시작하며
오늘은 Pandas를 사용해서 CSV 파일과 Excel 파일을 불러오거나 저장하는 기능과 데이터를 시각화할 수 있는 Matplotlib에 대해 배웠다. 매일 배열값들만 보다가 그래프와 차트로 구현된 데이터를 보니 꽤 흥미로웠다.
csv
파일 불러오기
df = pd.read_csv("practice_book_dataset.csv")데이터 정보 확인
df.shapedf.dtypesdf.info()df.describe()df.head()df.tail()df.isnull()- 등 각종 정보 확인 메서드 사용 가능
새로운 csv 파일로 저장
new_df.to_csv(”파일이름.csv”)
df2 = df.copy()
df2["library"] = "seoul library"
df2.to_csv("new_book_dataset.csv")Excel
파일 불러오기
openpyxl설치 필요
df = pd.read_excel("practice_employee_dataset.xlsx")새로운 excel 파일로 저장
new_excel.to_excel(”파일이름.xlsx”)
df2 = df.copy()
df2["Working Period"] = 3
df2.to_excel("New_employee_dataset.xlsx")Matplotlib
import matplotlib
import matplotlib.pyplot as plt # matplotlib의 서브 패키지
matplotlib.__version__- 한글 폰트 깨짐 방지
# Windows에서 한글 폰트 설정
plt.rcParams['font.family'] = 'Malgun Gothic' # '맑은 고딕'이 설치되어 있을 경우
plt.rcParams['axes.unicode_minus'] = False # 마이너스(-) 부호 깨짐 방지# macOS에서 한글 폰트 설정
plt.rcParams['font.family'] = 'AppleGothic' # macOS 기본 한글 폰트
plt.rcParams['axes.unicode_minus'] = False그래프 그리기
plt.plot()
- 기본적으로는 선 그래프 생성
x = [1,2,3,4,5]
y = [10,14,19,23,25]
plt.plot(x,y)
plt.show()plt.savefig("test_graph.png"): 이미지를 파일로 저장plt.tight_layout(): 그래프 간격 자동 조정
plt.subplots(행, 열)
- figure : 여러 그래프가 그려지는 최상위 컨테이너
- axes : 실제 그래프가 그려지는 공간
- axis : 그래프의 축
- 행과 열을 입력하지 않으면 하나의 figure와 하나의 axes를 만듦
- 1행 2열의 axes 생성
fig, axs = plt.subplots(1,2)
axs[0].plot([1,2,3], [1,2,3])
axs[1].plot([1,2,3], [1,4,9])
plt.show()
- 2행 2열의 axes 생성
fig, axs = plt.subplots(2,2)
axs[0,0].plot([1,2,3], [1,2,3])
axs[0,1].plot([1,2,3], [1,4,9])
axs[1,0].plot([1,2,3], [3,2,1])
axs[1,1].plot([1,2,3], [9,4,1])
plt.show()
그래프의 공통 구성 요소
- 기본 방식
linestyle: 그래프 스타일 설정label: 범례에 표시될 이름 지정color: 그래프 색 변경marker: 그래프 마커 생성 및 모양 변경title(): 제목fontsize: 폰트 사이즈 조절color: 글자 색 변경
xlabel(), ylabel(): x, y축 이름 지정labelpad: 간격 설정
xticks(), yticks(): x, y축 개수 지정rotation: 기울기 설정
xlim(), ylim(): x, y축 시작/끝 지점 설정legend(): 범례 (생성시label=설정 필수)loc: 범례 위치 설정”lower right”, “upper left”title: 범례의 이름 설정
grid(): 그리드 생성linestyle: 그리드 스타일 설정alpha: 투명도 조절axis: 그리드 표시 축 설정“x”, “y”
plt.plot([1,2,3], [1,4,9], label="제곱 그래프", linestyle=":", color="g", marker="o")
plt.title("제곱 함수 그래프", color="b", fontsize=20)
plt.xlabel("x 값")
plt.ylabel("y 값(x의 제곱)")
plt.xticks([1,2,3], ["A", "B", "C"])
plt.yticks([1,5,10,15])
plt.legend()
plt.grid(linestyle="--", alpha=0.5)
plt.show()
subplots()방식fig, ax = plt.subplots()set_title(): 제목set_xlabel(), set_ylabel(): x, y축 이름 지정
fig, ax = plt.subplots()
ax.plot([1,2,3],[1,4,9], label="제곱 그래프")
ax.set_title("제곱 함수 그래프")
ax.set_xlabel("x 값")
ax.set_ylabel("y 값(x의 제곱)")
ax.legend()
ax.grid()
plt.show()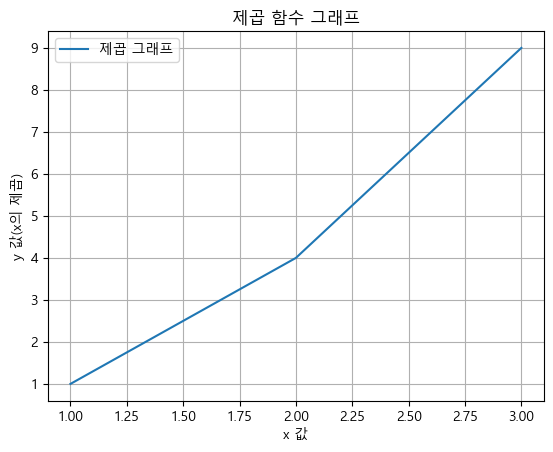
fig.suptitle(): 전체 이름 설정
fig, axs = plt.subplots(2,2)
fig.suptitle("여러 함수 그래프")
axs[0,0].plot([1,2,3], [1,2,3])
axs[0,0].set_title("1번 그래프")
axs[0,1].plot([1,2,3], [1,4,9])
axs[0,1].set_title("2번 그래프")
axs[1,0].plot([1,2,3], [3,2,1])
axs[1,0].set_title("3번 그래프")
axs[1,1].plot([1,2,3], [9,4,1])
axs[1,1].set_title("4번 그래프")
plt.tight_layout()
plt.show()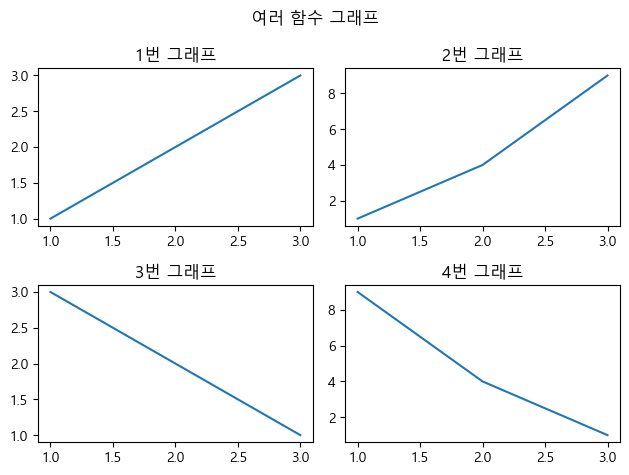
하나의 axes에 여러개의 그래프 그리기
x = np.arange(10)
y1 = 2 * x + 1
y2 = 3 * x - 5
plt.plot(x, y1, marker="o", label="y = 2x + 1", color="c")
plt.plot(x, y2, marker="*", label="y = 3x - 5", color="m")
plt.title("두개의 선 그래프 비교")
plt.xlabel("x값")
plt.ylabel("y값")
plt.legend()
plt.grid(linestyle=":", alpha=0.5)
plt.show()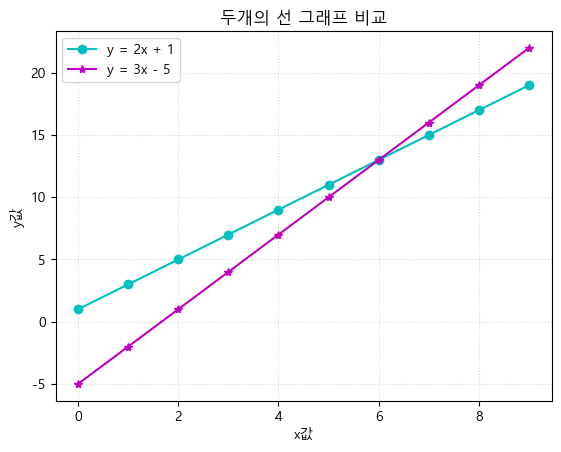
다양한 2D 그래프 그리기
수직 막대 그래프
plt.bar(): 수직 막대 그래프 생성width: 그래프 폭 조절
labels = ["A", "B", "C", "D"]
values = [10,24,15,32]
plt.bar(labels, values, width=0.5)
plt.show()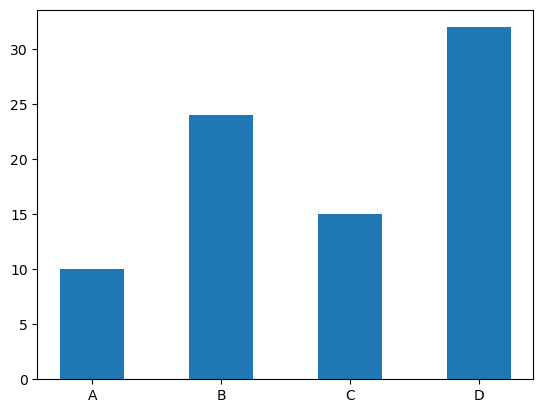
수평 막대 그래프
plt.barh(): 수평 막대 그래프 생성
labels = ["A", "B", "C", "D"]
values = [10,24,15,32]
plt.barh(labels, values, height=0.5)
plt.show()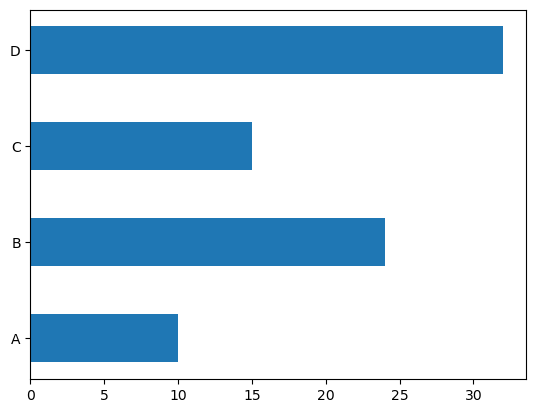
여러 막대 그래프
- 각 그래프를 x축의 -와 +위치로 설정
labels = ["1분기", "2분기", "3분기", "4분기"]
men_means = [20,34,30,35]
women_means = [25,32,34,40]
x = np.arange(len(labels))
fig, ax = plt.subplots()
width = 0.4
ax.bar(x - width/2, men_means, width, label="남성")
ax.bar(x + width/2, women_means, width, label="여성")
ax.legend()
ax.set_xticks(x, labels)
plt.show()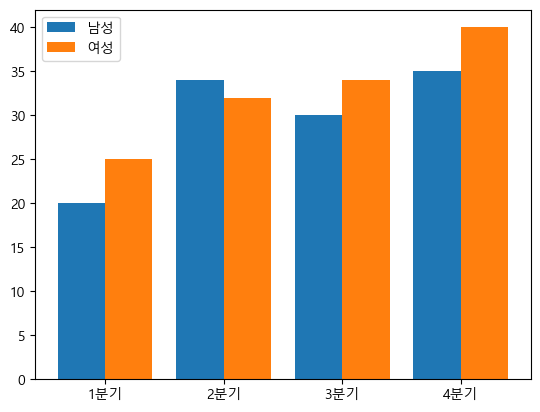
히스토그램 (Histogram) 그래프
- 연속형 데이터의 분포를 구간별로 막대의 높이로 나타내는 그래프
- 히스토그램 그래프 생성
plt.hist(data, bins=None, edgecolor=None, rwidth=None)data: 입력 데이터 (수치형 배열)bins: 구간의 개수 또는 구간 리스트edgecolor: 테두리 색 변경rwidth: 그래프 폭 설정
np.random.seed(42)
data = np.random.randint(1,7,(100))
plt.hist(data, bins=(np.arange(1,8) - 0.5), edgecolor="k", color="g", rwidth=0.5)
plt.title("주사위 눈 빈도 히스토그램")
plt.grid(linestyle=":", alpha=0.7, axis="y")
plt.xlabel("주사위 눈")
plt.ylabel("빈도")
plt.ylim(0,30)
plt.show()cnt, bins = plt.hist(data, bins=(np.arange(1,8) - 0.5)): 언패킹하여 각 칸의 데이터 개수와 분포값 확인 가능
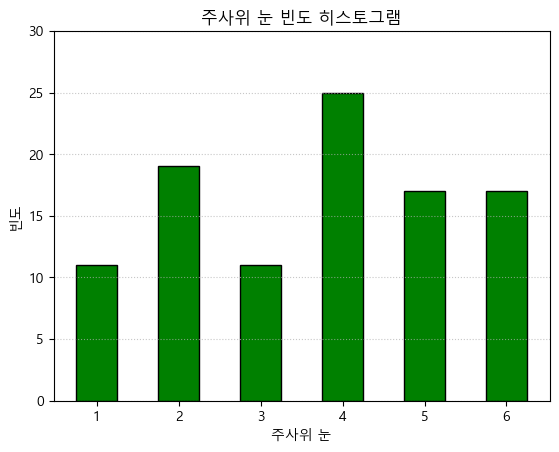
산점도 그래프
- 변수 간의 관계 (상관관계, 패턴, 분포)를 점으로 시각화한 그래프
- 산점도 그래프 생성
plt.scatter(x, y, s=None, c=None)x, y: x, y축 데이터s: 점의 크기c: 점의 색상cmap: color map 불러오기 가능colorbar(): 색상별 데이터 값 확인
np.random.seed(42)
n = 50
x = np.random.rand(n)
y = np.random.rand(n)
colors = np.random.rand(n)
sizes = np.random.rand(n) * 1000
plt.scatter(x, y, s=sizes, c=colors, alpha=0.7, cmap="viridis")
plt.colorbar()
plt.show()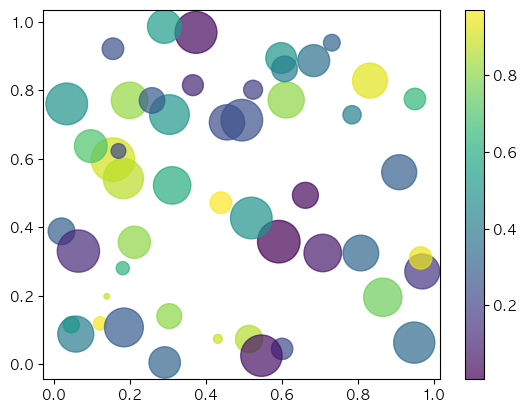
파이 차트 (Pie Chart)
- 전체에 대한 부분의 비율을 원형의 조각으로 표현하는 그래프
- 파이 차트 생성
plt.pie(sizes, labels=None, autopct=None, startangle=None, colors=[], explode=None, shadow=False)sizes: 각 조각의 값(수치형, 전체 합이 1 또는 100% 기준)labels: 각 조각의 이름autopct: 각 조각에 비율/수치 표시”%1.1f%%”= 소수점 1자리 까지만 표시startangle: 시작 각도colors: 각 조각의 인덱스에 따라 색 지정 가능explode: 특정 조각 강조 가능shadow: True 시 그림자 생성
labels = ["Apple", "Banana", "Mango", "Blueberry"]
sizes = [15,30,45,10]
explode = [0,0.1,0,0]
plt.pie(sizes, labels=labels, autopct="%1.0f%%", shadow=True, explode=explode, startangle=80, colors=["r", "y", "m", "b"])
plt.show()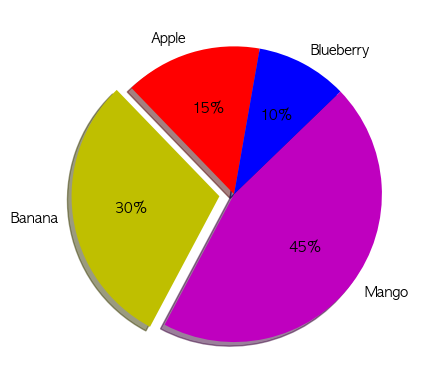
마치며
어제는 코드 결과값을 정리하느라 시간이 다 갔었는데, 오늘은 그래프 이미지 처리에서 시간이 오래 걸렸다. 그래프 이미지를 하나씩 가져와서 마크다운 형식으로 정리하는 과정이 생각보다 번거로웠다.
노션에서 바로 이미지를 가져올 수 있으면 좋을 텐데, 복사한 이미지가 제대로 열리지 않아서 결국 VS Code에서 다시 복사해서 정리해야 했다.
앞으로 데이터 관련 블로깅을 할 때 이미지를 많이 활용할 것 같은데, 더 효율적인 방법을 빨리 찾아봐야겠다.
NOTION

Hello I'm TaeHyunAn, Currently Studying Data Analysis