
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
전 포스팅 인공지능 고급(시각) 강의 복습 - 9. CNN 모델 만들기 - 1) 데이터셋까지 에서는 데이터셋의 전처리까지 설명했으니
이제 모델을 설계하고 훈련/검증을 진행하고자 한다.
1. 모델 설계
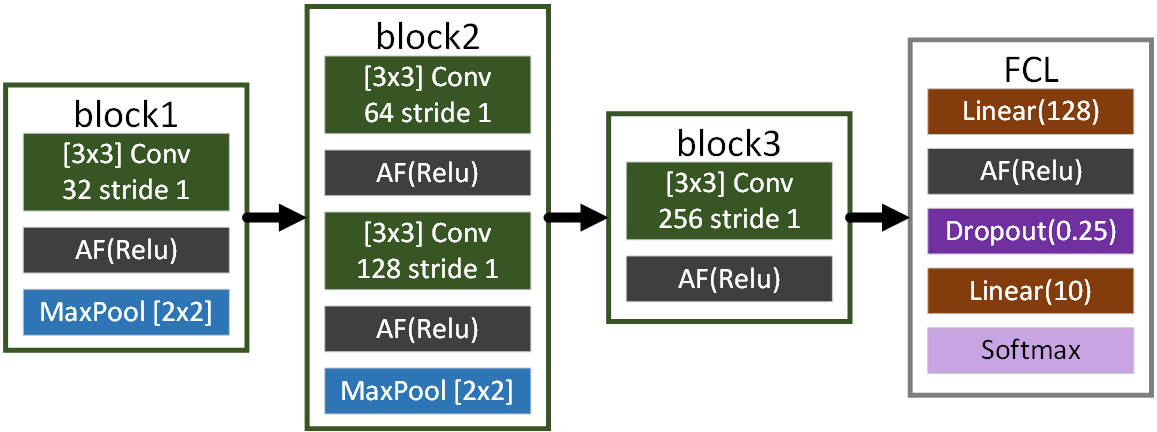
모델은 위 사진으로 표시한 SimpleNet을 설계해 보고자 한다.
위 설계도를 코드로 구현하면 아래와 같다.
import torch.nn as nn
class SimpleNet(nn.Module):
def __init__(self, in_channels=3, num_classes=10):
super(SimpleNet, self).__init__()
self.block1 = nn.Sequential(
nn.Conv2d(in_channels, 32, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.block2 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=0),
nn.ReLU(),
)
self.flatten = nn.Flatten()
self.fc1 = None # Initialize fc1 as None
self.fcblock = nn.Sequential(
nn.ReLU(inplace=True),
nn.Dropout(0.25),
nn.Linear(128, num_classes),
nn.Softmax(dim=1)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.flatten(x)
if self.fc1 is None:
self.fc1 = nn.Linear(x.size(1), 128).to(x.device)
x = self.fc1(x)
x = self.fcblock(x)
return x위 코드로 구현한 모델에 대한 요약 정보를 확인하려면 아래의 코드를 실행시키면 된다.
from torchsummary import summary #설계한 모델의 요약본 출력 모듈
debug_model = SimpleNet()
summary(debug_model, input_size=(3,32,32), device='cpu')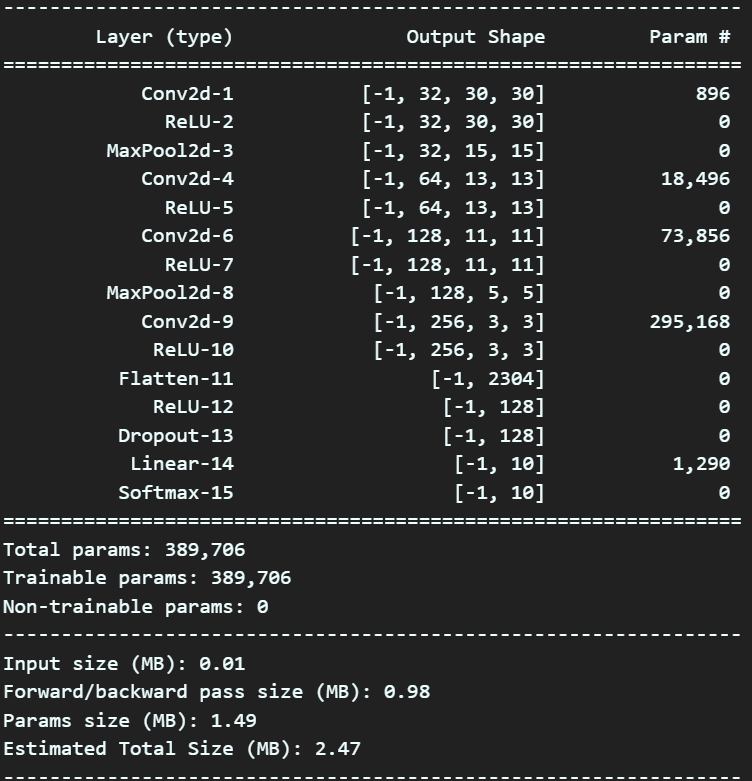
코드에 대한 설명을 하자면 아래와 같다.
1) torch.nn.Sequential : 모델을 설계할 때 설계자의 가독성을 높이기 위한 용도로 사용되는 메서드라 보면 된다.
음.. 그러니까
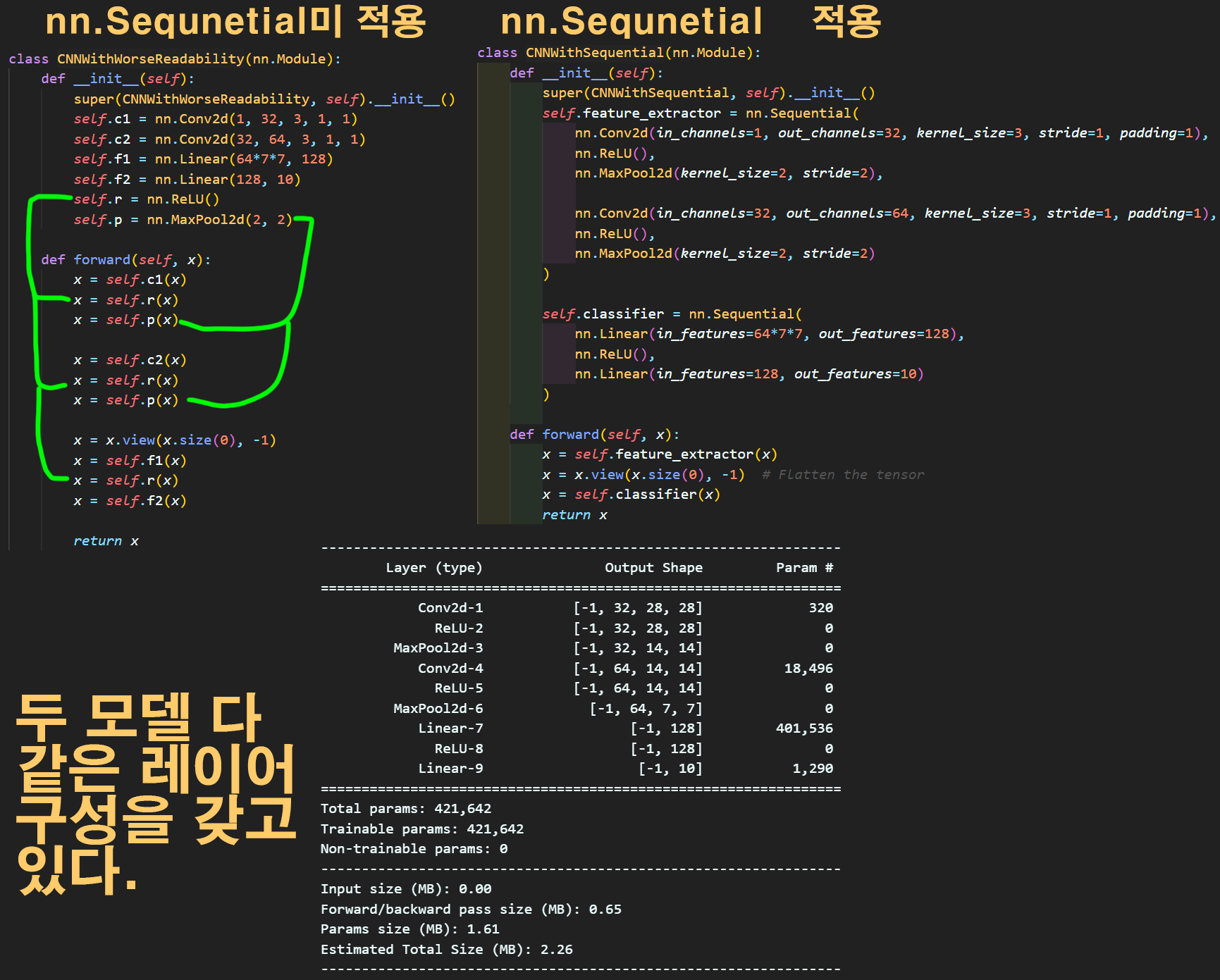 이 예시를 보면 좀 이해가 될 거 같긴한데
이 예시를 보면 좀 이해가 될 거 같긴한데
torch.nn.Sequential을 적용을 안하면 왼쪽 위 모델처럼 사용된 레이어 종류만 주욱 나열되고
이걸 def forward() 함수에서 신나게 나열된 레이어를 이곳저곳에서 가져와서 레이어 배치를 하는 코드가 더러 있다.
이게 코드리뷰를 하다 보면 참 알아먹기 힘들게 된 것을 알 수 있을 것이다.
이걸 좀 편리하고 가독성이 높이려고 지원되는 메서드라 보면 될 것 같다.
2) torch.nn.Conv2d : Pytorch 라이브러리가 제공하는 합성곱 연산 레이어 이다. 이 모듈의 동작은... 6. 합성곱 연산 함수 구현을 참조하면 될 듯 하다...
3) torch.nn.ReLU : Pytorch가 제공하는 Activation Function이다.
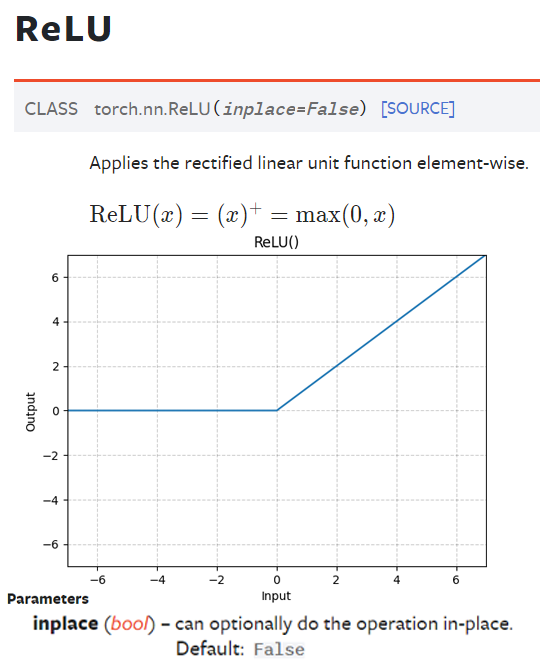
여기서 골이 아파오는 인자값이 inplace=True인데
다른 설명을 봐도 좀 이해가 안되긴 하다.
그러니까 위 옵션을 True로 하면 메모리 절약 차원에서
입력되는 Tensor를 덮어쓰기 한다는건데...
약간 파이썬의 list설명할 때 다루는
Shallow Copy / Deep Copy인
list_B = list_A 와
list_B = list_A.copy()의 차이점? 으로 이해하면 될 것 같다...
Relu 레이어는 기본 옵션이 inplace=False 이고
출력 Tensor = AF연산[입력Tensor.copy()]
으로 연산을 주로 수행하지만,
Relu 레이어의 옵션을 inplace=True 로 바꾸면
출력 Tensor = AF연산[입력Tensor] 이런 느낌으로 덮어쓰기를 해버려서 메모리를 절약한다.. 뭐 이런 개념인거 같다.
문제는 메모리 덮어쓰기인데 입력 Tensor을 덮어 써서 출력 Tensor로 해버리니 원본 데이터가 아에 날아가 버리는 문제가 발생할 수 있다... 라는 것이다.
이게 어떻게 문제가 발생하는지는 솔직히 잘 감도 안오고.. 그런데
대충 다른이들의 코드를 살펴보면
가장 마지막 레이어(현재의 모델 상으로는 FC Layer)에 ReLU가 적용되면 여기에서 메모리 절약 차원에서 inplace=True를 적용한다.. 라고 이해하고 넘어가면 될 것 같다.
중간레이어에는 ReLU에 inplace=True를 잘 적용하지 않는다
그런데 애초에 딥러닝이 메모리+연산성능 낭비를 전제로 깔고 하는 작업인데 메모리를 아끼면 얼마나 아낄 수 있을까...
4) torch.nn.MaxPool2d : Pooling Layer을 구현할 때 쓰는 메서드이고
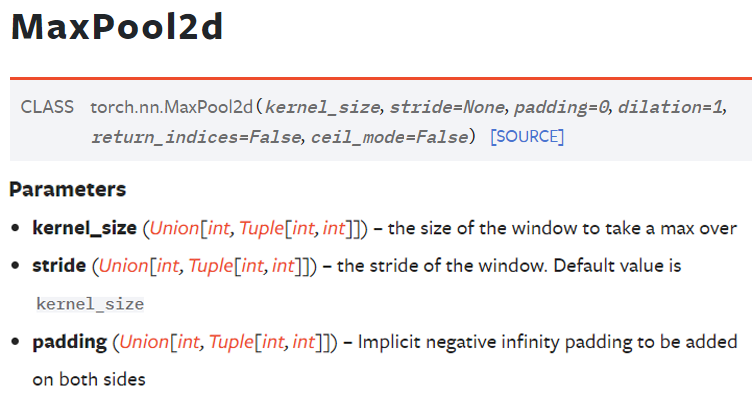 인자값으로 3개를 받는데
인자값으로 3개를 받는데 padding은 기본이 0, stride는 기본이 kernel_size랑 같은 값이다.
따라서
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)이거는
nn.MaxPool2d(kernel_size=2)와 동일하다.
5) nn.Flatten(), nn.Linear() : 이 메서드는 Conv -> FCL로 넘어가면서 필연적으로 발생할 수밖에 없는 Flatten 과정에 대해 이해가 선행되어야 한다.
![]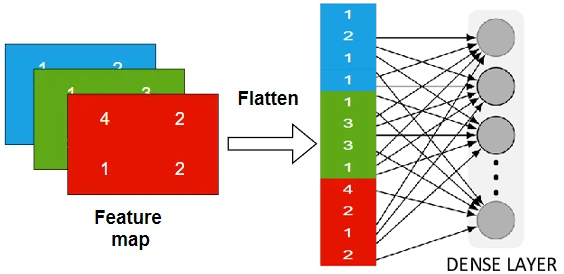 위 사진으로 표현할 수 있듯이 Conv레이어를 통과한 결과물인
위 사진으로 표현할 수 있듯이 Conv레이어를 통과한 결과물인 Feature map은 FCL(Dense Layer)에 입력하려면
FCL(Dense Layer)은 1차원 행렬 데이터만 받기에
이 다차원의 Feature map을 1차원으로 재배치를 해줘야 한다.
이 과정을 Flatten이라 부른다.
이 과정이 PyTorch에서는 골이 좀 아파오는 부분이 있는데
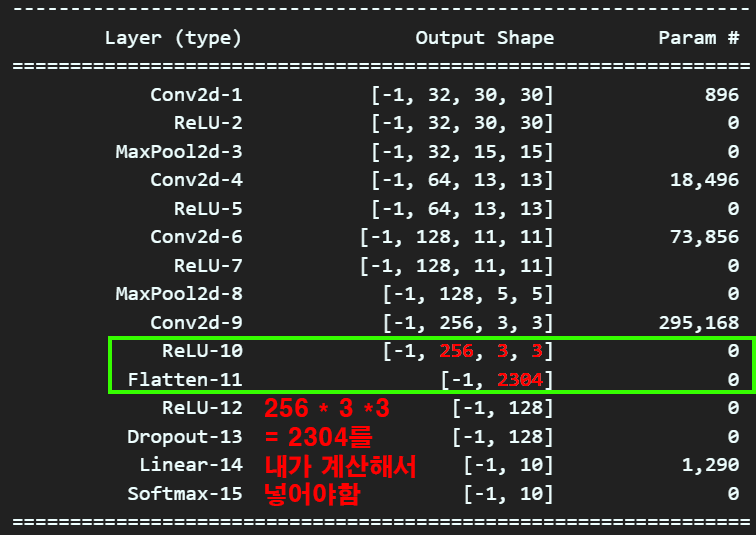
위 사진처럼 내가 256 X 3 X 3 = 2304 라는 값을 계산해서 nn.Linear(in_features , out_features)의 in_features에 넣어줘야 한다는 거다.
즉, 정석대로라면
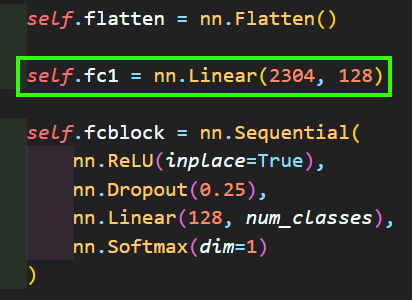 이렇게 코드를 작성해야 한다.
이렇게 코드를 작성해야 한다.
이 2304라는 값을 계산하기 어려워서
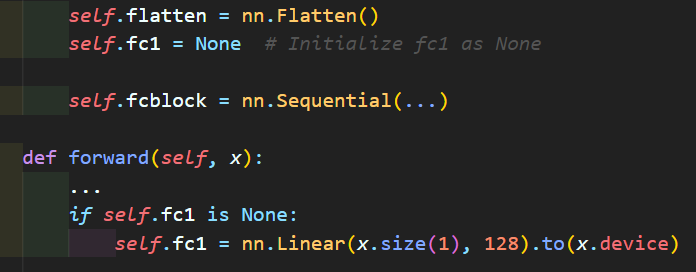 위와 같은 방식으로 Conv 레이어의 차원값을 동적으로 받아서 FCL(Dense Layer)로 넘어가게 코드를 구현했다.
위와 같은 방식으로 Conv 레이어의 차원값을 동적으로 받아서 FCL(Dense Layer)로 넘어가게 코드를 구현했다.
이걸 설명을 하자면
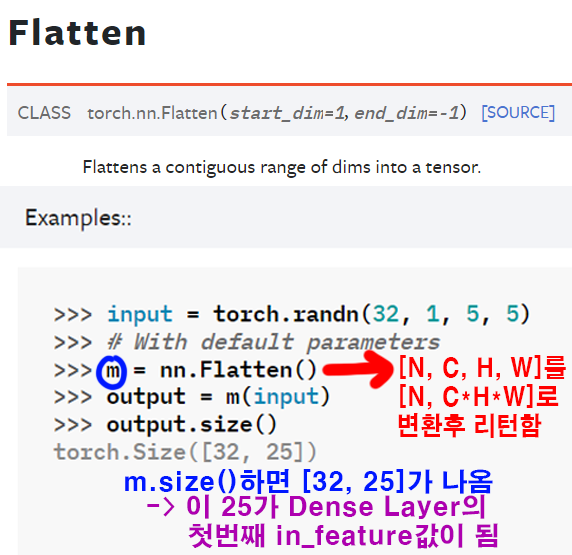 위 사진과 같으며 이
위 사진과 같으며 이 output.size(1)이 Deense Layer에 속하는 fc1의 nn.Linear(in_feature, out_feature)의 in_feature에 넣어주면 된다.
여기서 또 골이 아파와 지는게
.to(x.device)를 붙여줘야 한다.
안그러면 딥러닝 모델의 레이어 계산 결과인 Tensor자료형이 CPU로 넘어가 버린다.
딥러닝 모델을 CPU에서 구동하면 상관없지만
GPU에서 구동하면 GPU데이터가 CPU로 넘어가서 에러가 난다.
이제 설계한 모델이 잘 구동되는지, 그리고 GPU로 옮기는 과정을 수행해보자
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#GPU사용이 가능하면 'cuda'가 device에 들어감
from torchsummary import summary
#모델 요약본 출력해주는 라이브러리
ex_model = SimpleNet(num_classes=num_classes)
ex_model.to(device)
summary(ex_model, input_size=(3,32,32), device=device.type)2. 손실함수부터 훈련까지
2.1 손실함수, 최적화 방법론 정의
from torch import optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.RMSprop(ex_model.parameters(), lr=0.001)손실함수는 다중 분류 문제이기에 CrossEntropyLoss
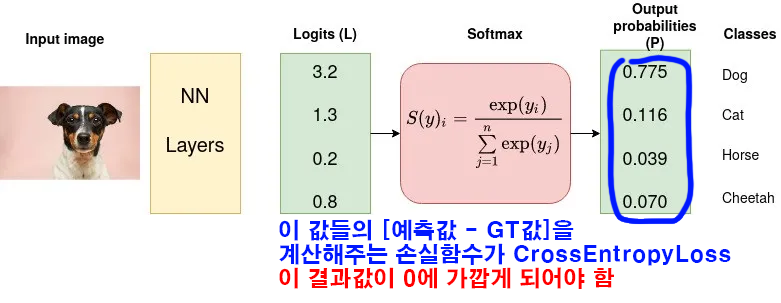
CrossEntropyLoss을 Global Mininum으로 보내는 방법론은optim.RMSprop이라 보면 된다.
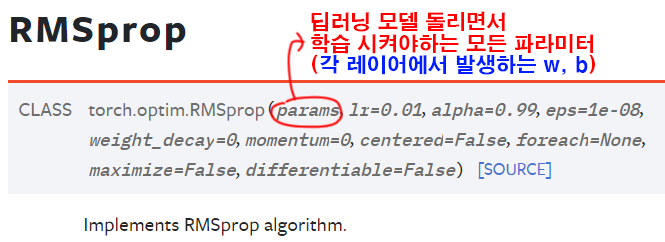
optimizer의 다른 인자값들은 하이퍼 파라미터라고 불리면서 논문이나 해당 모델의 최적화 방법론을 검색하면 얼마얼마라고 설정하라는 값들이 있다.
대충 Learning Rate, Momentum이 하이퍼 파라미터에 속한다 보면 된다.
2.2 훈련/검증/실행 파트
모델을 훈련, 검증시키는 함수와
이 두 함수를 받아서 반복적으로 실행하는 코드는 아래와 같다.
2.2.1 훈련 함수
from tqdm import tqdm #훈련 진행상황 체크
def model_train(model, data_loader, loss_fn, optimizer_fn, processing_device):
model.train() # 모델을 훈련 모드로 설정
#loss 및 Accuracy를 계산하기 위한 변수
run_size, run_loss, correct = 0, 0, 0
progress_bar = tqdm(data_loader)
for image, label in progress_bar:
#입력 이미지를 GPU로 이전
image = image.to(processing_device)
label = label.to(processing_device)
#forward과정 수행
output = model(image)
loss = loss_fn(output, label)
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
#argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
progress_bar.set_description('[Training] loss: ' +
f'{run_loss / run_size:.4f}, accuracy: ' +
f'{correct / run_size:.4f}')
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
return avg_loss, avg_accuracy2.2.2 검증함수
def model_evaluate(model, data_loader, loss_fn, processing_device):
model.eval() # 모델을 평가 모드로 전환
#eval()으로 전환 시 설정되는 것들
#1. dropout 기능이 꺼진다
#2. batchnormalizetion 기능이 꺼진다.
with torch.no_grad():
# 여기서도 loss, accuracy 계산을 위한 임시 변수 선언
run_loss, correct = 0, 0
progress_bar = tqdm(data_loader)
for image, label in progress_bar:
#입력 이미지를 GPU로 이전
image = image.to(processing_device)
label = label.to(processing_device)
output = model(image)
pred = output.argmax(dim=1) #예측값의 idx출력
correct += torch.sum(pred.eq(label)).item()
run_loss += loss_fn(output, label).item() * image.size(0)
accuracy = correct / len(data_loader.dataset)
loss = run_loss / len(data_loader.dataset)
return loss, accuracy2.2.3 실행 파트
his_loss, his_accuracy = [], []
num_epoch = 50
for epoch in range(num_epoch):
# 훈련 손실과 정확도를 반환 받습니다.
train_loss, train_acc = model_train(ex_model, train_loader, criterion, optimizer, device)
print(f"epoch {epoch+1:03d}, Training loss: {train_loss:.4f}, Training accuracy: {train_acc:.4f}")
# 검증 손실과 검증 정확도를 반환 받습니다.
test_loss, test_acc = model_evaluate(ex_model, test_loader, criterion, device)
print(f"Test loss: {test_loss:.4f}, Test accuracy: {test_acc:.4f}")
# 손실과 정확도를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_accuracy.append((train_acc, test_acc))2.2.4 결과물 출력 파트
import matplotlib.pyplot as plt
# 손실 그래프
train_losses, val_losses = zip(*his_loss)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='train')
plt.plot(val_losses, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# 정확도 그래프
train_accuracies, val_accuracies = zip(*his_accuracy)
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='train')
plt.plot(val_accuracies, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Train-Val Accuracy')
plt.tight_layout()
plt.show()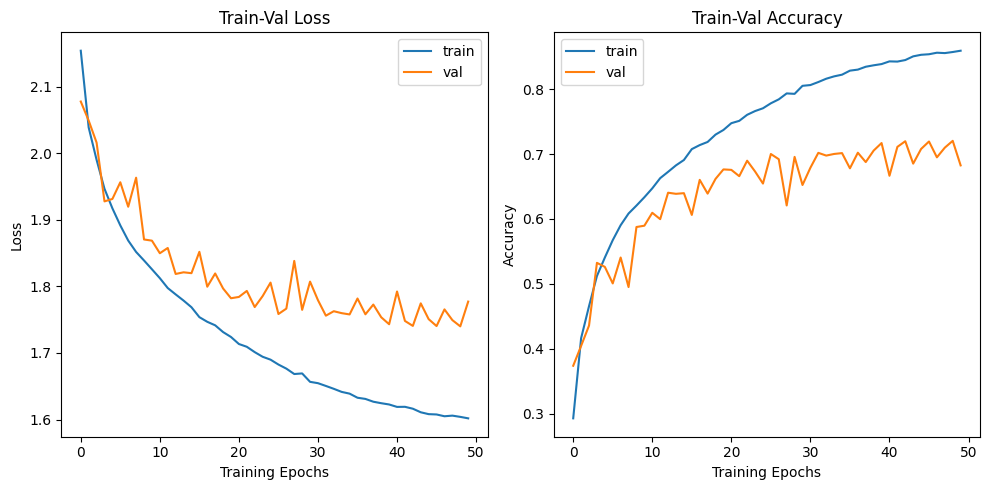
2.2.5 훈련된 모델의 저장/불러오기
#모델의 가중치만 저장하기
MODEL_NAME = 'SimpleNet'
torch.save(ex_model.state_dict(), f'{MODEL_NAME}.pth')
# 모델 전체를 저장 (모델 구조와 가중치를 포함)
torch.save(ex_model, 'SimpleNe3_model.pth')# 저장한 모델을 불러오기
ex_model.load_state_dict(torch.load(f'{MODEL_NAME}.pth'))
ex_model.to(device)2.2파트의 경우는
코드만 붙여 놓으며
이 부분은 계속 반복적으로 사용되는 코드이기에
다음 포스팅에서 좀 더 자세하게 설명하겠다...

ㅅㄱ...
