
목차
- Visualizing - ConvNet 안에서는 어떤 일이 일어나고 있을까?
- 시각화 실험 예시들
- Gradient Ascent
- Feature Inversion
- Texture Synthesis
- Neural Style Transfer
ConvNet 안에서는 어떤 일이 일어나고 있을까? (Visualizing)
- visualizing이 중요한 이유:
딥러닝이 잘 작동하는 이유를 설명하기 위해, 딥러닝이 잘 작동되어도 딥러닝을 믿지 못하는 연구자들에게 딥러닝의 내부 동작을 보여줌으로써 해석 가능한 부분이 있다는 것을 알려주기 위해!
layer visualization
첫번째 layer

alexnet 첫번째 conv의 결과로는 31111 크기의 feature map이 출력된다. 필터의 가중치와 입력 이미지의 내적을 통해 구해진다. 위 그림은 feature map을 시각화 한 것. 보통 edge나 보색 등을 찾아낸다.
첫번째 레이어는 이미지와 가장 가까운 층이다. 이미지 내 edge같은 특징을 추출하기 위해 사용된다.
중간 layer

첫번째 feature map의 특징들에서 한 번 더 특징을 뽑아내는 것이기 때문에 인간이 해석하기가 쉽지 않다.
- layer 1: 7x7 이미지가 3개의 채널(rgb)의 값으로 16개의 필터로 나타내지는 것을 표현함.
- layer 2: 7x7 이미지가 16개의 채널씩 20개의 필터,
- layer 3: 7x7 이미지가 20개의 채널씩 20개의 필터로 나타내지는 것을 표현함.
Visualzing Activations

모든 중간 레이어가 해석이 어려운 것은 아니다.
AlexNet의 conv5 activation map에서, 사람 사진을 입력했을 때 얼굴의 모양과 위치가 비슷한 image를 확인할 수 있었다. 활성화 맵을 통해서 이미지의 특징들이 추출되는 것을 확인할 수 있다.
마지막 layer (FC layer)

사진 예시: Nearest Neighbor Algorithm(2강에서 나옴)의 last layer인 fc layer의 시각화.4096개의 dimension을 가진다. 픽셀 공간에서 벗어나게 되면서 근접한 이미지의 특징을 잘 추출 할 수 있게 된다. 가운데 표에서 test 이미지: 가장 왼쪽 열
신기한 점은 test 이미지 중 코끼리 그림에서 코끼리가 왼편에 있는데 비슷한 이미지로 선정된 이미지는 모두 코끼리가 오른편에 서있다. 실제 픽셀에서는 이 두 사진은 완전히 다른 픽셀로 이루어져 있다. 하지만 특징 공간에서는 이들을 비슷한 이미지로 인식한다. loss fuction을 통해 학습한 것이 아니라 네트워크를 거치며 저절로 학습된 것이다.
차원축소 시각화
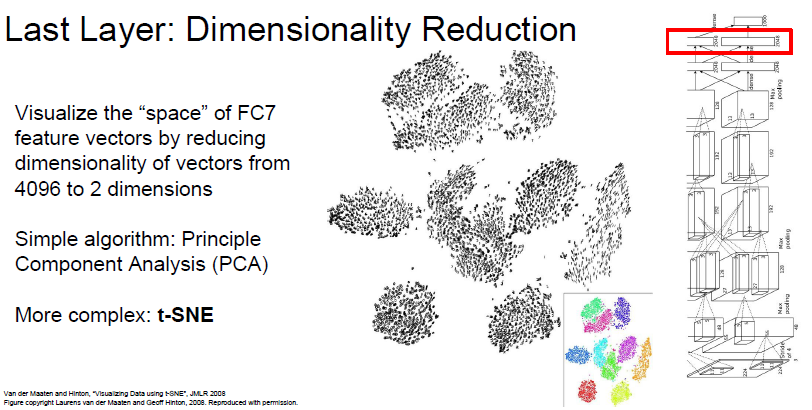
4096개 차원의 특징 벡터를 PCA와 t-SNE으로 2차원으로 차원축소하고 시각화했다. 같은 class들의 이미지끼리 가깝게 분포한다는 걸 알 수 있다.
Maximally Activating Patches
개념
CNN에서 특정 필터가 가장 강하게 반응하는, 즉 가장 높은 활성화 값을 가지는 이미지 부분.
위에서는 고정적인 하나의 이미지가 들어왔을 때 각 layer에서 어떤 반응을 보이는지 관찰했다. 아래 실험에서는 모델에 어떤 이미지가 들어와야 각 뉴런들의 활성화가 최대가 되는지 알아보았다.

랜덤으로 17번째의 channel에서 이미지의 일부분을 시각화 했다. 오른쪽 사진 모음의 각 row별로 비슷한 이미지의 특징이 활성화되었다고 추측할 수 있다.
Occlusion Experiments
목적
입력의 어떤 부분이 Classification을 결정했는지 알아보기 위해

오른쪽 노랑~빨강 차트는 이미지의 일부를 가린 후 각 부분의 스코어를 나타낸다. 노란색 지역은 확률 값이 높음을 의미한다
동작 방법
입력 이미지의 일부분을 가린 후 분류를 잘 하는지 확인한다. 만약 입력 이미지의 일부를 가렸는데 네트워크 스코어에 변화가 있다면 네트워크가 그 부분을 분류를 하는데 크게 본다고 해석할 수 있다.
go-kart의 이미지에서는 초록색 카트를 가렸다. 사진 속 앞쪽의 초록 go-kart 부분 위치가 빨간색으로 표시된다. 이 이미지를 분류할 때 초록 go-kart를 많이 고려한다는 뜻이다.
Saliency Maps (saliency: 중요한)
목적
어떤 픽셀을 보고 이미지를 분류했는지 알아보는 시각화 기법.
동작 방법
입력 이미지의 각 픽셀들에 대해서, 예측한 class score의 gradient를 계산한다.

개 이미지를 saliency map으로 나타내면 개의 윤곽을 그리며 시각화된다.
Guided Back Propagation
이미지의 중간의 뉴런을 하나 뽑아서 이미지 픽셀에 관련된 뉴런의 기울기를 구한다.
이미지의 어떤 부분이 내가 선택한 뉴런에 영향을 주는 것인지 알아본다.
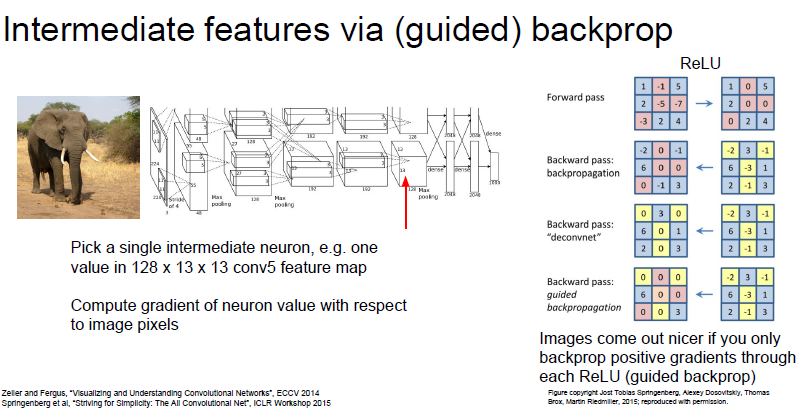

네트워크를 구성할 때 ReLU를 이용하여 Activation function을 구성하는 일이 많은데 ReLU의 양수 gradient값만(negative 부분은 relu 함수에서 전부 0이므로) 살려서 구하면 훨씬 선명하게 활성화된 위치를 파악할 수 있다.
Gradient Ascent
gradient decent
보통 gradient를 구할 때 backpropagation으로 구한다. 이 방법은 입력 이미지가 들어왔을 때, weight 값을 update시키기 위해 사용했다.
gradient ascent 방법은 반대로 네트워크의 Weight를 고정을 시킨 후, 해당 뉴런을 활성화 시키는 General한 입력 이미지를 찾아내는 방법이다. (가중치값은 고정이지만 입력 이미지의 픽셀값은 유동적이라 이미지가 특정 뉴런 값을 최대화시키는 방향으로 생성되도록 한다.)
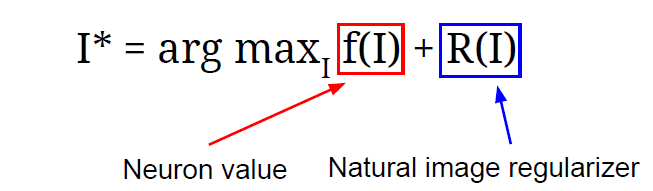
뉴런 값에 regularization이 추가 되었다. I*: 이미지의 픽셀 값, arg max_i: argument of maximum의 약자로, 함수가 최대값을 가지는 입력값을 찾음
Regularization fuction
이미지가 특정 뉴런 값을 최대화시키는 방향으로 update되는데, 좀 더 자연스러운 이미지를 만들기 위해 추가되었다.
regulation 종류. 결과

보통 L2 norm만 쓰지만 다른 것들을 추가시킨 방법들도 존재한다.
- Gaussian Blur Image
- Clip pixels with small values to 0 (픽셀 중 작은 value를 가지는 것을 0으로 변환)
- Clip pixels with small gradient to 0 (픽셀 중 작은 gradient를 가지는 것을 0으로 변환)
이미지 생성 동작 방법
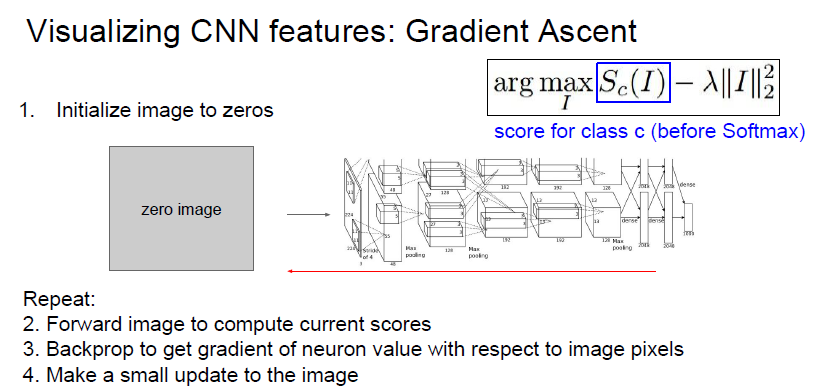
1. 처음 이미지를 0으로 초기화 시킨다. (노이즈로 초기화 시켜도 됨)
2. Image의 현재 score를 계산한다. (이미지 forward)
3. Image pixel 단위에서 Backpropagtion을 통해 뉴런값과 gradient 값을 구한다.
4. 이미지를 특정 뉴런이 최대화할 수 있도록 픽셀 단위로 update를 진행한다.
prior information

imagenet의 특정 클래스를 최대화하는 이미지를 생성한 것. 입력 이미지의 픽셀을 곧장 최적화하는 것 대신 fc6를 최적화하는 것으로 feature inversion network을 사용했다.
Deep Dream
목적:
재미있는 이미지 만들기
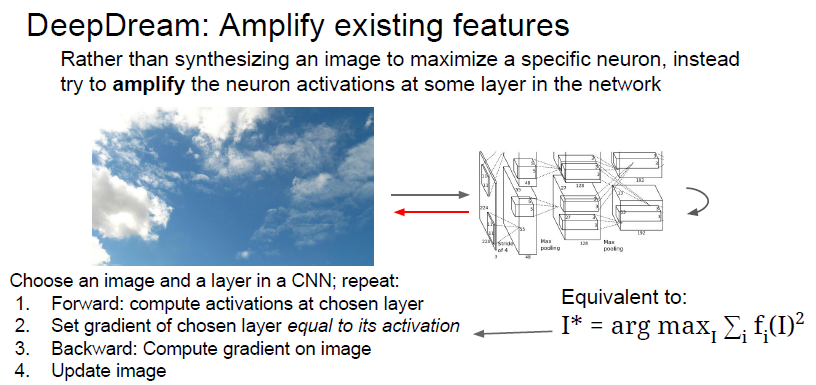

작동 방식
- 입력 이미지를 CNN의 중간 Layer까지 통과를 시킨다.
- 해당 gradient를 activation value 값으로 저장을 시킨다.
- Backpropagation을 통해서 이미지를 update한다.
- 위의 내용을 반복한다.
개가 결합된 건물들이 많이 보이는데, 개에 관련된 class가 200가지가 넘는 imagenet으로 학습시켰기 때문이다.
Feature Inversion
cnn에서 구한 feature로 역으로 input 이미지를 생성하는 방법. 네트워크의 다양한 layer에서 어떤 요소들을 포착하고 있는지 짐작할 수 있다.
작동 방식
이미지에서 특정 layer에서 activation map을 추출한 후, 이 activation map으로 이미지를 재구성한다. 이 방법에서 gradient ascent을 활용한다. score를 최대화하는 방법 대신 벡터의 거리가 최소화되는 방향으로 update한다. 새로 생성한 이미지의 특정 벡터와 기존에 계산한 특정 벡터(activation map에서 추출한 특징 벡터)의 거리를 측정하는 것.
결과

얕은 layer에서 activation map을 추출하면 원본 영상과 비슷한 이미지를 재구성한다. 깊은 layer에서 activation map을 추출하면 전체적인 구조만 가지고 이미지를 재구성한다는 것을 확인할 수 있다.
Texture Synthesis

특정 질감을 생성하는 알고리즘. 대표적으로 nearest neighbor 전략이 있다. 일반적인 텍스처 합성은 딥러닝으로 하지 않아도 잘 수행되지만, 글자를 이용하여 텍스처 합성은 어렵다. 이를 위해 DL 모델 방법들이 제안되었다.
Gram Matrix
작동 원리
서로 다른 공간 정보에 있는 channel을 외적 계산하여 새로운 matrix를 만든다. 이 matrix는 특징 벡터간 다양한 상관 관계를 한 번에 나타낼 수 있다.
과정
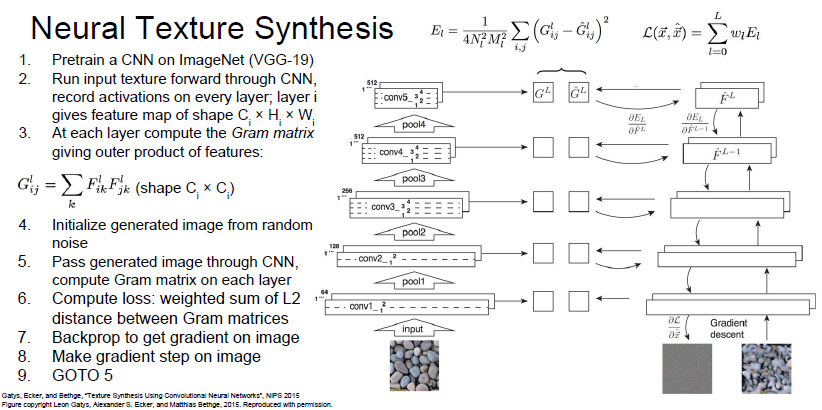
1. Input Image를 넣고 Pretrained 된 VGG Network에서 다양한 Gram Matrix를 생성한다.
2. Random Noise로 초기화 된 Image를 VGG Network를 통과 시켜 Gram Matrix를 생성한다.
3. Input Image와 만들어진 Image의 Gram Matrix를 비교하여 L2 distance가 최소가 되도록 Loss값을 계산한다.
4. 계산된 Loss 값을 이용하여 Backpropagation을 진행하여 이미지 픽셀의 Gradient를 계산한다.
5. Gradient Ascent 방법을 통해 이미지의 픽셀 값들을 update한다.
6. 위 단계를 반복하여 입력 이미지와 유사한 이미지가 만들어지도록 한다.
결과

얕은 layer에서 생성한 gram matrix로 만든 이미지는 공간적인 구조를 잘 살리지 못했다. 좀 더 깊은 layer에서 생성한 gram matrix로 만든 이미지는 텍스처 합성이 잘 된 모습을 보인다.
Neural Style Transfer
배경
texture synthesis를 예술쪽에 응용해봄.
개념
gram matrix를 재구성하는 것과 feature를 재구성하는 것을 합하여 이미지를 만듬.

입력이 2가지
- Content Image: 최종 이미지가 어떻게 생겼으면 좋을지 알려주는 이미지
- Style Image: 최종 이미지의 texture가 어떻게 생겼으면 좋을지 알려주는 이미지
손실 함수 2가지
- content loss: 생성된 이미지가 content image와 얼마나 비슷한지 측정
- style loss: 생성된 이미지가 style image의 스타일을 얼마나 잘 캡처했는지 측정.
content image의 feature reconstruction loss와 style image의 gram matrix reconstruction loss를 동시에 최소화하여 최종 이미지를 만든다. Style transfer는 deep dream보다 생성 control가 많아진다. 즉 deep dream보다 사용자가 결과물에 더 큰 영향을 줄 수 있다.
단점
수많은 forward, backward 과정을 반복해야 되므로 매우 느리다.
구글에서는 위 단점을 보안한 Content Image와 Style Image를 동시에 넣는 방식으로 다양한 스타일을 만들어 내는 논문을 제안했다. 합성하고자하는 이미지의 최적화를 전부 수행하는 것이 아니라 content image만을 입력으로 받아서 단일 네트워크를 학습시켰다. 이 네트워크 학습시에는 content loss와 style loss를 동시에 학습시키고 네트워크의 가중치를 업데이트 시킨다. 학습은 좀 걸리지만 한 번 학습시키고 나면 이미지를 네트워크에 통과시켜 바로 결과를 볼 수 있다.

