
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. 작업개요
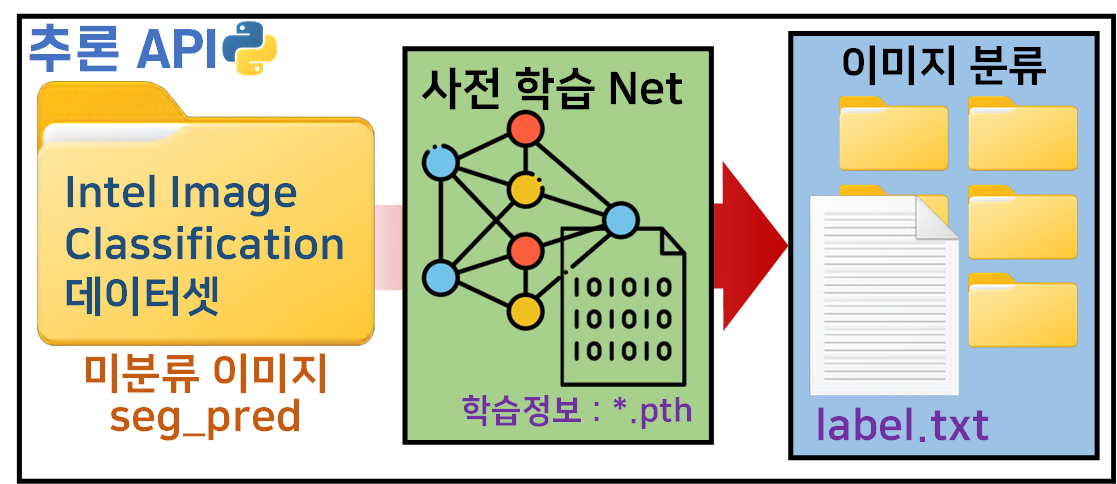 본 포스트에서 수행하고자 하는 Task는 위 이미지로 표현할 수 있다.
본 포스트에서 수행하고자 하는 Task는 위 이미지로 표현할 수 있다.
Intel Image Classification 데이터셋에 존재하는 미 분류 이미지 데이터셋 : seg_pred폴더 내 이미지를
이전 포스트 인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (2) Inception-v3,v4 훈련/검증에서 학습이 완료된 Inception_resenet_v2 모델을 불러와서
해당 모델로 seg_pred 데이터셋의 이미지에 대한 추론작업을 수행
수행 결과값에 따라 클래스 종류로 라벨링된 서브폴더에 해당 이미지 파일들을 배치하고
각각의 배치된 이미지파일에 대한 리스트를
label.txt로 추출하는 작업을 수행하고자 한다.
이때 이 label.txt는
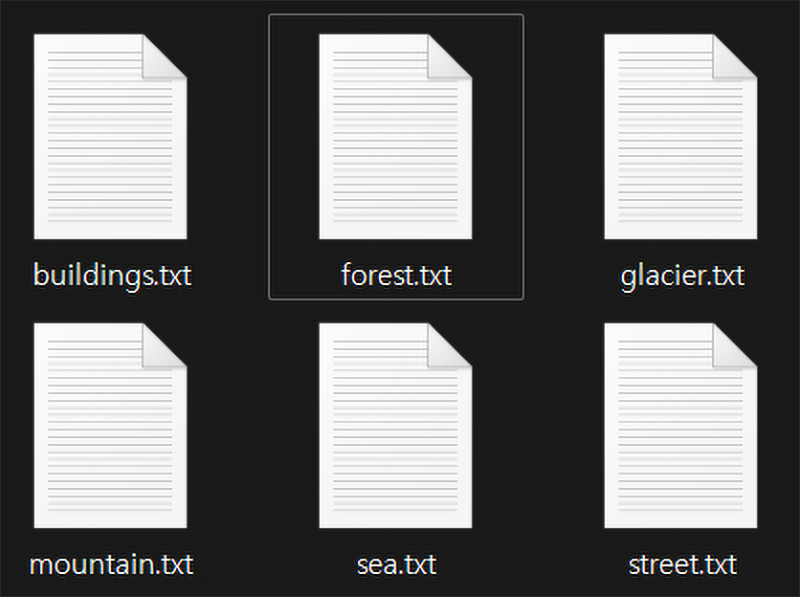 위 사진처럼 각 클래스명으로 생성된 서브 txt파일을 생성하는 것이
위 사진처럼 각 클래스명으로 생성된 서브 txt파일을 생성하는 것이
이 포스트의 목표라 볼 수 있다.
2. Inception_resenet_v2.py
먼저 첫번째로 수행할 항목은 학습이 완료된
모델에 대한 클래스를 저장하여 이를 *.py파일로 생성한다.
이후 API 프로그램에서 해당 파일을 import하는 것이 목표다.
해당 클래스 파일에 대한 코드는 아래와 같다.
모델 설계 부분은
인공지능 고급(시각) 강의 복습 - 20. 주요 CNN알고리즘 구현 : (1) Inception-v3,v4 모델포스트에 기재한
모델 클래스 구현 코드를 그대로 긁어온 것이다.
여기서 아래 debug용 함수 및 main구문을추가해주자
import torch
import torch.nn as nn
from torch.autograd import Variable
class Inception_v4(nn.Module): ...
class Inception_ResNet_V2(nn.Module): ...
def debug(model_name):
input = torch.rand(1, 3, 299, 299)
if model_name == "Inception_v4":
# Inception_v4 모델의 테스트 정보 출력
model_v4 = Inception_v4(in_channels=3, num_classes=1000)
print("Inception_v4 모델 구조: ")
print(model_v4)
#임의의 데이터 준비
input_v4 = Variable(input)
# forward
output_v4 = model_v4(input_v4)
# 출력 텐서 크기 확인
print("Inception_v4 모델 출력 크기:", output_v4.size())
elif model_name == "Inception_ResNet_V2":
# Inception_v4 모델의 테스트 정보 출력
model_resnet_v2 = Inception_ResNet_V2(in_channels=3, num_classes=1000)
print("Inception_ResNet_V2 모델 구조: ")
print(model_resnet_v2)
#임의의 데이터 준비
input_resnet_v2 = Variable(input)
# forward
output_resnet_v2 = model_resnet_v2(input_resnet_v2)
# 출력 텐서 크기 확인
print("Inception_v4 모델 출력 크기:", output_resnet_v2.size())
else:
print("모델이름이 유효하지 않음")
print("유효한 모델 이름: 'Inception_v4' or 'Inception_ResNet_V2'")
if __name__ == '__main__':
# 예시 호출
debug("Inception_v4")
debug("Inception_ResNet_V2")이 debug()함수를 구현해놔서
향후 다른이들에게 배포를 진행할 때
문제가 발생하는지 크로스체크를 할 수 있는 기능을 넣어서
예의를 준수하자.

3. API 설정
API의 생성은
설계한 *.py파일 및 학습이 완료된
파라미터 정보인 *.pth파일을 로드해야한다.
import torch
from incpetion_resnet_v4 import Inception_ResNet_V2#학습 완료된 모델 파라미터 경로 설정
MODEL_NAME = 'Inception_resenet_v2'
model_path = f'{MODEL_NAME}.pth'
print(model_path) #Inception_resenet_v2.pth 이케 떠야함이후 불러온 모델 및 파라미터 정보를 본격적으로 사용하기 전에
사전설정 데이터 및 GPU에 모델을 인스턴스하는 과정을 수행하자
# 기본정보 변수로 불러오기
INTEL_IMG_CLASSES = [
'buildings', 'forest', 'glacier', 'mountain', 'sea', 'street'
]
num_classes = len(INTEL_IMG_CLASSES)
intel_val = [[0.4302, 0.4575, 0.4538], [0.2355, 0.2345, 0.2429]]# GPU사용가능여부 확인
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 모델 인스턴스화
model = Inception_ResNet_V2(num_classes=num_classes)
# 모델을 GPU로 보내기
model.to(device)
# 불러온 모델에 학습된 파라미터를 로드하여 대입
model.load_state_dict(torch.load(model_path))
# 모델을 평가 모드로 전환
model.eval()여기까지 했으면 절반은 끝난 것이다.
이제 seg_pred폴더 내 이미지를 불러와서
추론 전용 Dataset인 InferenceDataset
을 생성하고
이를 전처리 후
데이터 로더로 변환하는 작업을 수행하자
#추론용 커스텀 데이터셋 만들기
from torch.utils.data import Dataset
from PIL import Image
import osclass InferenceDataset(Dataset):
def __init__(self, target_root, transform=None):
self.target_root = target_root #추론할 이미지가 담긴 폴더
self.transform = transform
#이미지가 담긴 폴더 내 파일 리스트 추출
self.img_files = [f for f in os.listdir(target_root) if f.endswith('.jpg')]
def __str__(self):
# img_mode메서드 함수가 동작 후에도 해당 리스트가 비어 있으면 실패로 간주
if not self.img_files:
return "오류가 났으니 확인하시오"
else:
return f"찾은 이미지 개수 : {len(self.img_files)}"
def __len__(self):
return len(self.img_files)
def __getitem__(self, idx):
img_name = self.img_files[idx]
#이미지 경로를 절대경로로 전환해야 한다.?
img_path = os.path.join(self.target_root, img_name)
image = Image.open(img_path).convert('RGB')
if self.transform:
image = self.transform(image)
return image, img_pathinfer_dataset = InferenceDataset(target_root='[seg_pred 폴더 경로]')
print(infer_dataset) #이미지를 7301개 찾아야 정상from torchvision.transforms import v2
from torch.utils.data import DataLoader
transformation = v2.Compose([
v2.Resize((299, 299)), #이미지 크기를 229x229로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=intel_val[0], std=intel_val[1]) #데이터셋 표준화
])
#추론 데이터를 전처리
infer_dataset.transform = transformation
infer_loader = DataLoader(infer_dataset, batch_size=128, shuffle=False)데이터로더까지 만들었으면
역시 예의가 바르게 데이터셋이 잘 만들어졌는지 확인하자
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
class_name = INTEL_IMG_CLASSES
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
if isinstance(labels, torch.Tensor):
print(f"첫 번째 이미지의 라벨: {labels[0].item()}, ", end='')
print(class_name[labels[0].item()])
print(f'라벨의 데이터타입 : {labels.dtype}')
else:
print(f"첫 번째 이미지의 파일명: {labels[0]}")
print(f'파일명의 데이터타입 : {type(labels)}')
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break
# infer_loader 정보 출력
print_dataloader_info(infer_loader, "추론 데이터 로더")추론 데이터 로더 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 299, 299])
첫 번째 이미지의 파일명: ./seg_pred\16213.jpg
파일명의 데이터타입 : <class 'tuple'>4. 추론작업 수행
추론 작업의 수행은
수행 결과값은 results라는 딕셔너리에
각 라벨별로 이미지의 경로 정보를 저장
하는 작업을 먼저 수행한다.
# 추론 및 결과 저장
results = {class_name: [] for class_name in INTEL_IMG_CLASSES}from tqdm import tqdm
#추론 과정은 평가코드랑 거의 같다.
with torch.no_grad():
for images, img_names in tqdm(infer_loader, desc="추론 진행 중"):
images = images.to(device)
outputs = model(images)
_, preds = torch.max(outputs, 1)
for img_name, pred in zip(img_names, preds):
class_name = INTEL_IMG_CLASSES[pred]
results[class_name].append(img_name)추론 진행 중: 100%|██████████| 58/58 [00:42<00:00, 1.36it/s]추론작업의 수행은 이미지가 꽤 있더라도
GPU상에서 추론을 진행하기에 그리 오랜시간이 걸리지는 않았다.
이제 딕셔너리result에 저장된 항목을 확인해보자
#각 클래스 별로 이미지가 몇장씩 배치됫는지 확인하자.
for class_name, img_names in results.items():
print(f"{class_name}: {len(img_names)}개")buildings: 1192개
forest: 1172개
glacier: 1337개
mountain: 1229개
sea: 1174개
street: 1197개대략 6개의 클래스에 맞춰서 이미지가 천여장 씩 배치된 것을 확인할 수 있다.
4.1 label.txt파일 만들기
위 딕셔너리로 저장된 결과값을 텍스트파일로 저장하자
#결과를 텍스트 파일로 저장
output_dir = "./infer_result"
#폴더가 이미 생성되어 있어도 유연하게 대처하기
os.makedirs(output_dir, exist_ok=True)
#txt파일을 만들어서 이미지 리스트를 저장하기
for class_name, img_paths in results.items():
output_file = os.path.join(output_dir, f'{class_name}.txt')
with open(output_file, 'w') as f:
for img_path in img_paths:
# 파일경로 + 확장자 제거한 [파일이름]만 저장하기
file_name = os.path.splitext(os.path.basename(img_path))[0]
f.write(f"{file_name}\n")
print("추론 및 결과 저장 완료!")위 코드를 수행하면
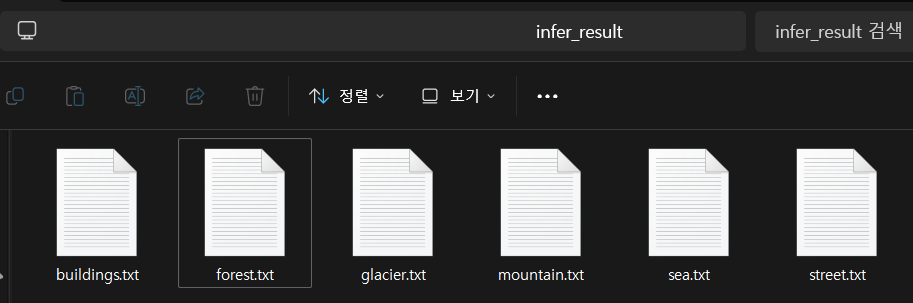 이렇게 텍스트파일 6개가 생성될 것이다.
이렇게 텍스트파일 6개가 생성될 것이다.
4.2 이미지 서브폴더 만들기
txt_dir = "./infer_result" #라벨 텍스트 파일이 저장된 폴더
#라벨링이 되지 않은 원본 이미지가 저장되어 있는 폴더
origin_dir = "[./seg_pred]폴더 경로"
#txt파일에 맞춰 라벨링을 완료한 이미지들이 저장될 폴다
classificated_dir = './label_result'3개의 폴더 경로를 정의한 뒤
import os
import shutil
# 텍스트 파일을 읽어 서브폴더를 생성하고, 이미지를 복사하는 함수
def labeling_func(txt_dir, origin_dir, classificated_dir):
if not os.path.exists(classificated_dir):
os.makedirs(classificated_dir, exist_ok=True)
for txt_file in os.listdir(txt_dir):
if txt_file.endswith('.txt'):
class_name = os.path.splitext(txt_file)[0]
class_dir = os.path.join(classificated_dir, class_name)
if not os.path.exists(class_dir):
os.makedirs(class_dir, exist_ok=True)
txt_file_path = os.path.join(txt_dir, txt_file)
with open(txt_file_path, 'r') as f:
for line in f:
img_name = line.strip() + '.jpg' # 파일명에 확장자 추가
img_path = os.path.join(origin_dir, img_name)
if os.path.exists(img_path):
shutil.copy(img_path, class_dir)
else:
print(f"이미지 파일을 찾을 수 없습니다: {img_path}")이미지 파일을 각각의 서브폴더에 배치하는 코드를 작성한다.
labeling_func(txt_dir, origin_dir, classificated_dir)
print("이미지 정리 및 복사 완료!")위 과정을 수행하면
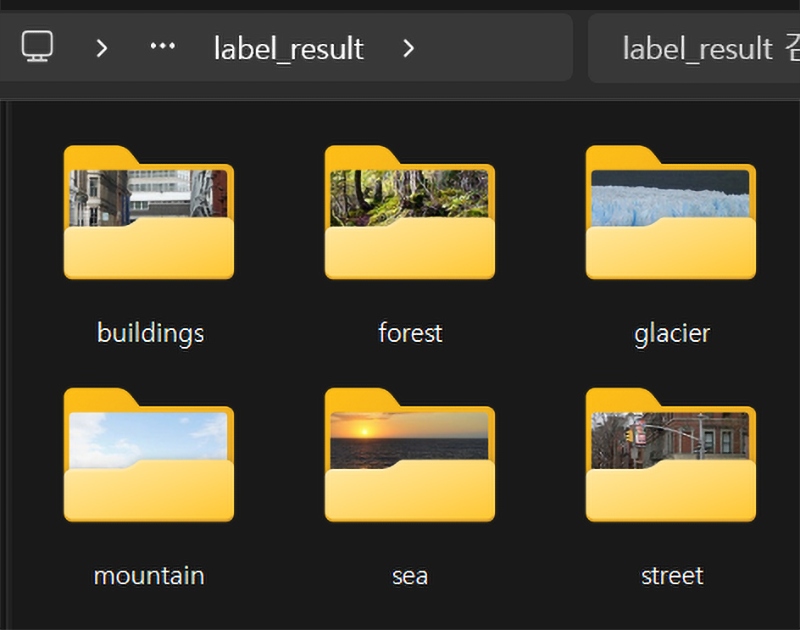 이런식으로 총 6개의 폴더가 생성되고
이런식으로 총 6개의 폴더가 생성되고
이미지 파일이 배치될 것이다.
5. 인간지능 검증

여기서 끝내면 역시 격식을 차리지 않은 것이다.
분류된 이미지에 대해서 마지막으로 직접 사람이
잘 분류되었는지 안되었는지 확인을 해야한다.
필자가 일일이 7천장의 분류된 이미지를 검토한 결과
나름 필자의 주관이 100%개입하여
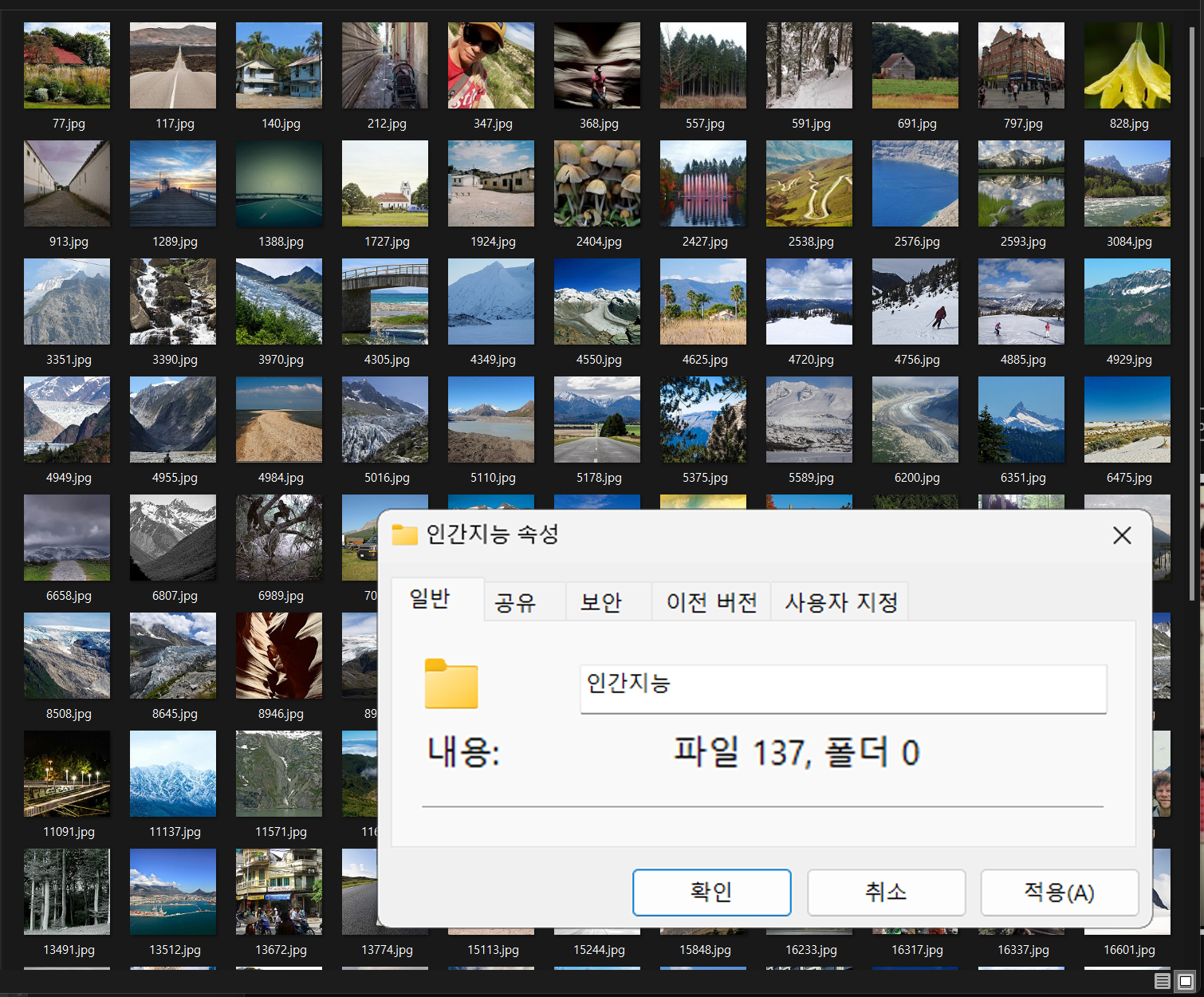 분류가 잘못되었다고 판단되는 137장의 이미지를 추려낼 수 있었다.
분류가 잘못되었다고 판단되는 137장의 이미지를 추려낼 수 있었다.
음.. 이 인간지능 검증은... 사람이 할짓이 아니었다
참고로 분류가 완료된 라벨링 데이터는
https://github.com/tbvjvsladla/incpetion_v4_intel_Image_Classification_infer_result
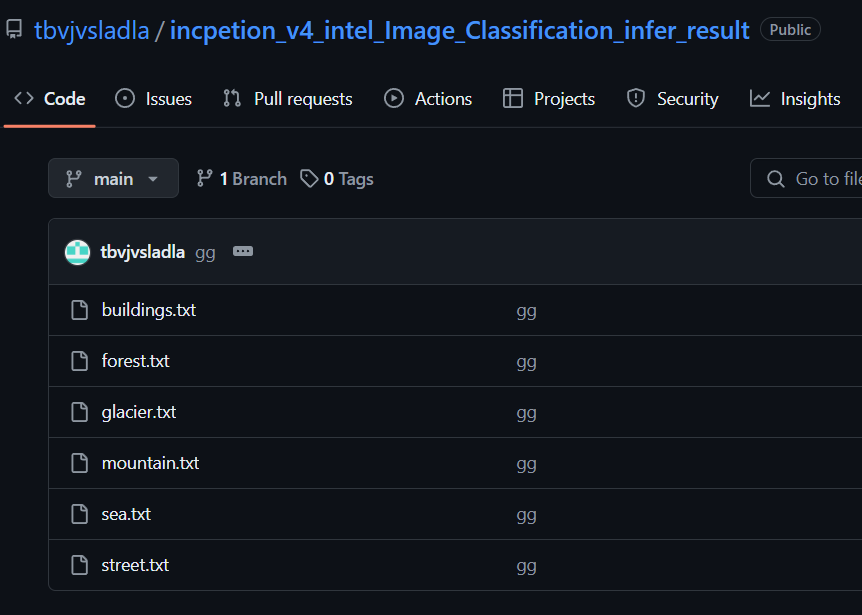 에 업로드하였다.
에 업로드하였다.
이게... 남들이 Intel Image Classification의 seg_pred이미지를 어떻게 분류했는지 결과를 알아보려고 이곳저곳 서치를 해봣는데
필자는 결과값을 찾질 못햇다...
음.. 뭐 다들 코드는 붙여넣긴 했는데
딸깍 딸각 하는 식으로 결과물이 어케 나왔는지
쉽게 한줄 요약 좀 해줫으면 좋겠다...

아무튼 필자는 6개의 라벨 결과물(txt)파일로 추론API의 결과값을 첨부했다.
정확도는... 대략 150장 정도는 잘못 분류되는 모델이니
추가적인 개선은 필요하다
