Reference
https://aclanthology.org/W19-6120.pdf
Abstract
- Sentiment analysis는 인터넷 유저로 인해 연구와 비즈니스 분야에서 아주 유명해지고 있음.
- 이 논문은 사전학습된 BERT를 활용하여 contextual word representations의 잠재력을 보여주고, out-of-domain ABSA 문제를 풀며, 이전의 SOTA(state of the art)결과를 능가하기 위해 추가적으로 생성한 text와 함께 fine-tuning 방법을 활용하는 것을 보여줌.
Introduction
- ABSA 문제에 대한 간단한 정의
- Sentiment analysis는 opinion mining이라고도 함.
- 문장에 있는 sentiment를 분류해야 하는데 일반적으로 positive, negative, neutral 3가지로 분류함.
- SNS와 제품 리뷰에서 여러가지 평을 할 수 있음. 예를 들어, 브랜드, 제품 또는 아이디어나 주제에 대해서 여러 가지 평을 할 수 있음.
- 전통적인 감정 분류는 문장에 대한 감정 전체를 분류하는 방식으로 진행됐음.
- 하지만 이러한 방식은 한 문장 내에 다른 주제 또는 entity가 포함되어 있을 때 충분하지 않은 방식임.
- 따라서 일반적인 문장 분류보다 더 복잡한 문제임.
- pretrained BERT의 역할
- 사전학습된 기본 언어 모델을 통해 external 훈련 데이터셋을 활용하게 함.
- 따라서, ABSA 문제에서 out-of-domain classification에 대한 해결책을 제시.
Aspect-Based Sentiment Analysis
- ABSA 문제에 대한 구체적 정의
- Aspect Category Classification
- 문장에 대해서 특정 word가 aspect(i.e. PRICE, QUALITY)로 분류되는 것.
- Opinion target expression(OTE)
- 문장에 대해서 category로 분류될 수 있는 특정한 word를 추출하는 것. 문장에서 특정한 word가 없을 수도 있음. 그러한 경우 NULL로 정의함.
- Sentiment polarity classification
- 특정한 word 또는 entity에 대해서 positive, negative, neutral 등의 평가를 분류하는 것.
- Aspect Category Classification
ABSA with BERT
- BERT는 NLP task에 대해 좋은 결과들을 보여줌.
- BERT를 활용하여 ABSA task를 해결할 때, sentence-pair classification task를 활용하여 문제를 해결하고자 함.
Experiments
- Pre-processing entity and aspect pairs for BERT
- 기본적인 SemEval-2016 데이터셋은 'ENTITY#ASPECT'와 같은 형태로 되어 있음.
- BERT에 더 적합하게 맞추기 위해 'FOOD#STYLE_OPTIONS'와 같이 되어 있는 것을 문장의 형태로 바꾸어 'food,style options와 같은 형태로 변경.
- Data generation
- 생성된 각 data는 연관이 없는 aspect로 되어 있는 annotation이 부착되어 있음.
- 예를 들어, text 'The food tasted great!' 는 aspect 'restaurant, ambience'는 아무 연관이 없음.
- 또한, 특정 text에 대해 annotated 되지 않은 aspect는 문장과 연관이 없다고 볼 수 있음. 따라서 label을 'unrelated'로 부착함.
- Unbalanced data
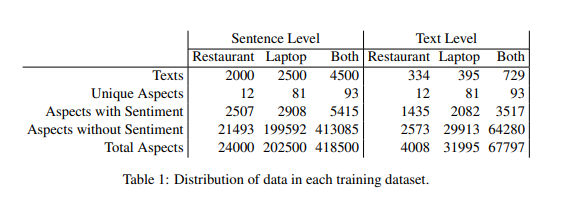
- 위 데이터를 보게 되면 class 불균형이 심함.
- 따라서 불균형을 보정하기 위해, 클래스의 빈도에 따라 가중치를 조정하였음. 높은 빈도의 라벨일수록, 라벨에 낮은 가중치를 줌.
- 구성
- Sentiment Classifier
- sentiment 예측 분류기 -> positive, negative, neutral 등으로 예측
- Aspect Category Classifier
- aspect를 기존 문장과 sentence pair로 만든 다음, 'related' 또는 'unrelated'로 예측하게 함. 이는 out-of-domain인 aspect에 대해 다룰 수 있게 함.
- Combined model
- Aspect와 sentiment에 대해서 함께 예측하는 모델.
- Sentiment Classifier
Evaluation
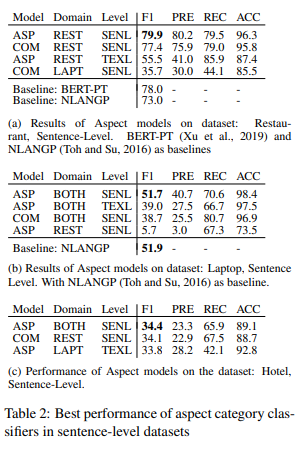
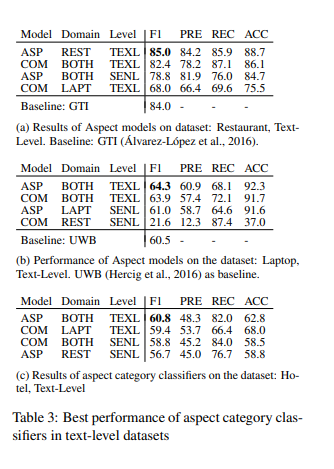
- Aspect 모델과 Combine 모델에 대한 평가
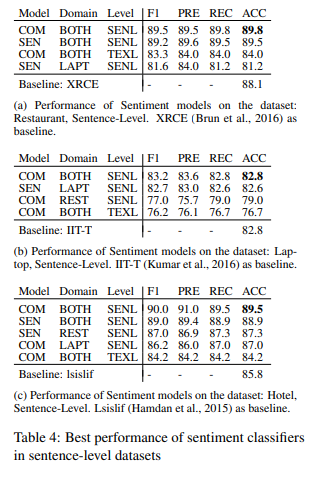
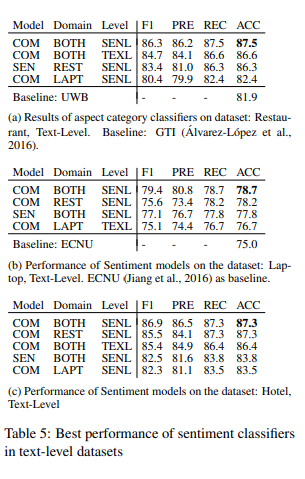
- Sentiment 모델과 Combine 모델에 대한 평가
Discussion
- 논문에서 제시된 방법은 out-of-domain 문제에 대해 강건함.
- 결과를 보면 Table 3c에서 이전에 모델에 학습하지 않았던 hotel 카테고리에 대해 Table 3b에 있는 laptop에 대한 모델보다 더 높은 f1 score를 달성함. -> 이를 통해 text와 aspect를 pair로 학습하는 방식이 semantic 유사성의 잠재력을 보여줄 수 있음.
Conclusion
- ABSA 문제를 'related'와 'unrelated'문제로 치환하고, pretrained된 BERT를 활용하여 문제를 품으로써, in-domain과 out-domain을 모두 예측할 수 있음을 시사함.

매일 매일 한 걸음씩 나아가고자 합니다.