
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. Convolution Layer
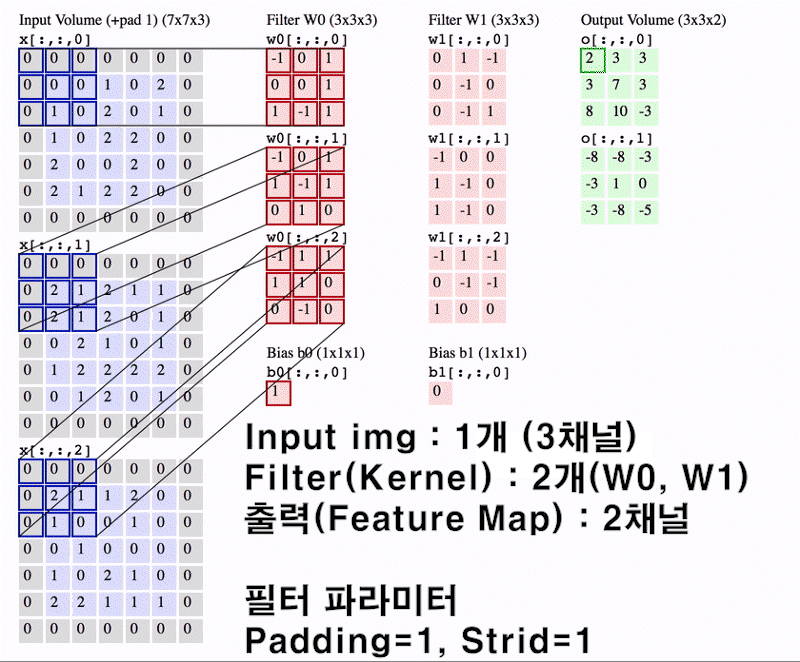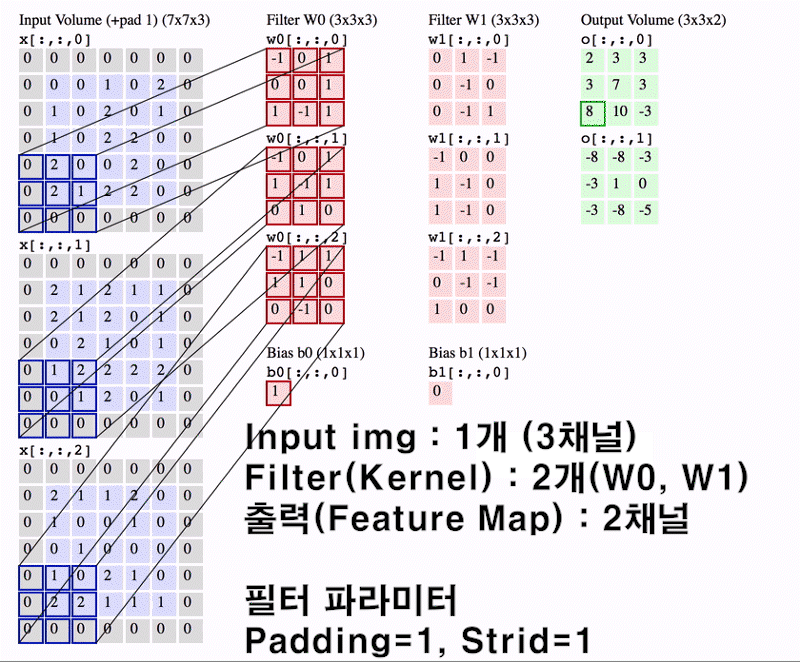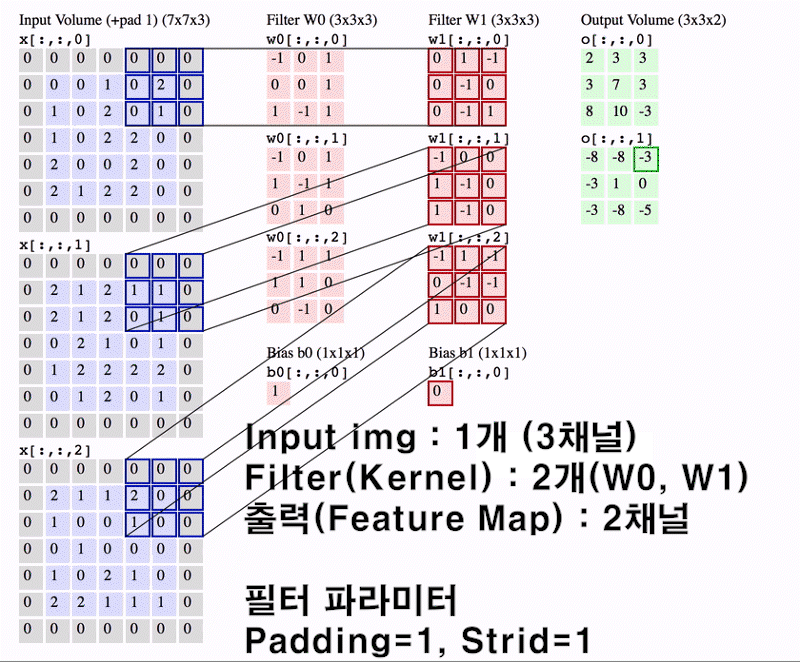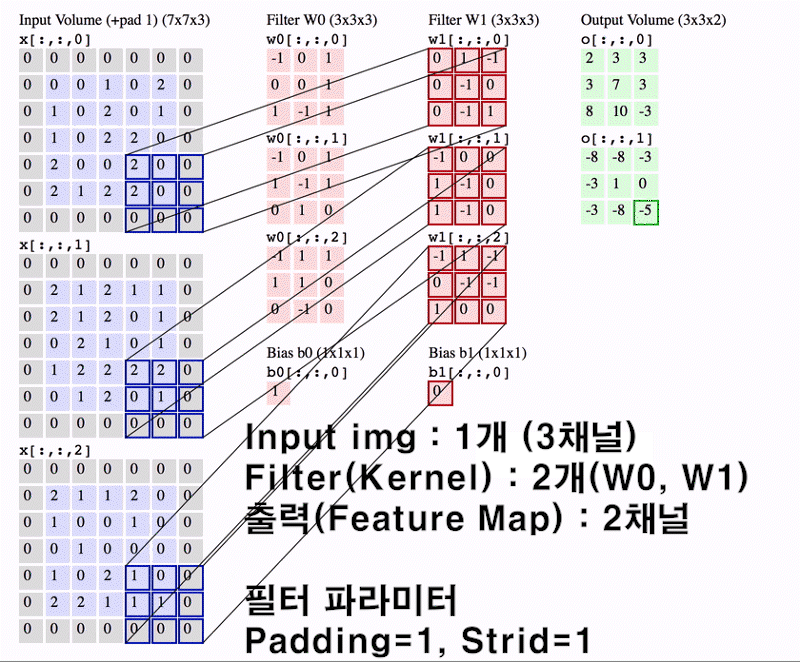 앞서 설명한
앞서 설명한
챕터 5 합성곱 연산 개요 ~
8 멀티채널 Conv와 im2col까지가 이
Convolution Layer의 진행 과정에 대한 설명이었다.
이를 코드로 구현하는 과정에 따른 개념은 설명했으니
PyTorch에서는 해당 기능을 어떻게 구현했는지 파악하면 된다.
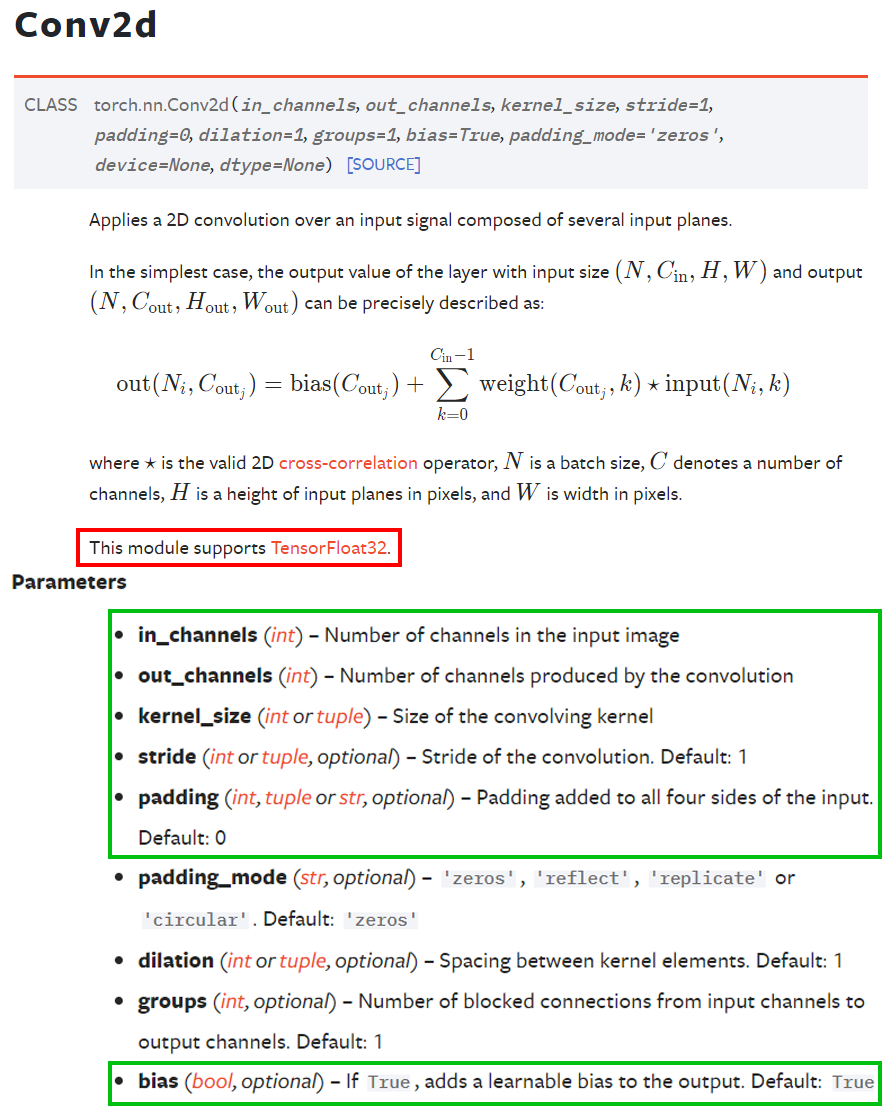 PyTorch라이브러리에서는
PyTorch라이브러리에서는 torch.nn.Conv2d클래스를 통해 지원하고 있으며,
필수 입력 인자값 : in_channels, out_channels, kernel_size
기본값이 정해진 인자값 : stride, padding, bias
총 6가지 인자값이 필요하다.
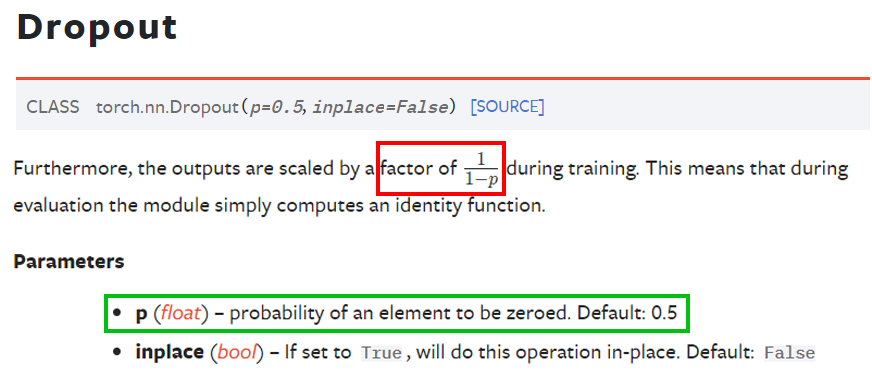
1.1 Conv레이어 모델 개선 방법 - Dropout
Conv의 연산과정에 대한 설명이 input_img의 매트릭스와 kernel 매트릭스의 어쩌구 저쩌구 이지만
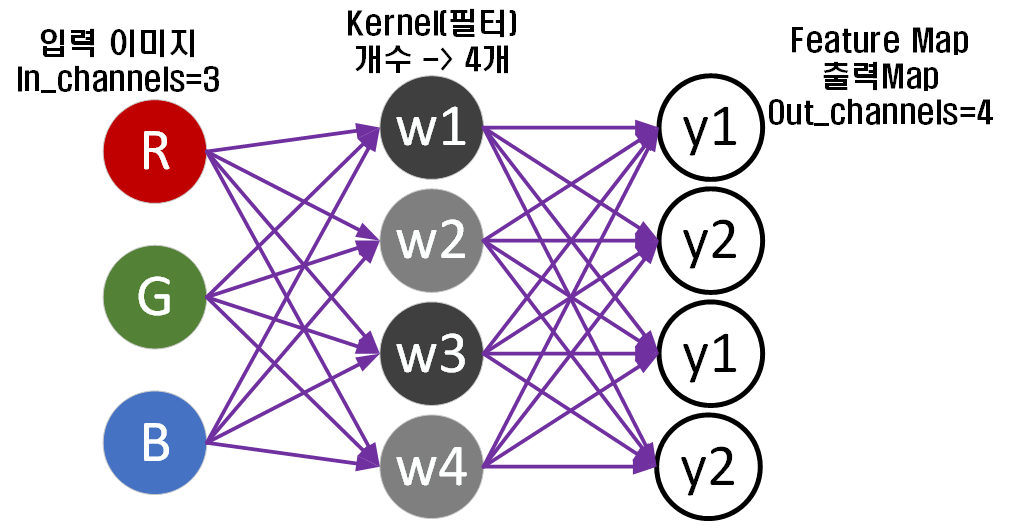 기본적으로 위 이미지처럼 Neural Net 이미지로 표현할 수 있다.
기본적으로 위 이미지처럼 Neural Net 이미지로 표현할 수 있다.
그리고 이런 Neural Net는 모두 '과대적합', w와 b가 학습 데이터에 지나치게 최적화 되서 성능이 떨어지는 현상이 발생한다.
지금 이미지에서는 'b'는 그림에 포함하지 않았으니
커널인 [w1, w2, w3, w4]이 지나치게 학습되어 있다.
라고 볼 수 있다.
이때 과적합 방지 방법론으로 L1, L2 정규화 방법론이 도입되었으나, 지금은 Dropout 기법으로 문제를 해결하고 있다.
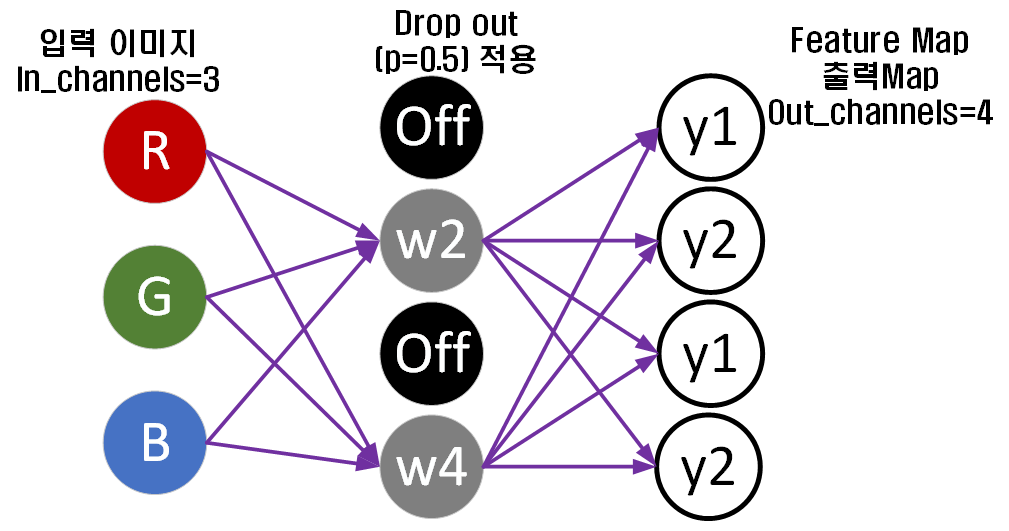 지금 위 이미지처럼 Kernel을 4개 적용하던 것에 Dropout를 적용하면 사진처럼 2개의 Kernel에 연결된 연결망을 잘라내는 것이다.
지금 위 이미지처럼 Kernel을 4개 적용하던 것에 Dropout를 적용하면 사진처럼 2개의 Kernel에 연결된 연결망을 잘라내는 것이다.
이 연결망이 잘리는 kernel Node의 선택은 무작위로 이뤄지며, 코드로는 torth.nn.Dropout클래스를 통해 지원된다.
1.2 모델 개선 방법 - Batch Normalization
다음으로 소개할 내용은 Batch Normalization으로
그림으로 표현하면 아래와 같다.
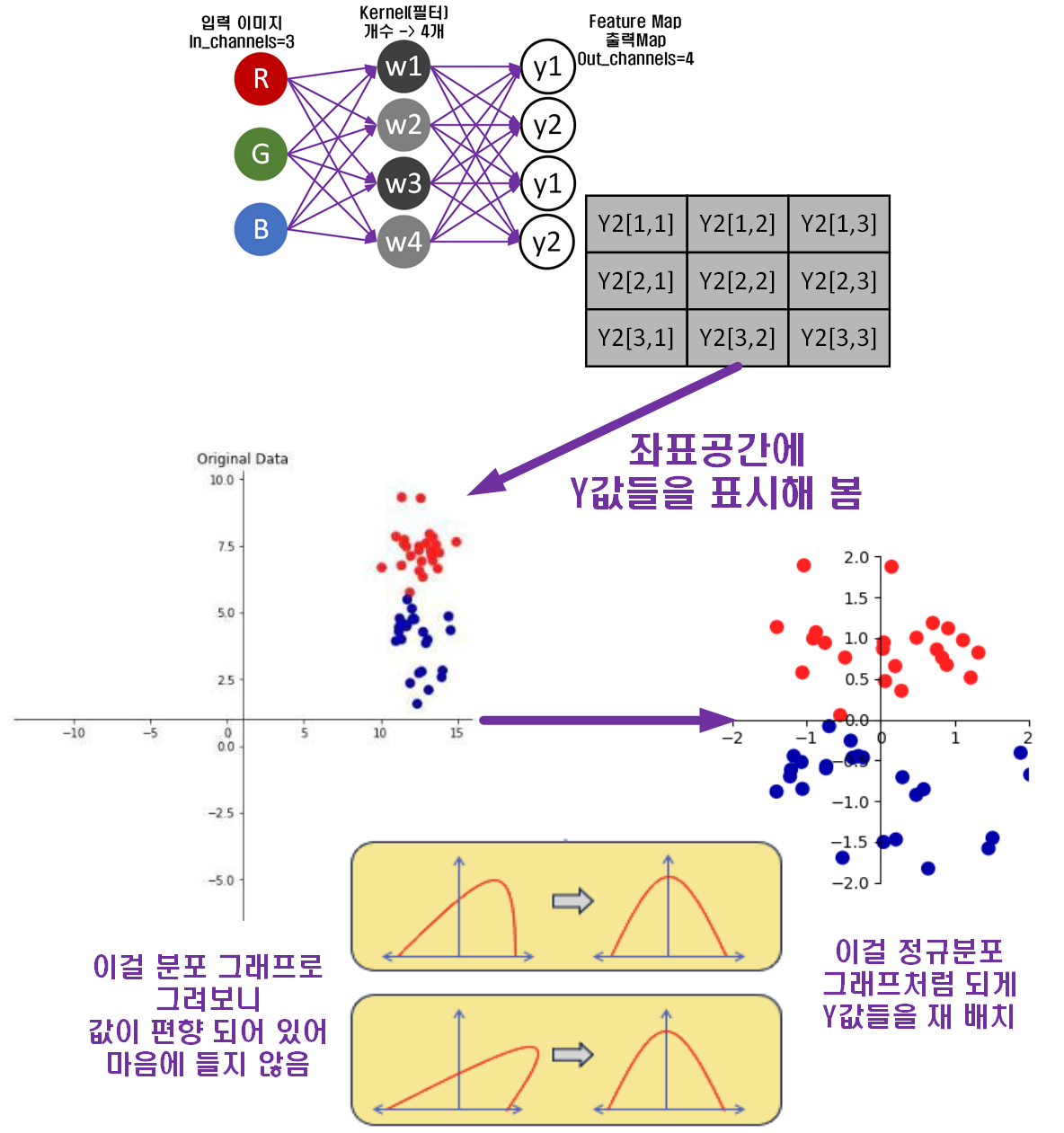 딱 이느낌으로 편향되어 있던 값을
딱 이느낌으로 편향되어 있던 값을 평균은 0, 분산은 1의
정규분포로 정규화하는 것이라 보면 된다.
이걸 수식으로 표현하면 위 수식과 같은데 여기서 는 'bias'에 해당한다.
참고로 Convolution Layer의 기초가 되는 퍼셉트론을 수식화 하면
으로 표현할 수 있는데 여기서 도 'bias'에 속한다.
 따라서 나중에는 위 사진처럼
따라서 나중에는 위 사진처럼 Conv BN AF 순으로 연결된 Conv_block을 당연하다는 듯이 사용하게 될 텐데
이때 Conv의 인자값인 'bias'는 False(0)으로 설정한다.
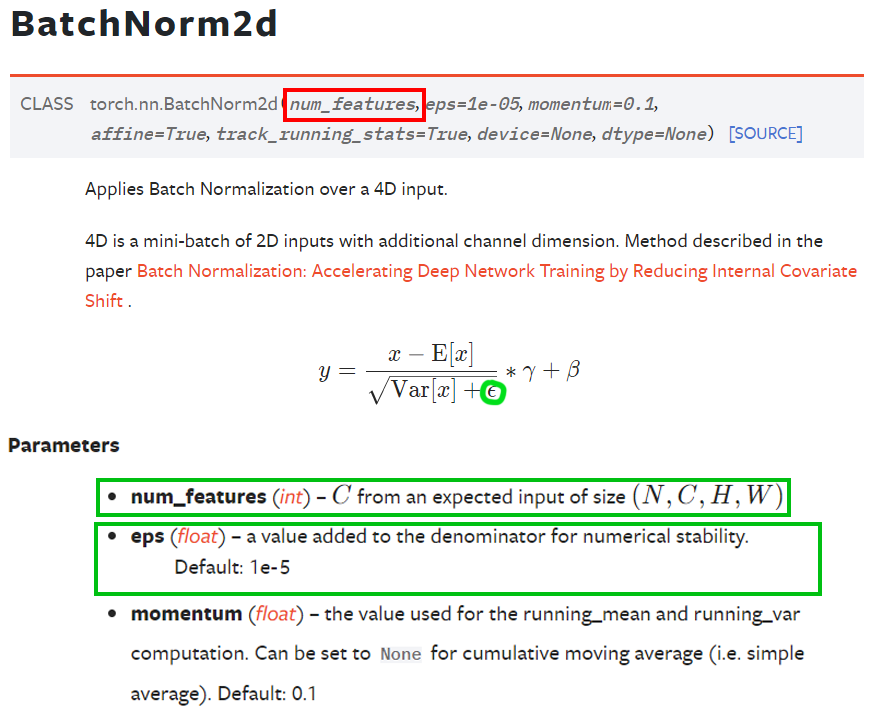
PyTorch라이브러리는 torch.nn.BatchNorm2d클래스로 기능을 지원하고 있으며, num_feature는 앞에 연결된
Conv의 Output_channels을 넣어주면 되고, 또 다른 인자값으로 eps이 있는데
이거는 Batch normalization연산을 수행하다 보면 분모가 0이 되서 NaN이 되는 경우가 있다. 이걸 방지하기 위한 인자값인데 기본값으로 가 적용되어 있으니 딱히 신경 쓸 필요는 없다.
2. Conv기반 모델 만들기
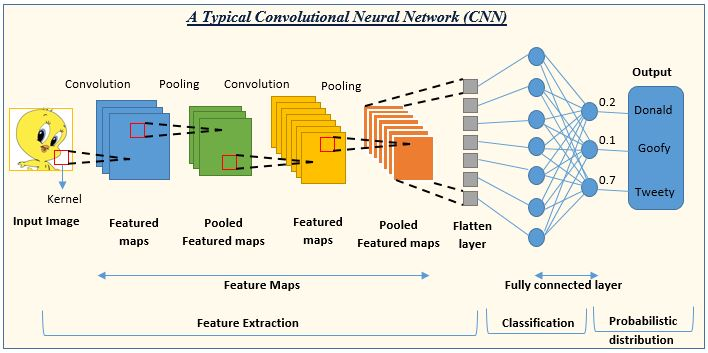 이번에는 위 사진에서 표현되는 일반적인 Convolution 계열의 Neural Network에 대한 코드구현을 해보고자 한다.
이번에는 위 사진에서 표현되는 일반적인 Convolution 계열의 Neural Network에 대한 코드구현을 해보고자 한다.
2.1 데이터셋 불러오기
Convolution Neural Network의 input Image에 해당하는 데이터셋은 무수히 많은 종이 있지만 대표적으로 자주 사용되며, PyTorch라이브러리에서 제공하는 이미지 데이터셋이 존재한다.
https://pytorch.org/vision/stable/datasets.html
 이는 PyTorch의 여러 서브 패키지중 하나인
이는 PyTorch의 여러 서브 패키지중 하나인 torchvision패키지를 통해 데이터셋을 가져올 수 있으며, 해당 패키지가 제공하는 데이터셋은
Image classification : 이미지 분류용 딥러닝 모델 학습에 필요한 데이터셋
Image detection or segmentation : 객체 검출 및 Segmentation 작업용 딥러닝 모델 학습에 필요한 데이터셋
외 여러 작업에 필요한 딥러닝 모델을 개발했으면, 이 모델을 학습시키기 위한 예제 데이터셋을 제공한다.
이 중 Image classification - CIFAR10 데이터셋을 다운받아 이를 학습용 데이터셋으로 사용해보고자 한다.

CIFAR10데이터셋은 6만장의 컬러 이미지가 포함되어 있으며, {airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck} 총 10종의 클래스와 각 클래스 별로 6천장씩 이미지가 할당되어 있다.
그리고 훈련용 데이터는 총 5만장, 검증(test)용 데이터는 1만장으로 나뉘어져 있다.
이 데이터셋을 PyTorch라이브러리를 통해 다운받으려면
import torchvision
trainset = torchvision.datasets.CIFAR10(root='[폴더경로]',
train=True,
download=True)
testset = torchvision.datasets.CIFAR10(root='[폴더경로]',
train=False,
download=True)이렇게 코드를 작성하면 된다.
이때 필요한 인자값은 root, 옵션이지만 쳐주는게 좋은 인자값은 train, download
그리고 나중에라도 꼭 설정해야 할 인자값은 transform이다.
2.1.1 root
root 인자값에는 폴더 경로를 넣어야 하는데 여기서 상대경로 라는 개념을 알고 넘어가야 좀 편하다.
 첫번째로 내가
첫번째로 내가 어쩌구저쩌구/어쩌구/저쩌구/src 라는 경로의
src라는 폴더에서 현재 실행중인.py파일을 실행한다 가정해보자
여기서 src 폴더에 있는 현재 실행중인.py는 이 src의 폴더명을 사용하지 않고 그냥 .으로 인식한다.
즉,
dot(.)은 현재 디렉토리가 어디에 위치하던 현재 실행중인.py이 위치한 디렉토리의 경로를 뜻하며, 이때, 이 현재 실행중인.py을 담고 있는 src의 폴더명은 dot(.)으로 치환된다 보면 된다.
그리고 dot 두 개(..)는 현재 디렉토리의 상위 디렉토리를 의미한다.
여기서 알 수 있는 사실은
작업 폴더의 위()로 향하는 폴더명은 모두 dot 두 개(..)으로 치환되며, 아래로 향할 때만 폴더명을 기재한다 라고 이해하면 된다.
예시를 만들어보자
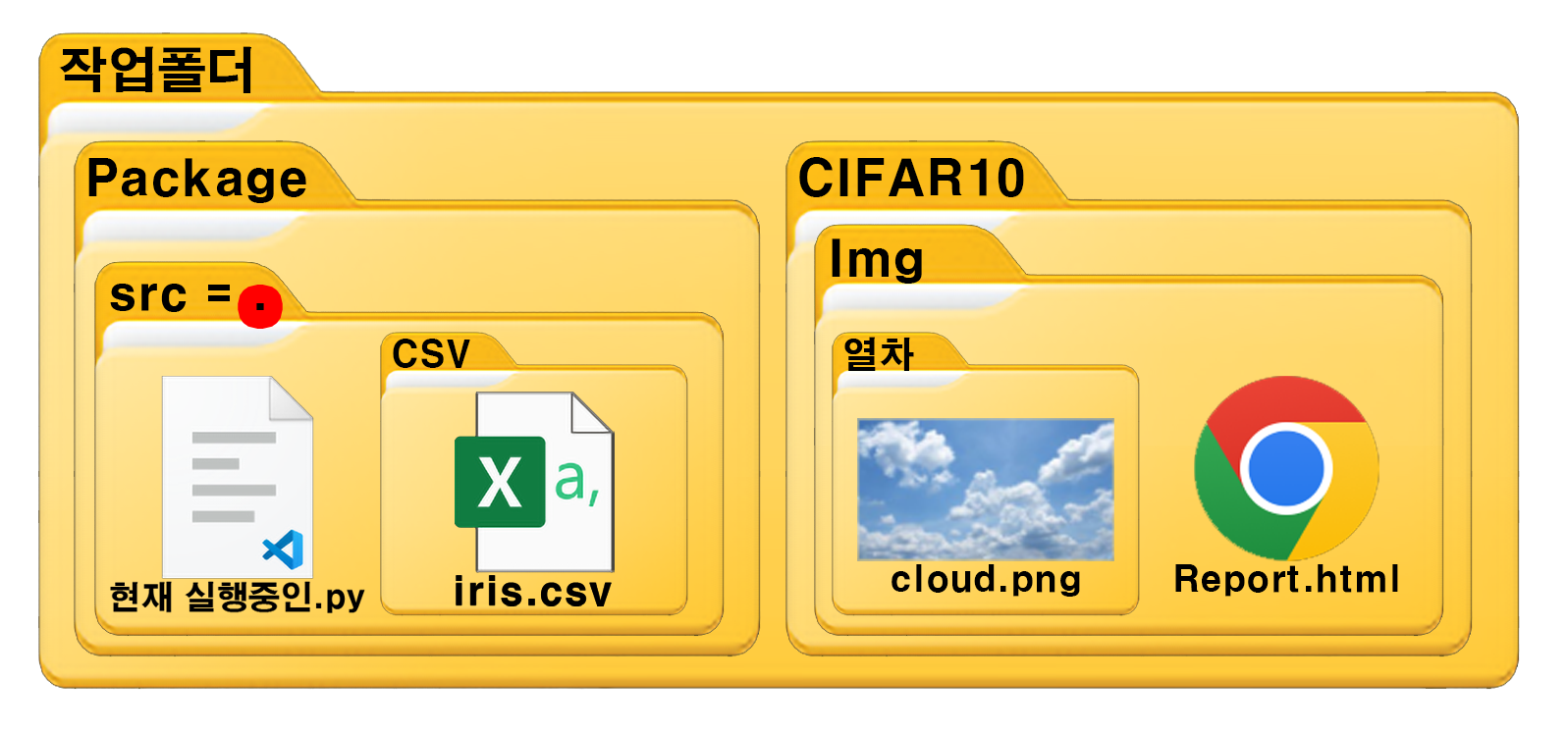 [C:\작업폴더]가 있고, 폴더의 구성은 사진과 같다.
[C:\작업폴더]가 있고, 폴더의 구성은 사진과 같다.
현재 실행중인.py파일은 src 폴더에 있으나 해당 폴더는 dot(.)으로 치환된다.
여기서 src폴더의 하위 경로인 CSV 그리고 그 폴더 안에 있는 iris.csv에 접근한다면
아래의 코드를 작성하면 된다.
csv_path = './csv/iris.csv'그리고 위()로 향하는 폴더명은 모두 dot 두 개(..)로 치환된다 했으니
작업폴더에 위치하고 싶다면 아래와 같이 코드를 작성하면 된다.
workspace_path = './../../'이제 여기서 CIFAR10, Img로 내려가서 Report.html파일을 읽고 싶다면 아래의 코드를 작성하면 된다.
report_path = './../../CIFAR10/Img/Report.html'마지막으로 열차 폴더의 cloud.png파일에 접근하고 싶다면 아래의 코드를 작성하자
cloud_path = './../../CIFAR10/Img/열차/cloud.png이런 식으로 상대경로 개념을 활용하여 root에 폴더 경로를 입력해주면 된다.
2.1.2 download
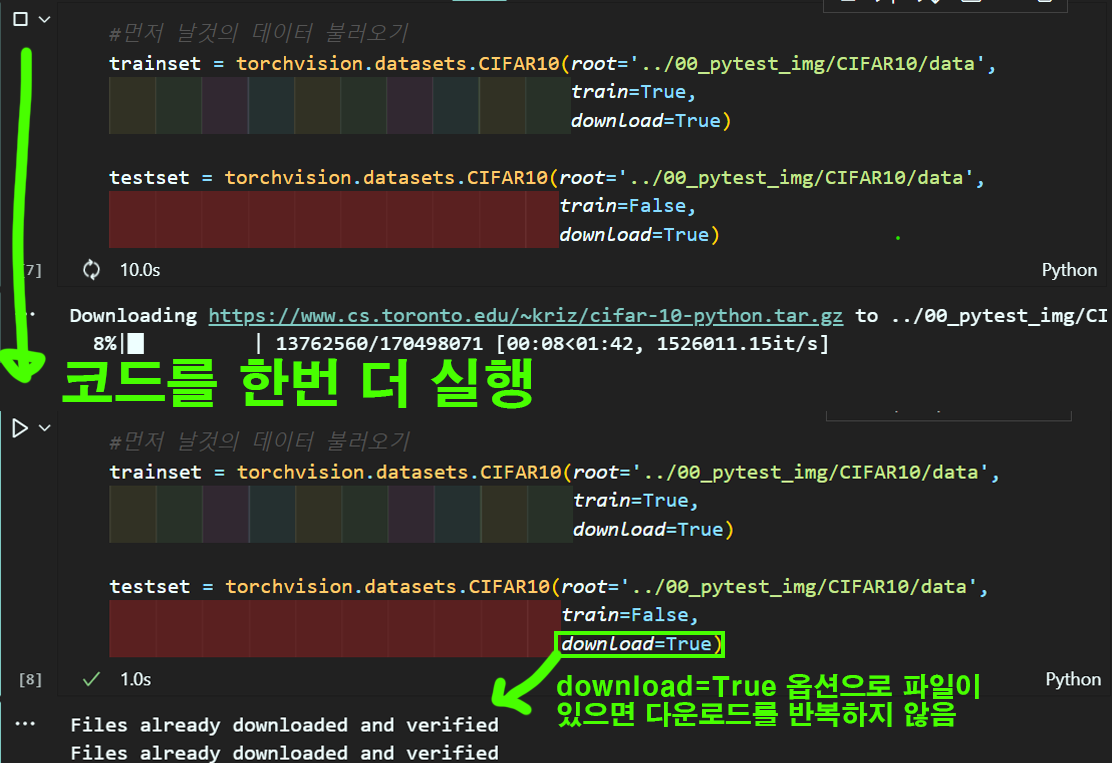 이 download 옵션은 파일을 다운로드 받을 때
이 download 옵션은 파일을 다운로드 받을 때
해당 파일이 존재
한다면 다운로드 과정을 건너 뛰라는 옵션이다.
최초로 코드를 작성하면 웹사이트에 접속하여 다운로드 과정을 수행하지만
다운로드를 완료 후 다시 코드를 실행시키면 이미 파일이 존재하기에 다운로드 과정을 건너뛴다.

아무튼 위 코드를 실행하면
cifar-10-python.tar.gz파일을 다운받고
해당 파일의 압축을 풀어서
cifar-10-batches-py폴더와 그 아래 파일들을 생성한다.
해당 폴더를 열어보면 접근할 수 없는 META파일만 생성되지만
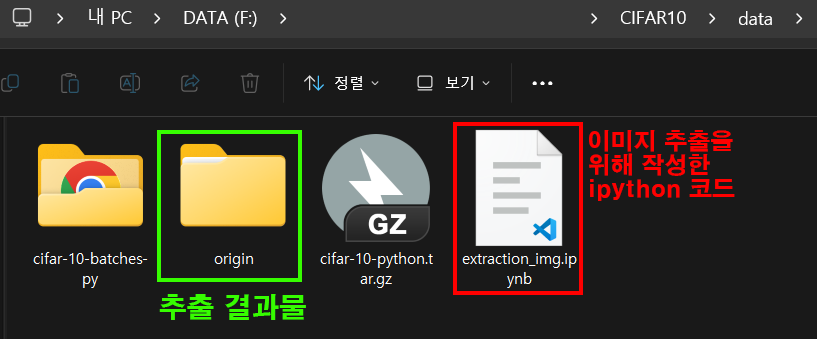 위 사진처럼 이미지 추출을 위한
위 사진처럼 이미지 추출을 위한 extraction_img.ipynb코드를 작성하고 origin이란 폴더명으로 이미지를 추출해 보겠다.
import os
import pickle
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
#CIFAR=10메타데이터 경로
data_path = "./cifar-10-batches-py"
# CIFAR-10 데이터셋의 파일 이름
train_files = [
"data_batch_1",
"data_batch_2",
"data_batch_3",
"data_batch_4",
"data_batch_5"
]
test_files = ["test_batch"]
# CIFAR-10 클래스명
class_names = [
"airplane", "automobile", "bird", "cat",
"deer", "dog", "frog", "horse", "ship", "truck"
]
# 저장할 디렉토리
train_dir = "./origin/cifar10_images/train"
test_dir = "./origin/cifar10_images/test"
os.makedirs(train_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
# 클래스명으로 디렉토리 생성
for class_name in class_names:
os.makedirs(os.path.join(train_dir, class_name), exist_ok=True)
os.makedirs(os.path.join(test_dir, class_name), exist_ok=True)
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def save_images_from_batch(batch_data, batch_labels, batch_index, output_dir):
for i in range(len(batch_data)):
img = batch_data[i]
label = batch_labels[i]
img = img.reshape(3, 32, 32).transpose(1, 2, 0)
img = Image.fromarray(img)
class_name = class_names[label]
img_dir = os.path.join(output_dir, class_name)
img.save(os.path.join(img_dir, f"batch{batch_index}_img{i}.png"))
for batch_index, batch_file in enumerate(train_files):
batch_path = os.path.join(data_path, batch_file)
batch = unpickle(batch_path)
batch_data = batch[b'data']
batch_labels = batch[b'labels']
save_images_from_batch(batch_data, batch_labels, batch_index, train_dir)
for batch_index, batch_file in enumerate(test_files):
batch_path = os.path.join(data_path, batch_file)
batch = unpickle(batch_path)
batch_data = batch[b'data']
batch_labels = batch[b'labels']
save_images_from_batch(batch_data, batch_labels, batch_index, test_dir)
print("Images extracted and saved successfully.")이 코드를 그대로 작성하여 실행시키면
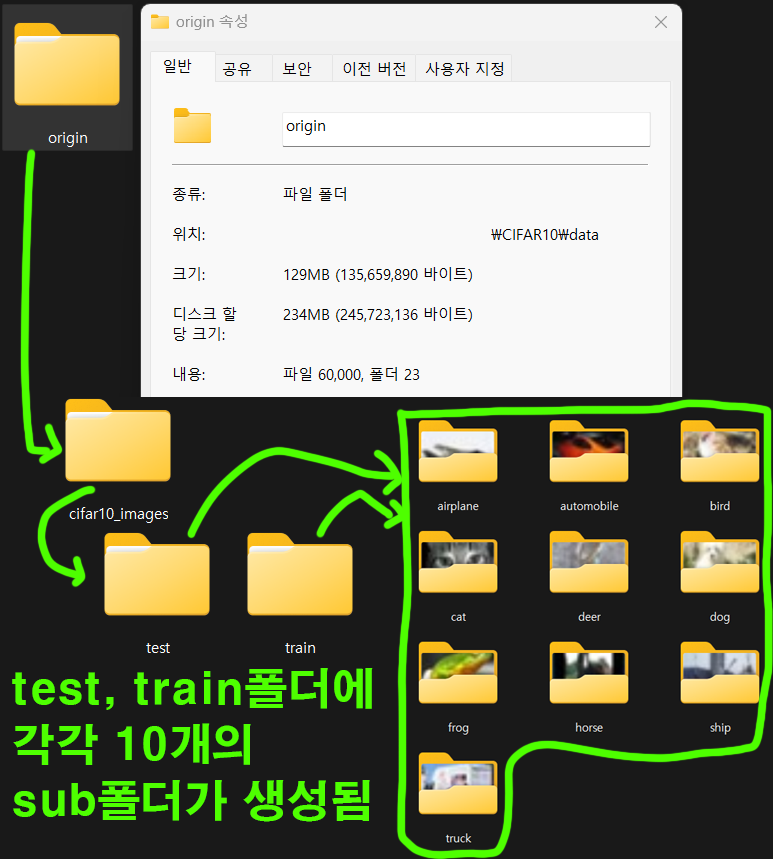 위 사진처럼 각 폴더별로 10개의 서브폴더가 생성되고 이미지 파일이 배치된다.
위 사진처럼 각 폴더별로 10개의 서브폴더가 생성되고 이미지 파일이 배치된다.
 참고로 배치된 이미지 파일은 [32,32] 픽셀의 매우 작은 이미지 파일이라서 사람이 보면 알아볼 수준의 이미지 이긴 하다..
참고로 배치된 이미지 파일은 [32,32] 픽셀의 매우 작은 이미지 파일이라서 사람이 보면 알아볼 수준의 이미지 이긴 하다..
2.2 데이터셋 전처리
위 2.1 데이터셋 불러오기 작업을 수행한 뒤에는 이제 데이터셋을 딥러닝 모델에 학습 가능한 형태로 자료형 변환을 해줘야 한다.
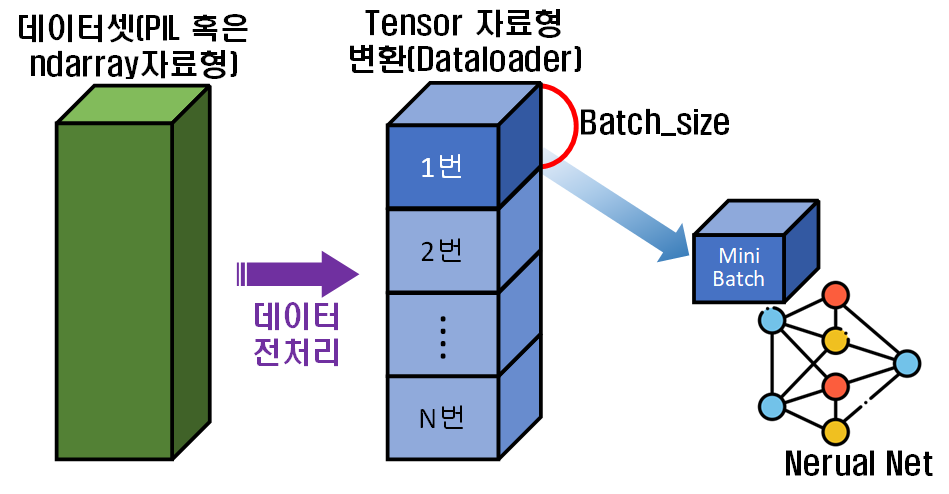 대략 위 사진처럼 데이터셋(이미지 파일의 경우
대략 위 사진처럼 데이터셋(이미지 파일의 경우 PIL 혹은 ndarray자료형으로 되어 있음)
을 Tensor자료형으로 변환하고, 또 Neural Net의 연산기(GPU, NPU)가 연산이 가능할 만큼의 데이터양 만큼 전체 데이터중 일부를 Slice해서 넣어준다.
이 Slice에 해당하는게 Batch_size라 보면 된다.
그리고 Batch_size만큼 잘라낸 데이터를 Mini Batch이라 하고, 이 Mini Batch를 Neural Net에 넣어 훈련시키고 다음 Mini Batch를 가져와서 훈련시키고... 이 과정을 반복한다
-> 이 반복의 횟수가 epoch에 해당한다.
아무튼 개론에 대해 알았으니
자료형 변환을 수행해보자
2.2.1 torchvision.transforms.v2
앞서 설명한 torchvision패키지는 단순히 데이터셋만 제공하는 것이 아니라 해당
데이터셋의 Transforming, Argumenting기능도
지원하고 있으며,
사실 이것이 더 중요하다 라고 생각한다.
 설명을 보면 Neural Net에 대한 훈련/추론을 위한 데이터 변환 및 증강 작업을 해주는 라이브러리라 설명하고 있으며
설명을 보면 Neural Net에 대한 훈련/추론을 위한 데이터 변환 및 증강 작업을 해주는 라이브러리라 설명하고 있으며
여기서 조금.. 힘들어 지는게
torchvision.transforms
torchvision.transforms.v2
두가지가 있는데
둘다 동일하게 데이터 변환, 증강작업을 수행하지만
v2가 최신 API이고, 더 성능이 좋다고 한다.
23년 10월에 출시하여 11월, 12월 두번의 패치 및 호환성 개선이 이뤄지고 24년 1월부터 정식 버전이 나왔다니
앞으로의 강의 복기는 해당 라이브러리를 최대한 사용하여 작업을 수행하고자 한다.
전처리 과정에 대한 전체 코드는 아래와 같다.
from torchvision.transforms import v2
#CIFAR-10의 정규화 파라미터
CIFAR_N_value = [[0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]]
#v2 API로 데이터 전처리 방식 정의
transformation = v2.Compose([
v2.Resize((32, 32)), #이미지 크기를 32x32로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=CIFAR_N_value[0], std=CIFAR_N_value[1])
])
#이미지에 v2전처리 방식을 적용
trainset.transform = transformation
testset.transform = transformation
BATCH_SIZE = 256
train_loader = torch.utils.data.DataLoader(trainset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = torch.utils.data.DataLoader(testset,
batch_size=BATCH_SIZE,
shuffle=False)항목별로 설명하면 아래와 같다.
1) v2.Compose : 데이터 전처리 라는 것에는 여러가지 기법이 함께 적용되는 경우가 많다.
이 말은 여러 변환 메서드를 동시에 적용시켜야 한다는 뜻인데 이걸 한꺼번에 묶어서 관리를 해주는 클래스라 보면 된다.
파이토치로 데이터 전처리를 수행한 유저라면
transform = transforms.Compose(
1번 전처리 메서드...
2번 전처리 메서드...
3번 전처리 메서드...
)이런식의 코드를 많이 봤을 텐데 transforms.Compose이 부분이 v2.Compose로 변경된 것이라 보면 된다.
2) v2.Resize() : 크기가 (h, w)에 해당하는 이미지의 크기를 조정하는 메서드이다. 입력되는 자료형은 size=튜플 (이미지 높이, 이미지 너비)순으로 입력해야 한다.
3) v2.ToImage(), v2.ToDtype : 이 메서드는 이해하는데 가장 머리가 아파오는 메서드였다.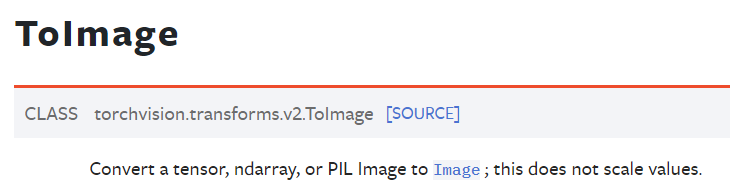 그냥 이렇게 짧은 단어로 설명되어 있고
그냥 이렇게 짧은 단어로 설명되어 있고
Image to Image라고 해서 이게 무슨 말인지 이해가 특히 안되는 부분이 있었다.
아니 Tensor 자료형으로 변환을 시켜야 하는데 예제에는 ToImage를 쓰는 형식으로 되어 있고
코드를 보니 대충
이전 라이브러리의 transfroms.ToTensor인거 같은데 뭐지?
라는 느낌이 있어서 찾아보니까
 v2 API에도
v2 API에도 v2.ToTensor이란 라이브러리가 있는 것을 확인했다.
이게 transfroms.ToTensor을 대체하는 라이브러리인 것을 확인했고, 이제는 쓰지 말란다.
좀더 정확하게는 v2.ToTensor = v2.ToImage() + v2.ToDtype(torch.float32, scale=True)
로 대체되었다는 설명이 기재되어 있다.
그래서 v2.ToImage()메서드로 들어가서 Image가 클릭 가능한 버튼이니 눌러보고 드디어 이해를 완료했다
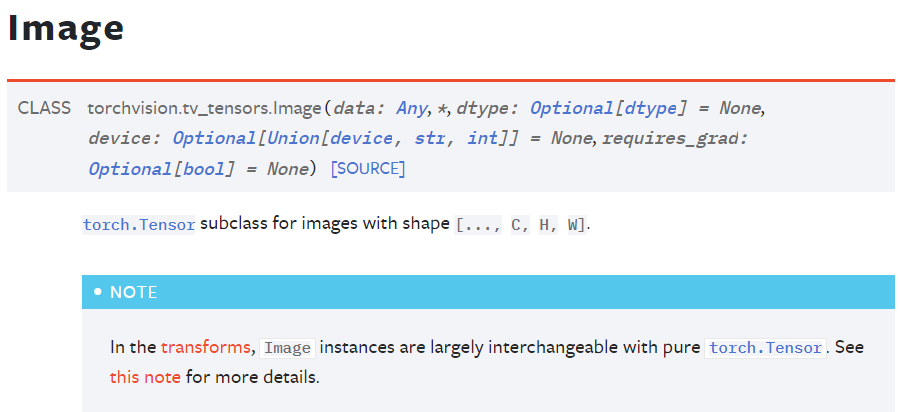 요약을 하자면 Tensor 자료형이긴 한데 이미지 처리에 좀 더 특화시킨 자료형이란다.
요약을 하자면 Tensor 자료형이긴 한데 이미지 처리에 좀 더 특화시킨 자료형이란다.
아무튼 Tensor랑 큰 차이 없고 더 유연하고 더 호환성 좋게 작동한다고 PyTorch 개발진들이 홍보하니 잘.. 써보자...
아무튼 transfroms.ToTensor은 v2.ToImage()와 v2.ToDtype(torch.float32, scale=True)으로 메서드 기능이 분리되었고
v2.ToImage()는 Tensor계열의 자료형 변환을 수행한다 하니
나머지 v2.ToDtype()는 Tensor 데이터 타입의 지정, 그리고 변환하는 데이터의 범위를 설정 하라는 뜻인데
이미지 처리용 모델에는 왠만하면torch.float32을 사용하니 이걸로 지정하면 되고
scale=True는 이미지의 데이터 범위를 [0.0 ~ 1.0]사이로 스케일링 하라는 뜻이다.
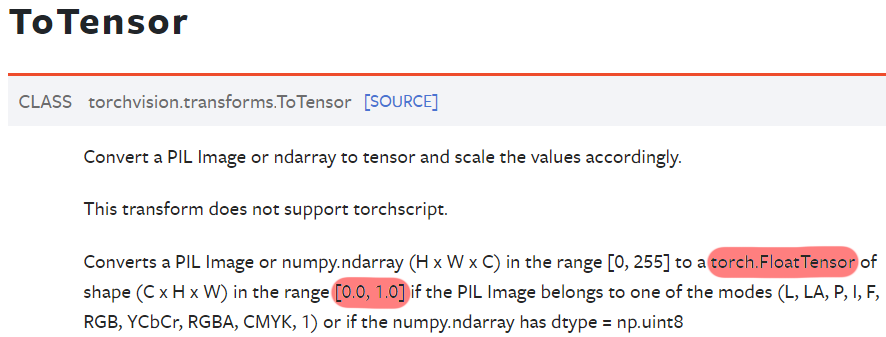
transfroms.ToTensor의 빨간색으로 표시한 float32 자료형변환 + [0.0 ~ 1.0] 스케일링을 v2.ToDtype()메서드가 수행한다는 뜻이고, 이 과정은(torch.float32, scale=True)를 인자값으로 넘겨주면 동일하게 수행할 수 있게 된다.
4) v2.Normalize() : 데이터(이미지) 정규화를 수행하는 메서드이다.
이게.. 효과는 Batch Normalization과 거의 유사하게 학습과정의 안정화를 꾀하는 메서드라고 보면 된다.
둘다 학습안정화, 학습 속도 향상을 목표로 하고 있다 보면 되고
v2.Normalize()에는 데이터셋(이미지)는 3채널이니
3채널(R, G, B)의 평균, 표준편차 값을 넣어서 정규화하는데
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))이렇게 일반적인 정규화를 수행하는 경우가 있고
입력하는 이미지의 데이터셋에 특화된 ((평균), (표준편차))값을 넣는 경우가 있다.
이번 강의에서는 CIFAR10데이터셋을 사용했고
해당 데이터셋은
평균 = [0.4914, 0.4822, 0.4465],
표준편차 = [0.2023, 0.1994, 0.2010]
값에 특화되어 있어 이를
CIFAR_N_value = [[0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]]라는 변수로 묶어서 v2.Normalize()에 인자값으로 넘겨준다.
마지막으로 v2.Compose의 메서드 입력 순서에 대해 설명하겠다.
transform = v2.Compose([
# 데이터 증강 기법
v2.RandomCrop(32, padding=4),
v2.RandomHorizontalFlip(),
v2.RandomRotation(15),
v2.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
# 전처리
v2.Resize((32, 32)),
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=CIFAR_N_value[0], std=CIFAR_N_value[1])
])위 코드로 보면 알 수 있듯이
1) 원본 이미지에 대한 Data Argumentation기법을 먼저 적용 후
2) 이미지를 Tensor 자료형으로 변환(Data Transformation)을 수행한다.
위 메서드의 순번은 딱히 섞여도 큰 문제는 없기는 하지만
지켜서 하는게 성능이 더 좋게 나온다.. 라고 한다...
2.2.2 torch.utils.data.DataLoader
데이터셋 전처리를 완료했으면 이제 딥러닝 모델에 입력 가능하게 데이터셋을 Slice(Batch_size)하여 Mini-Batch를 만들어주는 DataLoader 자료형으로 마지막 변환을 수행한다.
 설명을 보면 데이터 세트에 대한
설명을 보면 데이터 세트에 대한 iterable을 제공하고.. 다중 프로세싱 어쩌구 저쩌구 인데...
아무튼 딥러닝 모델에 Mini-Batch을 잘 넣어주는 자료형이라 보면 된다.
이게 파라미터 설정할게 굉장히 많은데 필수, 설정할 만한 옵션, 안건드려도 되는 것 3가지로 나눈다면
 위 사진에서 빨간색은 필수조정, 초록색은 선택조정 으로 보면 된다.
위 사진에서 빨간색은 필수조정, 초록색은 선택조정 으로 보면 된다.
1) dataset : 전처리가 완료된 데이터셋을 의미한다.
2) batch_size : 전체 데이터셋 중 1회 딥러닝 연산으로 넘길 Mini-Batch의 크기를 말한다
3) shuffle : 이 Mini-Batch를 섞을지 말지를 결정한다. 통상 train_dataset은 shuffle=True를 하고
test_dataset은 shuffle=Fales를 한다.
다음은 선택해서 조정하는 옵션이다
4) num_workes : 데이터를 로드할 때 사용되는 프로세서(통상 CPU이다)를 몇개 작업에 참여시킬지 결정하는 인자이다. Default=0이면 모든 CPU를 작업에 참여시킨다는 뜻이다.
5) collate_fn : 앞서 torchvision.transforms.v2으로 데이터 전처리 및 증강기법을 도입하지만
이걸로 안되는 경우가 왕왕 존재한다
대체로
데이터셋이 복잡하게 구성되어 있다던가...
샘플이 고정되어 있지 않다던가..
특수전처리가 필요하다던가..
하는 아무튼 난해한 데이터셋을 처리해야 할 때
custom collate_func를 따로 설계하고 그 함수를 인자값으로 넣어준다 보면 된다.
이걸 쓸 정도의 데이터셋이라면 머리가 아파오는 데이터셋일 것이다.
다음챕터에서는 이렇게 전처리가 완료된 데이터셋을 모델에 입력하고 훈련/평가(검증)하는 코드를 작성해 보도록 하겠다.
