Data augmentation
Data augmentation이 필요한 이유
- Neural networks는 데이터섹은 compact한 정보만 학습
- 실제 데이터와 다름
- 학습 데이터는 실제 데이터의 극히 일부일 뿐
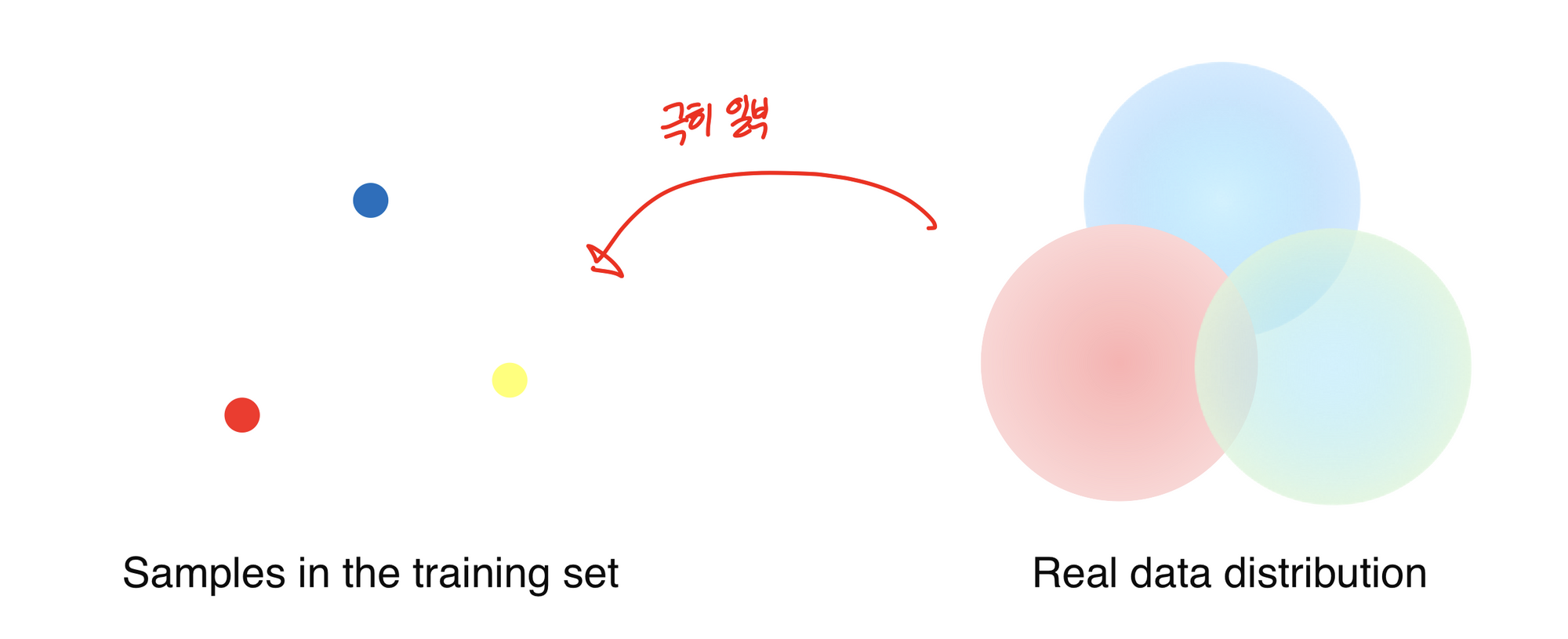
→ Augmentation은 sample data와 real data간의 gap을 줄여주는 역할을 한다.
Augmentation 종류
- 밝기 조절
- rotate, flip
- crop
- affine tranformation
- cutmix
- rand augment(랜덤으로)
Augmentation parameter
- 어떤 augmentation 사용할지
- 얼마나 강하게 적용할지
Leveraging pre-trained information
Transfer learning
데이터가 많이 필요한데 라벨링은 너무 비쌈
→ 사전에 학습된 모델을 이용하여 다른 데이터 셋에서 활용하는 기술
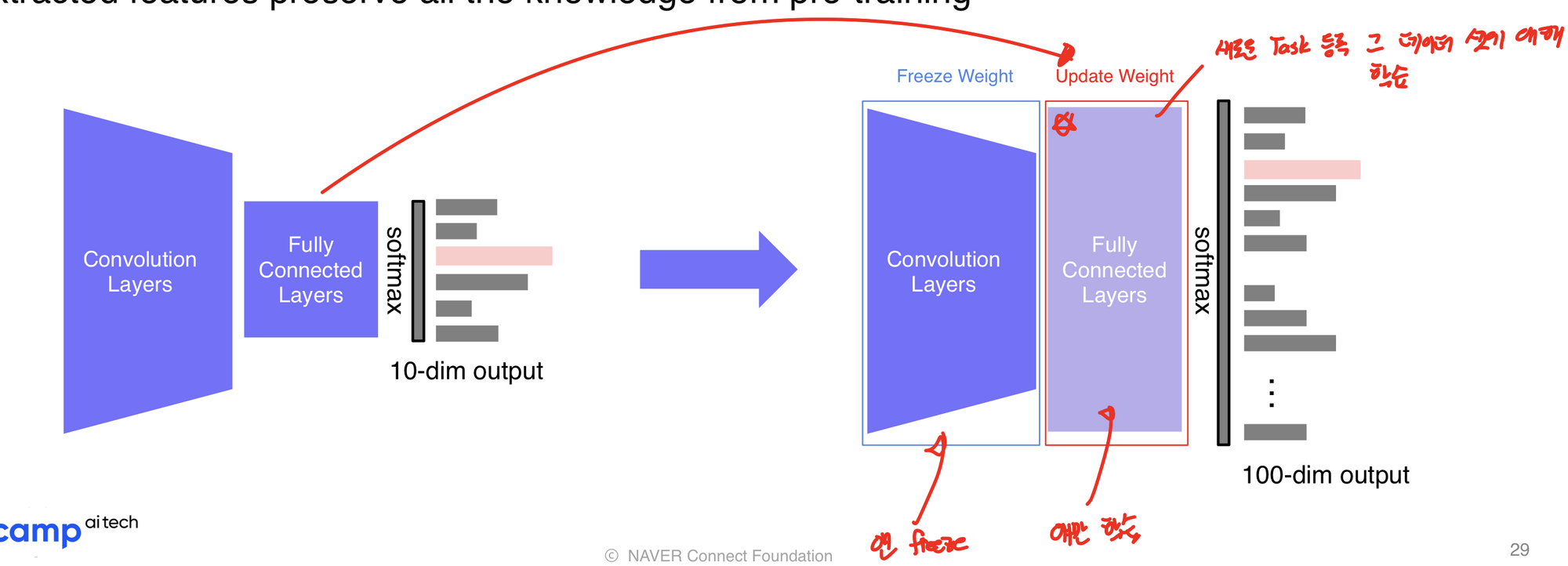
방법1: pretrained된 모델을 새로운 task에 활용(데이터가 정말 적을 때 사용해볼만 옵션)
원래 모델에서 convolution layer를 freeze시키고 fully connected layer를 제거한 후에 새로운 모델의 task에 맞게 학습
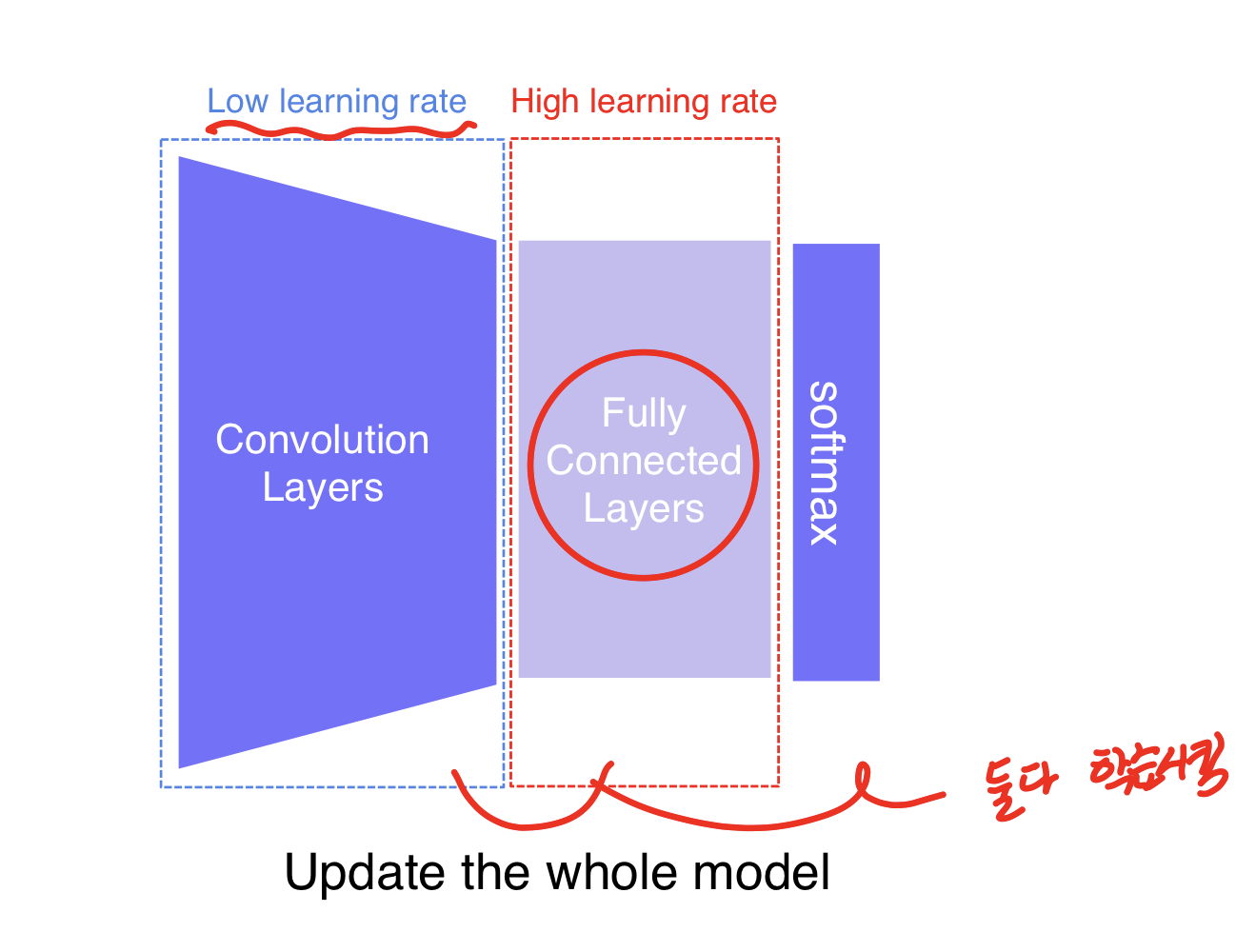
방법2: Fine tunning the whole model(데이터가 좀더 있을 때 해볼만한 옵션)
pretrained된 모델의 final layer를 새로운걸로 바꾸고 다시 모두 학습시키는 것(freeze 안함)
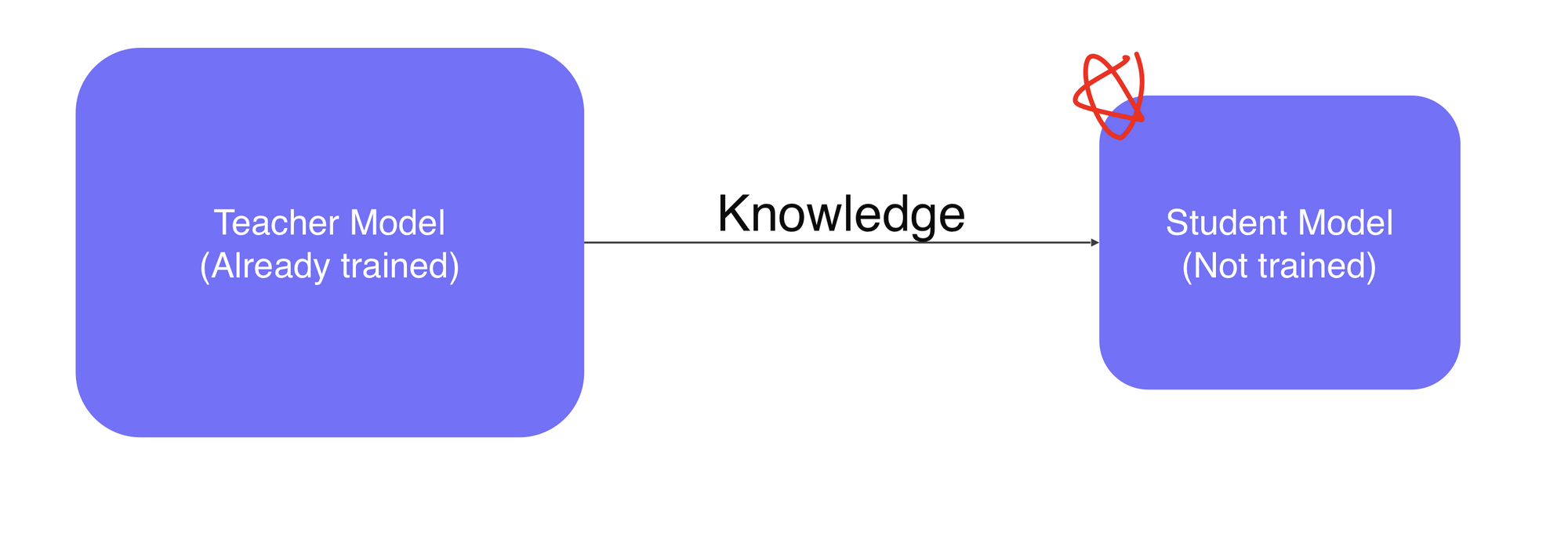
Knowledge distillation(농축물?, 추출물?, 정수)
이미 학습된 모델의 distillate 지식을 작은 모델에 학습시키는 것
모델압축에 사용
pseudo labeling을 통해 더 많은 데이터를 사용 가능하게 함
참고: 부스트캠프 AI Tech 4기 CV강의 오태현 교수님

Study and Share