
목차
- 최적화
- 최적화 함수
- 정규화
- 전이학습
최적화 (Optimization)
최적화가 필요한 이유
nn의 loss가 최저인 지점을 찾기 위해 backpropagation을 거듭하는데 가장 빠르게 가기 위한 지름길을 찾기위해 gradient update함.
SGD(Stochastic Gradient Descent, 확률적 경사 하강법)
개념
초기에 설정한 학습률을 이용하여 손실함수의 값(loss)가 최소가 되는 방향으로 가중치를 업데이트함.
단점
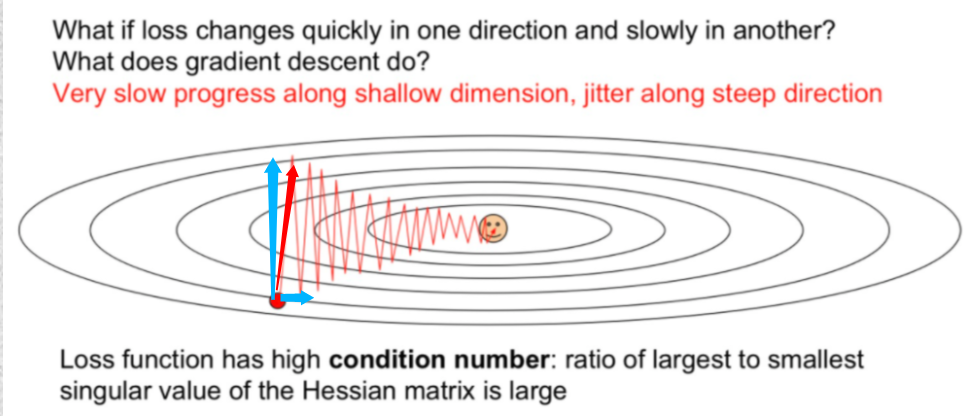
- 느리다. 빗살무늬토기처럼 깊고 좁은 공간으로 나타난다면 기울기 변화가 가파르다. 이 두벡터의 합방향으로 움직여야하기 때문에 지그재그를 그리며 최저점에 도착함.
- local minima:
- loss 함수에 기울기가 0인 부분이 있는 경우, 더 이상 가중치 업데이트가 되지 않고 멈춤.
- saddle point:
- 기울기 0의 주변 지점의 기울기가 매우 작아져서 update도 느려지는 현상.
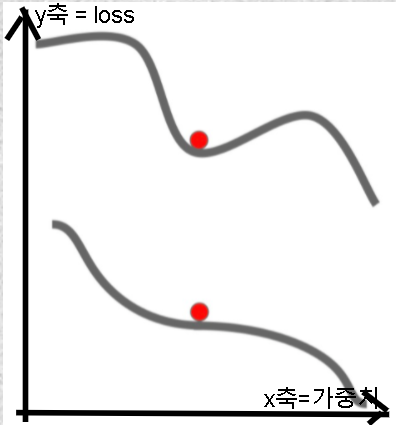
위: local minima, 아래: saddle point. 고차원일수록 잘 발생함.
- satochastic:불확실성, 또는 무작위성

무작위성으로 인해 불안정성을 유발할 수 있음
sgd는 mini batch마다 loss를 계산하며 전진하는데 비효율적이다.
mini batch마다 update를 위해 추정값을 이용하는데 이게 엄청난 noise를 일으킴.
구불구불 이동
sgd+ momentum

vx가 추가됨
momentum
경사 하강법에서 기울기 업데이트 시 이전 기울기 업데이트의 영향을 고려하여 움직이는 방식.
물리학에서 영감을 받은 최적화 기법.
볼링공이 경사를 굴러 내려갈 때, 처음에는 속도가 느리지만 점점 중력에 의해 같은 방향으로 점점 더 빠르게 움직이는 현상을 생각해보자.
모멘텀은 전 단계에서의 움직임(속력)을 고려하여 현재 단계의 움직임을 결정한다.
더 부드럽고 일관된 업데이트 방향을 제공한다. 지그재그 움직임이 없어지게 된다.
기울기가 0인 지점에서도 update됨.
한계점
가중치가 최적화하려는 방향으로 너무 빠르게 이동하다가, 원하는 최적의 지점을 지나치는 경우가 있음.
Nesterov Momentum
Momentum 방법의 한계를 극복하기 위해 제안됨
현재의 속도 벡터와 현재 속도로 한 걸음 미리 가 본 위치의 gradient vector를 더해 다음 위치를 정함
AdaGrad
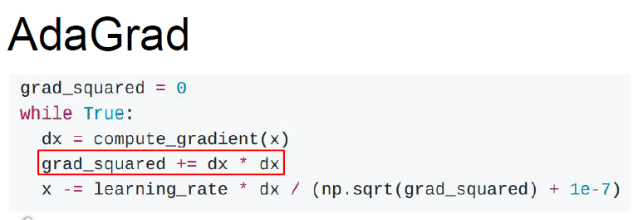
손실 함수 곡면의 변화에 따라 적응적으로 학습률을 정하는 알고리즘
가속도가 아닌 기울기의 제곱값을 이용. 학습중에 기울기의 제곱값을 grad_squred에 계쏙 더해나가서 update step에서 나눠 준다.
RMSProp
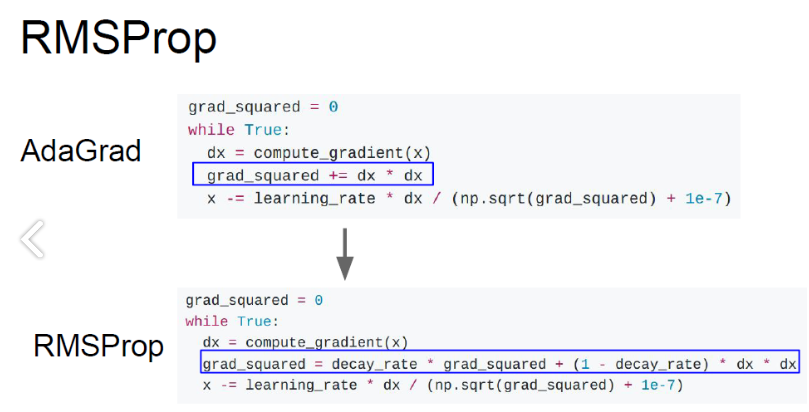
grad_squard를 똑같이 이용하지만 rmsprop은 train하는 동안에 값을 계속 축적함. (decay값을 삽입)
Adam

adagrad와 rmsprop을 합친 버전
실제로 제일 많이 씀.
learning rate 조절 - 최적의 learning rate를 찾는 방법.
수렴은 잘 하고 있는데 gradient가 점점 작아짐 → learning rate가 너무 높아서 깊게 들어가지 못함.
최선의 방법: 초기에 큰 학습률을 사용해 빠르게 최소 loss로 수렴하도록 하고, 뒤로 갈수록 학습률을 낮추기.
n차 근사
경사하강법에서는 함수의 기울기를 이용해서 조금씩 파라미터를 업데이트해서 함수의 값을 점차 줄여나가면서 함수의 최소값을 찾는다.
1차 근사

위 경사하강법 과정에서 해당 함수를 선형 함수로 근사화하는 방법. 지금까지 배운 경사하강법은 1차 근사, 1차 미분 방식이었다.
2차 근사 (1차 근사보다 한 번에 이동하는 빨간 점의 폭이 크다)
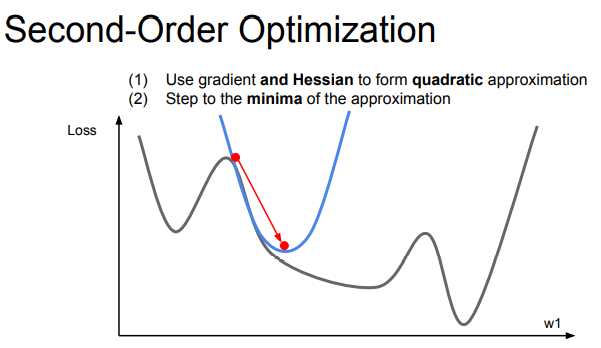
특정 지점에서 기존함수에 근사하는 2차함수를 찾는 것. Hessian의 역행렬을 이용.
loss의 최저점을 찾아갈 때 2차 근사하면 더 빨리 최저점에 도착할 수 있다. (사진의 빨간 점 비교)
learning rate가 필요 없음. 근사함수를 만들고 그 최소값으로 이동하면 된다.
Hessian(헤시안) 행렬을 직접 계산하고 이용하는 것은 계산량이 많아서 비효율적이라 딥러닝에선 사용x.
뉴턴 방법 (Newton’s Method)
헤시안 행력의 역행렬을 이용
헤시안 행렬의 역행렬을 곱하면, 기울기가 큰 방향은 더 크게 보정하고 기울기가 작은 방향은 더 작게 보정해서 최적화 과정이 더 빨라지게 된다.
경사하강법은 1차 미분을 사용하는 반면, 뉴턴 방법은 2차 미분을 사용하기 때문에 성능이 훨씬 좋다.
n차 근사

2차 근사 뿐만 아니라 테일러 근사함수 공식으로 n차근사함수까지 얼마든지 구할 수 있다.
ensemble
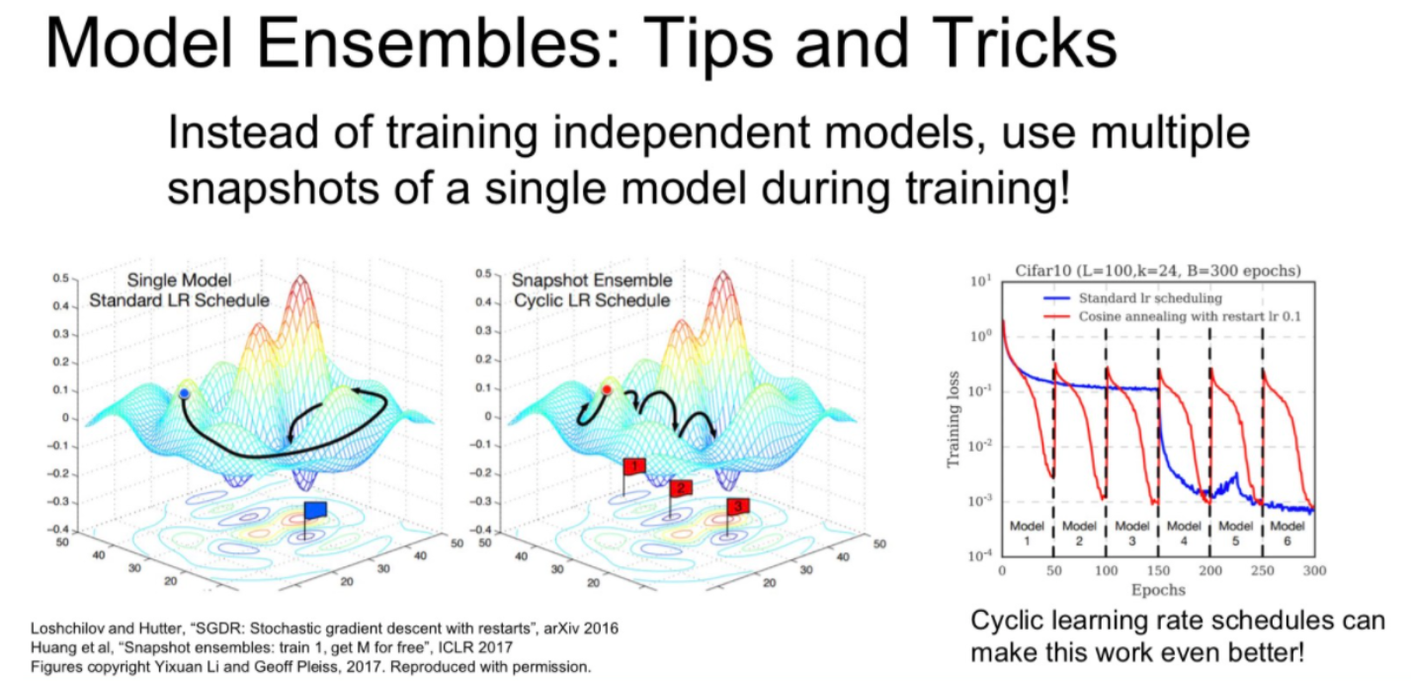
여러 모델을 각 따로 학습시켜서 그 평균값을 이용하는 방법.
처음보는 validation data에도 잘 작동한다.
Regularization (정규화)
모델 복잡도를 줄여서 train data에 모델이 overfitting되는 것을 줄이고 처음 본 data에도 잘 작동하게 하기 위함
Dropout

forward pass 과정에서 일부 뉴런을 비활성화 시킴. 네트워크가 특정 feature에만 의존하지 못하게 함.
일종의 ensemble 방식: train epoch를 돌 때마다 랜덤으로 바뀌는 노드의 구성이 변하기 때문에 마치 여러 모델의 값을 평균내는 ensemble 효과를 냄.
Data Augmentation
train data에 변형을 주기.
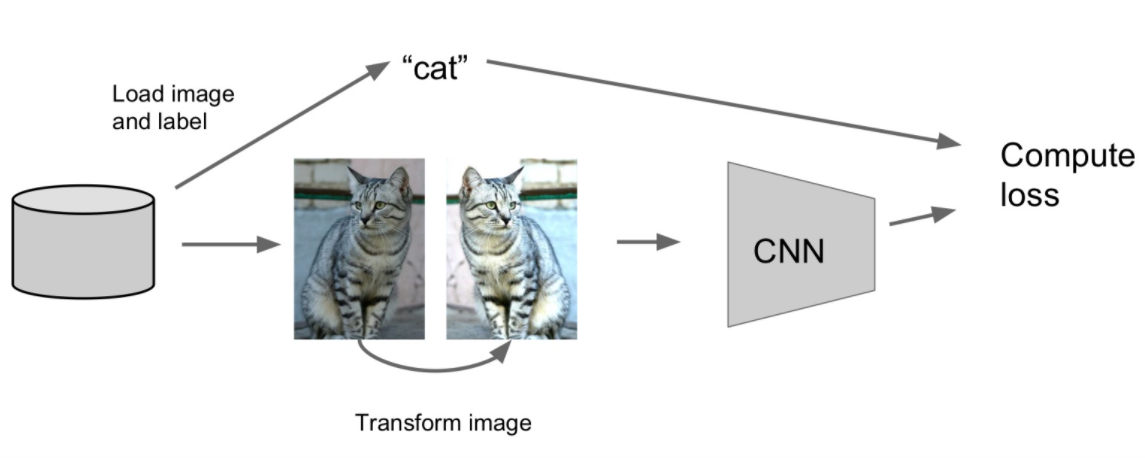
- 사진 좌우반전
- 사진 랜덤하게 자르기
- 사진 크기 바꾸기
DropConnect
dropout은 노드의 activation을 0으로 만드는 것. dropconnect는 노드의 weight matriz를 0행렬로 만드는 것.
frational max pooling & Stochastic depth
max pooling
pooling 연산 어디서 할지 랜덤 선정

stochastic depth
train time에 네트워크 레이어를 랜덤 drop. 일부만 사용해서 학습. test에서는 전체 다 이용.
max pooling: pooling 연산 어디서 할지 랜덤 선정
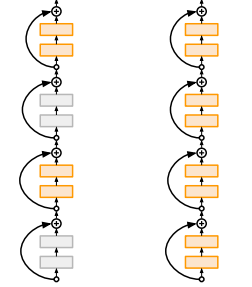
stochastic depth: train time에 네트워크 레이어를 랜덤 drop. 일부만 사용해서 학습. test에서는 전체 다 이용.
Transfer Learning (전이 학습)
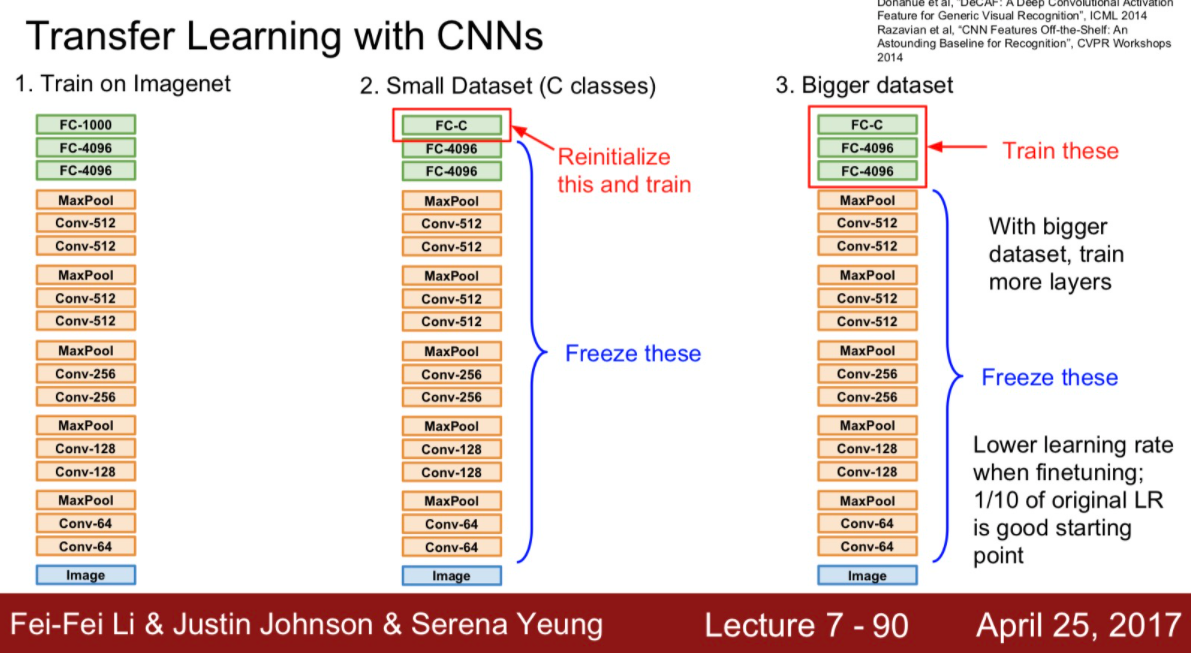
학습 데이터가 충분하지 않을 경우 overfitting이 일어나기 쉬움.
cnn으로 imageNet같은 아주 큰 데이터셋으로 한 번 학습시킨 모델을 우리가 가진 작은 데이터셋에 적용시킴.
- 어떻게? 마지막 FC layer를 초기화해서 지금 필요한 클래스 분류로 바꿈.
- 데이터가 조금 더 많이 있다면 좀 더 위의 layer로 이동해서 fine tuning할 수 있다.
transfer learning은 아주 보편적으로 사용된다.
cv 관련 알고리즘들은 요즘 밑바닥부터 학습하지 않고 대부분 pretrained-modeld을 관련 task에 맞게 fine-tuning한다.
