python
Importing the libraries
import numpy as np
import matplotlib.pyplot as plt
import pandas as pdImporting the dataset
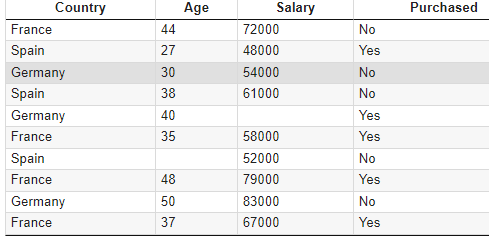
dataset = pd.read_csv('Data.csv')
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, -1].values
# iloc : 항목 추출
# [:, :-1] : ':' - 전체 범위 , ':-1' - 마지막 열 뺀 범위
print(X)
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 nan]
['France' 35.0 58000.0]
['Spain' nan 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]
print(y)
['No' 'Yes' 'No' 'No' 'Yes' 'Yes' 'No' 'Yes' 'No' 'Yes']Taking care of missing data
from sklearn.impute import SimpleImputer
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
imputer.fit(X[:, 1:3])
X[:, 1:3] = imputer.transform(X[:, 1:3])
print(X)
[['France' 44.0 72000.0]
['Spain' 27.0 48000.0]
['Germany' 30.0 54000.0]
['Spain' 38.0 61000.0]
['Germany' 40.0 63777.77777777778]
['France' 35.0 58000.0]
['Spain' 38.77777777777778 52000.0]
['France' 48.0 79000.0]
['Germany' 50.0 83000.0]
['France' 37.0 67000.0]]Encoding categorical data
범주형 데이터 인코딩
Encoding the Independent Variable
독립변수 : 연구자가 의도적으로 변화시키는 변수 , 종속변수에 영향을 주는 변수, 입력값이나 원인을 나타냄
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import OneHotEncoder
ct = ColumnTransformer(transformers=[('encoder', OneHotEncoder(), [0])], remainder='passthrough')
X = np.array(ct.fit_transform(X))
print(X)
[[1.0 0.0 0.0 44.0 72000.0]
[0.0 0.0 1.0 27.0 48000.0]
[0.0 1.0 0.0 30.0 54000.0]
[0.0 0.0 1.0 38.0 61000.0]
[0.0 1.0 0.0 40.0 63777.77777777778]
[1.0 0.0 0.0 35.0 58000.0]
[0.0 0.0 1.0 38.77777777777778 52000.0]
[1.0 0.0 0.0 48.0 79000.0]
[0.0 1.0 0.0 50.0 83000.0]
[1.0 0.0 0.0 37.0 67000.0]]Encoding the Dependent Variable
종속변수 : 독립변수 변화에 따라 어떻게 변하는지 알고 싶어하는 변수, 결과물이나 효과를 나타냄
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
print(y)
[0 1 0 0 1 1 0 1 0 1]Splitting the dataset into the Training set and Test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=1)
print(X_train)
[[0.0 0.0 1.0 38.77777777777778 52000.0]
[0.0 1.0 0.0 40.0 63777.77777777778]
[1.0 0.0 0.0 44.0 72000.0]
[0.0 0.0 1.0 38.0 61000.0]
[0.0 0.0 1.0 27.0 48000.0]
[1.0 0.0 0.0 48.0 79000.0]
[0.0 1.0 0.0 50.0 83000.0]
[1.0 0.0 0.0 35.0 58000.0]]
print(X_test)
[[0.0 1.0 0.0 30.0 54000.0]
[1.0 0.0 0.0 37.0 67000.0]]
print(y_train)
[0 1 0 0 1 1 0 1]
print(y_test)
[0 1]Feature Scaling
서로 다른 변수의 값 범위를 일정한 수준으로 맞추는 작업
하는 이유
1. 변수 값의 범위, 단위 달라 발생 가능한 문제 예방
2. ML 모델이 특정 데이터의 편향성을 갖는 걸 방지
3. data 범위 크기에 따라 모델 학습하는데 있어 bias 달라질 수 있어 하나의 범위 크기로 통일해주는 작업이 필요할 수 있다.
Feature scaling 종류
1. 표준화
2. 정규화
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train[:, 3:] = sc.fit_transform(X_train[:, 3:])
X_test[:, 3:] = sc.fit_transform(X_test[:, 3:])
print(X_train)
[[0.0 0.0 1.0 -0.19159184384578545 -1.0781259408412425]
[0.0 1.0 0.0 -0.014117293757057777 -0.07013167641635372]
[1.0 0.0 0.0 0.566708506533324 0.633562432710455]
[0.0 0.0 1.0 -0.30453019390224867 -0.30786617274297867]
[0.0 0.0 1.0 -1.9018011447007988 -1.420463615551582]
[1.0 0.0 0.0 1.1475343068237058 1.232653363453549]
[0.0 1.0 0.0 1.4379472069688968 1.5749910381638885]
[1.0 0.0 0.0 -0.7401495441200351 -0.5646194287757332]]
print(X_test)
[[0.0 1.0 0.0 -1.0 -1.0]
[1.0 0.0 0.0 1.0 1.0]]R
data_prepro_template.R
# Data Preprocessing
# Importing the dataset
dataset = read.csv('Data.csv')
# Taking care of missing data
dataset$Age = ifelse(is.na(dataset$Age),
ave(dataset$Age, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Age)
dataset$Salary = ifelse(is.na(dataset$Salary),
ave(dataset$Salary, FUN = function(x) mean(x, na.rm = TRUE)),
dataset$Salary)
# Encoding categorical data
dataset$Country = factor(dataset$Country,
levels = c('France', 'Spain', 'Germany'),
labels = c(1, 2, 3))
dataset$Purchased = factor(dataset$Purchased,
levels = c('No', 'Yes'),
labels = c(0, 1))
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[, 2:3] = scale(training_set[, 2:3])
test_set[, 2:3] = scale(test_set[, 2:3])
////////////////////////////////////////////////////
# Data Preprocessing
# Importing the dataset
dataset = read.csv('Data.csv')
dataset = dataset[, 2:3]
# Splitting the dataset into the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased, SplitRatio = 0.8)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
# training_set[, 2:3] = scale(training_set[, 2:3])
# test_set[, 2:3] = scale(test_set[, 2:3])데이터 세트 분리 이유 : 과적합 방지
