
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. WRN 배경
 기존의 ResNet은 네트워크의 Depth을 효과적으로 늘릴 수 있는
기존의 ResNet은 네트워크의 Depth을 효과적으로 늘릴 수 있는 Residual block라는 기여를 통해 상당히 깊은 네트워크도 구현이 가능한 지평을 열았다.
하지만 Vanishing Gradient, Expoloding Gradinet의 문제가 억제가 되었다는 것이지 계속 층을 쌓아나가게 되면 결국은 위 같은 문제에 Degradation와 같은 학습성능이 저하되는 현상까지 야기될 수 있다.
WRN(Wide Residual Networks)는 이 Depth를 늘리는 것이 아닌 Kernel의 개수에 해당하는 Width를 늘려서 Depth를 억제하면서 성능을 유지시키는 방법을 제시한 논문이다.
1.1 Wide residual block
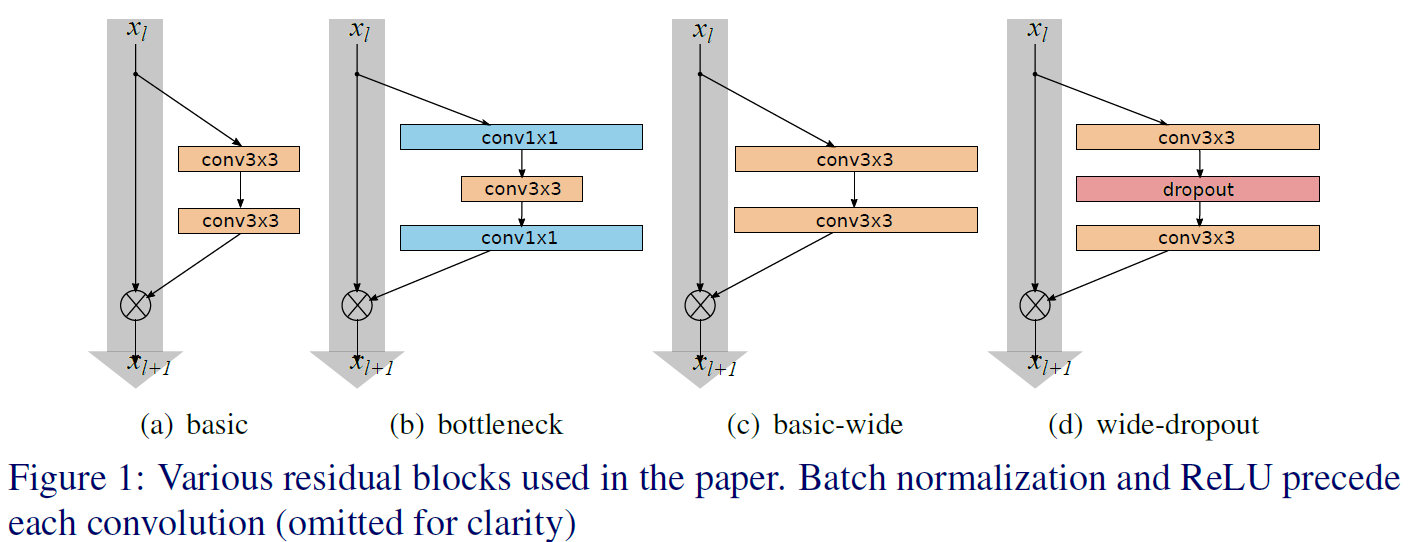 논문에서는 위 4가지 기본 블록 중 Wide residual block에 속하는 (c), (d)를 사용을 통해 ResNet의 성능을 개선하는 아이디어를 제시한다
논문에서는 위 4가지 기본 블록 중 Wide residual block에 속하는 (c), (d)를 사용을 통해 ResNet의 성능을 개선하는 아이디어를 제시한다
라고 표현하고 있지만, 그림만 봐서는 조금 이해가 안되는 부분이 꽤나 많다.
이 그림을 다시 그리면 아래와 같다.
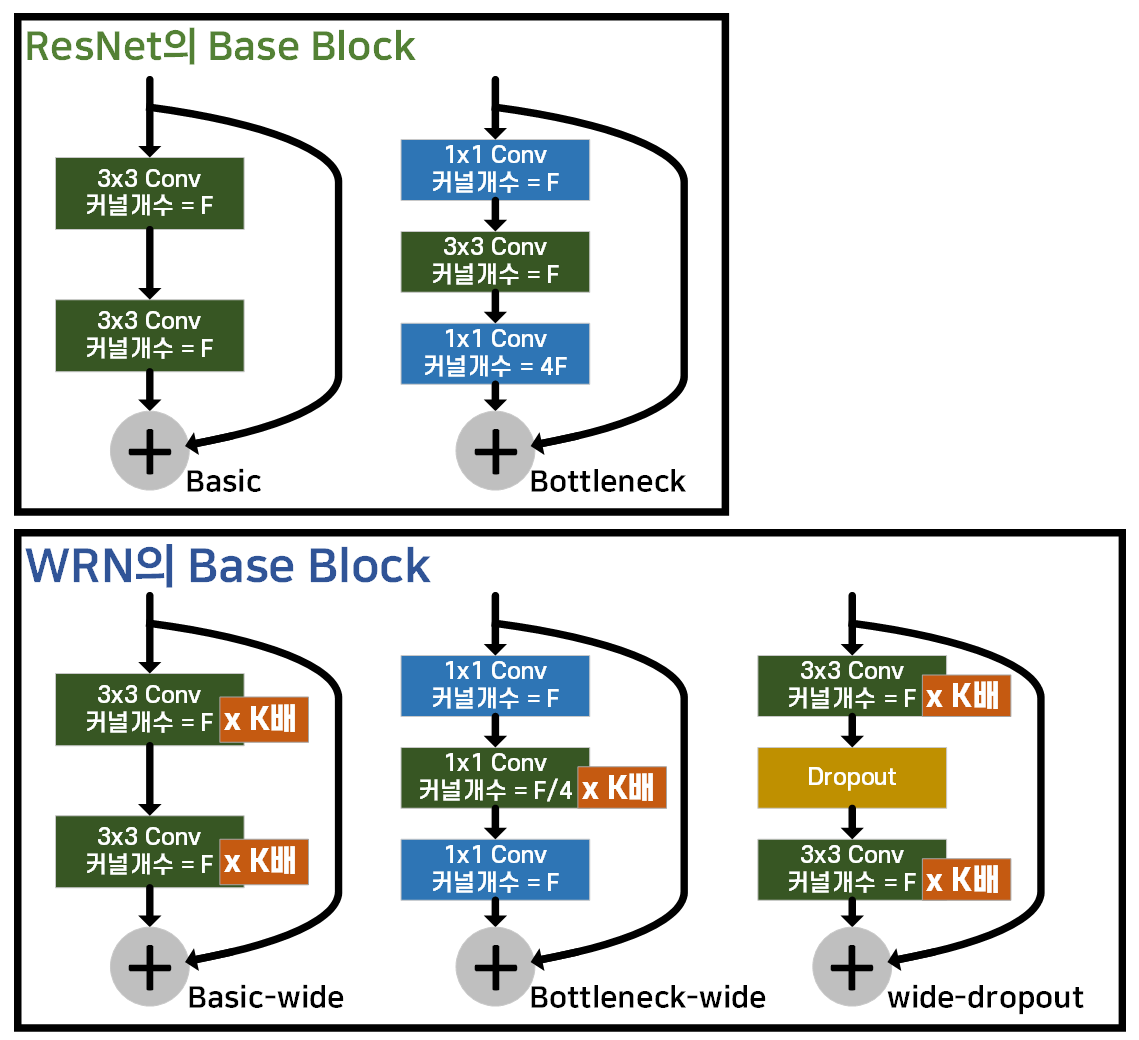 위 사진처럼 ResNet은 2종의 블록이 Base block로 사용된다면, WRN에서는 총 3종의 Base block이 기본으로 사용되고
위 사진처럼 ResNet은 2종의 블록이 Base block로 사용된다면, WRN에서는 총 3종의 Base block이 기본으로 사용되고
이 중 논문에서는 Base-wide, wide-droupout이 주로 언급되고, 실제 어플리케이션에서 사용되는
WRN 모델은 Bottleneck-wide블록을 기본 블록으로 사용한다.
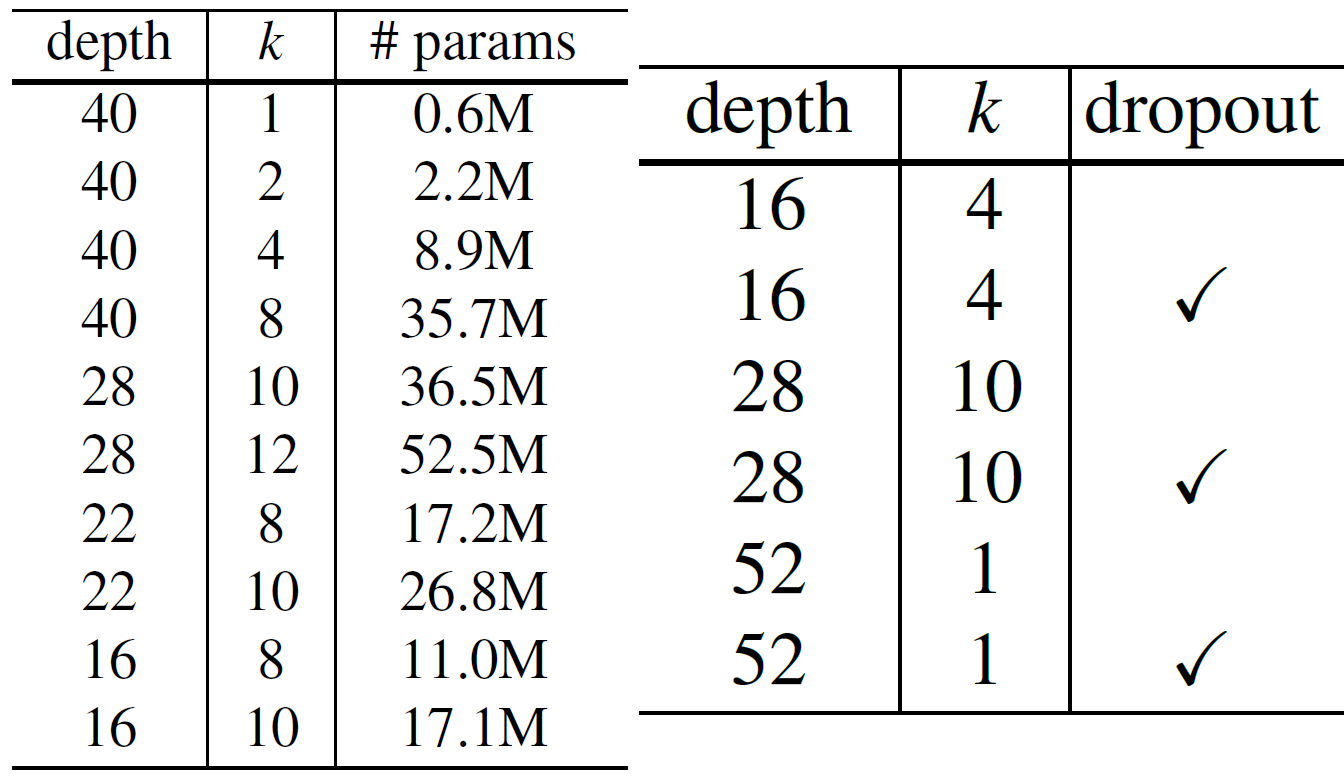
위 Baseblock를 바탕으로 WRN은 다양한 파생 net 종류를 설계하는데 이 중 WRN-28-10 네트워크는 아래의 그림처럼 ResNet-164 보다 더 좋은성능을 내는 것으로 확인할 수 있다.
여기서 WRN-28-10의 28은 해당 네트워크의 Depth을 의미하며, 28층의 적은 깊이로 구성된 WRN-28-10이 164층의 매우 깊은 네트워크에 속하는 ResNet-164보다 더 우수한 성능을 낸다.
이것이 논문의 기여라 볼 수 있다.
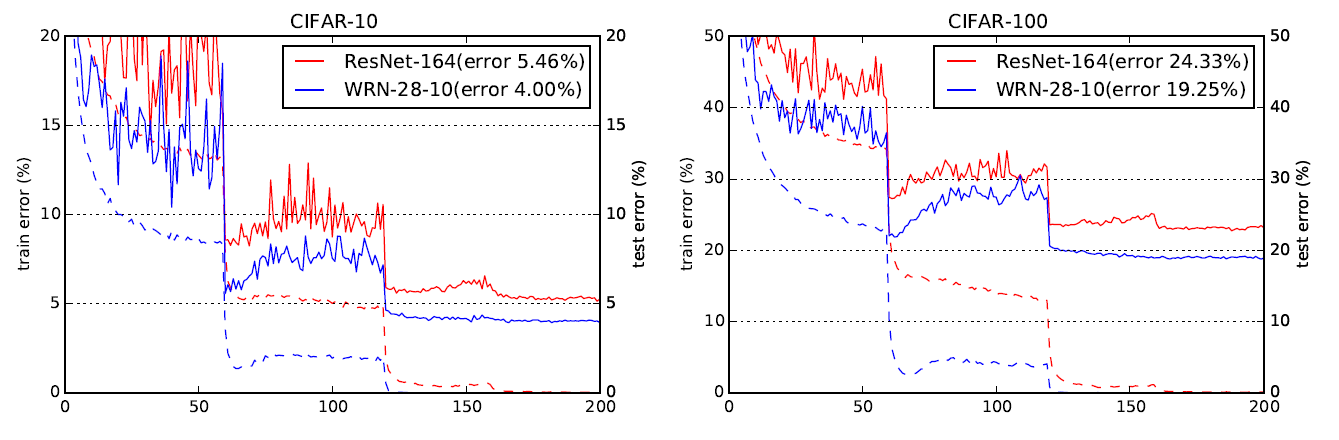
이후에 결과를 다시 한번 도출하겠지만
ResNet-101과 WRN-28-10을 구현하고 이를 Summary 했을 때
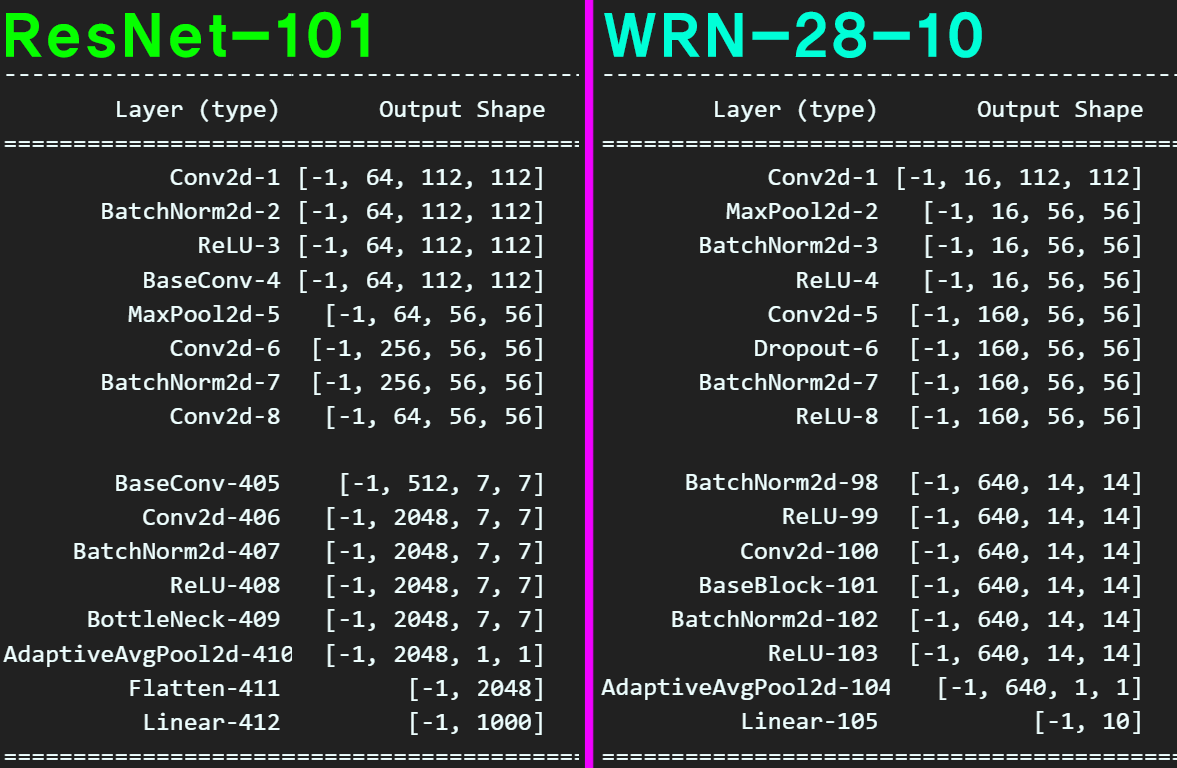 위 사진처럼 레이어의 깊이는 ResNet-101이 깊고 아래층 레이어의 Width 또한 WRN-28-10보다 넓게 설계되어 있다.
위 사진처럼 레이어의 깊이는 ResNet-101이 깊고 아래층 레이어의 Width 또한 WRN-28-10보다 넓게 설계되어 있다.
하지만 WRN-28-10는 위층 레이어 부터 Width이 160으로 넓어진 상태에서 시작하는데
이걸 그림으로 그린다면 ResNet-101은 피라미드 혹은 삼각형에 가까운 식으로 네트워크를 도식화할 수 있고,
WRN-28-10는 직사각형에 가까운 마름모꼴 형태로 네트워크를 표현할 수 있다.
즉, WRN 계열의 네트워크는 Depth와 Width로 연상할 수 있는 네트워크의 '면적' 개념이 삼각형에서 사각형으로 도형이 바뀜으로 인해, 등주 문제로 풀이할 때 더 최적에 가깝다고 볼 수 있다.
따라서 등주 문제에서 둘레길이(네트워크 자원)이고, 면적(네트워크 용량)으로 각각 치환해서 본다면 WRN-28-10이 더 최적화된 네트워크다... 라고 설명할 수 있을 것이다.
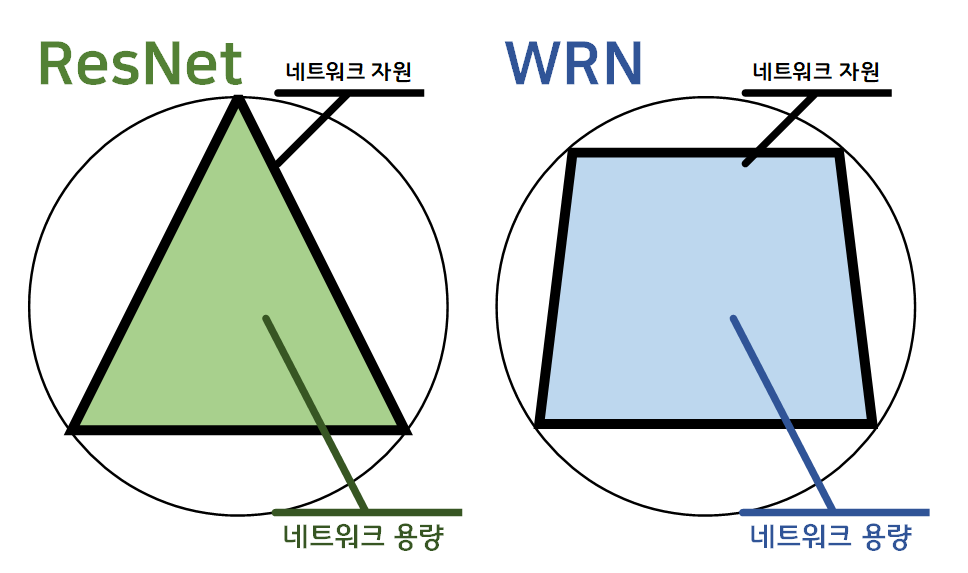
2. WRN 아키텍쳐

구조는 BN ReLU Conv 이 3개의 레이어가 하나로 묶여 동작하는 ConvBlock이 기본블록으로 활용되고
WRN Conv Base block은 skip connection에 해당하는
측면 우회로에 In channel과 out channel의 차원 차이가 날 때 이를 컨버팅 해주는 [1x1] Conv layer가 하나 붙어있는 구조이다.
이 WRN Conv Base block을 기본블록으로 하여 WRN Conv2, WRN Conv3, WRN Conv4는 각각 Width에 해당하는 커널 개수는 16, 32, 64의 K 배하여 늘어나고, 각 블럭은 N 회반복해 쌓이는 구조로 되어있다.
이를 코드로 구현하면 아래와 같다.
import torch
import torch.nn as nnclass BaseBlock(nn.Module):
def __init__(self, in_channels, out_channels,
dropout_rate=0.0, stride=1):
super(BaseBlock, self).__init__()
self.bn1 = nn.BatchNorm2d(in_channels)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, out_channels,
kernel_size=3, stride=stride,
padding=1, bias=False)
self.dropout_rate = dropout_rate
self.dropout = nn.Dropout(p=dropout_rate)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(out_channels, out_channels,
kernel_size=3, stride=1,
padding=1, bias=False)
#차원매칭을 위한 숏컷레이어
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels,
kernel_size=1, stride=stride,
padding=0, bias=False)
)
def forward(self, x):
out = self.bn1(x)
out = self.relu1(out)
out = self.conv1(out)
if self.dropout_rate > 0:
out = self.dropout(out)
out = self.bn2(out)
out = self.relu2(out)
out = self.conv2(out)
out += self.shortcut(x)
return outclass WideResNet(nn.Module):
def __init__(self, depth, widen_factor, dropout_rate=0.3, num_classes=10):
super(WideResNet, self).__init__()
self.start_channels = 16 #반복블록의 첫 입력 채널
#depth 인자값이 논문에서 정의한 값이 맞는지 확인하는 용도
assert (depth - 4) % 6 == 0, 'Depth should be 6n+4'
N = (depth - 4) // 6 #각 블록별 반복 횟수(각 블록의 depth)
K = widen_factor #위 표에 나와있는 N, K 상수 구현하기
#K는 conv레이어에서 출력되는 필터의 개수를 정하는 계수
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1, bias=False)
self.layer2 = self._make_layer(16*K, N, dropout_rate, stride=1)
self.layer3 = self._make_layer(32*K, N, dropout_rate, stride=2)
self.layer4 = self._make_layer(64*K, N, dropout_rate, stride=2)
self.fcl = nn.Sequential(
nn.BatchNorm2d(64*K),
nn.ReLU(inplace=True),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(64*K, num_classes)
)
#layer2~4(conv2~4)에 해당하는 내부함수 설계
def _make_layer(self, out_channels, blocks, dropout_rate, stride):
layers = []
for i in range(blocks):
if i == 0:
layers.append(BaseBlock(self.start_channels, out_channels, dropout_rate, stride))
else:
layers.append(BaseBlock(out_channels, out_channels, dropout_rate, stride=1))
self.start_channels = out_channels
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.fcl(x)
return x위 코드대로 2개의 class를 설계한다면 아래의 코드로 쉽게
설계한 모델에 대한 검증이 가능할 것이다.
from torchsummary import summary #설계한 모델의 요약본 출력 모듈
debug_model = WideResNet(depth=28, widen_factor=10)
summary(debug_model, input_size=(3, 64, 64), device='cpu')이때 depth와 widen_factor은 각각 N, K와 관련된 계수이며,
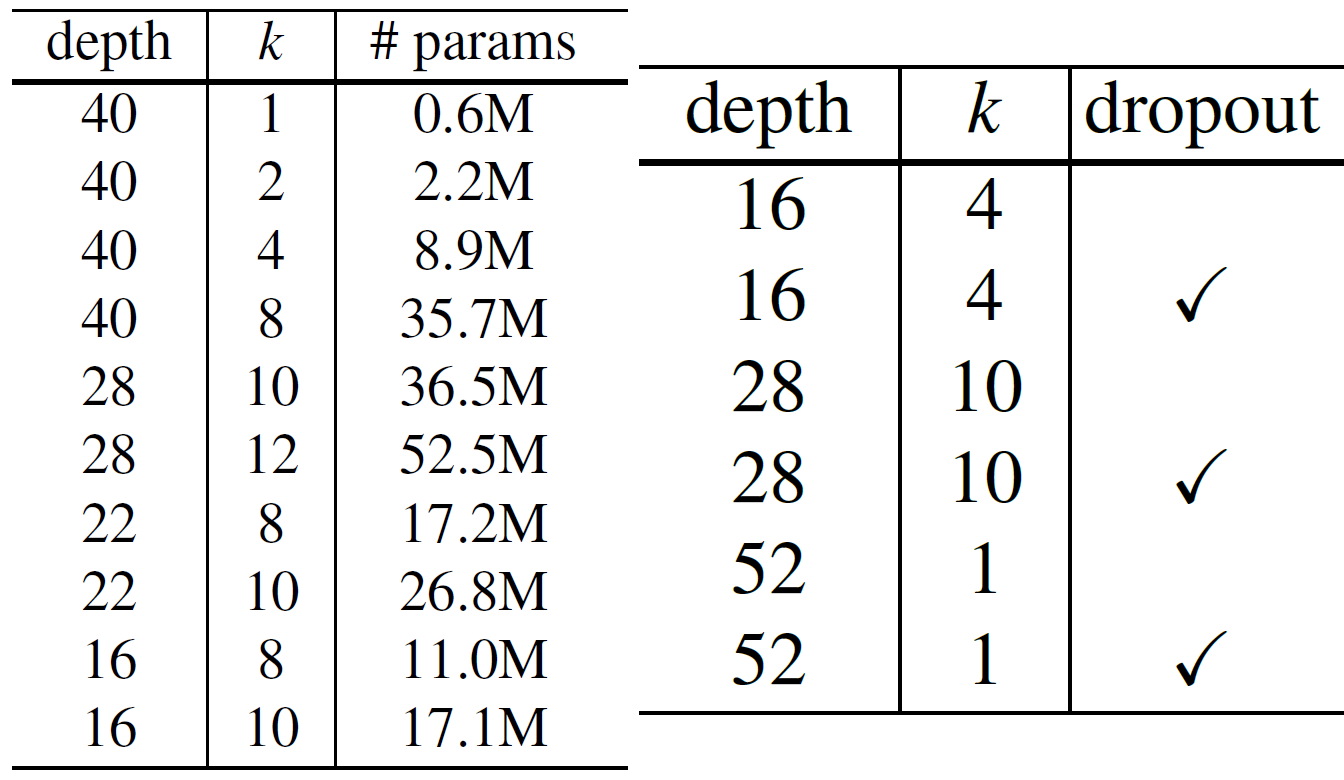
위 사진에 기입된 항목에 맞춰서 파라미터 계수를 조정하면
다양하게 WRN의 파생 네트워크를 생성할 수 있다.
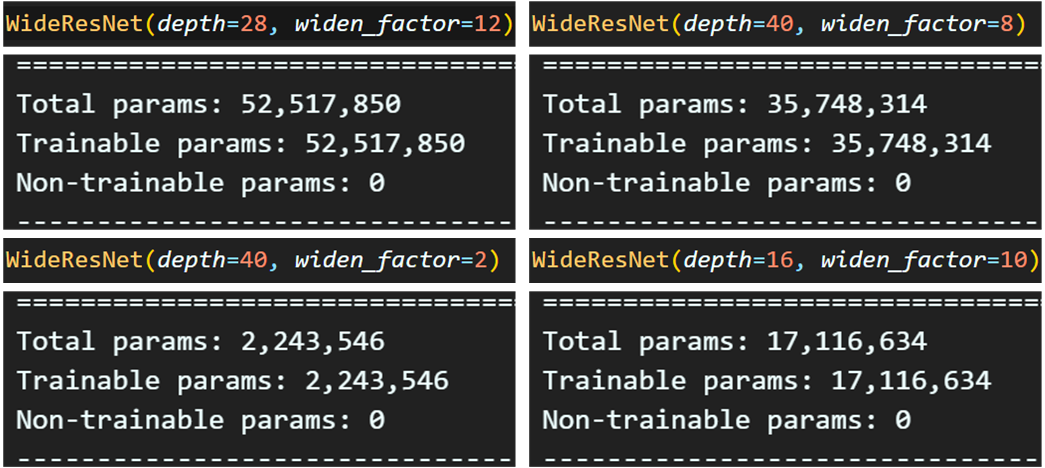 임의로 몇가지 네트워크를 생성해보고 네트워크의 파라미터 개수가 논문에서 기재된 파라미터 개수와 일치하는지 확인하도록 하자.
임의로 몇가지 네트워크를 생성해보고 네트워크의 파라미터 개수가 논문에서 기재된 파라미터 개수와 일치하는지 확인하도록 하자.
이번 포스트는 여기까지 수행하고 다음 포스트에서는
논문에서 제시한 WRN계열 논문 중 Pre-trained(사전학습) 된 모델을 불러와서 사용하는 방식에 대해 기술하려 한다.
