
목차
- Semantic Segmentation
- Classification + Localization
- Object Detection
- R-CNN
- Fast R-CNN
- Faster R-CNN
Semantic Segmentation

단점: cow 두 마리를 하나의 덩어리로 분류함
이미지의 각 픽셀이 어떤 클래스에 속하는지 예측하는 작업. Classification과 마찬가지로 미리 클래스의 수와 종류를 정해 놓아야 한다.
알고리즘 종류
Sliding Window
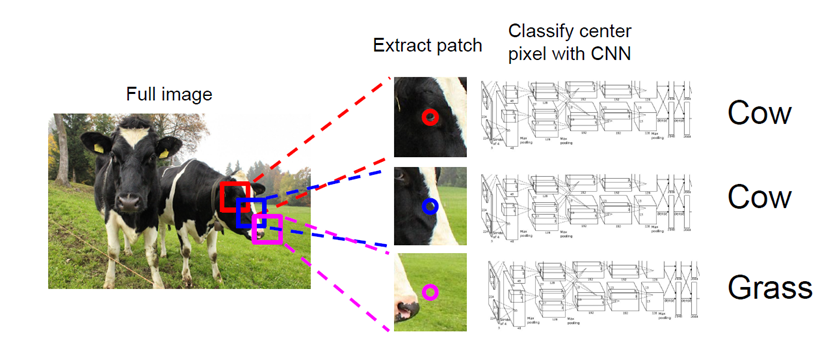
작동 방법
작은 ‘window’를 이미지 전체를 움직여 가면서(slide하면서) 해당 윈도우 내에 cow 또는 grass가 있는지 분류기로 판별한다.
이때 분류기는 이미 학습된 것이고, 분류기는 cow, grass 등 특정 객체의 특성을 학습한다. 보통 SIFT, SURF 등 특성 추출 알고리즘을 사용한다.
단점
- Computational Cost가 매우 높다.
- 각 pixel(=윈도우)마다 pixel중심으로 crop을 진행한다. → CNN에 crop한 이미지들을 전부 넣으니 연산이 많아진다.
- Sharing computation이 고려되지 않았다.
- 각 pixel마다 crop을 진행할 때, 이웃 pixel들은 crop한 영역이 필연적으로 겹치게 된다. 이 겹치는 부분을 매번 다시 계산하고 이건 매우 비효율적이다. 이 중복되는 computation에 대한 처리가 없어 효용이 떨어진다.
Fully Convolutional
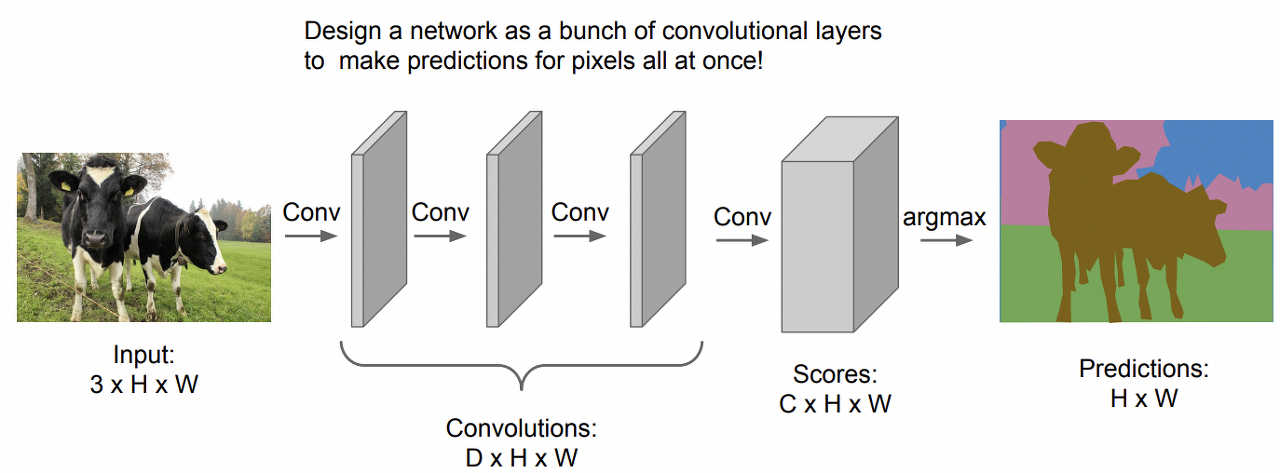
작동 방법
이미지 한장을 CNN에 통째로 통과
단점
training data 한장을 만드는데 오래 걸리고, high resolution(해상도)을 끝까지 유지한다는 점에 있어서 computational cost가 너무 부담스러워짐
Fully Convolutional with downsampling / upsampling
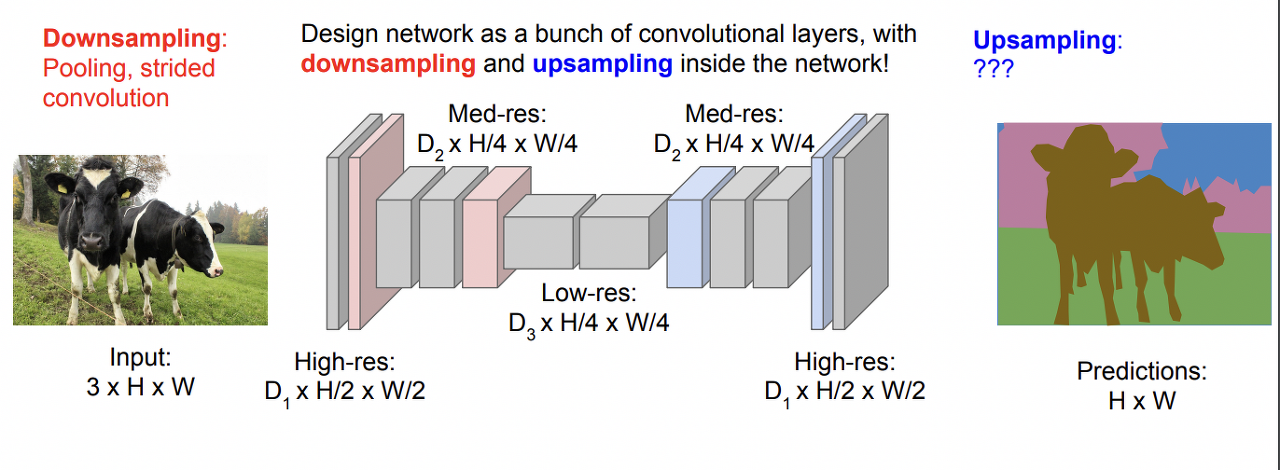
작동 방법
원본 resolution에서 시작해 downsample을 몇차례 거치면서 해상도를 낮추다가, 중간부터는 다시 upsampling으로 해상도를 올리는 방식
- 장점
높은 resolution을 유지하기 위한 computation cost 문제를 어느 정도 해결할 수 있다. 중간 단계에서는 낮은 resolution을 사용하지만 input과 output의 사이즈가 결과적으로 동일하기 때문.
Upsampling
목적
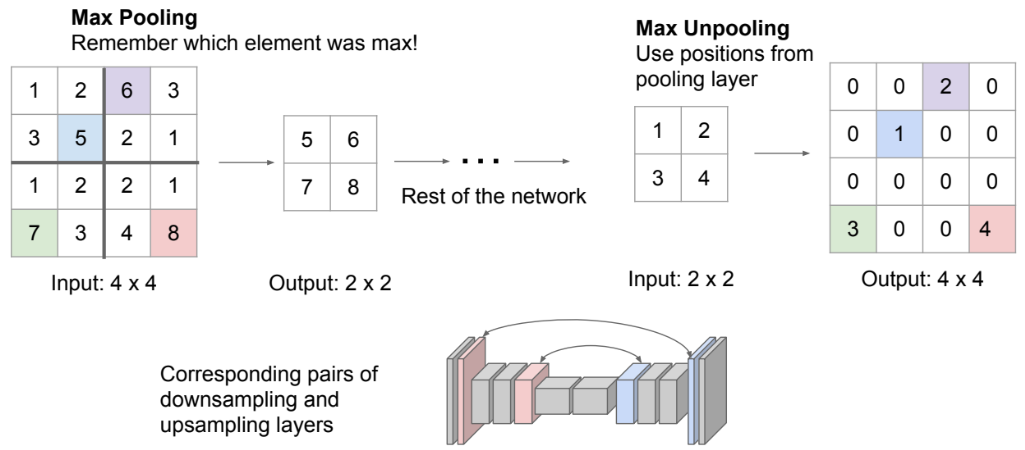
낮은 해상도(resolution)의 이미지를 더 높은 해상도로 변환하기 위해. Max Unpooling 대부분의 네트워크가 downsampling 과정을 거칠 때 Maxpooling 과정을 거치는데 네트워크가 주로 대칭적인 특징을 가지고 있어 그 위치로 Upsampling을 해줘야 한다.
작동 방식
이미지의 사이즈를 늘리면 0으로 된 빈 공간이 발생한다. 이 빈 공간을 채우는 작업.
기법 종류
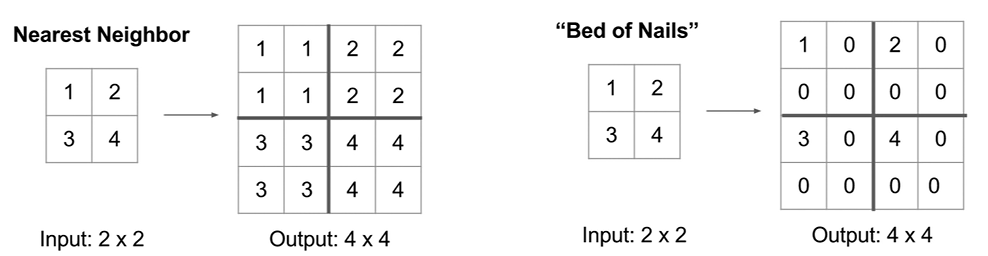
- Unpooling: 단순하게 채우는 방법 (Nearest Neighbor: 단순하게 같은 값으로 복붙.
- Bed of Nails: 원래 픽셀 위치의 값을 그대로 유지하고 나머지 위치의 값을 0으로 설정)
- Max Upooling: 픽셀의 가장 큰 값의 위치를 기억하여 그 위치로 Upsampling.
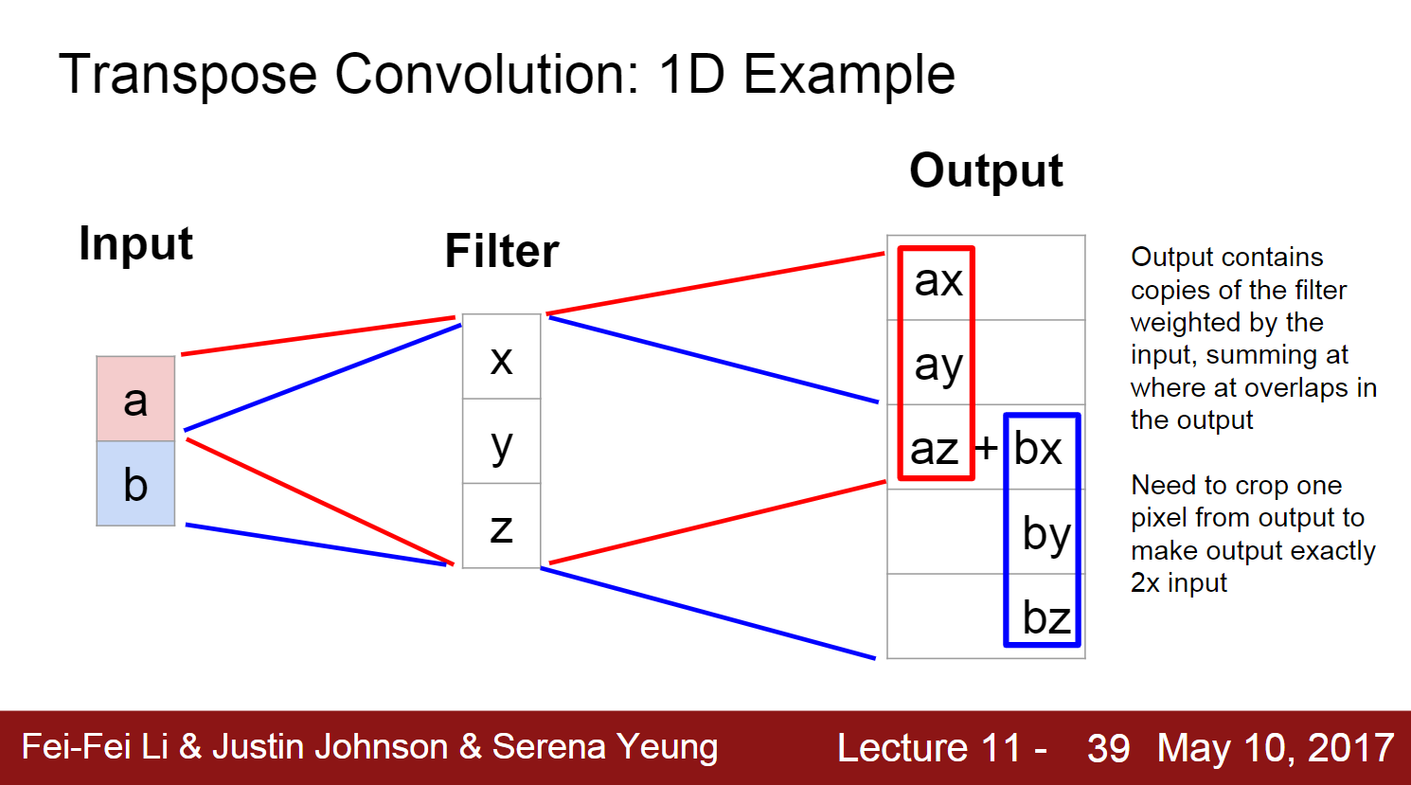
- Transpose Convolution
- 일반적인 convolution의 '역' 과정을 수행하는 합성곱.
- 이미지의 해상도를 높이면서도 이미지의 특징을 유지할 수 있다.
- 과정
- 이미지의 입력 feature map 주위에 zeropadding하여 공간을 만든다. (zeropadding으로 출력 이미지의 더 넓은 영역에 영향을 미치게 됨) 그리고 늘어난 공간에 대해 Convolution 연산을 수행한다.
- 입력 이미지의 각 픽셀* 필터의 가중치를 필터의 복사본이라고 한다. 이 복사본은 한 픽셀마다 여러 픽셀을 생성한다. 즉, 픽셀이 분산된다. 그리고 겹치는 부분은 더해서 계산된다.
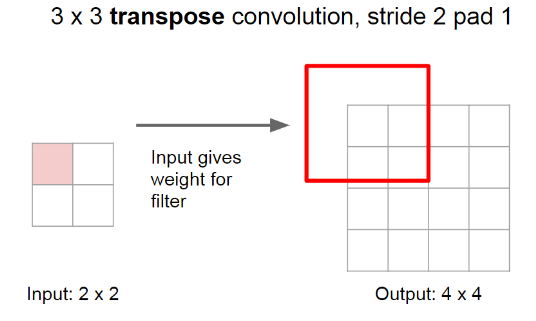
겹치는 부분을 더 자세하게 보여주는 사진

3x3 필터, stride=2인 경우다. 겹치는 부분은 값을 더해준다.
특징맵의 스칼라값(분홍색)을 선택하여 필터와 곱한다.
cs231n - 11강 - Detection and Segmentation ← Transpose Convolution gif 참고
- Convolution 연산과의 차이점
- 일반적인 Convolution 연산: 필터가 이미지를 스캔하면서, 필터 내의 가중치와 입력 이미지의 픽셀 값을 곱한 후 이를 모두 더하여 출력 값을 만든다. 이 출력 값은 출력 이미지의 한 픽셀에 대응된다. 즉, 여러 입력 픽셀이 하나의 출력 픽셀에 영향을 미친다.
- Transpose Convolution 연산: 입력 이미지의 각 픽셀 값에 필터의 가중치를 곱한 값이 출력 이미지의 여러 픽셀에 분산되어 더해진다. 즉, 한 입력 픽셀이 여러 출력 픽셀에 영향을 미친다. → 이미지의 해상도를 높이면서도 이미지의 특징을 유지하는 것이 가능함.
Classification + Localization

- Classification: 이미지를 'Cat'이라고 분류.
- Localization: 'Cat'의 위치를 Bounding box를 그려 파악.
구조, 과정

기본적으로 image classification 과정과 비슷한데, fc layer가 하나 추가되어 총 2개의 fc layer가 있다. 하나의 fc layer(위)는 이미지 분류처럼 class 별로 점수를 매기고 카테고리를 결정한다. 또 하나의 추가된 fc layer(아래)는 box의 위치를 조정한다. 즉, [width, height, x, y]값을 조정해서 박스의 위치, 크기를 정한다. 따라서 학습을 시킬 때 2개의 Loss function을 사용한다.
사진에서 “4096 to 1000”: 사진속 순서도의 모델은 객체를 1000개의 클래스로 분류한다. 이전 layer에 4096개의 뉴런이 있고, 마지막 fc layer에는 1000개의 뉴런이 있다. 1000개의 뉴런이 각 다른 클래스에 대응하며, 각 뉴런의 출력값이 해당 클래스의 점수를 나타낸다. 이 FC layer를 통과한 후에는 이미지가 1000개의 다른 클래스 중 하나에 속할 확률을 나타내는 점수를 얻게 된다.
Object Detection
Object Detection은 한 장의 이미지에서 다수의 물체를 찾고, 그 물체가 어디 있는지 알아내는 Task.
Classification + Localization과 다른 점: 이미지마다 몇 개의 객체가 있는지 정해지지 않아서 더 어려운 task다.
알고리즘 종류Regression
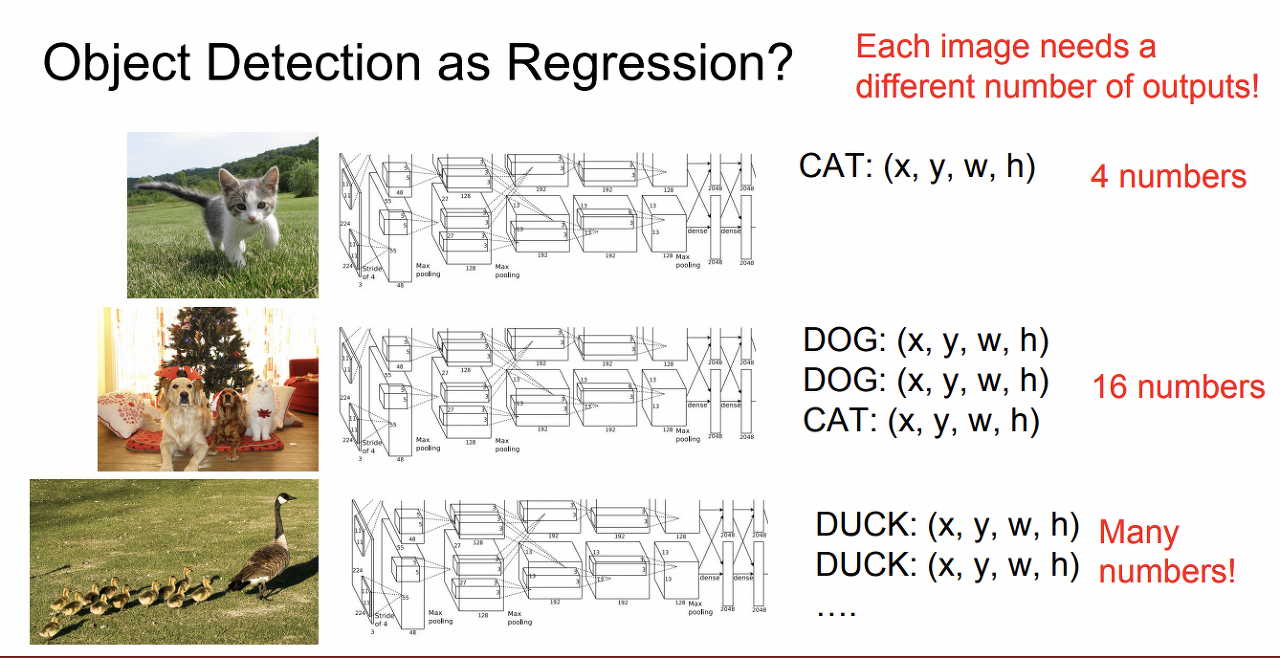
1개의 객체 당 x좌표, y좌표, box의 가로, 세로 4개의 수가 필요함
box의 위치, 크기로 회귀를 돌려서 알아내는 방법.
단점: output의 개수가 정해져 있지 않아서 어렵다. 좌표를 regression으로 예측하는 것도 까다롭다.
Sliding Window
sliding window를 사용해서 각 crop마다 어떤 class에 속하는지 하나하나 분류한다.
단점: 어떤 좌표에 어떤 크기로 crop할지 어려움. 모든 면적에 window를 지나치면서 모든 경우의 수를 계산하는 게 불가능에 가깝다.
Region Proposal

DL아니고 Rule based이지만 network에서 많이 활용되는 방법으로, 이미지 픽셀의 컬러, 무늬, 크기, 형태에 따라 유사한 Region(즉, 특정 객체가 존재할 가능성이 있는 지역)을 계층적 그룹핑 방법으로 계산하는 방식이다.
계층적 그룹핑: 유사한 특징을 가진 픽셀을 그룹으로 만드는 과정을 여러 단계에 걸쳐 수행하는 그룹화 방법. 먼저, 가장 유사한 픽셀들이 그룹으로 묶인다. 그리고 이러한 작은 그룹들이 유사한 더 큰 그룹으로 묶인다.
R - CNN (R: region)
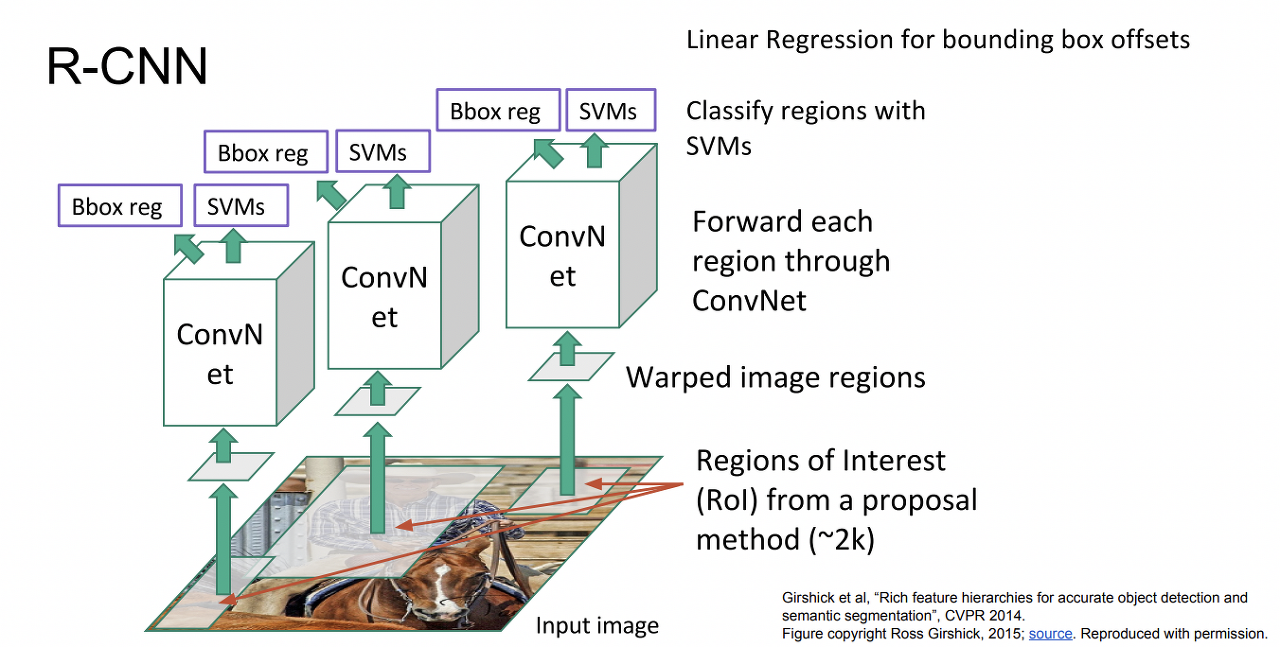
warp: 뒤틀리게 만들다동작 과정
- Region Proposal 방식을 사용해서 ROI(Reason of Interest, 관심 영역)를 추출한다. roi란, 이미지에서 특정 물체나 특이점을 찾기 위해 관심을 두고 보는 영역이다.
- ROI를 cnn에 training하기 위해 input size를 동일하게 맞춘다.
- cnn을 통과한 후, svm을 통해 classification과정을 거친다.
- Linear Regression을 통해서 Bounding Box도 Loss값을 계산하고, 두 개의 loss가 최소가 되는 방향으로 training시킨다.
단점
- 계산 비용 높다.
- 용량 많이 든다.
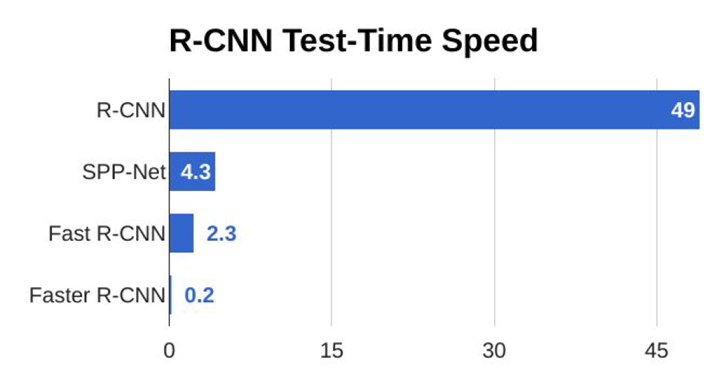
- 학습 과정 느린다. (논문 기준 81시간)
- test time 느리다 (한 이미지당 30초)
- 학습 되지 않는 Region Proposal이 존재한다.
Fast R - CNN
r - cnn에서 계산 비용이 많이 드는 이유를 각각의 ROI 영역에서 cnn과정을 진행했기 때문이라고 생각하고 fast r-cnn에서는 input 이미지에 대해 한 번의 cnn과정을 거친다. 이미지를 통째로 COnv Net에 넣어 추출한 feature map에서 ROI(Regions of Interest)를 추출한다. 나머지 과정은 r-cnn과 동일하다.
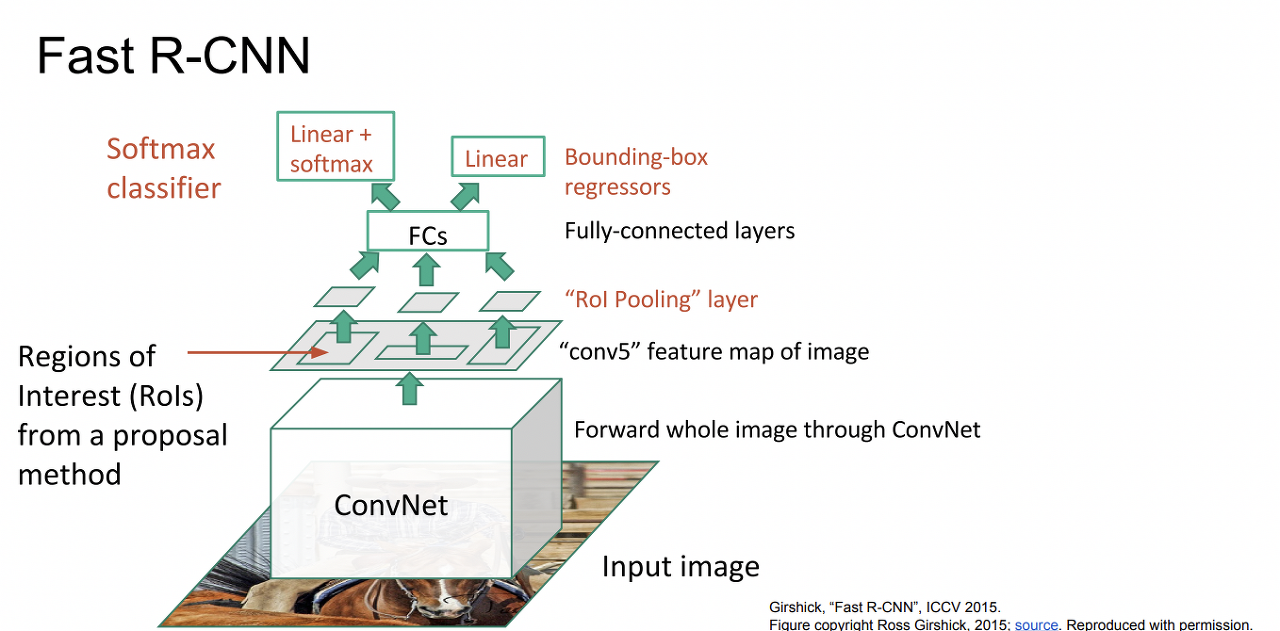
동작 과정
- feature map에서 Region proposal을 찾아낸다. 이 때, ROI 영역에 모둔 다른 Issue가 발생한다. 일반적인 방법으로 Pooling을 통해 Input Size를 맞춰주어야 하는데 ROI가 다르기 때문에 일반적인 Pooling으로는 Input Size가 맞춰지지 않는 문제가 발생한다.
- ROI pooling 과정을 거쳐 Feature map의 Size를 통일시킨다.
- feature map의 size를 통일하는 이유: feature map을 FC Layer에 input으로 넣어야 하는데 FC Layer는 동일한 크기의 입력을 필요로 한다.
- FC Layer를 통해서 Classification에 대한 Loss 값을 계산한다.
Bounding Box에 대한 Loss 값을 계산한다.
장점
R-CNN에서는 ROI마다 ConvNet을 따로 적용하기 때문에 연산 시간이 매우 길었다. 반면, Fast R-CNN에서는 전체 이미지를 한 번에 Conv Net에 통과시키므로 연산 시간을 단축 시켰다.
R-CNN에서는 단순 rule-based 방식인 Region Proposal 과정으로 ROI를 지정하였다. 반면 Fast R-CNN에서는 이미지가 Conv Net을 통과한 결과인 feature map에서 ROI을 찾는다. 즉, ROI의 후보들을 정하는 과정에서 딥러닝을 사용하기 때문에 학습 되지 않는 Region Proposal을 줄일 수 있다.
단점
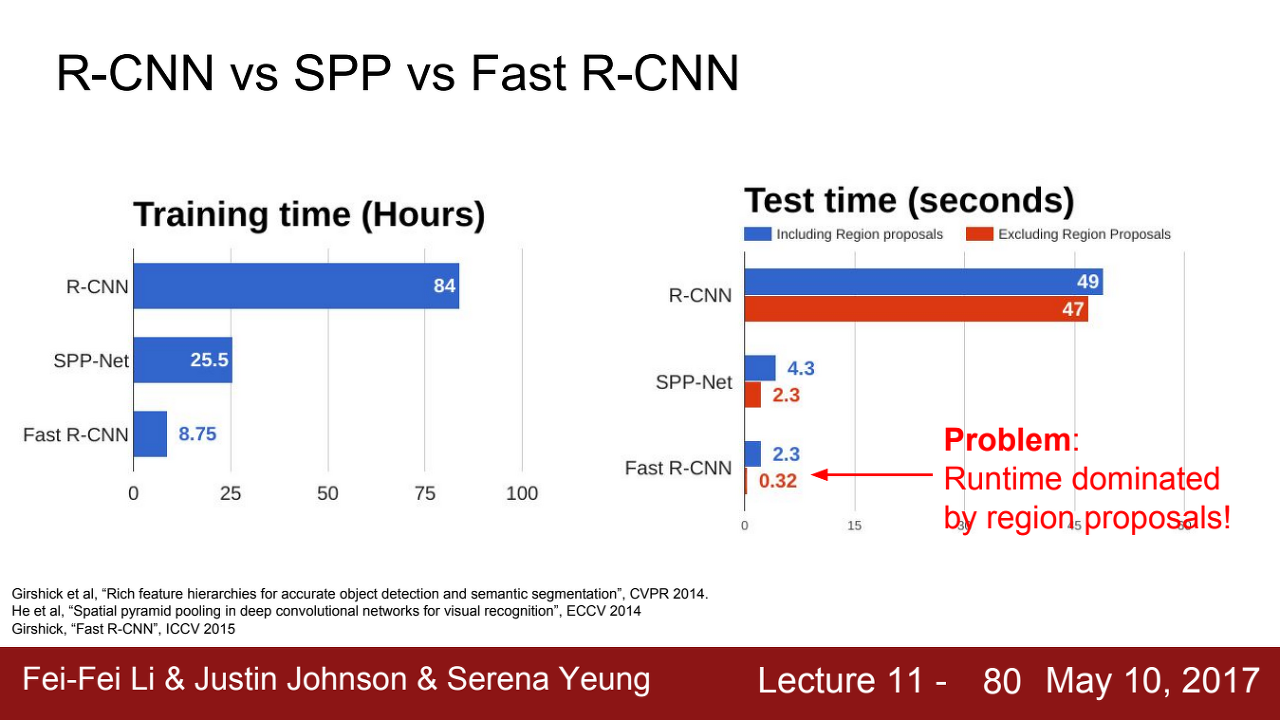
fast r-cnn이 r-cnn보다 훨씬 빠르지만, 여전히 Selective search 알고리즘을 통해 region proposals 추출하기 때문에 학습 및 detection 속도를 향상시키는데 한계가 있다. 2000개의 roi를 찾아내는 데에 2초나 소요한다.
Faster R-CNN
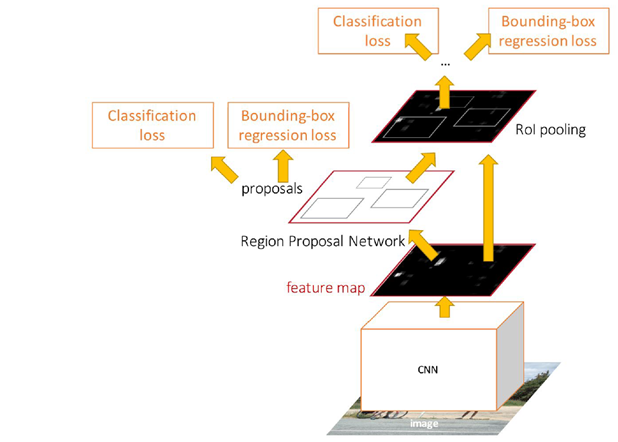
위 그림 부분을 제외하면 fast r-cnn과 구조가 유사함
fast r-cnn에서 문제가 된 bottlenect(병목 현상, 2초나 걸리는 부분)을 해결하기 위해 만들어졌다.
Feature map을 만드는 CNN과 그 이후 classification + localization하는데 사용하는 CNN을 공유해서 사용하자는 아이디어에서 출발했다.
Region Proposal을 Network로 따로 만들어 전체 Network내부에서 처리하기 때문에 병목현상이 발생하지 않는다.
RPN(Region Proposal Network)
이미지 내에서 객체가 있을 법한 후보 영역 추출 작업을 수행하는 네트워크
RPN이 보다 정교하게 region proposal을 추출하기 위해 도입된 개념
Anchor box
다양한 크기와 가로세로비를 가지는 bounding box
동작
- 원본 이미지를 CNN 모델에 통과시켜 feature map을 얻는다.
- feature map은 RPN에 전달되어 적절한 region proposals을 산출한다.
- region proposals와 a. 과정에서 얻은 feature map을 통해 ROI pooling을 수행하여 고정된 크기의 feature map을 얻는다.
- Fast R-CNN 모델에 고정된 크기의 feature map을 입력하여 Classification과 Bounding box regression을 수행한다.
Loss function
4개의 loss function을 사용한다.
- RPN classify object / not object (binary classification): 객체 존재 여부 판별. 앵커 박스에 대한 객체 존재 확률을 계산하며, 이를 통해 객체 후보 영역을 선정한다.
- RPN regress box coordinates: RPN에서 앵커 박스의 좌표를 조정하는 과정에 사용된다. 앵커 박스의 위치와 크기를 실제 객체에 더 잘 맞도록 수정하는 회귀 작업을 수행한다.
- Final classification score (object classes): 최종적으로 객체의 클래스 분류를 하는 과정에 사용된다. ROI Pooling을 거친 후보 영역들에 대해, 각각 어떤 클래스의 객체인지를 분류한다.
- Final box coordinates: 최종적으로 객체의 bounding box 좌표를 조정하는 과정에 사용된다.
r-cnn 시리즈 중에 제일 발전된 모델이고 제일 빠르다.
faster r-cnn 출처: https://herbwood.tistory.com/10
