Image classification
image classification의 역사
LeNet-5(1998)
1998년에 소개된 아주 간단한 CNN 구조
conv - pool - conv - pool - fc - fc
AlexNet(2012)
LeNet과 유사하지만 7개의 hidden layers(deeper) 6억개의 파라미터
large amount of data로 학습
activation함수로 ReLU를 사용하고 Regularization으로 dropout 사용
당시는 GPU메모리가 부족하여 두개의 GPU에 올려서 학습함
- LRN(Local Response Normalization)은 batch normalization으로 바뀌었고, 11x11 convolution filter는 사용되지 않음(너무 큼)
VGGNet(2014)
Simpler architecture 사용
3x3 conv filter만 사용하고 2x2 max pooling 사용 ← 11x11보다 파라미터수 적어 더 deep하게 쌓을 수 있음
3x3 여러개 사용해서 receptive field의 크기를 충분히 크게 유지할 수 있음
better performance(deep하게 쌓아서)
better generalization(적은 파라미터로 인해)
#Problems with deeper layers
layer가 깊어질수록 더 복잡한 관계에 대해서 학습하고 더 큰 receptive fields를 가지므로 더 강력한 features를 학습한다
→항상 깊게 쌓는게 좋은가? No!
문제
- gradient vanishing/exploding
- 복잡도가 높아져서 더 큰 메모리 있는 GPU 필요로함
- Degradation problem
GoogLeNet(2015)
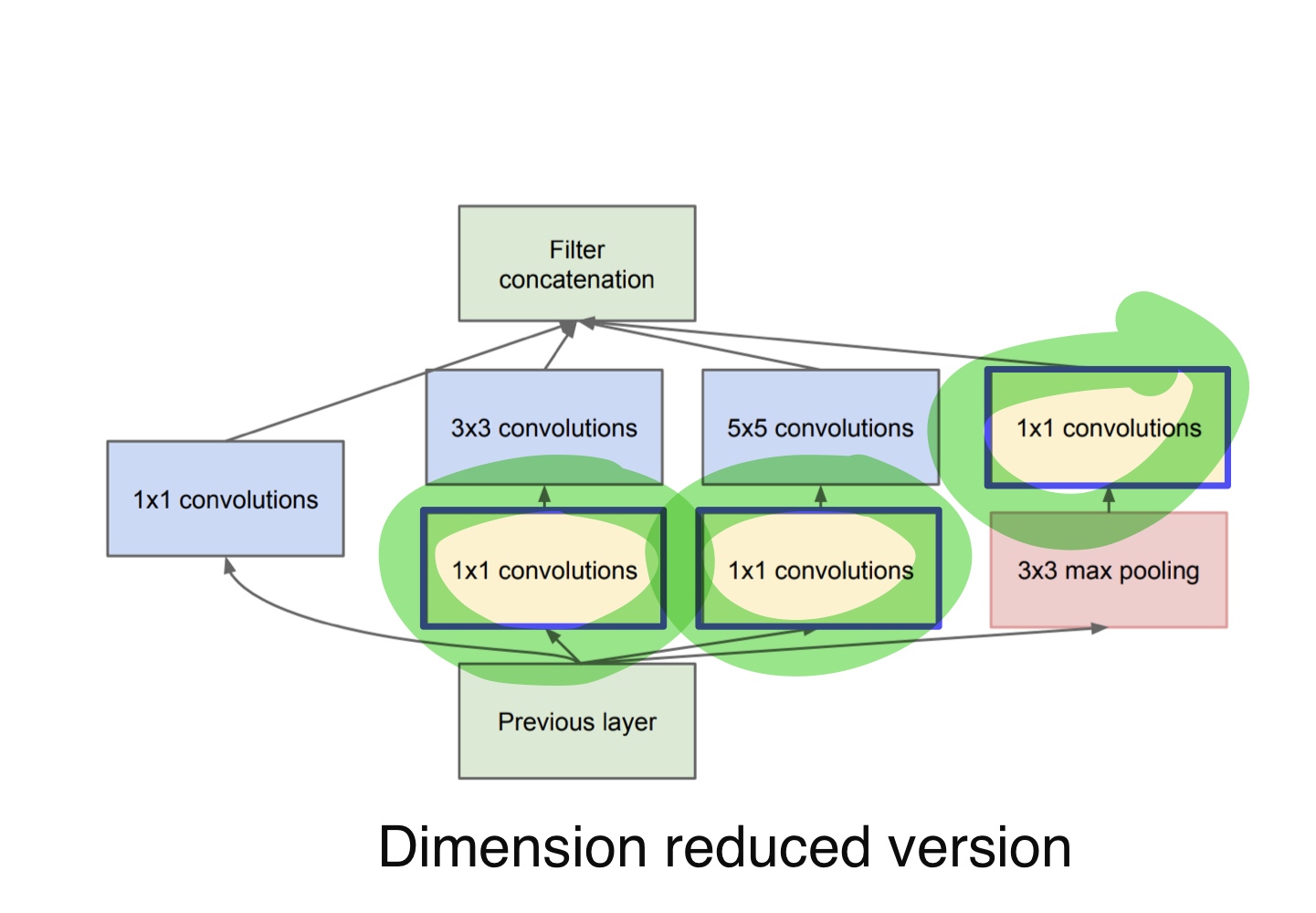
Inception module 사용하여 depth가 아닌 width를 넓게 만들어줌
문제: 계산 복잡도나 용량이 커지는 문제
해결책: 1x1 convolution을 사용!→ 파라미터수 감소
+문제: 깊게 쌓이면서 gradient가 사라지는 문제
해결책: Auxilary classifiers
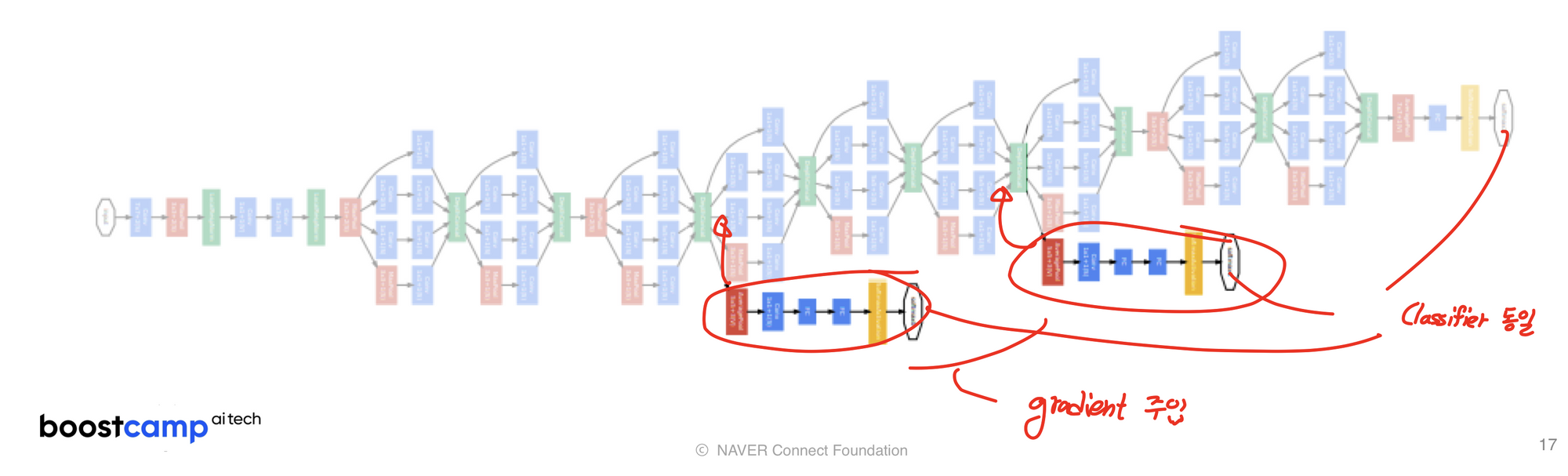
Auxilary classifiers를 이용하여 중간에 gradient를 주입해줘서 gradient vanishing 문제를 해결했다.
auxilary classifier는 training때만 사용하고 test할때는 제거한다.
ResNet(2016)
다른 모델들보다 엄청 deep하게 쌓음
네트워크가 깊어질수록 빠르게 degrade됨, 이건 optimization문제였음
Plain layer로 좋은 H(x)를 바로 학습하기 어려워짐→ Residual block을 이용함
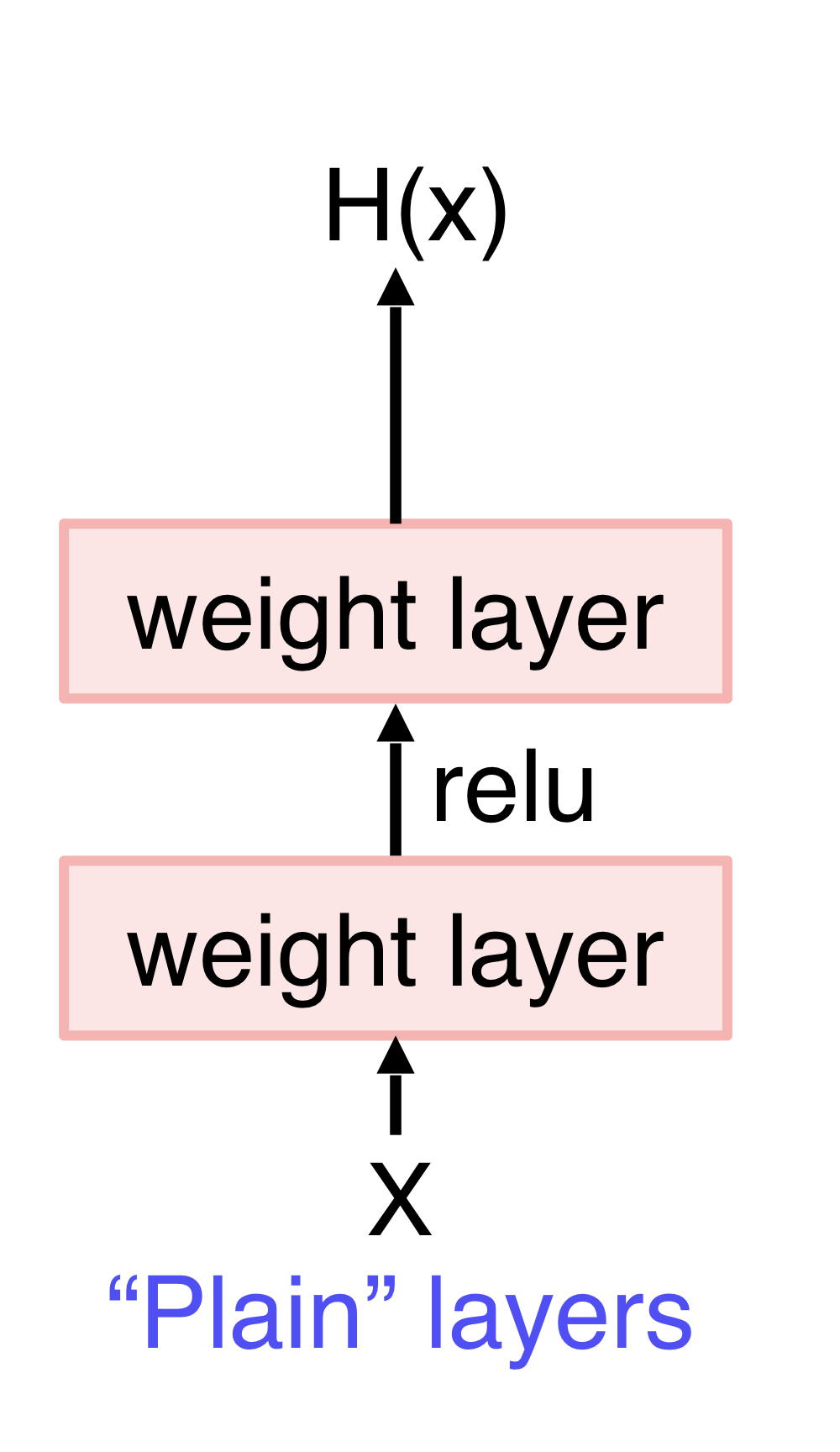
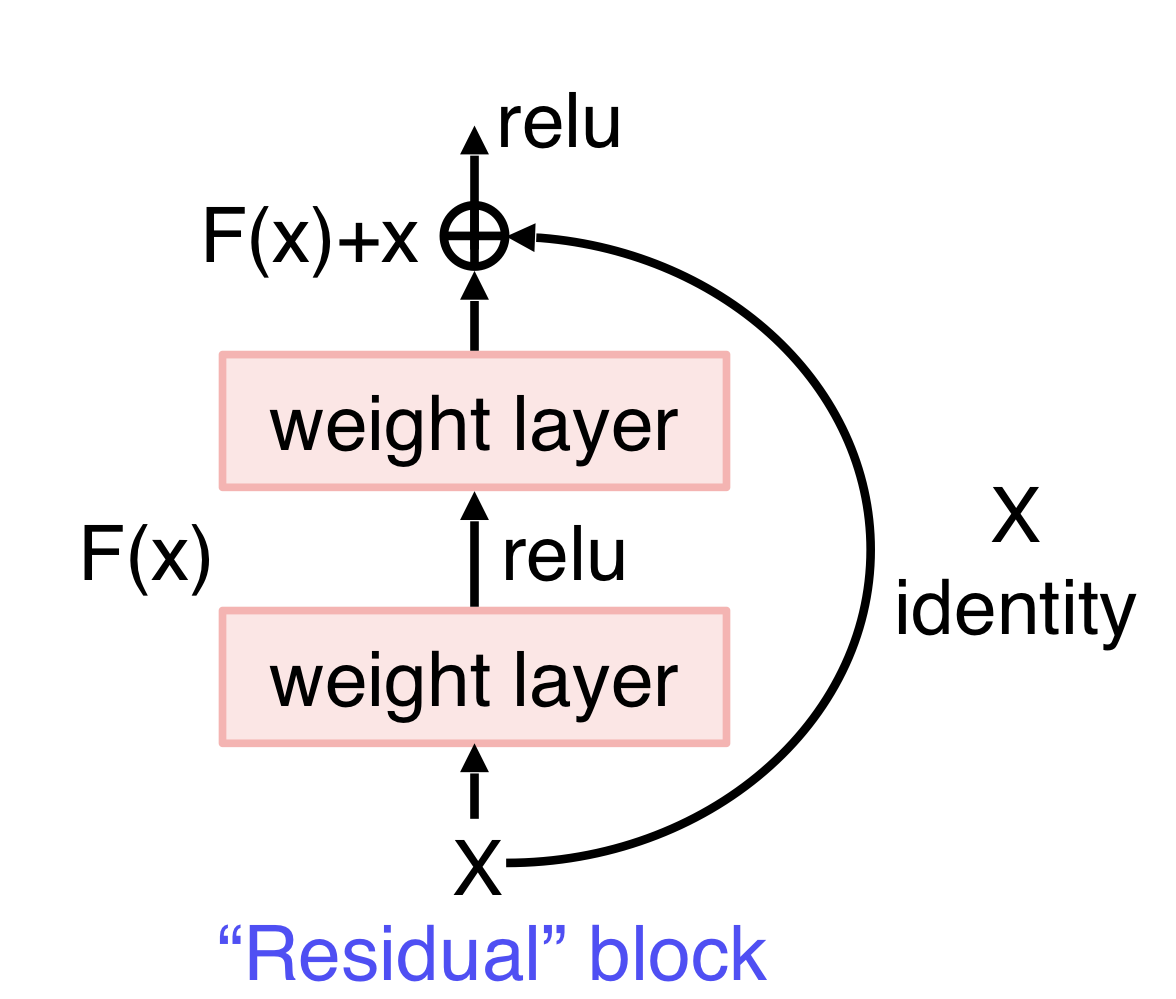
H(x)를 바로 학습하는 것은 어렵지만 residual block을 이용하면 H(x) = F(x) + x, F(x) = H(x) - x이므로 나머지 잔여부분만 학습해 학습 부담이 적어진다. 미분을 해도 1+F’(x)이므로 gradient vanising 문제를 막는다.
→ residual block은 skip connection을 이용한다.(X identity를 바로 위에 더해줌)
학습이 잘되는 이유?
residual network는 2^n개의 implicit paths를 가지고 있어 다양한 mapping을 학습할 수 있다.
DenseNet(2017)
ResNet에서는 skip connection을 통해 x를 그냥 더해줬음→ 정보 손실
DenseNet에서는 Dense blocks에서 각각의 layer들이 채널축으로 concat된다.
→ Gradient vanishing 완화, feature들을 더 잘 전해줌, Feature를 더 재사용
SENet
channel 사이에서 attention을 통해 채널간의 관계 파악 및 중요도를 파악할 수 있다.
- 주요 연산 Squeeze: average pooling을 통해 channel wise response의 분포를 파악한다.(채널의 평균정보 가져온다) Excitation: FC layer에서 얻은 channel wise 가중치들을 gating한다.(채널간의 연관성 고려해서 attetion score가져온다) 중요도가 떨어지는 것은 닫히도록, 중요도가 큰 것은 강하게
참고: 부스트캠프 AI Tech 4기 CV강의 오태현 교수님
