
목차: cnn 모델 5가지
- Lenet
- AlexNet
- VGG
- GoogLeNet
- ResNet
LeNet
산업에 성공적으로 적용된 최초의 ConvNet
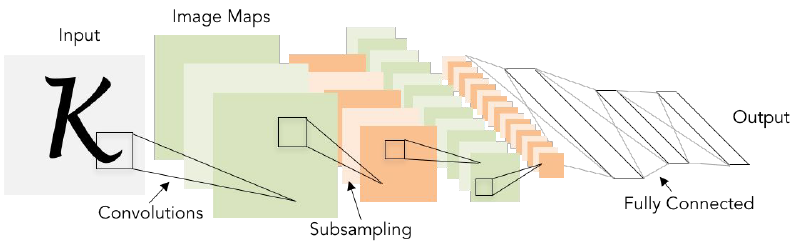
subsampling=pooling
이미지를 입력으로 받아서 stride = 1인 5x5 필터를 거치고 몇 개의 Conv Layer와 pooling layer를 거친다.
AlexNet
2012년에 나온 모델, 최초의 Large scale CNN
구조:
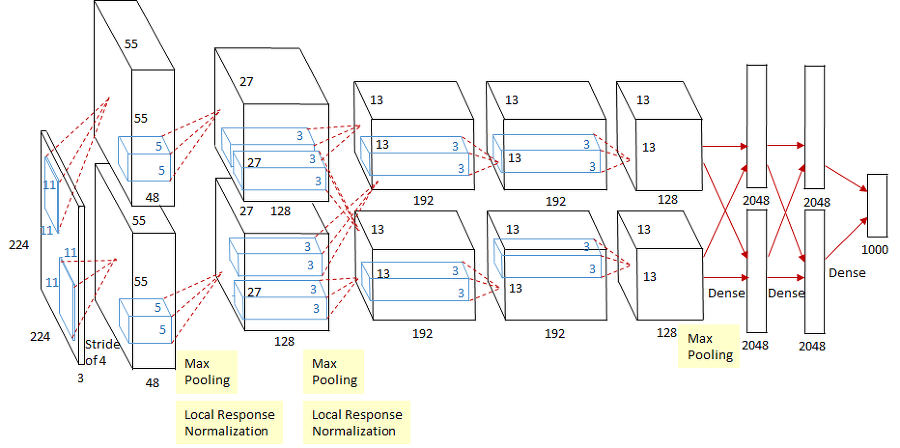
기본적으로 conv-pool-normalization 구조가 두 번 반복, 그리고 뒤에 conv layer가 조금 더 붙고 그 뒤에 pooling layer가 있다. 마지막엔 FC-layer가 몇 개 붙는다.
5개의 Conv Layer와 2개의 FC-layer로 구성
2개의 GPU로 병렬연산을 수행하기 위해서 병렬적인 구조로 설계
AlexNet의 ImageNet으로 학습시키는 경우 입력의 크기가 227 x 227 x 3 이다. 첫 레이어는 11 x 11 크기 필터가 stride = 4로 96개가 존재.
Q: 첫 레이어의 출력은?
답: 55(width) *55(hight) * 96(depth)
풀이: 출력 너비 = (227-11)/4+1 = 55, 출력 높이 = (227-11)/4+1 = 55
Q: 첫 레이어의 전체 파라미터 갯수는?
답: 34,848개
풀이: 각각의 필터에 대한 파라미터 수 = 11 x 11 x 3 (필터 너비 x 필터 높이 x 입력 깊이(RGB값 3개), 필터는 총 96개 있으므로 96을 곱해줌 = 34,848개
Q: 두 번째 레이어는 Pooling Layer이다. stride = 2인 3x3 필터가 있다. 두 번째 레이어의 출력값 크기는?
답: 27x27x96
풀이: (55(첫 레이어의 출력값) - 3)/2+1 = 27. depth(96)는 입력값에서 변하지 않는다.
Q: 두 번째 레이어의 파라미터 갯수는?
없다. Pooling layer에는 파라미터가 없다.
없는 이유: 파라미터는 학습시키는 가중치다. pooling layer는 특정 지역에서만 큰 값을 뽑아내는 역할을 한다. 따라서 학습시킬 파라미터가 없는 것이다.
VGGNet
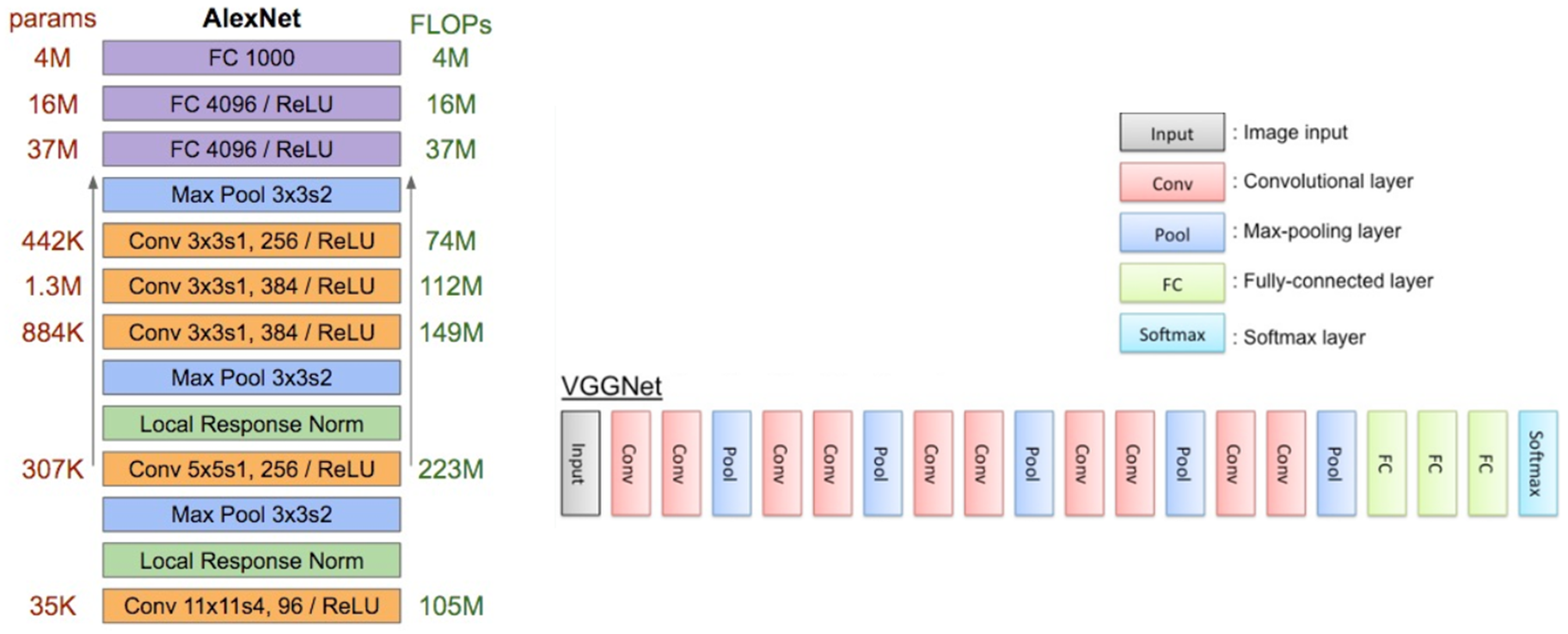
전보다 더 깊어짐. 더 작은 필터 사용.
더 작은 필터란 항상 3 x 3 필터만 사용하고, 이는 이웃하는 픽셀을 포함시킬 수 있는 최소 필터.
이런 작은 필터를 유지해주며 주기적으로 Pooling을 수행하며 전체 네트워크를 구성한다.
작은 필터를 쓰는 이유
필터의 크기가 작으면 파라미터의 수가 적다. 큰 필터에 비해서 레이어를 조금 더 많이 싸을 수 있다(=depth를 더 키울 수 있다). 3x3필터를 3개 쌓은 것은 결국 7x7 필터를 사용하는 것과 실질적으로 동일한 Receptive field(수용 영역, 특정 뉴런이 수용하는 입력 데이터의 범위)를 가진다.
Q: stride = 1인 3x3 필터를 3개의 receptive field는 몇 일까?
답: 49 (7x7)
풀이: 3x3 크기의 필터를 stride=1로 사용하면, 한 번의 합성곱 연산에서 3x3 영역의 입력에 대해 연산이 이루어진다. 따라서 한 번의 합성곱 연산에 대한 receptive field는 3x3이다. 그러나 여러 계층을 거치면서 receptive field는 점점 넓어진다. 왜나하면 각 계층에서 이전 계층의 출력에 대해 합성곱 연산을 수행하기 때문이다. 예를 들어, 첫 번째 계층에서 3x3 필터를 적용하면 나오는 feature map 각각은 원본 이미지에서 3x3 크기의 영역에 해당된다. 두 번째 계층에서 다시 3x3 필터를 적용하면, 이번에는 첫 번째 계층에서 생성된 특징 맵 상의 3x3 영역이 한 픽셀로 축소된다. 이것은 실제 원본 이미지 상에서 보았을 때 receptive field는 5x5 크기가 된다(가장자리에 한픽셀의 둘러졌다고 생각하면됨. 맨 마지막 필터를 거쳤을 때 제일 가장자리인 픽셀은 마지막 필터를 한번만 거치게 되는 방식)
GoogLeNet
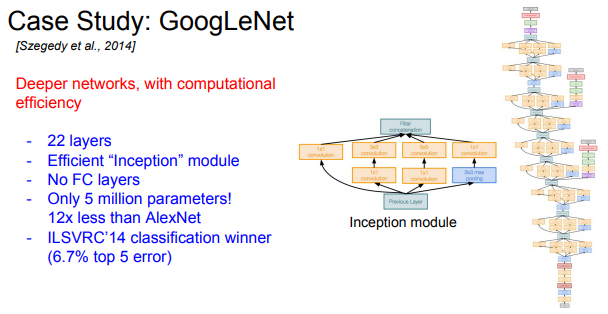
2014년 Classification Challenge에서 우승한 모델.
22개의 레이어를 가지고 있는 엄청 깊은 모델.
GoogLeNet은 높은 계산량을 효율적으로 수행할 수 있도록 네트워크가 디자인되었다. GoogLeNet은 Inception module을 사용한다. 이 모듈을 여러 개 쌓아서 만들고, FC-Layer는 없다(파라미터를 줄이기 위해 제거함). 전체 파라미터 수가 5백만개로 AlexNet에 비해 적은 수다.
Inception modeule이란?
-
GoogLeNet은 네트워크와 네트워크 사이에 있는 네트워크라는 개념의 local topology를 만들었고, 이 local topology 간의 네트워크를 Inception module이라 한다.
-
inception module 내부엔 다양한 필터가 병렬로 존재한다. (아래 사진은 128개의 1x1 필터, 192개의 3x3 필터 등을 예시로 들었다) 각 크기가 다른 필터는 다른 종류의 특징을 추출할 수 있다. conv 연산을 나중에 depth 방향으로 한번에 concatenate한다.

궁금증 on 🤔
pooling이 다른 conv 작업과 동등하게 병렬로 처리되면 input에 바로 pooling 작업이 적용되서 정보 손실이 일어나지 않을까?
👉 gpt 답변:
입력에 pooling이 직접 적용되는 것이 아니라 이전 레이어의 출력에 pooling이 적용되는 것이다. 이전 레이어에서는 이미 합성곱 연산을 통해 특징이 추출되었기 때문에 pooling을 통해 이런 특징을 보다 촘촘하게 표현할 수 있다. 그리고 inception module 내에서 pooling 말고도 다양한 합성곱이 동시에 이루어지기 때문에 많은 정보를 표현할 수 있다.
- dimension reduction (차원 축소, bottleneck layer)
2에서 한 번에 concat하면 계산량이 엄청 많아진다. (위 사진의 Conv Ops 계산 부분)
1x1 conv 연산을 통해 출력 feature map의 차원(깊이)을 조정하여 계산량을 줄일 수 있다.

다양한 필터를 거치는 Conv 과정 전에 dimension reduction 과정을 추가
1x1 conv는 각 spatial location에서만 내적을 수행한다. (이미지의 가로, 세로 방향으로는 이동하지 않고, 깊이 방향으로만 연산을 수행한다는 뜻. 즉, depth만 줄일 수 있다. 입력의 depth를 더 낮은 차원으로 projection(투영)한다. (input feature map들 간의 선형결합) 즉, 각 레이어의 계산량은 1x1 conv을 통해 줄어든다.
1x1 필터를 통해 수행되는 합성곱 연산은 입력 feature map의 depth와 동일한 크기의 필터를 각 픽셀 위치에 적용된다. 이 때 사용하는 필터의 개수가 출력 feature map의 깊이가 된다.
-
예시: feature map 깊이가 256, 1x1 conv 필터가 64개라면, 각 픽셀 위치에서 256개의 값과 64개의 필터 각각의 가중치를 곱한 후 더하게 되어 출력 feature map 깊이는 64가 된다.
-
이때 입력 feature의 깊이인 256은 출력 feature map의 깊이와 상관이 없다. 왜냐면 각 1x1 합성곱 필터는 입력 feature map의 전체 깊이(256)에 대해 연산을 수행하기 때문이다. 각 필터는 입력 feature map의 각 위치에서 하나의 출력 값을 생성한다.
아래 사진의 Conv Ops 부분을 읽고 googLeNet의 흐름을 이해해보자.

수행해야하는 연산의 수가 줄어들었다. 전에는 854M ops(operation)이었는데 1x1 필터 사용 후에는 358M으로 줄어들었다.
ResNet
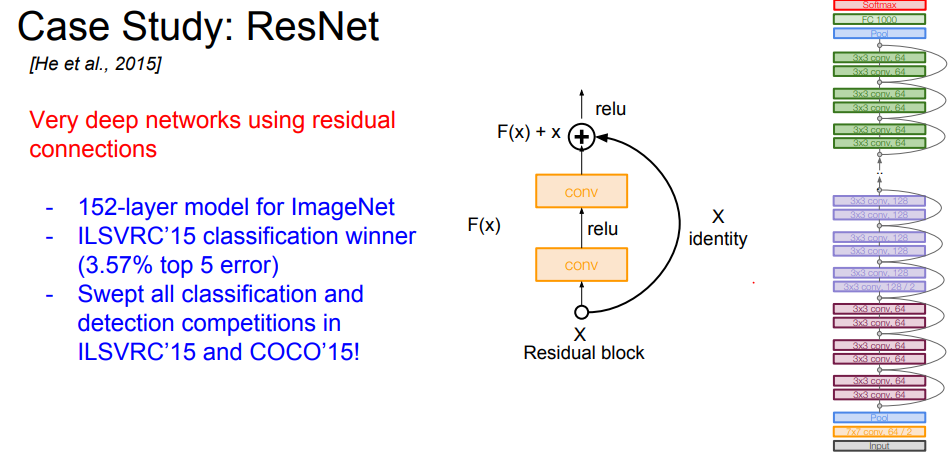
등장 배경
네트워크가 깊어지면 깊어질수록 풍부한 특징들을 추출할 수 있지만, 무작정 깊은 층을 쌓으면 성능이 저하되는 문제가 있었다.
구조
2014년의 GoogLeNet이 22개 층으로 구성된 것에 비해, ResNet은 152개의 층(약 7배)을 갖는다. 깊은 신경 망을 효과적으로 학습 시킬 수 있는 구조를 제안한 모델. 기존의 딥러닝 모델은 layer를 깊게 쌓을수록 최적화가 어려운 단점이 있다. resnet은 이런 문제를 해결하기 위해 일부 레이어에 Residual Connection을 도입하여 정보 손실을 최소화하면서 network를 깊게 만들었다.
Residual Connection
잔차 연결 = ideintity mapping = Skip Connection(스킵 연결)
이전의 출력을 그대로 출력으로 내보냄. 입력이 어떤 변환 과정을 거치지 않고 그대로 다음 계층으로 전달한다. 즉, 일부 레이어를 그냥 건너 뛴다.
ResNet이 ‘잔차 함수’ 구조라서 identity mapping이 가능하다. 아래 그림의 오른쪽 순처럼 그대로 출력으로 보내고 실제 레이어는 잔차(delta, 입력 x에 대한 residual)만 학습한다.

residual
신경망의 입력과 출력 사이의 차이. 최종 출력값 h(x) = f(x) + x(residual)
궁금증 on 🤔
보통 합성곱 연산을 통해 계산된 출력은 입력보다 크기가 작은데 어떻게 잔차를 계산하는가?
👉gpt 답변:
잔차 연결은 필터가 포함된 레이어가 합성곱 연산을 하는 과정 중에 같이 진행되는 연산이 아니다. 합성곱 필터를 통해 연산을 수행하는 레이어와 병렬로 동작한다. 이 잔차 연결은 입력을 그대로 다음 레이어로 전달한다. 따라서 잔차 연결을 통과하는 입력의 크기는 변하지 않는다. 그리고 이 입력은 합성곱 레이어를 통과한 출력과 결합되어, 두 값 사이의 잔차를 계산하는 데 사용된다.
근데 아직도 이해 못함!!!! 3x3 필터 렝이ㅓ 2개를 건너 뛰게 되는데 이건 또 어떻게 잔차를 건너 뛸 수 있는지 모르겠다!!!!
Residual block은 3x3 conv layer로 되어있다. 이 residual block을 깊게 쌓는다.

