- 실제 강의 내용의 일부분만 발췌했습니다.
<원본데이터>
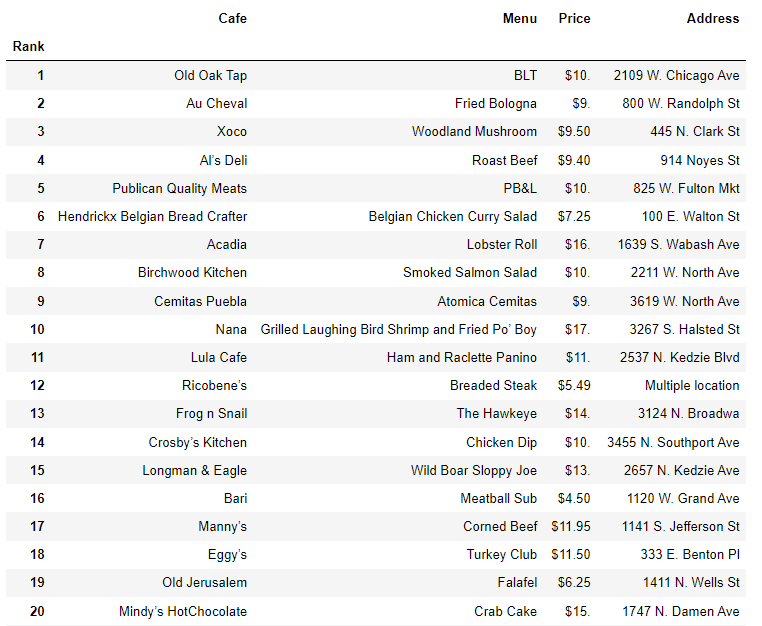
시카고 맛집 50선

<결과데이터>
메인 페이지에서 각 가게의 정보를 가져온다
- 가게 이름, 대표 메뉴
from urllib.request import Request, urlopen
from bs4 import BeautifulSoup
url_base = "https://www.chicagomag.com/"
url_sub = "chicago-magazine/november-2012/best-sandwiches-chicago/"
url = url_base + url_sub
response = urlopen(url)
response.status 위와 같이 접근을 하면 403error가 뜬다. 서버에서 접근을 거부한 것이다. 이를 해결하려면 header를 지정해주어야 한다. 원래는 하기에 표기된 User-Agent 값으로 header를 지정해주어야 한다.
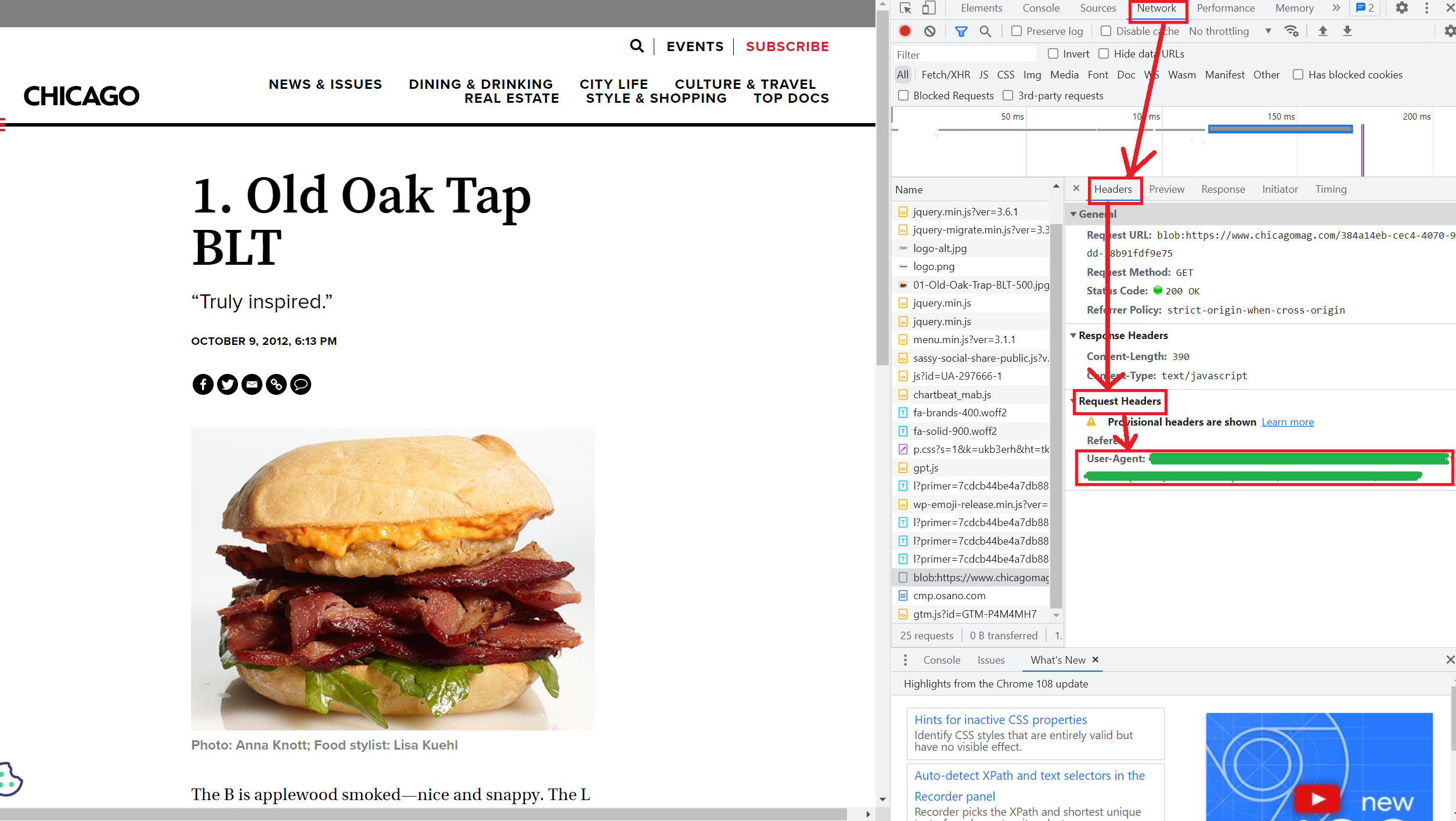
다만, 약식으로 "Chrome"을 쓰기도 한다.
req = Request(url, headers = {"User-Agent":"Chrome"})
response= urlopen(req)
response.status200
soup = BeautifulSoup(req,"html.parser")
tmp_one = soup.find_all("div","sammy")[0]
print(tmp_one)
tmp_one.find("div",{"class":"sammyListing"}).text'BLT\nOld Oak Tap\nRead more '
import re
tmp_string = tmp_one.find(class_="sammyListing").get_text()
re.split("\n|\r\n", tmp_string)['BLT', 'Old Oak Tap', 'Read more ']
print(re.split("\n|\r\n", tmp_string)[0])
print(re.split("\n|\r\n", tmp_string)[1])BLT
Old Oak Tap
from urllib.parse import urljoin
# 필요한 내용을 담을 빈 리스트
# 리스트로 하나씩 컬럼을 만들고, DataFrame으로 합칠 예정
rank = []
main_menu =[]
cafe_name = []
url_add = []
list_soup = soup.find_all("div","sammy")
for item in list_soup:
rank.append(item.find(class_="sammyRank").get_text())
tmp_string = item.find(class_="sammyListing").get_text()
main_menu.append(re.split("\n|\r\n", tmp_string)[0])
cafe_name.append(re.split("\n|\r\n", tmp_string)[1])
# base 링크와 상대 링크를 결합시켜서 append
url_add.append(urljoin(url_base, item.find("a")["href"]))
import pandas as pd
data = {
"Rank" : rank,
"Menu" : main_menu,
"Cafe" : cafe_name,
"URL" : url_add
}
df= pd.DataFrame(data)
df.tail(2)
50개의 URL에 접근해서 대표메뉴의 가격과 가게 주소를 스크랩핑하자
df["URL"][0]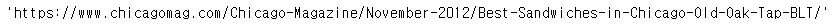
req = Request(df["URL"][0], headers = {"user-agent":"Chorme"})
html = urlopen(req).read()
soup_tmp = BeautifulSoup(html,"html.parser")
soup_tmp.find("p","addy")
price_tmp = soup_tmp.find("p","addy").text
re.split(".,", price_tmp)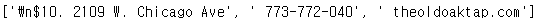
# 대표 메뉴 가격과 주소 추출
price_tmp = re.split(".,",price_tmp)[0]
# 대표 메뉴 가격과 주소 분리
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
print(price_tmp[len(tmp)+2:])
print(tmp)
price = []
address = []
for idx, row in df.iterrows():
req = Request(row["URL"],headers = {"user-agent":"Chrome"})
html=urlopen(req).read()
soup_tmp = BeautifulSoup(html, "html.parser")
#
gettings = soup_tmp.find("p","addy").get_text()
price_tmp = re.split(".,", gettings)[0]
tmp = re.search("\$\d+\.(\d+)?", price_tmp).group()
price.append(tmp)
address.append(price_tmp[len(tmp)+2:])
df["Price"] = price
df["Address"] = address
df.tail()
df= df.loc[:,["Rank","Cafe","Menu","Price","Address"]]
df.set_index("Rank", inplace = True)
df.head()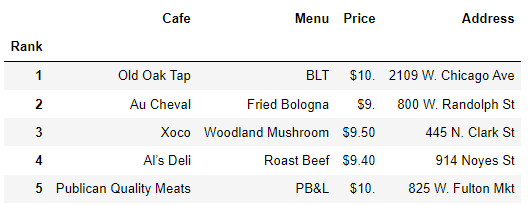

쉽고 유익하게 널리널리