여 정해진 텍스트 포맷(format)으로 데이터를 생성함.
- 학습시에만 사용되며 단어 자체의 의미는 가지지 않는 특별한 토큰
- Additional Information
- Attention mask
- Extraction-based MRC와 똑같이 어텐션 연산을 수행할지 결정하는 어텐션 마스크 존재
- Token type ids
- BERT와 달리, BART에서는 입력시퀀스에 대한 구분이 없어 token_type_ids가 존재하지 않음
- 따라서 Extraction-based MRC와 달리 입력에 token_type_ids가 들어가지 않음
- Attention mask
- 정답 출력
- Extraction-based MRC에선 텍스트를 생성해내는 대신, 시작 토큰과 끝 토큰의 위치를 출력하는 것이 모델의 최종 목표였음
- Generation-based MRC는 그보다 어려운 실제 텍스트를 생성하는 과제를 수행
- 전체 시퀀스의 각 위치마다 모델이 아는 모든 단어들 중 하나의 단어를 맞추는 classification 문제
Model
BART: Sequence-to-Sequence 문제 해결을 위한 Denoising Autoencoder
BART(Bidirectional and Auto-Regressive Transformers)는 기계 독해, 기계 번역, 요약, 대화 등 다양한 sequence-to-sequence 문제에 적합한 모델로, denoising autoencoder 방식을 활용한 pre-training을 수행한다.
-
BART의 Encoder와 Decoder 구조
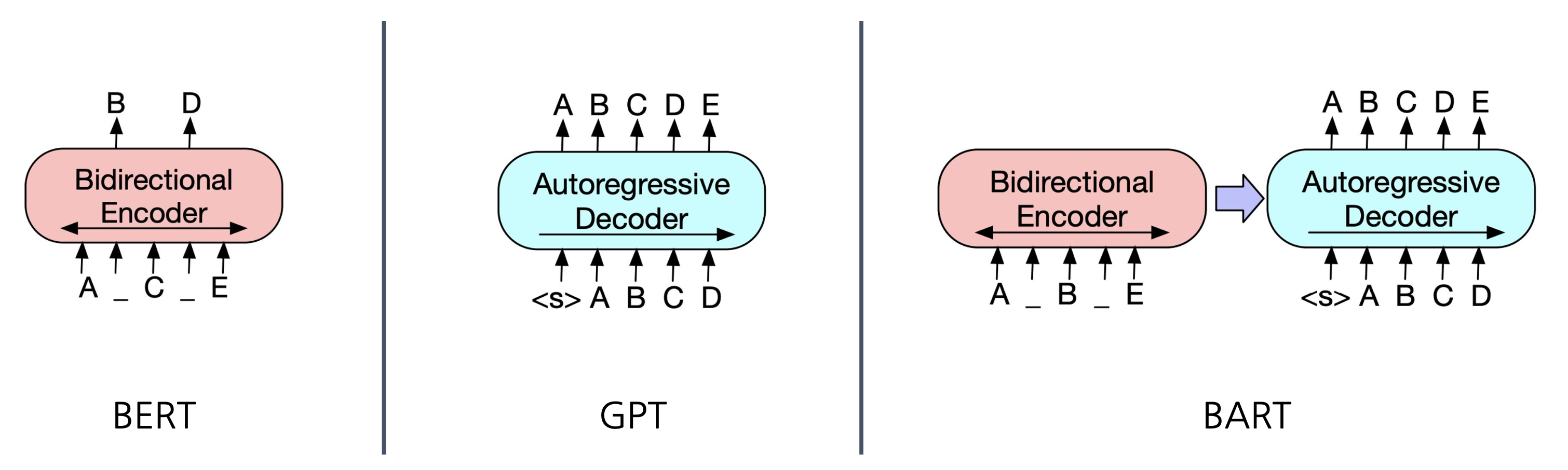
- BART의 인코더: BERT처럼 양방향(bi-directional)으로 텍스트를 처리
- BART의 디코더: GPT처럼 단방향(uni-directional)으로 autoregressive하게 텍스트를 생성
-
BART의 Pre-training 방식
-
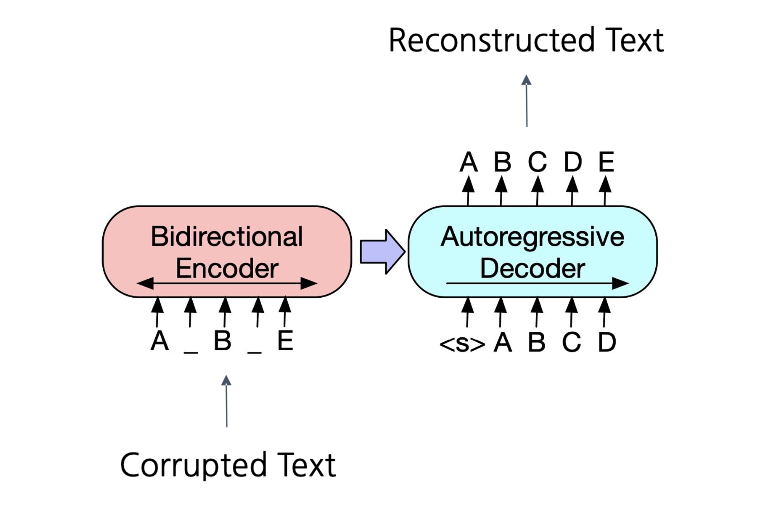
BART는 노이즈가 추가된 텍스트에서 원래 문장을 복원하는 방식으로 pre-training을 진행
-
이 과정에서 사용되는 주요 노이즈 기법
- Token Masking: 일부 토큰을 가리고 모델이 이를 예측하도록 함
- Token Deletion: 무작위로 토큰을 삭제하고, 모델이 삭제된 부분을 복원하도록 학습
- Text Infilling: 랜덤한 위치의 단어들을 제거한 후, 모델이 그 공백을 채우도록 함
- Sentence Permutation: 문장의 순서를 무작위로 바꾼 다음, 모델이 올바른 순서로 복구하게 함
- Document Rotation: 문서의 일부분을 돌려서 원래 문서의 시작점을 모델이 찾도록 함
-
T5: 모든 텍스트 처리 문제를 “text-to-text”로 해결
T5(Text-to-Text Transfer Transformer)는 모든 자연어 처리 문제를 “text-to-text” 형식으로 변환하여 해결한다. 즉, 텍스트를 입력으로 받아 새로운 텍스트를 출력하는 방식으로 모든 작업을 통합한다.
-
Text-to-Text Framework
- 번역, 요약, 질의응답 등의 모든 task들은 자연어 문장이 들어가고 자연어 문장이 나온다는 점에 착안해, 입출력 포맷을 ‘Text-to-Text’ task로 정의
- Relative position encoding
- 일반적으로 트랜스포머 모델은 입력된 단어의 순서를 이해하기 위해 Position Encoding을 사용하여 절대적인 위치 정보를 사용하는데, 각 단어가 문장에서 몇 번째에 위치해 있는지를 명시함
- 반면, Relative Position Encoding은 각 단어 간의 상대적인 위치에 집중하여 특정 단어가 다른 단어에 비해 얼마나 앞이나 뒤에 있는지에 대한 정보를 모델이 학습하도록 돕는데, 순서 정보가 중요한 작업에서 더 유연하고 효율적으로 작동함
- Downstream task에 대해 fine-tuning 시 prefix를 추가하여 작업을 구분
- T5는 다양한 작업(번역, 요약, 질의응답 등)을 하나의 모델로 처리하는데, 작업마다 다른 prefix(작업을 설명하는 짧은 텍스트)를 입력 앞에 추가함
- 예를 들어, 번역 작업의 경우
translate English to French: ...라는 형태로 문장을 입력하면 모델은 그에 맞는 번역 작업을 수행함 - 요약 작업에서는
summarize: ...처럼 작업의 성격을 미리 알려주는 텍스트를 붙여 작업을 구분함 - 이를 통해 하나의 모델이 여러 작업을 동시에 처리할 수 있음
-
T5의 Pre-training 방식
- Span 단위 Masking(Replace corrupted spans): 문장에서 일정 부분을 가린 후, 이를 복구하는 방식으로 pre-training을 진행
- Multi-task Pre-training: Pre-training dataset과 self-supervised task로 변환된 downstream task들의 dataset을 섞어 한 번에 학습
-
mT5(Multilingual Text-to-Text Transfer Transformer)
- mT5는 T5의 text-to-text 형식을 유지하면서 다국어 처리를 지원하는 모델
- 101가지 언어로 구성된 mC4 데이터셋으로 학습된 T5 모델로, 입력과 출력이 다른 언어로 이루어진 작업을 처리할 수 있음
Post-processing
- Decoding (디코딩)
- 이전 스텝의 출력이 다음 스텝의 입력으로 들어가는 autoregressive 방식
- 디코더는 순차적으로 토큰을 생성하는데, 첫 번째 입력은 항상 문장의 시작을 나타내는 스페셜 토큰임
- Searching (검색 기법)
- 디코딩된 문장을 완성하는 과정에서 모델은 여러 가능성 중 가장 적합한 결과를 선택하기 위해 검색(Search) 기법을 사용함
- 대표적인 검색 기법
- Exhaustive Search: 가능한 모든 문장 조합을 전부 탐색하여 최적의 문장을 찾는 방법으로 연산량이 매우 크고, 비효율적이기 때문에 거의 사용되지 않음
- Greedy Search: 각 단계에서 가장 확률이 높은 토큰을 선택하는 방법으로, 현재 스텝에서 최선의 선택을 반복해서 빠르게 문장을 생성하지만, 최종 결과가 항상 최적의 문장일 보장이 없으며 전역 최적 해를 놓칠 수 있음
- Beam Search: 속도와 성능 사이에서 균형을 맞출 수 있는 기법으로, 여러 가능성을 동시에 고려함으로써 Greedy Search의 단점을 보완한 방법. 한 스텝에서 가장 높은 확률을 가진 여러 개의 후보(beam)를 유지하고 각 후보에서 다음 토큰을 생성해 나가며, 최종적으로 가장 확률이 높은 문장을 선택함
Generation-based MRC 실습
범용적으로 사용되는 다국어 모델인 mT5 모델을 이용해 Generation 기반 MRC를 위한 Fine-tuning을 진행한다. 학습된 모델로 추론하고, 평가지표를 통해 모델의 성능을 평가한다.
데이터 및 평가 지표 불러오기
from datasets import load_dataset, load_metric
datasets = load_dataset("squad_kor_v1")
metric = load_metric('squad')Pre-trained 모델 불러오기
from transformers import AutoConfig, AutoModelForSeq2SeqLM, AutoTokenizer
model_name = "google/mt5-small"
config = AutoConfig.from_pretrained(model_name, cache_dir=None)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name, config=config, cache_dir=None)
tokenizer = AutoTokenizer.from_pretrained(model_name, cache_dir=None, use_fast=True)설정하기
max_source_length = 384 # 입력 텍스트(질문과 문맥)의 최대 길이 설정
max_target_length = 16 # 출력(정답)의 최대 길이 설정
padding = "max_length"
preprocessing_num_workers = 12 # 데이터 전처리를 위한 워커 프로레스의 수 설정. 전처리 속도가 빨라짐
num_beams = 3 # 빔 서치(beam search)에서 사용할 빔의 수를 설정
max_train_samples = 5000 # 훈련에 사용할 최대 샘플 수를 설정
max_val_samples = 500 # 검증에 사용할 최대 샘플 수를 설정
num_train_epochs = 5 # 모델을 훈련할 에폭 수를 설정. 전체 훈련 데이터셋에 대해 5회 반복하여 학습 진행
train_batch_size = 16 # 훈련 시 한 번에 처리할 배치의 크기를 설정
eval_batch_size = 8 # 평가 시 한 번에 처리할 배치의 크기를 설정
learning_rate = 1e-3 # 모델의 가중치를 업데이트할 때 사용할 학습률 설정전처리하기
def preprocess_function(examples):
inputs = [f'question: {q} context: {c}' for q, c in zip(examples['question'], examples['context'])]
targets = [f'{a["text"][0]}' for a in examples['answers']]
model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True, return_tensors='pt')
# Setup the tokenizer for targets
with tokenizer.as_target_tokenizer():
labels = tokenizer(targets, max_length=max_target_length, padding=padding, truncation=True, return_tensors='pt')
model_inputs["labels"] = labels["input_ids"]
model_inputs["labels"][model_inputs["labels"] == tokenizer.pad_token_id] = -100
model_inputs["example_id"] = []
for i in range(len(model_inputs["labels"])):
model_inputs["example_id"].append(examples["id"][i])
return model_inputs- 입력 데이터 준비
examples['question']와examples['context']를 받아서 각 질문과 문맥을 하나의 문장으로 결합한다. 이 결합된 문장은"question: <질문> context: <문맥>"형식으로 만들어진다.examples['answers']에서 정답 텍스트를 추출하여targets리스트에 넣는다.
- inputs 토큰화
- 결합된 질문과 문맥 데이터를
tokenizer로 토큰화한다. 이때, 최대 길이를 설정하고, 패딩 및 잘림 옵션을 적용하여 입력 데이터를 모델에 맞게 조정하며, 결과는 PyTorch 텐서 형태로 반환된다.
- 결합된 질문과 문맥 데이터를
- targets 토큰화
tokenizer의 타겟 토크나이저 설정을 이용하여targets에 있는 정답 텍스트를 토큰화한다. 이 과정에서도 최대 길이, 패딩 및 잘림 옵션을 적용하고, 결과를 PyTorch 텐서로 반환한다.
- 라벨 처리
- 토큰화된 정답 데이터를
model_inputs에 라벨(labels)로 추가한다. - 모델이 패딩 토큰을 무시하도록
model_inputs["labels"]에서 패딩 토큰의 위치를 -100으로 설정한다. 이 값은 손실 계산 시 패딩 토큰을 제외하기 위한 설정이다.- 일반적으로 PyTorch와 같은 딥러닝 프레임워크에서 CrossEntropyLoss를 사용할 때, 라벨 값이 -100인 위치는 손실 계산에서 제외되도록 설계되어 있다.
- CrossEntropyLoss 함수는 각 위치에 대해 모델의 예측과 실제 정답 간의 차이를 계산해 손실 값을 만드는데, -100은 무시해야 할 라벨이라는 의미로 사용된다.
- 따라서, 패딩 토큰이 있는 위치를 -100으로 설정하면 패딩 토큰에 대한 손실 계산이 생략되어 모델이 패딩 부분을 학습하지 않게 된다.
- 토큰화된 정답 데이터를
- 예제 ID 저장
- 각 데이터 예제의 고유 ID를
model_inputs에example_id로 추가한다. - 모델이 추론을 마치고 나서 각 예제에 대해 예측한 답을 검토하거나 평가하려면, 모델의 출력이 어떤 데이터 예제에 대한 예측인지를 알 수 있어야 하는데, 이때 ID가 필요하다.
- 각 예제(
i)에 대해 라벨이 있는(학습에 사용될) 예제의 ID를 추적하여, 나중에 예측 결과와 대응할 수 있도록 하는 것이다.
- 각 데이터 예제의 고유 ID를
Generation-based MRC에는 stride가 없는 이유
- Extraction-based MRC
- Extraction-based MRC는 문맥에서 답을 직접 추출하기 때문에, 문맥을 자르고 stride를 통해 겹쳐서 처리해야 한다.
- 문맥과 질문의 길이가 모델의 최대 입력 길이를 넘어 잘릴 경우, 필요한 정보를 놓칠 수 있다. 문맥의 중요한 부분이 뒤에 위치해 있으면 모델이 접근할 수 없기 때문에 stride를 사용하여 입력을 겹치게 자르고, 여러 번의 입력으로 나누어 처리한다.
- 답변이 문맥의 뒤쪽에 있을 경우도 있으므로, 문맥의 일부가 잘리는 것을 방지하기 위해 stride를 사용하여 겹쳐서 처리하는 것이다.
- Generation-based MRC
- Generation-based MRC는 문맥의 일부 정보로도 생성이 가능하므로, stride 없이 자르기만 해도 충분한 답변을 생성할 수 있다.
- 이 방식에서는 문맥의 특정 부분을 추출하는 것이 아니라, 문맥 전체를 참고하여 새로운 문장을 생성한다. 문맥의 일부가 잘리더라도, 질문의 의미를 이해한 모델이 문맥의 앞부분에서 답을 생성할 수 있기 때문에 stride가 필요하지 않을 수 있다.
- 모델이 입력된 문맥의 일부 정보만으로도 답변을 생성할 수 있는 능력을 갖추고 있다. 또한, 답변이 문맥의 특정 위치에 한정되지 않기 때문에 잘린 문맥에서도 답변을 충분히 생성할 수 있다.
column_names = datasets['train'].column_names
# train_dataset 토큰화
train_dataset = datasets["train"]
train_dataset = train_dataset.select(range(max_train_samples))
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=False,
)
# eval_dataset 토큰화
eval_dataset = datasets["validation"]
eval_dataset = eval_dataset.select(range(max_val_samples))
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
num_proc=preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=False,
)Fine-tuning 하기
from transformers import DataCollatorForSeq2Seq, Seq2SeqTrainer, Seq2SeqTrainingArgumentsExtraction-based MRC에서는
default를 이용했는데, Generation-based MRC에서는Seq2Seq가 쓰이는 이유
- Extraction-based MRC는 질문에 대한 답을 컨텍스트 내에서 그대로 추출하는 방식으로, 이 방식에서는 모델이 입력된 컨텍스트에서 답변의 시작 위치와 끝 위치를 예측하는 것이 목표이다. 따라서 특별한 시퀀스 생성 과정이 필요하지 않고,
default_data_collator와 같은 일반적인 datacollator를 사용하여 배치를 만들면 된다.default_data_collator는 일반적인 텍스트 분류, 추출 기반 모델에서 자주 사용된다.- Generation-based MRC는 생성 기반이기 때문에 모델이 단순히 컨텍스트에서 답을 추출하는 것이 아니라, 주어진 질문에 대해 자연어로 답을 생성한다. 이때 모델은 컨텍스트를 바탕으로 새로운 텍스트를 생성하는 과정이 필요하다. 따라서 Seq2Seq(Sequence-to-Sequence) 구조가 적합하며,
DataCollatorForSeq2Seq는 이러한 시퀀스 생성 작업을 위한 맞춤형 데이터 처리기를 제공한다.
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
features = [train_dataset.remove_columns('example_id')[i] for i in range(5)]
examples = data_collator(features)
examples.keys()featurestrain_dataset에서example_id열이 제거된 후, 첫 5개의 샘플을 포함하는 리스트- 각 샘플은 딕셔너리 형식으로 나타내며, 모델에 입력할 때 필요한 정보(질문, 문맥, 정답 등)를 포함
data_collator- 앞서 생성한
features를 인자로 받아 배치 데이터를 준비 - 입력 시퀀스와 레이블에 대한 패딩, 마스킹, 토큰화 등의 작업 수행
- 결과적으로
examples에는 모델 학습에 필요한 형태로 처리된 데이터 배치가 포함
- 앞서 생성한
examples.keys()examples는 Data Collator에 의해 처리된 결과로, 이 객체의 키를 반환- 일반적으로 모델 학습에 필요한 다양한 구성 요소(입력 ID, 어텐션 마스크, 레이블 등)의 키를 포함하며, 각 키는 모델이 필요로 하는 특정 정보를 나타냄
examples의 키를 확인하여 모델 학습에 필요한 데이터 구조를 이해하려는 것dict_keys(['input_ids', 'attention_mask', 'labels', 'decoder_input_ids'])
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels # 후처리된 예측 결과(preds), 레이블(labels) 반환Extraction-based MRC와 Generation-based MRC의 후처리 함수 비교
- 전반적인 후처리 함수 내용
- Extraction-based MRC의 후처리 함수는 모델이 출력한 시작과 종료 로짓을 기반으로 원래 문맥에서 답변을 추출하고, 이를 사람이 읽을 수 있는 형식으로 변환한다.
- Generation-based MRC의 후처리 함수는 모델이 생성한 문장을 가독성이 좋은 형태로 다듬고, 실제 레이블과 비교하여 정리한다.
- 두 후처리 함수 모두 예측된 답변과 실제 정답을
preds와labels로 구성하여 반환함
- Predictions (
preds): 모델이 예측한 답변
- Extraction 방식은 예측 결과에 ID를 포함하여, 각 예측이 어떤 질문에 대한 것인지 명확하게 표시
- Generation 방식은 모델이 생성한 문장만 반환하며, ID를 포함하지 않음
- Labels (
labels): 데이터셋에 포함된 레이블로, 각 질문에 대해 모델이 예측해야 하는 올바른 답변
- Extraction 방식은 레이블에 ID를 포함하여 각 레이블이 어떤 질문에 대한 것인지 명확하게 표시
- Generation 방식은 데이터셋에 주어진 정답(answer)만을 반환하여, 모델의 예측(
preds)과 비교하는 방식으로 성능을 평가
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
# preds/labels 배열에서 -100을 패딩 토큰으로 변경한 후 디코딩
# 예측된 토큰/정답 토큰을 사람이 읽을 수 있는 텍스트로 변환한다. skip_special_tokens=True는 특별한 토큰(예: <pad>, <sos> 등)을 제외한다.
preds = np.where(preds != -100, preds, tokenizer.pad_token_id)
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# decoded_labels is for rouge metric, not used for f1/em metric
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing: 디코딩된 예측과 레이블에 대해 후처리를 수행한다.
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
# 포맷팅: 모델의 예측 결과를 평가할 수 있는 적절한 형식으로 변환
formatted_predictions = [{"id": ex['id'], "prediction_text": decoded_preds[i]} for i, ex in enumerate(datasets["validation"].select(range(max_val_samples)))]
references = [{"id": ex["id"], "answers": ex["answers"]} for ex in datasets["validation"].select(range(max_val_samples))]
# 포맷팅된 예측과 레퍼런스를 사용하여 메트릭(F1 점수, EM(Exact Match) 점수, ROUGE 등)을 계산한다.
result = metric.compute(predictions=formatted_predictions, references=references)
return resultargs = Seq2SeqTrainingArguments(
output_dir='outputs',
do_train=True,
do_eval=True,
per_device_train_batch_size=train_batch_size,
per_device_eval_batch_size=eval_batch_size,
predict_with_generate=True,
num_train_epochs=num_train_epochs,
save_strategy = 'epoch',
evaluation_strategy = 'epoch',
save_total_limit = 2, # 모델 checkpoint를 최대 몇개 저장할지 설정
logging_strategy = 'epoch',
load_best_model_at_end = True,
learning_rate = learning_rate,
remove_unused_columns = True
)trainer = Seq2SeqTrainer(
model=model,
args=args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics,
)trainer.train()평가하기
trainer.evaluate(max_length=max_target_length, num_beams=num_beams, metric_key_prefix="eval")- 훈련된 모델을 사용하여 검증 데이터셋에 대한 성능을 측정하기 위해 EM, F1 Score을 사용한다.
def generarate_answer(sample):
inputs = f'question: {sample["question"]} context: {sample["context"]} </s>'
print(inputs)
sample = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True, return_tensors='pt')
sample = sample.to("cuda:0")
outputs = model.generate(**sample, max_length=max_target_length, num_beams=num_beams)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True)
pred = "\n".join(nltk.sent_tokenize(pred))
return predgenerarate_answer함수는 하나의 데이터 샘플을 받아 질문에 대한 답변을 생성하고 반환한다.inputssample에는 질문(question)과 문맥(context)이 포함되어 있어, 이를 포맷팅하여 모델이 이해할 수 있는 입력 형태로 변환한다. 이 경우question과context를 하나의 문자열로 결합하고, 끝에 문장의 끝을 나타내는 특별한 토큰</s>를 붙인다.
sample- tokenizer로
inputs을 토크나이징하고, 이를 텐서로 변환한다. - 모델이 GPU에서 동작할 수 있도록 입력 데이터를 CUDA 장치로 이동시킨다.
- tokenizer로
outputsmodel.generate를 사용하여 모델이 답변을 생성한다.max_length로 생성된 답변의 최대 길이를 설정하고,num_beams로 Beam Search 알고리즘에서 사용할 빔의 개수를 설정한다. 더 높은 값은 답변의 다양성을 향상시키지만, 속도는 느려질 수 있다.
pred- 생성된 답변(
outputs)을 다시 텍스트 형태로 변환한다. (토큰 디코딩) skip_special_tokens=True는 특수 토큰(<pad>,</s>등)을 무시한다.- NLTK(Natural Language Toolkit)의
sent_tokenize를 사용하여 생성된 답변을 문장 단위로 분할한 후, 여러 줄로 변환한다.
- 생성된 답변(
- 최종적으로 문장 단위로 분리된 답변을 반환한다.
# 랜덤한 데이터 샘플에 대해 답변 생성
np.random.seed(seed=7777)
for i in np.random.randint(0, len(datasets["validation"]), 5):
print(generarate_answer(datasets["validation"][int(i)]))
print("=" * 8)question: 유아인이 배우로서 처음으로 부산국제영화제에 참석한 년도는? context: 2006년 1월 스크린 데뷔작인 독립영화 《우리에게 내일은 없다》의 촬영을 시작했다. 이 영화를 연출한 노동석 감독은 오디션을 볼 당시 유아인에게 극 중 캐릭터에 대해 묻자 창 밖을 한참 바라보며 “슬프죠”라는 한 마디만을 던진 모습이 인상적이었다며 캐스팅의 이유를 밝혔다. 유아인은 이 영화에서 진짜 총을 구해 현실로부터 자신을 구해내려는 소년 ‘종대’ 역할을 맡았는데, 인터뷰에서 "종대처럼 사건에 휘말린 적도 없고 불우한 환경에서 자라지도 않았지만 제가 종대와 비슷한 시기에 느꼈던 불안이나 두려움 등이 연기를 하는 데 큰 도움이 됐습니다. 종대도 청춘이고 저도 청춘이니까요"라며 연기를 한 소회를 밝혔다. 2007년 5월 《우리에게 내일은 없다》 언론시사회에서는 작품에 대해 “배우라는 앞날에 대한 꿈을 꾸고 그림을 그렸다면 그 그림 속에 꼭 있어야 할 영화”라며 본인의 영화 데뷔작에 대한 애정을 드러낸다. 또한 배우로서 고유한 소년성을 갖게해 준 ‘첫 활시위’ 같은 작품이라고 설명한다. 2006년 10월 유아인은 이 영화를 통해 배우로서 처음으로 부산국제영화제 개막식과 GV에 참석한다. </s>
2006년
========
question: 김희선이 4년만에 브라운관에 컴백한 인기 드라마 <야마토 나데시코>를 원작으로 한 로맨스 드라마는? context: 김희선은 2000년대에 접어들면서 스크린으로 활동 무대를 옮겨 드라마 출연을 한동안 중단하였다. 영화 《와니와 준하》(2001), 《화성으로 간 사나이》(2003)에 출연했지만 번번히 이렇다 할 흥행을 거두지 못한 채 2003년 일본의 인기 드라마 《야마토 나데시코》를 원작으로 한 로맨스 드라마 《요조숙녀》로 4년여만에 브라운관에 컴백하였다. 하지만 이 작품은 진부한 설정과 스토리로 기대 이상의 주목은 받지 못했다. 이듬해, 2004년에는 한류를 겨냥한 멜로 드라마 《슬픈 연가》에서 출연하였지만 남자주인공 중 한 명인 송승헌이 병역비리 조사를 받게 되면서 제작 난항을 겪기도 했다. 2005년, 중국 영화 《신화 - 진시황릉의 비밀》으로 첫 해외 작품에 참여하며, 성룡과 호흡을 맞췄으며, 2006년에 2년 만의 브라운관 컴백작인 드라마 《스마일 어게인》 이후 연예계 활동을 전면 중단했다. </s>
요조숙녀
========
question: 세계 체스 선수권에서는 처음 40수에 대하여 각각 몇 분이 주어지나? context: 시간제한이 주어진 대국에 대해서 "타임 컨트롤"이 적용되었다고 한다. 일반적으로 시간제한이 있을 경우 자신에게 주어진 시간을 모두 사용하면 자동으로 경기에서 패배하게 된다. 그러나 자신의 시간을 모두 사용했음에도 불구하고 상대방이 자신을 체크메이트 할 수 없는 상황이었다면 무승부가 된다. 체스에서 타임 컨트롤을 하는 방법은 다양하다. 각 선수마다 경기 전체에 대한 시간을 할당받을 수도 있고, 몇 수마다 시간을 할당받을 수도 있다. 마지막으로 경우에 따라서 한 수를 둘때마다 몇초씩 시간을 더 주기도 한다. 예를 들어 세계 체스 선수권에서는 처음 40수에 대하여 각각 120분, 다음 20수에 대하여 각각 60분씩, 그 이후의 모든 수에 대하여 각각 15분+30초씩(나머지 모든 수에 대해서 개인당 15분의 시간이 주어지며 한번 수를 둘 때마다 개인 시간이 30초 추가됨) 주어진다. </s>
60분
========
question: 김영삼은 누구의 강요로 1980년 10월 은퇴를 선언하였는가? context: 1980년 9월 출범한 전두환의 제5공화국 정권에서도 계속된 가택 연금과 정치적 탄압에 항의하며 장기간의 단식 투쟁을 단행하여 세계의 주목을 받았다. 같은해 10월 김영삼은 보안사 대공처장 이학봉의 강요로 정계 은퇴 선언을 발표하였다. 1981년 5월 연금에서 해제된 김영삼은 이민우(李敏雨)·김동영(金東英)·최형우(崔炯佑)·김덕룡(金德龍) 등 정치활동 규제에 묶여있는 재야 인사들과 함께 등산모임을 조직하고 민주산악회를 출범시켰다. 민주산악회의 참가자가 증가하면서 김영삼은 1981년 6월 9일 공식기구로서 출범하는데 동참하였다. 공식 기구로 출범한 민주산악회는 이민우를 회장으로 선출하고 김영삼을 고문으로 추대하였다. 그 뒤 민주산악회는 주요 정치적 사건에 대한 성명서를 발표하고 지방조직을 확대하는 등의 사실상의 정치적 활동을 하였으며 한편 김대중 계열 정치인들도 민주산악회의 활동에 가담하여 적극 협력하며 야권통합과 범국민조직의 필요성을 강조했다. 이에 따라 김영삼 계열 정치인들은 김대중 계열까지 흡수하여 재야정치인들의 통합조직을 준비, 민주산악회를 모체로 하는 통합협의체의 구성에 합의하였다. </s>
이학봉
========
question: 오다 노부나가가 아카마쓰 마사히데와 손을 잡고 우라가미 무네카게에게 반란을 일으켰던 시기는 언제인가? context: 에이로쿠 12년(1569년), 오다 노부나가와 서 하리마의 아카마쓰 마사히데(赤松政秀)와 손을 잡고 주군 우라가미 무네카게에게 반기를 든다. 그러나 아카마쓰 마사히데가 구로다 모토타카(黒田職隆)·요시타카(孝高, 후의 간베에) 부자에게 패배하고, 노부나가가 파견한 이케다 가쓰마사(池田勝正)·벳쇼 야스하루(別所安治)등도 오다 군의 에치젠 침공 때문에 돌하가는 등 악재가 겹쳐, 역으로 무네카게가 약해진 아카마쓰 마사히데의 다쓰노 성(龍野城)을 공격하여 항복을 받아내었다. 이에 따라 우군을 모두 잃게 된 나오이에는 완전히 고립되었기 때문에 스스로도 항전이 불가하다고 판단하여 무네카게에게 항복할 수 밖에 없게 되었다. 이 때는 특별히 용서 받아 목숨을 구하고 귀순을 허락받았다. </s>
에이로쿠 12년
========