- 실제 강의 내용의 일부분만 발췌했습니다.
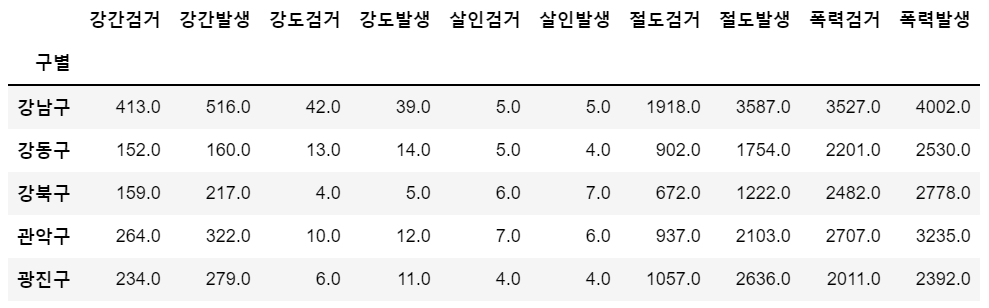
<원본 데이터 1>
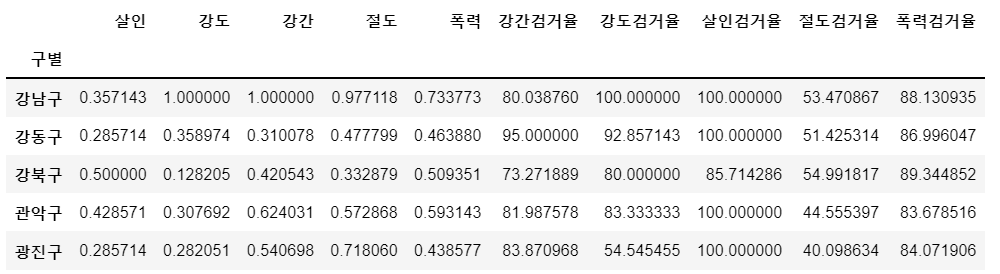
- 직전 포스팅 데이터에서 살인, 강도, 성범죄, 절도, 폭력을 정규화
- 정규화란 0에서 1사이 값으로 변환한 것으로 컬럼/(컬럼.max())로 구함
# 참고 코드
col = ["살인","강도","강간","절도","폭력"]
crime_anal_norm = crime_anal_gu[col]/crime_anal_gu[col].max()<원본 데이터 2>
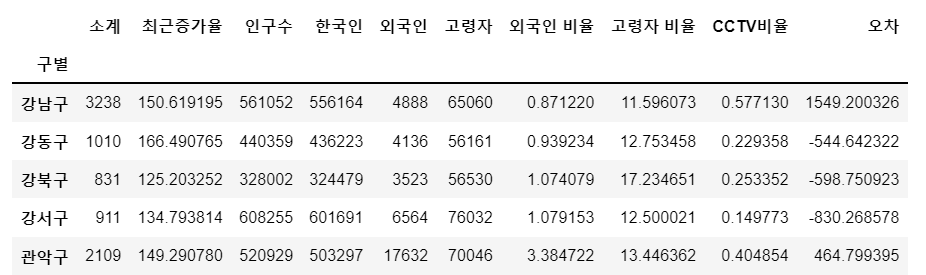
<결과 데이터>
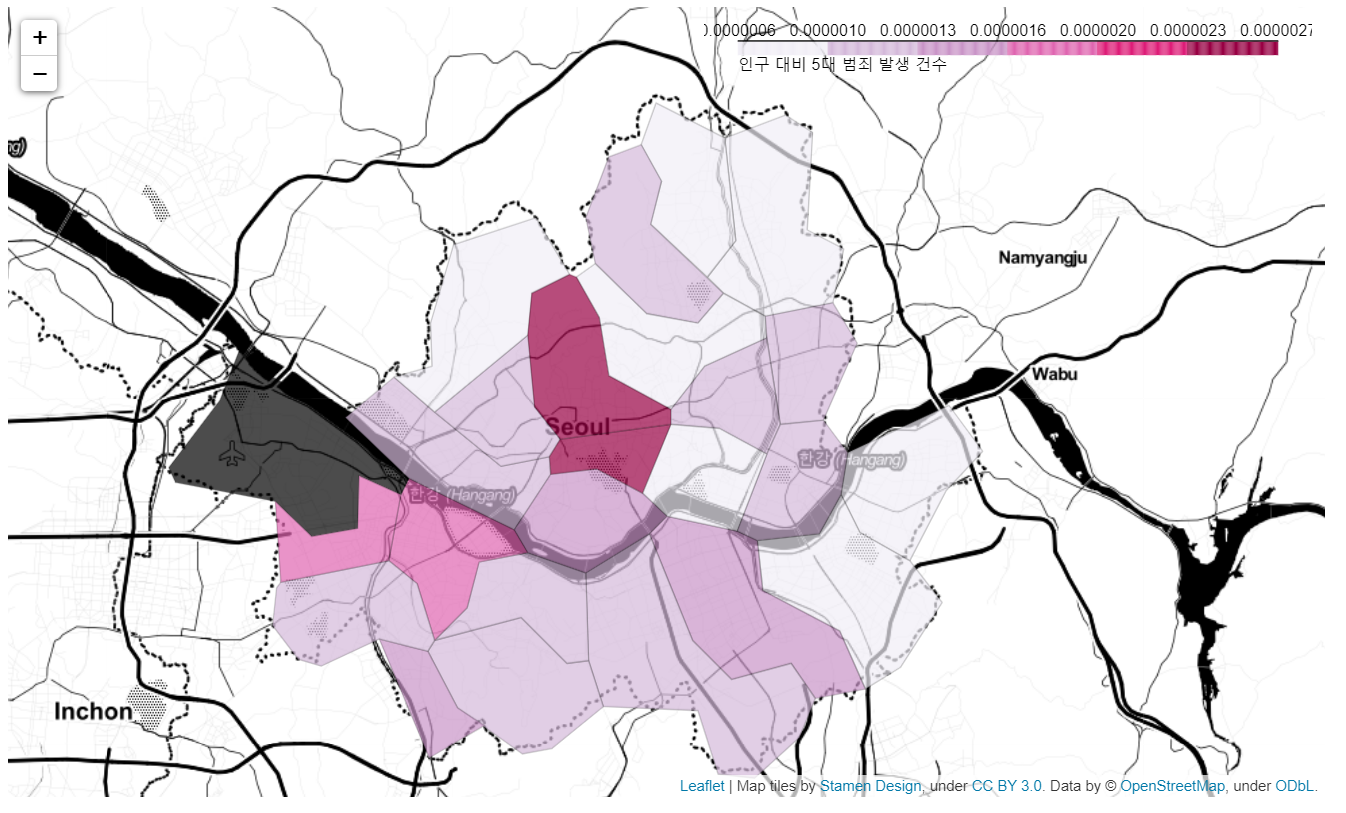
서울시 구별로 인구수 대비 5대 범죄 발생 빈도를 지도로 시각화해보자
# 원본데이터1 형성하기
col = ["살인","강도","강간","절도","폭력"]
crime_anal_norm = crime_anal_gu[col]/crime_anal_gu[col].max()
col2 = ["강간검거율","강도검거율","살인검거율","절도검거율","폭력검거율"]
crime_anal_norm[col2]= crime_anal_gu[col2]
# 원본데이터2 담아오기 (index는 "구별"로 원본데이터1과 동일하게 맞추기)
result_CCTV = pd.read_csv(
"../data/01.CCTV_result.csv",
index_col = "구별", # "구별" 컬럼을 인덱스로 설정
encoding = "utf-8")
# 원본데이터2의 "인구수", "소계"컬럼을 원본데이터1에 붙이기
crime_anal_norm[["인구수","CCTV"]]= result_CCTV[["인구수","소계"]]
crime_anal_norm.head()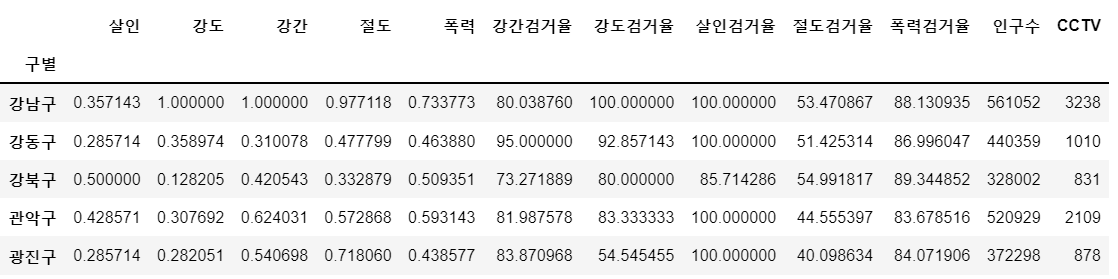
# 정규화된 범죄 종류별 발생 건수의 평균을 구해서 범죄 컬럼 대표값으로 사용
col = ["강간","강도","살인","절도","폭력"]
crime_anal_norm["범죄"]= np.mean(crime_anal_norm[col], axis = 1)
# 우리나라 경계선 좌표값이 담긴 데이터 담아오기
geo_path = "../data/02. skorea_municipalities_geo_simple.json"
geo_str = json.load(open(geo_path, encoding = "utf-8"))
# 인구 대비 5대 범죄 발생 건수 지도 시각화
tmp_criminal = crime_anal_norm["범죄"]/crime_anal_norm["인구수"]
my_map = folium.Map(
location = [37.5502, 126.982],
zoom_start = 11,
tiles = "Stamen Toner"
)
folium.Choropleth(
geo_data = geo_str, # json.load(open(행정구역경계선데이터))
data = tmp_criminal, #시각화할 데이터
# geo_data와 매핑할 변수, 시각화할 data의 변수
columns = [crime_anal_norm.index, tmp_criminal],
# 지리데이터내 지리데이터와 시각화할 데이터의 공통변수
key_on = "feature.id",
fill_color = "PuRd",
fill_opacity = 0.7,
line_opacity = 0.2,
legend_name = "인구 대비 5대 범죄 발생 건수"
#colorbar 아래에 적어줄 범례 문구
).add_to(my_map)
my_map

쉽고 유익하게 널리널리