
목차
- Unsupervised Learning
- Generative Models
- PixelRNN and PixelCNN
- Variational Autoencoders (VAE)
- Autoencoders
- Generative Adversarial Networks (GAN)
Unsupervised Learning
레이블 없이 학습 데이터만 가지고 데이터에 숨어있는 기본적인 구조를 학습시키는 것
정답 label없이 학습 data만 있음
종류
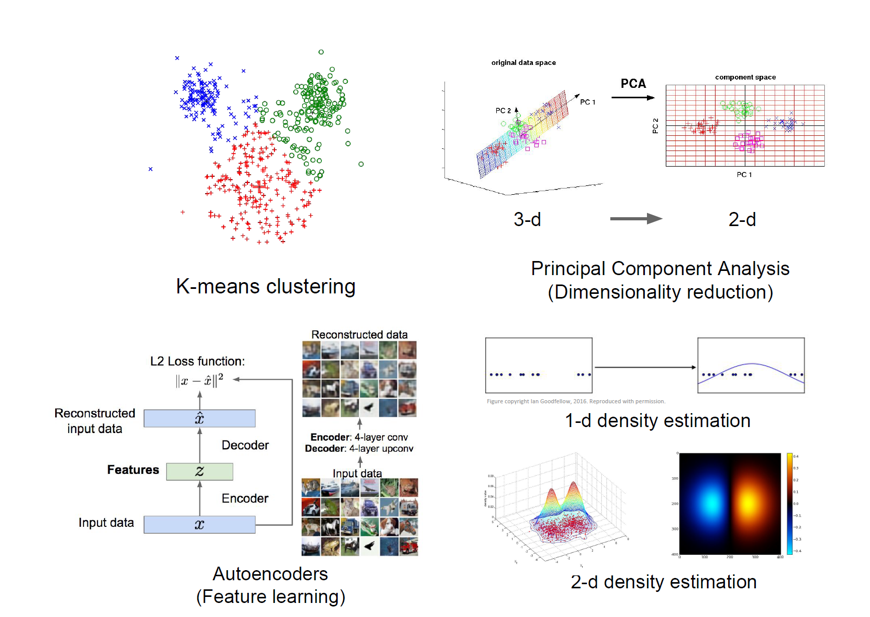
- 군집화: 학습 data의 feature를 분석하여 비슷한 군집끼리 모아 class를 할당
- 차원 축소(Dimensionality Reduction): 학습 데이터가 가장 많이 퍼져있는 축을 찾아내는 것
- 특성 학습(Feature learning (autoencoder)): 기계가 스스로 데이터의 특성을 추출하도록 학습하는 방법
- 밀도 추정(Density Estimation): 데이터의 분포를 추정
Generative Model
개념
training data가 주어졌을 때 이 data가 sampling된 분포와 같은 분포에서 새로운 sample을 생성하는 model. unsupervised learning에 속함 → 분포를 추정(density estimation)
목표
p_model(x)가 최대한 p_data(x)에 가깝게 만드는 것.
density estimation 방법 2가지
- Explicit Density Estimation : 생성 모델 Pmodel(x)를 명시적으로 나타내 주는 방법
- Implicit Density Estimation : 생성 모델 Pmodel(x)를 정의하지 않고 Sample을 얻어 내는 방법
사용 예시

data로부터 실제와 같은 샘플을 얻을 수 있음.
Super-resolution: 해상도를 높임
Colorization - 흑백 사진을 컬러로 바꾸기
밑그림 만으로 디테일한 사물 사진 얻어내기
종류
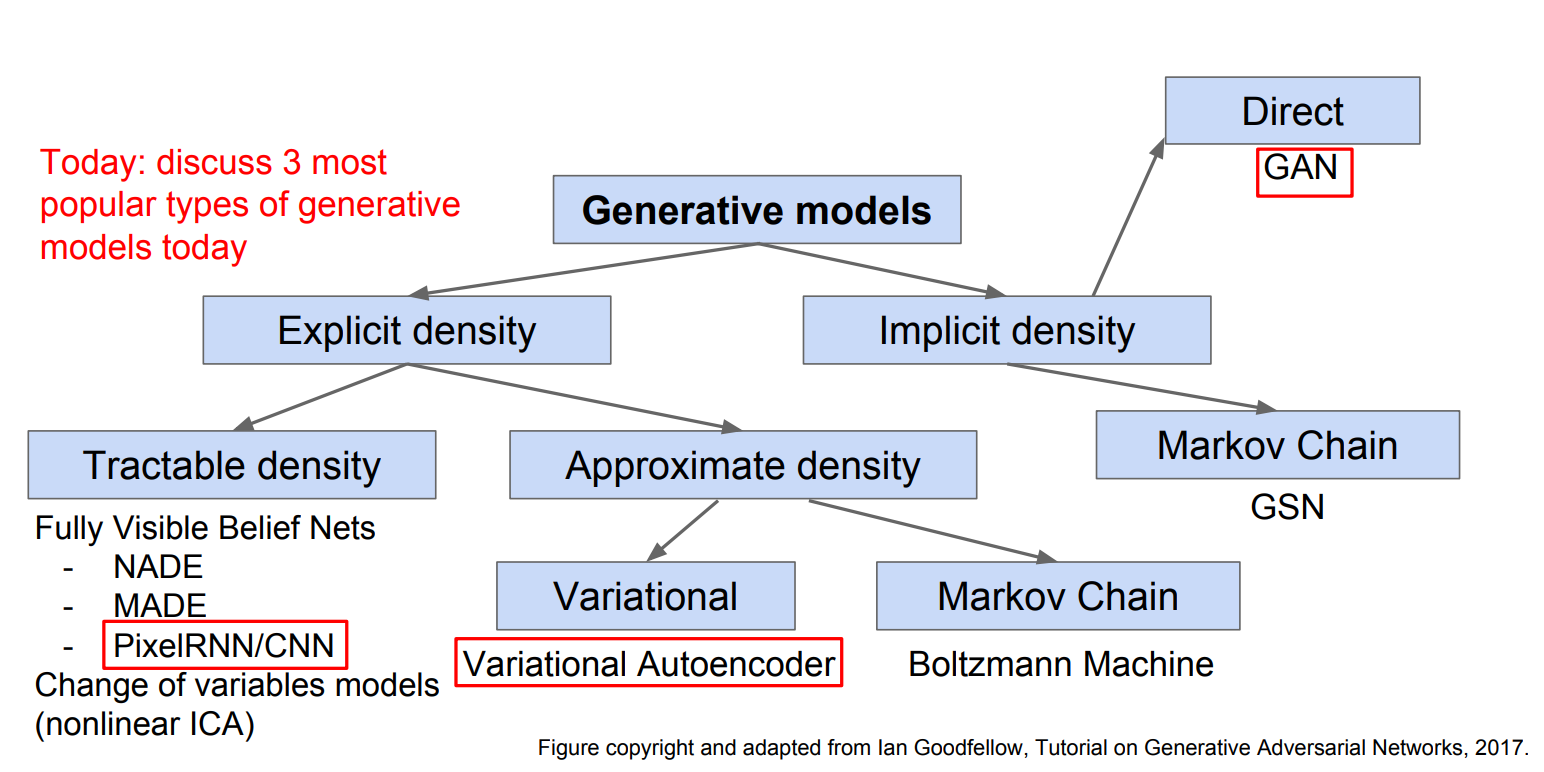
이 수업에선 빨간색 상자 안 3개의 개념을 다룬다
PixelRNN and PixelCNN
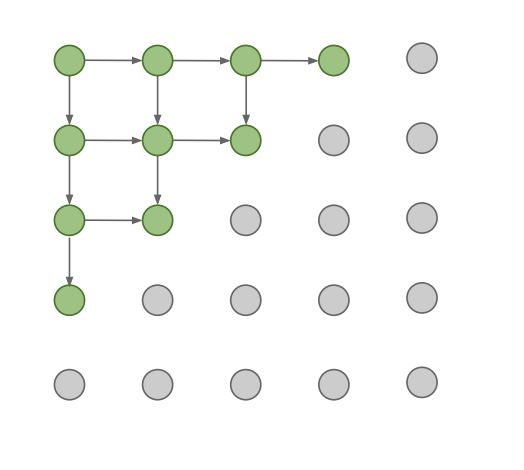
PixelRNN
왼쪽 상단 corner부터 픽셀 단위로 이미지를 생성. 이 때 각 픽셀의 값은 그 전에 생성된 모든 픽셀의 값에 의존한다(dependency). rnn과 lstm을 사용한다.
단점: sequential generation이기 때문에 느리다.
PixelCNN
Open image-20231004-032355.png
image-20231004-032355.png
왼쪽 상단 corner부터 픽셀 단위로 이미지를 생성하는 점, 각 픽셀의 값은 그 전에 생성된 픽셀값에 의존하다는 점은 PixelRNN과 동일하다.
pixelRNN과 다른점
- rnn과 달리 convolution을 병렬화한다.
- pixelCNN은 입력 이미지의 일부분만 보도록 필터를 설계하는 Masked convolution을 사용한다. 이를 통해 현재 위치한 픽셀의 주변 픽셀이 더 중요하게 고려된다.
- 단점: 병렬화 convolution을 사용하기 때문에 PixelRNN보다는 빠르지만 sequential generation이라 여전히 느리다.
공통 특징
explicit density model: 데이터의 조건부 확률 밀도 함수를 명시적으로(직접적으로) 모델링한다.

명시적이란?: 모델이 데이터의 확률 분포를 직접적으로, 즉 수학적 형태로 표현하고 이를 최적화하는 방식. 모델은 명시적인 접근 방식으로 데이터의 실제 분포와 가장 일치하는 확률 분포를 찾으려고 시도한다. 이 과정에서 데이터에 대한 밀도(즉 가능성)을 직접 계산한다.
반대로, implicit한 방식이란?: 모델이 직접적으로 확률 밀도 함수를 학습하지 않고 실제 데이터와 비슷한 데이터 sample을 새로 생성하는 방식. (ex. GANs)
조건부 확률 밀도 함수를 사용하는 이유: 어떤 이미지의 한 픽셀 값(예를 들어 (10,10))을 결정하려고 한다. (10, 10) 위치보다 왼쪽 또는 위에 있는 모든 픽셀 값들(이전에 생성된 모든 픽셀 값)을 고려하여 가장 가능성 있는 색상을 예측한다. 즉, P((10, 10) 위치의 색상| (10, 10)보다 왼쪽 및 위의 모든 픽셀 값들)의 조건부 확률을 밀도 함수 계산한다. 이미지 생성은 정답이 정해져 있지 않다. 최대한 그럴듯한 이미지의 확률을 계산하여 생성하는 것.
작동 방식:
각 픽셀이 이전에 생성된 픽셀에 조건부인 확률 분포를 학습함으로써 이미지를 생성한다. 위 식은 Chain Rule을 이용하여 Image x를 1차원 분포들 간의 곱의 형태로 분해를 한다.
Variational Autoencoders (VAE)
딥러닝과 베이지안 추론을 결합한 생성 모델. 위 PixelRNN/CNN은 계산이 가능한 확률모델 기반인 반면, VAE는 직접 계산이 불가능한 (intractable한) 확률 모델 기반이다. AE(AutoEncoder)와 유사한 구조이지만 여기에 확률론적 의미가 추가된다.
background: autoencoder

레이블이 없는 데이터에서 중요한 특성을 뽑는 비지도 학습법
encoder
추가적인 특징 변수이자 잠재 변수(latent variable)z를 모델링.
특징 벡터 z는 보통 input data x보다 작다. 차원이 줄어든 형태다. 그 이유는 input data에서 noise를 제거하고 중요한 특징만 담고 있는 특징 벡터를 이용하여 z를 구성하고 싶기 때문이다.
decoder
특징 벡터(z)를 통해 Input data처럼 재구성하는 과정. (encoder의 역과정, 차원이 다시 늘어난다.) Decoder는 training할 때만 쓰이고 실제로 test를 할 때는 Encoder만 사용한다.
decoder를 통해 input data x는 더 특성을 잘 반영해진 모습이 된다. 이 feature는 supervised model의 input으로 들어가, classification 하는데 사용한다. data가 넉넉하지 않을때, overfit/underfit되는걸 최대한 줄이기 위해 사용한다. 따라서 기존 classification model 보다 더 복잡한 형태이다.
이미지의 분포에 대해: 1. 이미지, 차원(dimension), 그리고 분포(distribution)간의 관계
개념
likelihood(p(x))의 lower bound을 구해서 최적화시킨다.
Autoencoder가 중요한 feature를 추출할 수 있으니, 이미지의 중요 feature를 추출하여 이미지를 재구성할 수 있을 것 같다는 아이디어에서 시작됨
개념

pθ(x): 모델링하려는 실제 데이터의 분포를 나타내는 함수. 강의에서 pθ(x)를 Prior라고도 한다. VAE의 목표는 이 실제 데이터 분포를 근사하는 생성 모델을 학습하는 것이다.
pθ(x|z(i)): VAE에서 사용하는 실제 데이터의 분포를 최대한 가깝게 찾는 함수.
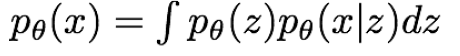
위 수식으로 실제 데이터의 분포를 구할 수 있다. 하지만 모든 z에 대해 p(x|z)의 적분을 취해줄 수 없다는 문제점이 있다. (intractable하다 즉 계산이 불가능함) 왜냐하면 잠재 공간 Z는 일반적으로 고차원이고 연속적인 값들로 이루어져 있기 때문이다. 이런 경우에는 모든 가능한 z의 조합에 대해 p(x|z)를 계산하고 합산하는 것이 계산적으로 불가능할 정도로 복잡해진다. 따라서 variational inference 방법을 사용한다.
Variational Inference
복잡한 확률 분포를 더 간단한 확률 분포로 근사하는 방법. 수학적으로 복잡한 적분을 계산할 필요 없이 원래의 문제를 근사적으로 풀 수 있게 해준다.
복잡한 p(z|x) 이 분포를 간단한 가정인 가우시안 근사 분포(qφ(z|x))로 대체한다. (φ: 근사 분포의 파라미터)
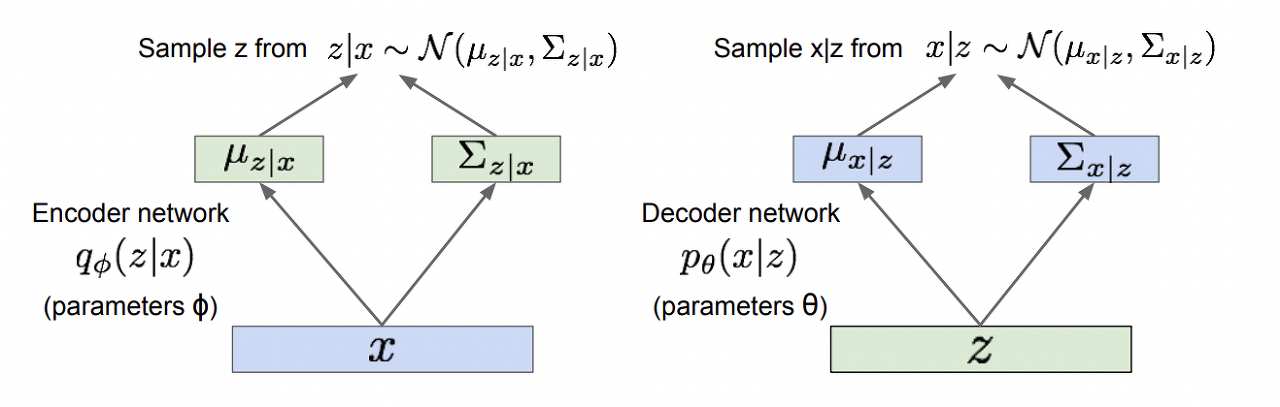
사진: VAE 네트워크 구조 (Encoder, Decoder). encoder에서 qφ(z|x)가 사용됨.
Encoder
qφ(z|x) : x를 input으로 받아서 mean, covariance추출 후, z space상에서 분포를 생성한다.
z는 gaussian 분포를 따른다고 가정.
Decoder
gaussian 분포로부터 z를 sampling한다.
pθ(x): sampling한 z로 space 상의 확률분포를 생성하고, x를 이 분포로부터 sampling한다.
이런 encoder → decoder (x → z → x) 구조를 가지기 때문에 auto-encoder라고 할 수 있고, 결과적으로 유의미한 feature vector z를 얻을 수 있다.
GAN (Generative Adversarial networks)
우리가 직접 확률분포를 모델링하지 않고 실제 데이터와 유사한 새로운 sample을 생성하는 방법을 학습한다.
게임이론의 접근법, 2-player game 방식으로 학습 분포를 학습한다.
- Generator Network: Discriminator를 속여 실제처럼 보이는 가짜 이미지를 만든다.
- Discriminator Network: 진짜 이미지와 가짜 이미지를 구별한다.
object function

generator와 discriminator 간의 minimax 게임을 한다고 생각하자.
discriminator는 Dθd(x) (x(실제 데이터)에 대해 진짜로 판별할 확률)을 최대화하려고 노력한다.
generator는 -Dθd(Gθg(z)) (자신이 만든 가짜 데이터 Gθg(z)를 가짜 데이터로 판별할 확률)을 최소화하려고 노력한다.
Ex~pdata: pdata(실제 데이터 분포)에서 샘플링 된 x(데이터)의 기대값.
Discriminator network와 Generator Network를 번갈아 가면서 경사하강법으로 학습을 진행한다.
gan은 2017년 당시 sota여서 매우 활발하게 연구되고 있었음.

