
목차
- cpu와 gpu 차이
- 딥러닝 프레임워크
cpu와 gpu 차이
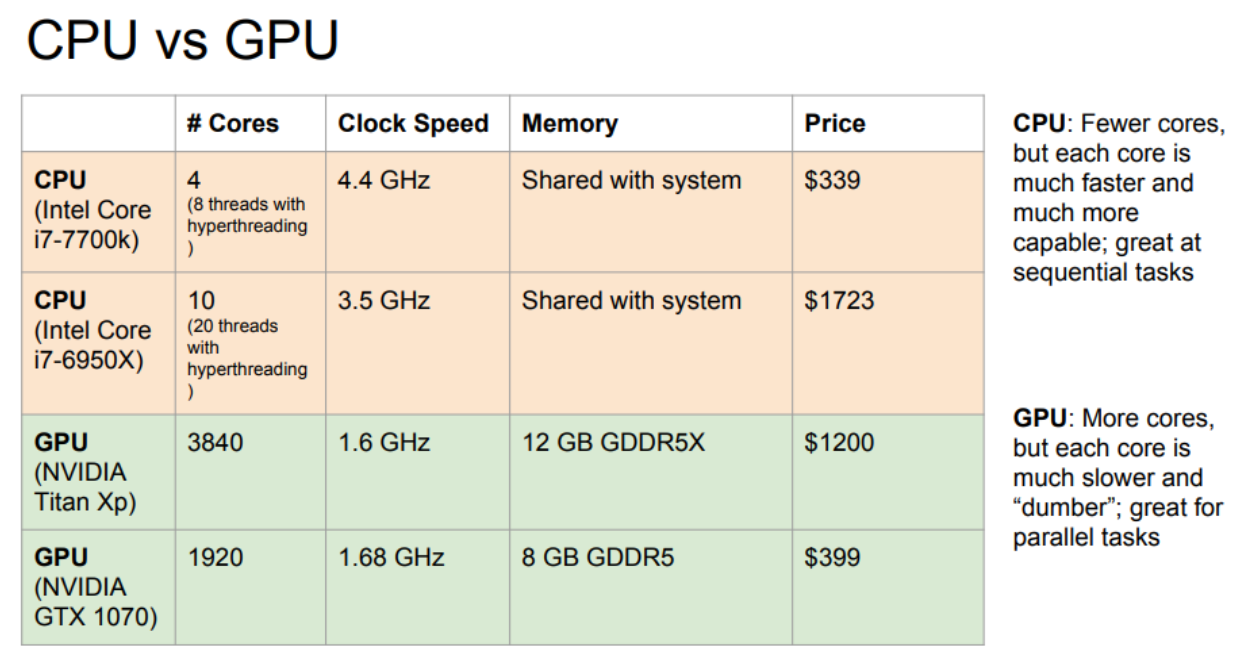
CPU: Central Processing Unit
- 더 적은 수의 cores (4~10개 정도로 한번에 20개의 일을 시행)
- 각 코어는 더 빠르고, 연속적 처리에 좋다. (sequential tasks)
- cache(데이터나 값을 복사해놓는 임시 장소)가 있지만, 대부분의 메모리는 컴퓨터 디스크에서 사용
GPU : Graphics Processing Unit -> NVIDIA
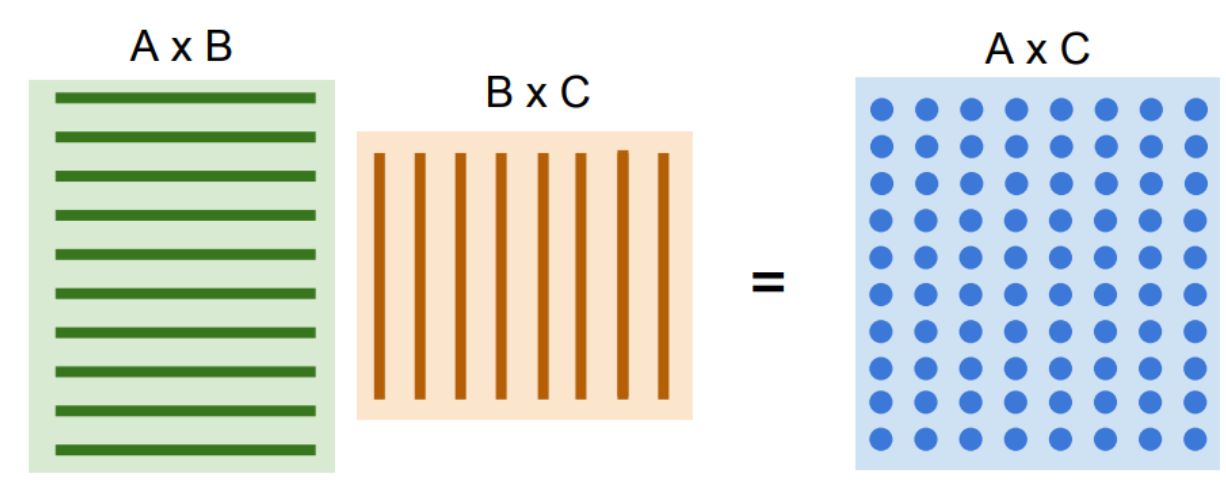
- 수천 개의 코어
- 각 코어는 더 느리지만 병렬 계산에 더 능하다. (parallel tasks)
- 두 행렬곱에서 GPU가 동시연산이 가능하다는 점에서 강력함.
개별적인 RAM을 갖고, RAM사이의 cache 시스템 존재
- 두 행렬곱에서 GPU가 동시연산이 가능하다는 점에서 강력함.
딥러닝 프레임워크
딥러닝 프레임워크의 장점
큰 computational graphs를 쉽게 그릴 수 있음
- 복잡한 딥러닝 모델 구조를 쉽게 파악할 수 있게 구조를 클래스로 묶고 파라미터를 설정함.
computational graphs의 gradients 계산을 쉽게 할 수 있음
GPU를 효율적으로 이용함
TensorFlow

이미지-랜덤 데이터로 2 layer ReLU network의 L2 loss를 구하는 예시로 기본 구조를 설명
TensorFlow 기본 구조
computational graph를 정의하는 단계: 1~3.
-
placeholder 함수: 그래프의 입력 노드 역할. 나중에 실제 데이터가 들어올 자리를 마련해줌.
-
forward pass: 계산식, pred와 loss. x와 w1의 matmul연산과 tf.maximum을 이용해 ReLU를 계산. 그 결과값 h와 w2의 matmul연산으로 예측값을 계산하고 L2 distance를 구함.
- matmul: 행렬 곱셈(matrix multiplication) 수행하는 함수
- backward pass : tf.gradients. 한줄로 가능
실제 데이터를 넣고 그래프를 실행시키는 단계: 4
values: 1.에서 그린 그래프에 실제 넣을 데이터 입력
out: 계산해서 반환할 값 지정
결과는 numpy array로 반환
weight를 placeholder가 아닌 Variable에 저장하는 방법의 구조

-
weight를 placeholder가 아닌 tf.Variable에 저장하여 GPU메모리에 저장하고 쉽게 불러올 수 있게 한다.
-
weight 업데이트 또한 computational graph 안에서 연산되도록 해준다.
-
x, y에 데이터 입력하고 실행
-
Optimizer
- 사진에서 빨간 상자 부분: updates = tf.group(new_w1, new_w2)을 꼭 추가해줘야 함.
- 저 코드 한 줄이 없으면 loss만 계산하고 가중치 업데이트가 안돼서 loss가 줄어들지 않는 문제가 발생함
- Optimizer를 사용하면 해당 코드 부분 없이도 learning rate만 정해주면 알아서 가중치를 update하면서 최적화함.
PyTorch
세가지 추상화 레벨
- Tensor : ndarray, GPU에서 구동
- Variable : computational graph의 노드, 데이터와 gradient를 저장함
- Module : neural network layer로 어떤 상태나 업데이트중인 weight를 저장함
Tensor

dtype = torch.cuda.FloatTensor를 적용해주면 torch의 tensor로 인식하고 GPU에서 실행. (사진엔 cuda가 없는데 cuda 넣어주면 gpu에서 실행할 수 있음.
Variable
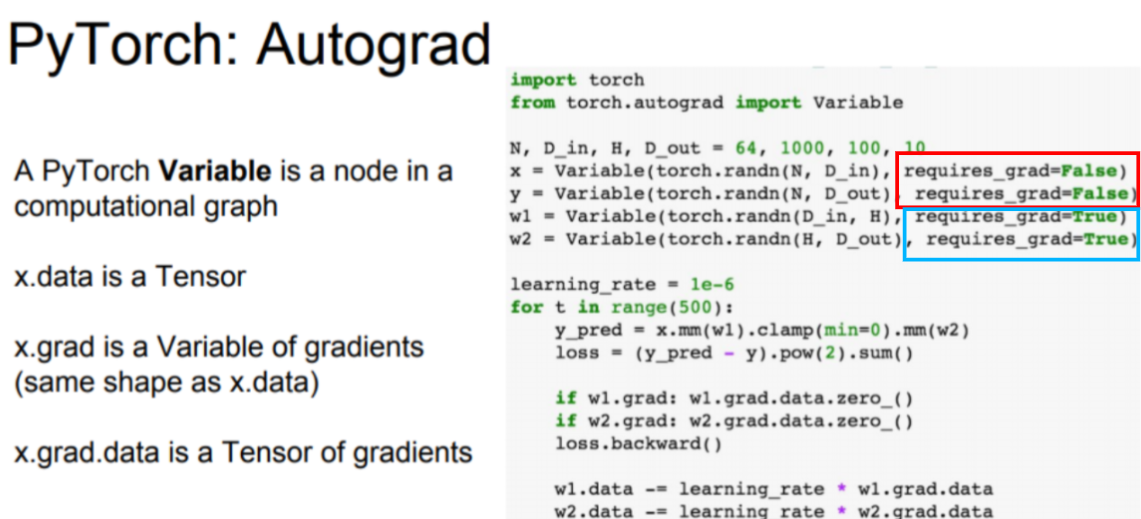
- x.data: Tensor
- x.grad: computational graph에서 tensor를 이용해 계산한 gradient
- x.grad.data: 그 gradients들을 담은 Tensor
Tensorflow와 PyTorch의 차이점
-
Tensorflow는 computational graph를 미리 그리고, 그래프를 실행하는 두 단계로 나뉘고, PyTorch는 그래프를 그리지 않고, forward pass를 할 때마다 새로 그린다. 그래서 코드가 겉으로 보기에 더 깔끔하다.
-
PyTorch는 자동으로 gradient를 계산하는 AutoGrad함수를 정의할 수 있다. Tensor를 이용해 forward와 backward를 구성하면 알아서 그래프에 넣을 수 있다.
operations
nn
PyTorch의 상위레벨 wrapper로 텐서플로우의 케라스같은 역할

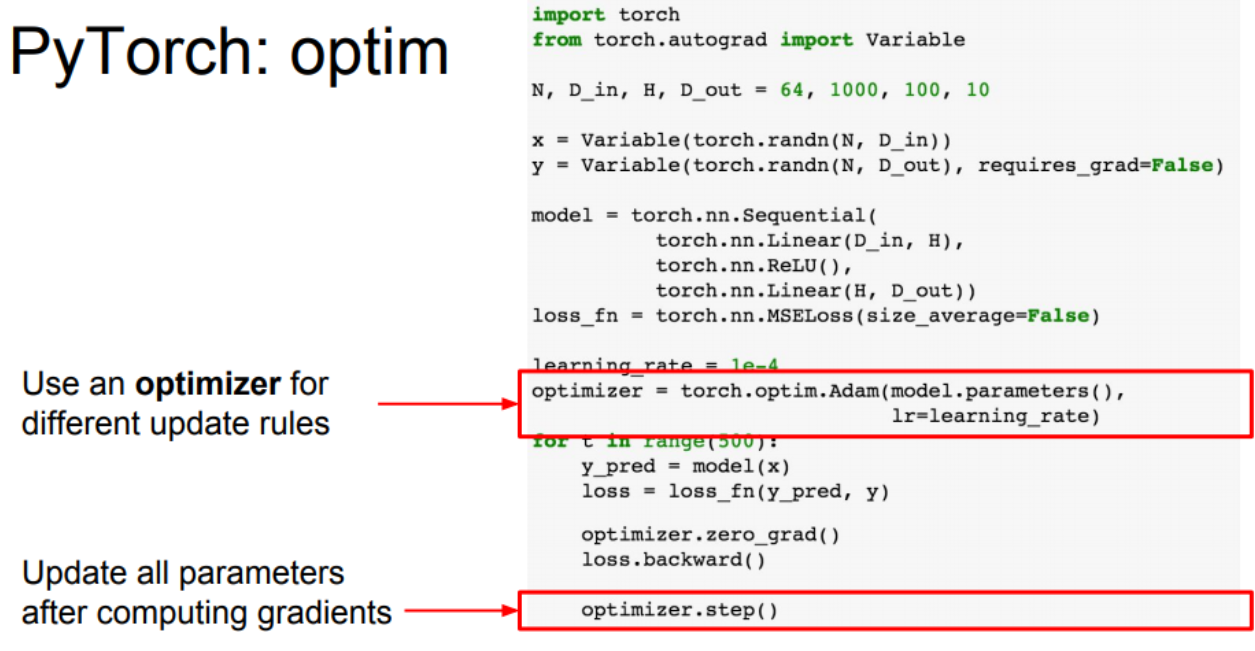
Optimizer
loss 최적화 함수를 사용할 수 있게 해준다. 역시 learning rate같은 하이퍼파라미터는 정해줘야 한다.
nn module
파이토치에 nn을 모델처럼 구현시킴. 사용자정의 모델을 이용해서 클래스 형태로 조금더 복잡한 모델 (깊은층)을 만들 수 있다.

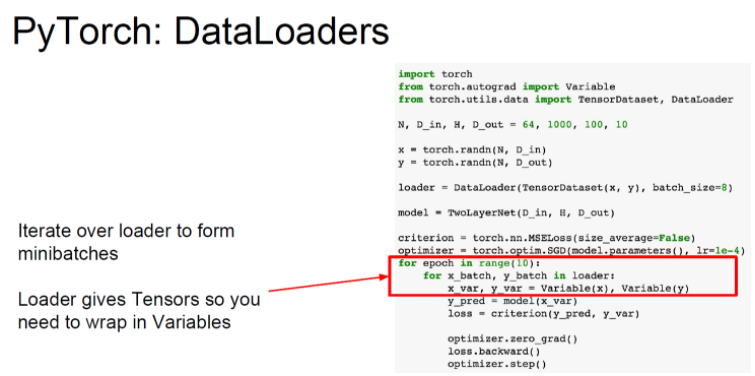
DataLoaders
데이터셋 불러오기. 미니배치, 셔플, 멀티스레딩을 알아서 해줌.
Static vs Dynamic

텐서플로우: static graph을 맨 처음에 구성하고 매 iteration마다 재사용.
파이토치: dynamic graph로 매 iteration을 수행할 때마다 새롭게 computational graph를 생성.
-
static graph의 장점: 코드가 쉽고 깔끔함.
- z값을 기준으로 y값 계산 식을 분기할 때, 파이썬 조건문을 쓸 수 있다.
- 파이토치는 매 iteration마다 새로운 그래프를 만들기 때문에, 경로를 나누어 놓아도 매번 선택할 수 있고, 그에 따른 역전파처리도 자동적으로 수행할 수 있어서 굿굿.
- 텐서플로우는 computational graph 안에 조건분기코드를 넣어야 하는데, 새로운 문법(tf.cond 등) 을 써야 하고 복잡해진다.
-
Dynamic 의 장점:
- 위 그림처럼 x, y, w가 매번 사이즈가 달라지는 경우 용이함. 파이토치에서는 그냥 파이썬 코드처럼 사용하면 됨. 텐서플로우라면 new operator를 이용해서 그래프를 만들어야 함.
Caffe
연구보다 모델 test에 유리함
training, fine tuning에 좋음
Caffe2
static graph 지원
코어는 C++로 작성되어 있고 python interface 지원
교수님의 advice:
텐서플로우는 두루두루 사용하기 좋은 만능 프레임워크.
반면 파이토치는 실험/연구할 때 좋음
