
목차
- CNN 구조
- CNN 시각화
- 용어 정리
CNN 개념
합성곱 연산(Convolution)을 사용하는 Neural Network 모델
- 합성곱 연산은 이미지의 픽셀 값으로 특정 패턴 또는 특징(가장자리, 색감, 질감 등)을 감지하는 데에 사용된다.
- 특징을 감지하기 위해 ‘필터’가 사용된다. 필터로 이미지 픽셀 하나하나를 훑으면서 각 픽셀과 그 주변의 픽셀의 조합을 분석한다. 필터와 이미지의 겹쳐진 부분의 가중치 합을 합성곱 연해서 새로운 이미지를 만든다. (이것이 feature map이다)
Convolutional Neural Network (CNN) 구조
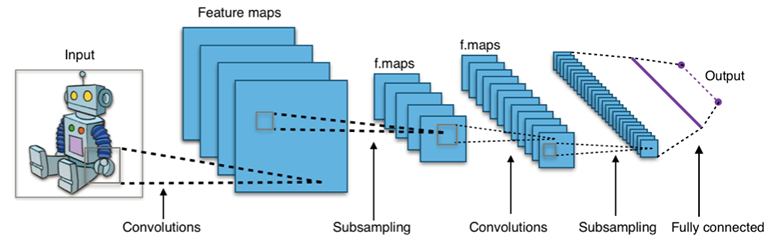
cnn 구조.
일반적으로 여러 개의 Convolutional Layer와 Pooling Layer를 거친 후 마지막에 Fully Connected Layer가 위치한다.
fully conntected(FC) Layer
fully connected layer 연산 예시
3강에서 2x2 이미지 사진을 [고양이, 차, 개구리]로 분류하는 과정과 유사하다
32*32*3 image를 10개의 class 분류하는 모델의 fc layer의 동작 구조
input image를 stretch해서 3072*1인 행렬로 변환.
가중치 w: 10(클래스 수)x3072 크기의 행렬. 가중치 W와 input vector의 내적 연산을 수행한다. 그 결과 10개의 output 값(각 클래스별 값)이 도출된다.
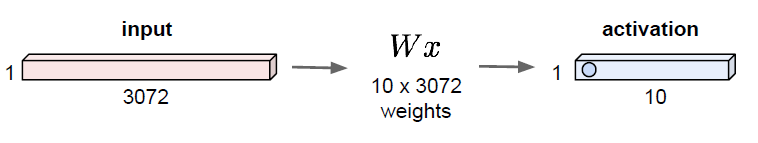
Convolution Layer
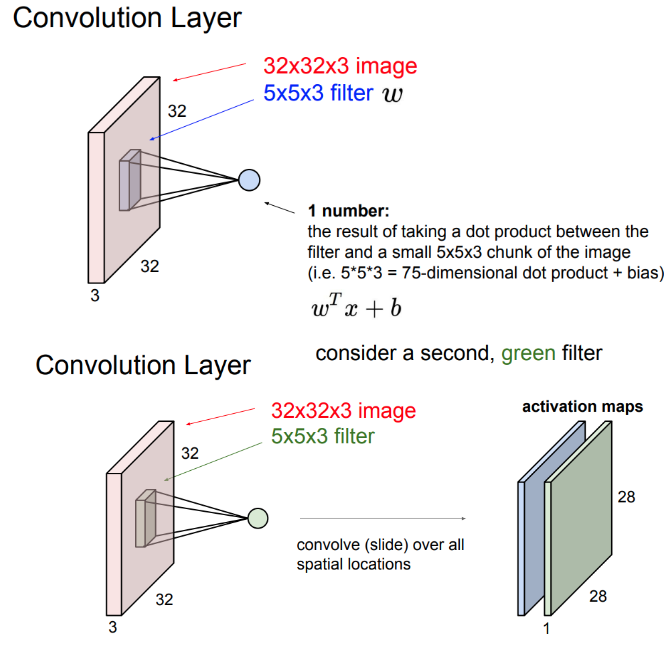
이미지의 공간적 특성을 사용하기 위해 conv layer를 사용한다.
fc layer와 다르게 입력 차원의 구조를 그대로 보존한다.
동작 방법
필터를 '슬라이딩'하며 ‘공간적’으로 내적을 수행한다.
필터와 이미지의 내적을 구하면 이미지의 특징을 추출할 수 있다.
- 슬라이딩: cnn에서 합성곱 연산을 수행하는 과정.
위 사진에서 필터의 크기는 5x5x3이다. 5x5의 크기는 정할 수 있지만 depth 3은 입력 데이터와 같게 맞춰야 한다. 필터는 가중치의 역할을 한다.
각 필터는 이미지로부터 1개의 특징을 추출한다.
필터당 하나의 특징 값이 도출되고 이 값이 모인 결과가 activation map이 된다.
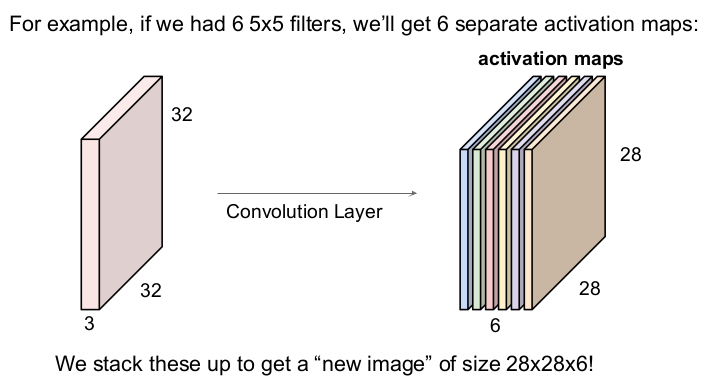
6개의 필터를 사용함.
filter의 개수만큼 activation map의 개수가 늘어난다. activation map을 모아 새 이미지를 얻을 수 있다. 위 사진에서는 6개의 5x5 필터를 사용하여 28x28x6의 새 이미지를 얻었다.
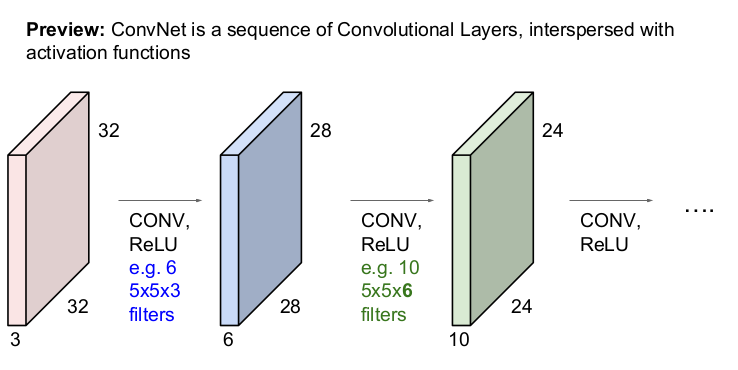
cnn은 이런 filter를 사용하는 layer들의 연속적인 형태를 말한다. 입력 이미지가 convolution layer와 활성함수 ReLU를 통과하여 다시 activation map을 얻는 과정을 반복한다.
conv layer를 거칠 수록 edge map이 더 복잡한 것을 추론한다. 마지막 pooling layer를 거치기 전까지의 각 값들은 각 필터가 가진 templete이 얼마나 활성되었는지 표현한다. 이 정보를 fc layer가 거치면 그 정보가 한데 모아 클래스 스코어를 계산한다.
pooling layer (또는 subsampling layer)
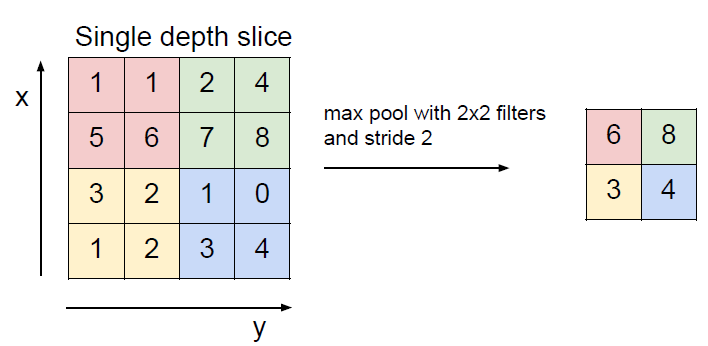
activation map 사이즈를 ‘공간적’으로 줄일 수 있다.
depth에는 아무 영향을 주지 않음. ReLU의 출력을 입력으로 받아서 downsampling한다.
cnn 시각화 예시
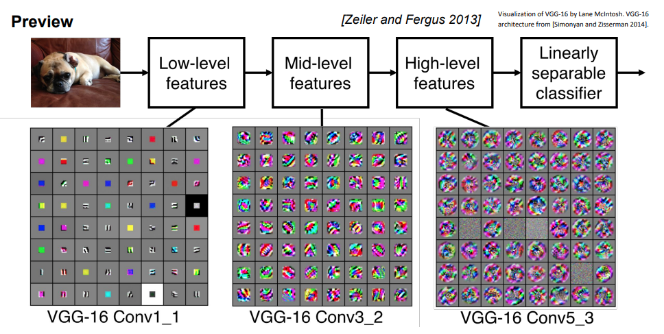
- VGG-16 Conv1_1: low-level 특징 학습 (edges 또는 color)
- VGG-16 Conv3_2: mid-level 특징 학습(corner, blobs)
- VGG-16 Conv5_2: high-level 특징 학습(통합)
layer가 깊어질수록 즉, 여러 개 쌓일수록 이미지의 특징을 더 많이 추출할 수 있다.
cnn 필터 별 activation map 시각화
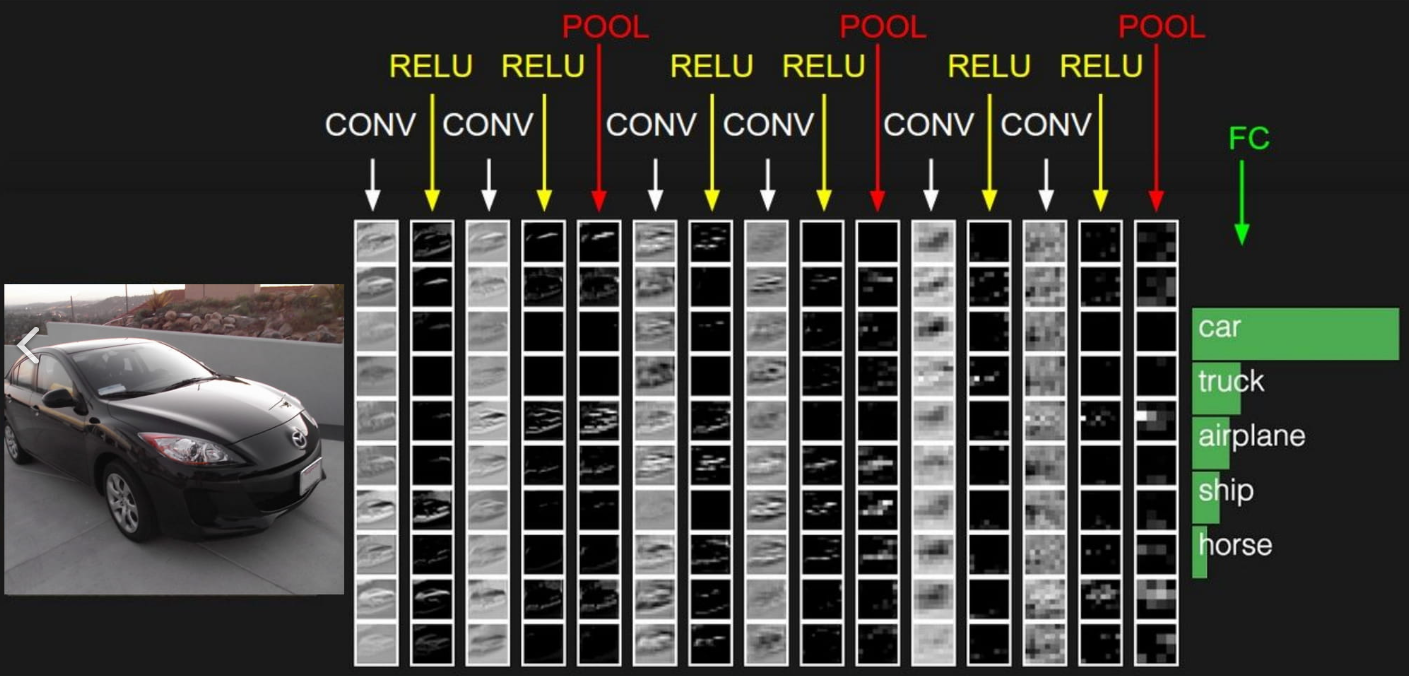
각 필터마다 activation map이 생긴다. 사진의 어떤 부분의 특징을 나타내 준다.
용어 정리
activation map
이미지의 특징을 시각적으로 표현한 것.
각 필터는 서로 다른 activation map을 생성함.
입력의 공간적인 정보를 보존하고 있음. 필터의 templete이 얼마나 활성화 되었는가 나타냄.
stride
필터가 옮겨 건너가는 칸의 수. (필터의 이동량)
stride=1인 경우
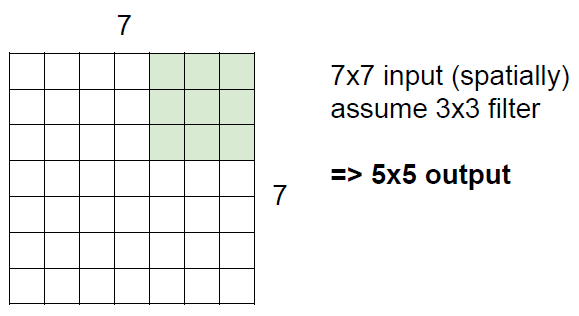
stride=2인 경우
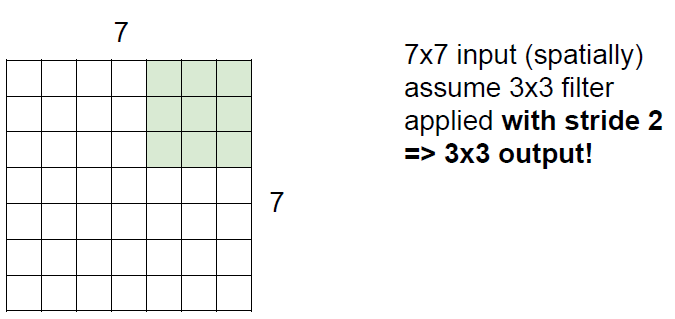
위 사진에서 초록색인 필터가 왼쪽위 corner에서 오른쪽으로 이동한다고 생각하자.
stride가 너무 커지면 필터가 모든 이미지를 커버할 수 없음. 일부 정보가 상실되어 원본이미지를 표현하기엔 너무 작은 값이됨.
Padding

convolution 과정에서 activation map의 크기가 줄어드는 걸 방지하기 위해 input 이미지의 가장자리에 값을 채워주는 것.
zero-pad
이미지 가장자리에 0을 채워넣어서 이미지 가장자리에도 필터 연산을 수행할 수 있음.
7x7 이미지에 1칸의 zero-padding을 했다. 3x3 크기의 필터로 conv를 할 것이다. 이 때 필요한 필터 수는?
- 답: 7x7
빠르게 계산하는 공식: (input 칸 수 - filter 칸 수)/stride + 1
(9(가장자리에 padding을 했으니 2칸씩 붙음, 7+2) - 3)/1 + 1
receptive field
뉴런이 한 번에 수용할 수 있는 영역.
5x5개의 필터는 5x5의 receptive filed의 역할을 한다. (필터 값이 같다는 것을 기억하자)
