Cluster-Former: Clustering-based Sparse Transformer for Question Answering Review
Paper Link
Background
- The background of this paper
- Transformer stands out on Natural Language Processing and Deep Learning.
- It has Self-Attention mechanism, which allows fully-connected contextual encoding over all input tokens.
- But basic Transformer that is fully-connected, so needs too much computing powers has weakness.
- So It only takes fixed-length input which is relatively short.
- Background model architecture
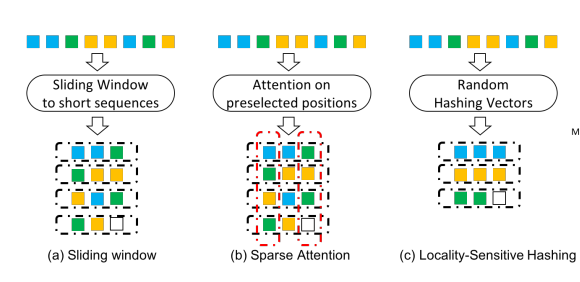
- Each Method Limitations
- Sliding window
- (a) is the sliding-window-based method to chunk a long sequence into short ones with window size 3 and stride 2. - Sparse Attention
- (b) builds cross-sequence attention based on sliding window over pre-selected positions (red-dotted boxes).- Limitation of Sliding window and Sparse Attention
- cannot encode long-range dependencies with as much flexibility or accuracy as fully-connected self-attention, due to their dependency on hand-designed patterns
- Limitation of Sliding window and Sparse Attention
- Locality-Sensitive Hashing
- (c) hashes the hidden states into different buckets by randomly-initialized vectors.- Limitation of Locality-Sensitive Hashing
- Locality-Sensitive Hashing method is still an unexplored territory in the context of long sequences.
- Limitation of Locality-Sensitive Hashing
- Sliding window
- Each Method Limitations
Model Architecture Summary
-
Model Summary Picture
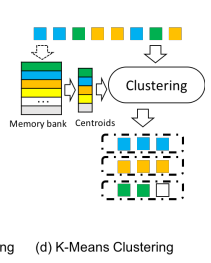
- combine Sliding Window method and Locality-Sensitive Hashing method
-
Model Key Component
- Role of Sliding-Window Layer
- encoding input tokens for local context
- Role of Clustering Layer
- encoding input tokens for global context
- Role of Sliding-Window Layer
Model Architecture Detail
- Model Architecture Picture
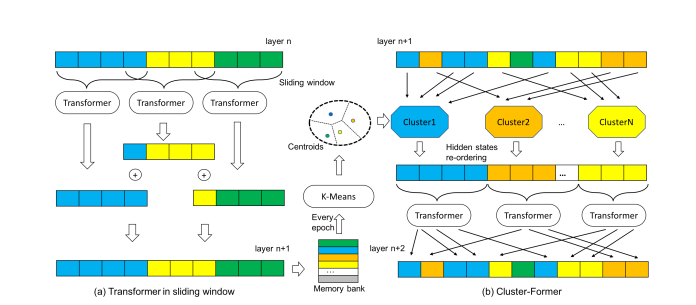
- Order of Cluster Former Model
- Chunk a long sequence into short ones with window size l and stride m (noted in this paper).
- Concatenate question Q with each sequence chuncked from the document.
- Pass Transformer Encoder to encode each sequence.
- Repeat steps 1 through 3 for N times. (N is number of Transformer Encoder)
- If the next layer is Cluster-Former Layer, layer n+1 will be saved into memory bank for the cluster centroids.

매일 매일 한 걸음씩 나아가고자 합니다.