
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. MobileNet v3 개요
MobileNet v3은 이전 포스트 26. 주요 CNN알고리즘 구현 : MobileNet v2 (1) - 인공지능 고급(시각) 강의 복습의 MobileNet v2를 좀 더 개선한 모델로
주요 개선사항은
⭐ 개선된 아키텍쳐 설계 및 최적화에 NAS(Neural Architecture Search)를 도입
⭐ 경량화 모델에 더 적합한 Activation Function인 Hard-Swish 활성화 함수 도입
⭐ SENet의 핵심 설계모듈인 SE Block(Squeeze-and-Excitation) 도입으로 모델 정확도 향상
⭐ 고성능 버전(MobileNet v3 - Large), 저용량 버전(MobileNet v3 - Small)으로 파생모델의 세분화
로 정리할 수 있다.
위 개선사항을 통해 MobileNet v2대비 동일 Width Multiplier, Resolution Multiplier 일 때 전반적으로 20%의 연산복잡도 최적화를 이뤄냈으며,
동일한 연산복잡도 조건에서는 약 3~6%의 정확도 향상을 기대할 수 있다.
2. MobileNet v3 개선 방법론
2.1. NAS(Neural Architecture Search)
MobileNet v3이 성능향상 및 최적화를 하는데 가장 핵심적으로 사용된 방법론이며
신경망 구조탐색으로 번역되는 해당 방법론은 AutoML의 한 분야에 속하는 방법론이다.
그러면 AutoML은 무엇이냐? 머신러닝 모델의 설계, 학습, 하이퍼 파라미터 튜닝, 평가, 배포와 같은
기존에 사람이 수작업으로 수행하던 머신러닝 개발 프로세스를 자동화 하는 것을 말하며
이 중 NAS는 더 최적화된 딥러닝 모델 설계를 위한 AutoML이라 보면 된다.
이를 통해 사람이 설계를 진행했던 MobileNet v2과 초기 버전의 MobileNet v3를 NAS를 통하여
레이어 크기, 채널수, 레이어 배치 순서 등을 인공지능으로 설계최적화를 꾀했다.
논문에서는 NAS의 주요 성과로
MobileNet v3의 가장 마지막 block인 Last Stage의 레이어 개선과
MobileNet v3를 Backbone으로 활용한 세그멘테이션 모델 설계 시 세그멘테이션 디코더 블럭의 구조개선을 언급하고 있다.
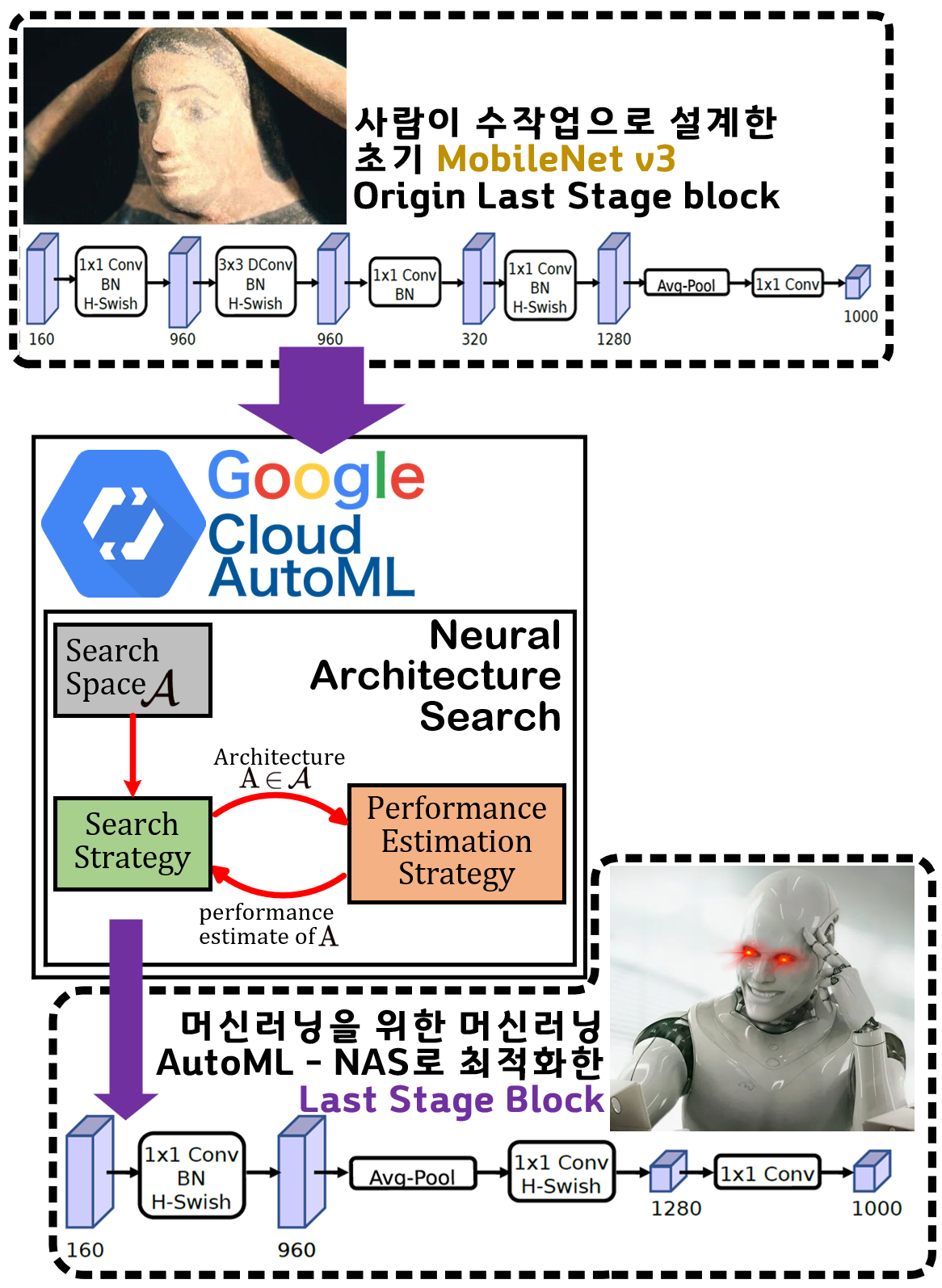
NAS를 적용하여 모델을 최적화하는 방법론을 도식화 한다면 초기 모델을 설계한 후
커널크기, 필터 크기, 레이어 개수 등을 탐색공간으로 정의하여
조건별로 여러 모델을 설계하고 각 파생 모델 중 가장 목적에 부합한 최적 모델을 찾아내는 식으로
머신러닝을 위한 머신러닝 : AutoML이 동작한다.
이 AutoML은 Google AtuoML, H2O.ai AutoML, Azure AutoML 등으로 플랫폼 형식으로 제공되는 서비스를 이용하는게 일반적인 적용 방법론인 듯 하다.
2.2 Activation Function
MobileNet v3는 새로운 활성화 함수를 사용하여 기존에 주로 사용되는 ReLU(ReLU6) 함수가 갖고 있는 비선형성 문제를 해결하면서
동시에 모바일 환경에서 더 나은 연산 효율성을 확보하려 한다.
이로써 모델의 성능은 향상시키면서 동시에 모델 최적화를 수행하는데
이를 위해서는 기존 활성화 함수가 내포하는 문제점과 개선사항을 모두 숙지할 필요가 있다.
2.2.1 ReLU의 장단점
CNN계열의 모델에서 주로 사용되는 ReLU (MobileNet계열은 Relu6를 사용하지만 주요 문제점은 거의 동일하다)
우선 ReLU가 갖고 있는 주요 장점은 아래와 같다.
⭐ 계산 효율성
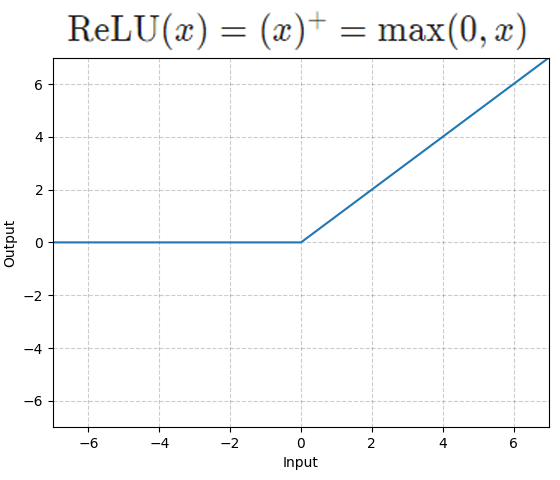
ReLU는 여타 다른 활성화 함수에 비해 수식이 매우 간단하기에 연산 속도 및 계산 효율성이 상당히 높은 편에 속한다.
이는 훈련 프로세스를 종료하는 수렴 단계로 도달하는 시간 단축에도 많이 영향을 끼치는데
통상 Sigmoid 함수 대비 6배 정도 수렴 단계에 도달하기에 훈련 프로세스에 소요되는 시간을 단축시키는 장점이 있다.
⭐ Vanishing Gradient(기울기 소실)에 대한 억제력이 높음
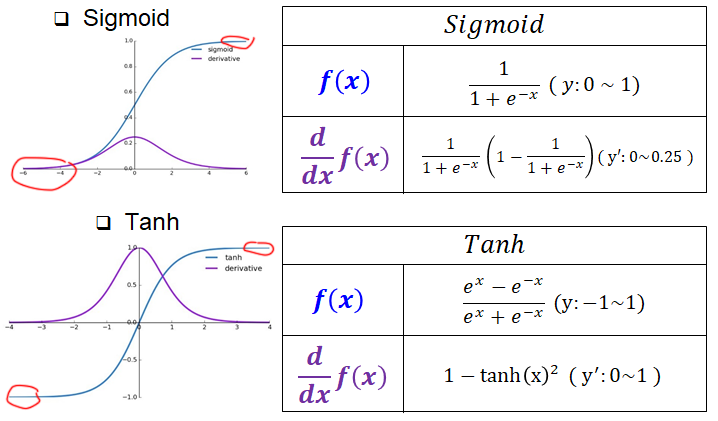
Sigmoid함수가 초기에 사용되었으나, 활성화 함수의 주류에서 밀려난 주 이유로 기울기 소실 문제가 있으며 위 사진처럼 활성화 함수의 출력값이 양 극단에 위치하는 값(Sigmoid는 0 or 1)일 때는 향후 역전파 연산 시 미분치(기울기값)가 0에 가까운 값이 되버려서 가중치가 거의 업데이트가 되지 않아 훈련이 중단되는 문제가 발생한다.
그에 반해 ReLU는 미분값이 정수값(1)을 갖기에 기울기 소실문제가 꽤 억제되는 특징이 있다.
⭐ 과적합 방지 및 정규화 효과
ReLU 함수는 음수 입력값을 모두 0으로 출력하기에 이는 뉴런을 비활성화 하는 Dropout기법과 유사한 효과를 기대할 수 있다.
따라서 역전파 과정에서 업데이트에 참여하지 않는 뉴런집단을 Dropout처럼 동일하게 만들어 내기에 이를 통한 과적합 방지 효과를 꾀할 수 있다.
또 가중치의 값 일부를 0으로 만드는 것은 weight에 패널티(0)을 줘서 원하는 뉴런만을 역전파 과정에 참여시키는
L1, L2 정규화 기법과도 그 효과를 비슷하게 기대할 수 있다.
2.2.1.1 Dead ReLU
ReLU의 장점중 '음수 입력은 0으로 출력'은 과적합 방지라는 장점을 가져오지면 동시에 Dead ReLU이라는 단점을 가져온다.
뉴런이 비활성화 하는게 장점일 수 있지만
동전의 양면처럼 단점이 되기도 하는 것이다.
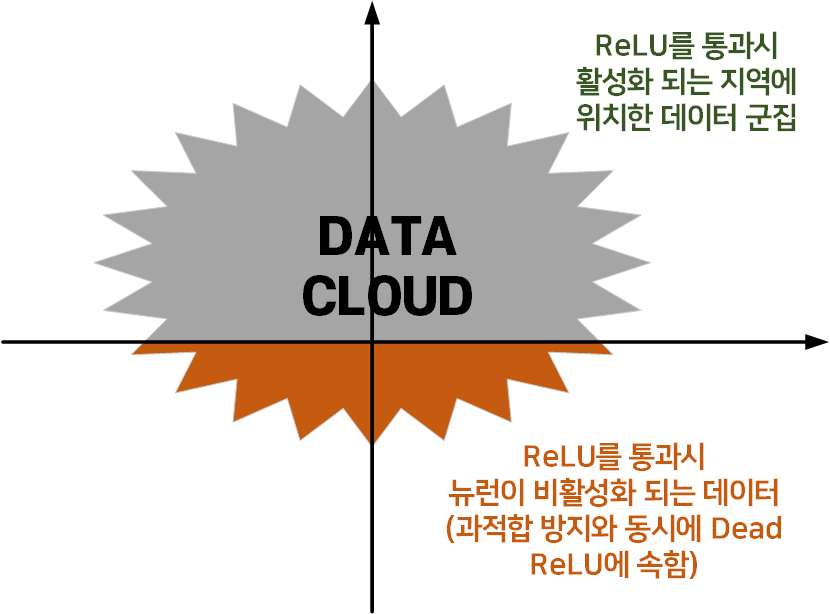
이는 위 그림처럼 임의의 데이터셋 Data cloud가 존재할 때 ReLU 함수를 통과하면 값이 음수인 지역(주황색)은 뉴런이 비활성화되는 Dead ReLU가 되버린다.
통상적으로 딥러닝을 학습시키면 위와 같이 Dead ReLU에 속하는 데이터 클라우드는 10~20% 정도가 발생하기에
흔히 Dropout의 설정값으로 사용하는 0.2~0.5보다 적은 뉴런이 비활성화 된다.
따라서 대다수의 CNN모델에서는 ReLU의 단점보다는 장점이 더 많이 부각되지만
MobileNet 계열 네트워크는 단점이 더 많이 부각되는데
이는 Data Cloud를 차원 축소 후 연산하는 과정이
Inverted Residual Bottelneck Block에 포함되기 때문이다.
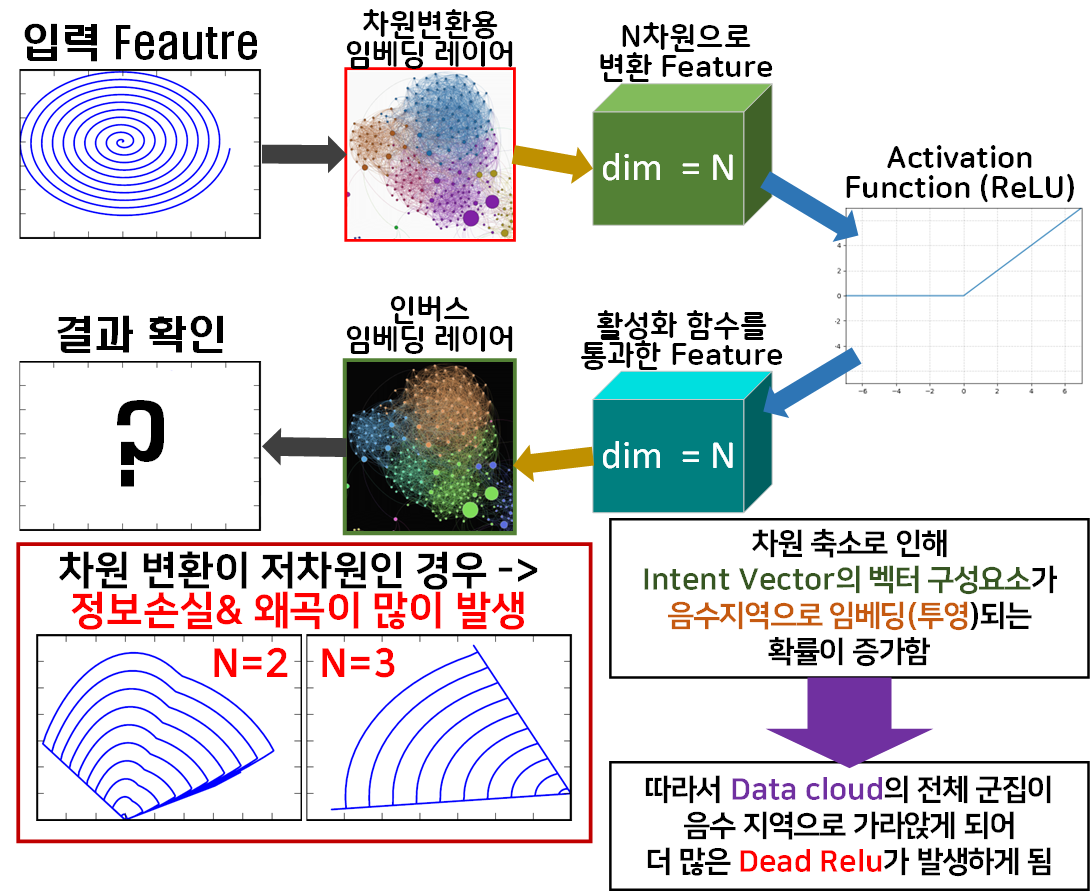
이는 Inverted Residual Bottelneck Block가 가장 마지막 레이어는 활성화 함수를 사용하지 않는 이유와 맞닿아 있는데
초기 고차원의 Data Cloud를 구성하는 Intent Vector은 통상적인 음수벡터 요소가 10~20% 정도 되기에
적당한 과적합 방지 효과를 기대할 수 있지만
이 Data Cloud를 저차원으로 임베딩 하면서 Intent Vector의 벡터 구성요소가 음수지역으로 투영되는 확률이 증가하게 된다.
이는 적정선의 비활성 뉴런의 개수를 증가시키는 효과를 가져오기에
과적합 방지의 이점보다는 Dead RelU의 단저이 더 부각되는 부작용이 발생하는 것으로 이해할 수 있다.
2.2.2 ReLU의 개선 - SiLU
ReLU의 장/단점을 공부했으니 이를 개선하고자 하는 수많은 활성화 함수들이 연구되었으며,
대표적으로 사용되는 함수는
LeakyReLU, SiLU(Swish), GeLU, Mish 등이 존재한다.
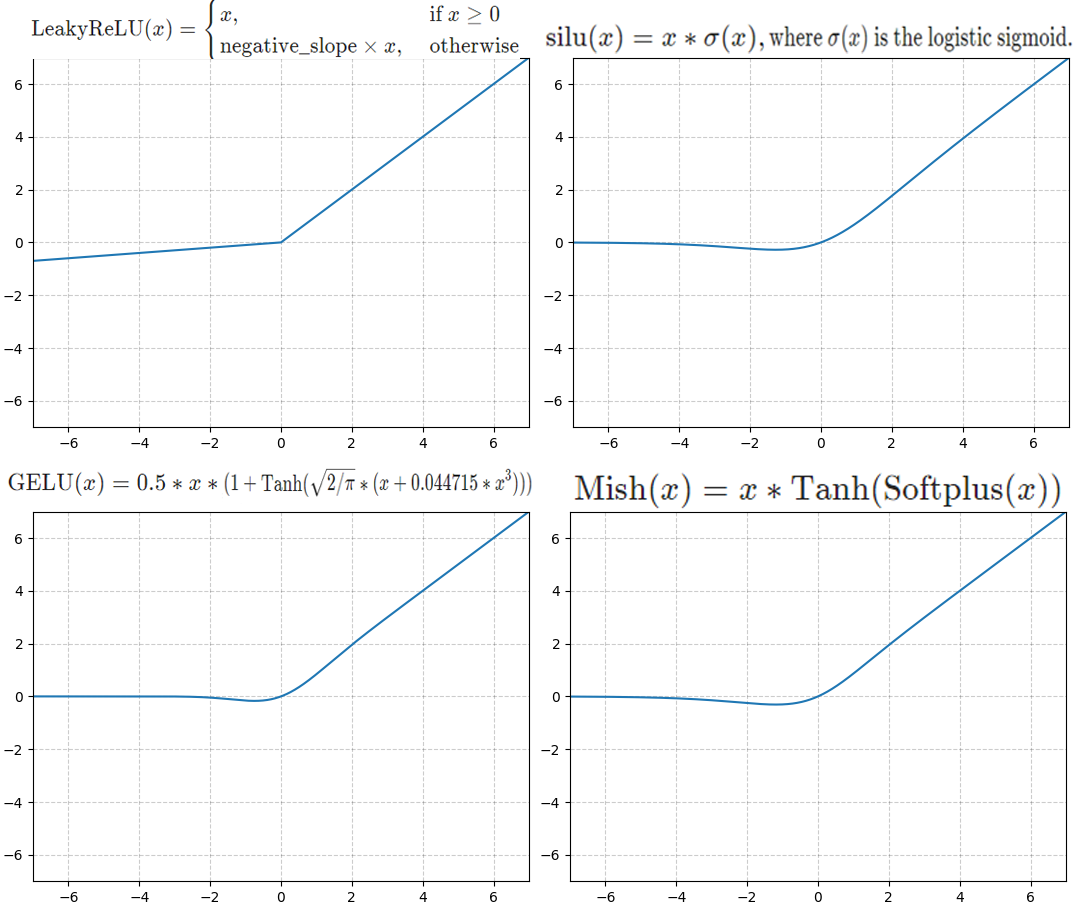
MobileNet v3는 SiLU(Swish) 계열의 활성화 함수를 사용하며,
💎 입력값이 음수 구간이어도 작은 값으로 출력이 발생함
💎 기울기(Gradien)가 0이 아닌 부드러운 비 선형성을 갖고 있음
의 장점이 있다.
그러나 다른 활성화 함수랑 비교한다면 SiLU는 타 활성화 함수인 GeLU, Mish랑 그래프 상으로는 큰 차이가 없어보이는데 SiLU가 사용되는 주요한 이유가 있다.
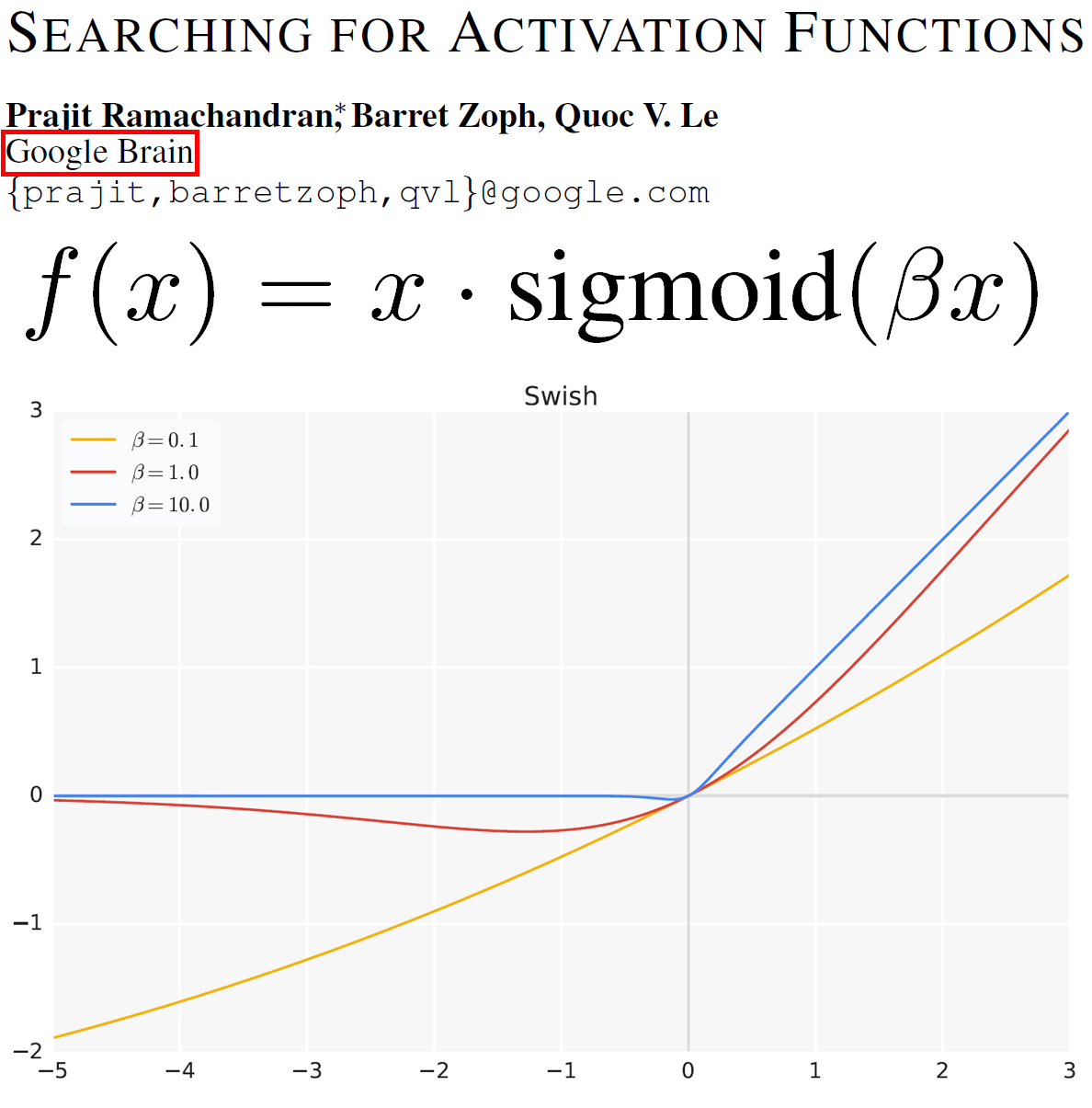
SiLU(swish)를 제안한 연구팀은 Google Brain으로 MobileNet v3은 동일 부서인 Google Brain와 Google AI Perception부서의 cowork으로 제안된 모델이기에
MobileNet v3의 개발에 SiLU이 적용되는 것이 당연하다 볼 수있다.

2.2.3 최종 적용 : Hardswish
MobileNet v3에 적용된 Activation Function은 SiLU(swish)를 목적에 맞게 경량화 시킨 버전인 Hardswish함수를 사용한다.
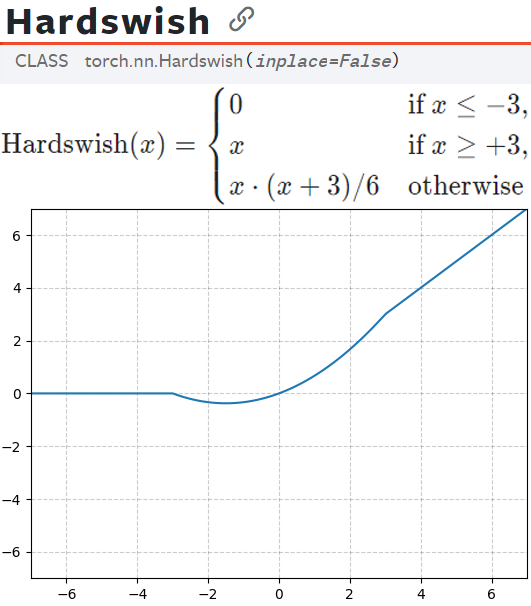
Hardswish는 수식으로 보면 어려워 보이지만
SiLU = Relu X Sigmoid인 것이랑 동일하게
Hardswish = ReLU 6 X Sigmoid로 함수를 정리할 수 있다.
ReLU의 경량화 버전인 ReLU 6에 Sigmoid함수를 섞은 것이기에 기존 MobileNet에 적용되던 ReLU 6의 장점과
SiLU의 장점이 함께 적용되기를 기대한 함수라 보면 된다.
이때 MobileNet v3는 NAS를 사용하여 전체 모델에 대한 최적화가 진행되었기에
모든 블럭의 활성화 함수로 Hardswish를 적용하는 것이 아닌
Hardswish와 ReLU를 혼용하여 사용한다.
2.3 Squeeze-and-excite
다음으로 MobileNet v3에 적용된 성능 향상 기법은 이전 포스트 23. 주요 CNN알고리즘 구현 : SENet (3) - 인공지능 고급(시각) 강의 복습에서 언급한 SENet의 핵심 설계모듈인 SE Block으로
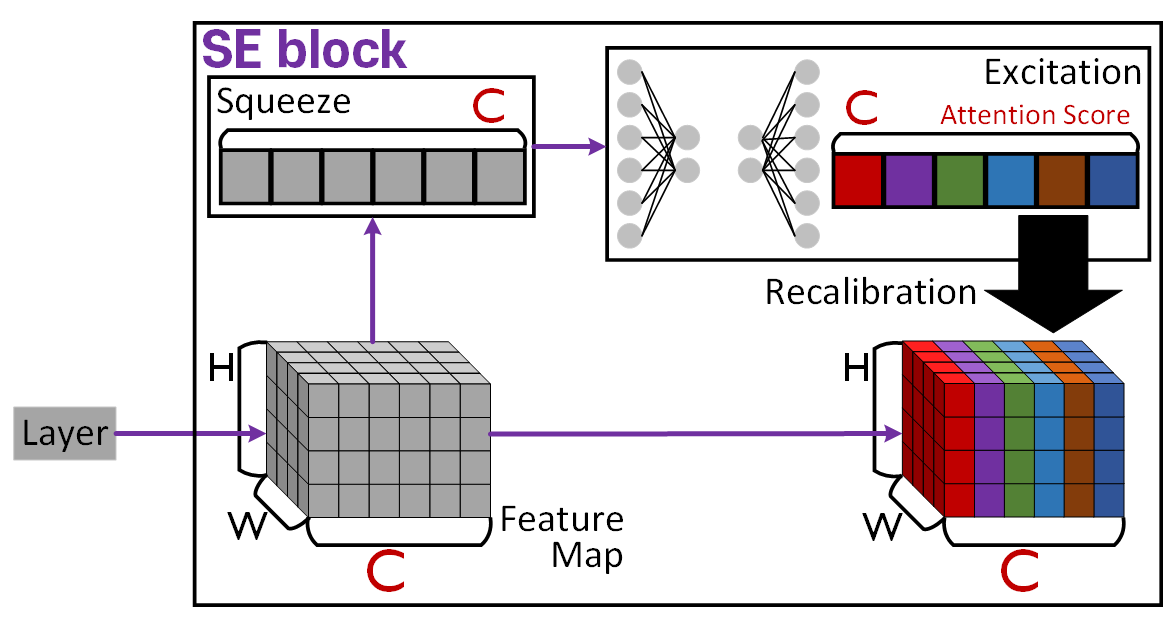
위 사진처럼 채널별 Attention Score을 산출한 값을 곱하는 과정을 통해 연산 Cost가 약간 증가하나 이를 상쇄하고도 남는 성능(Accuracay)향상을 꾀할 수 있다.
2.3.1 SE block의 코드개선
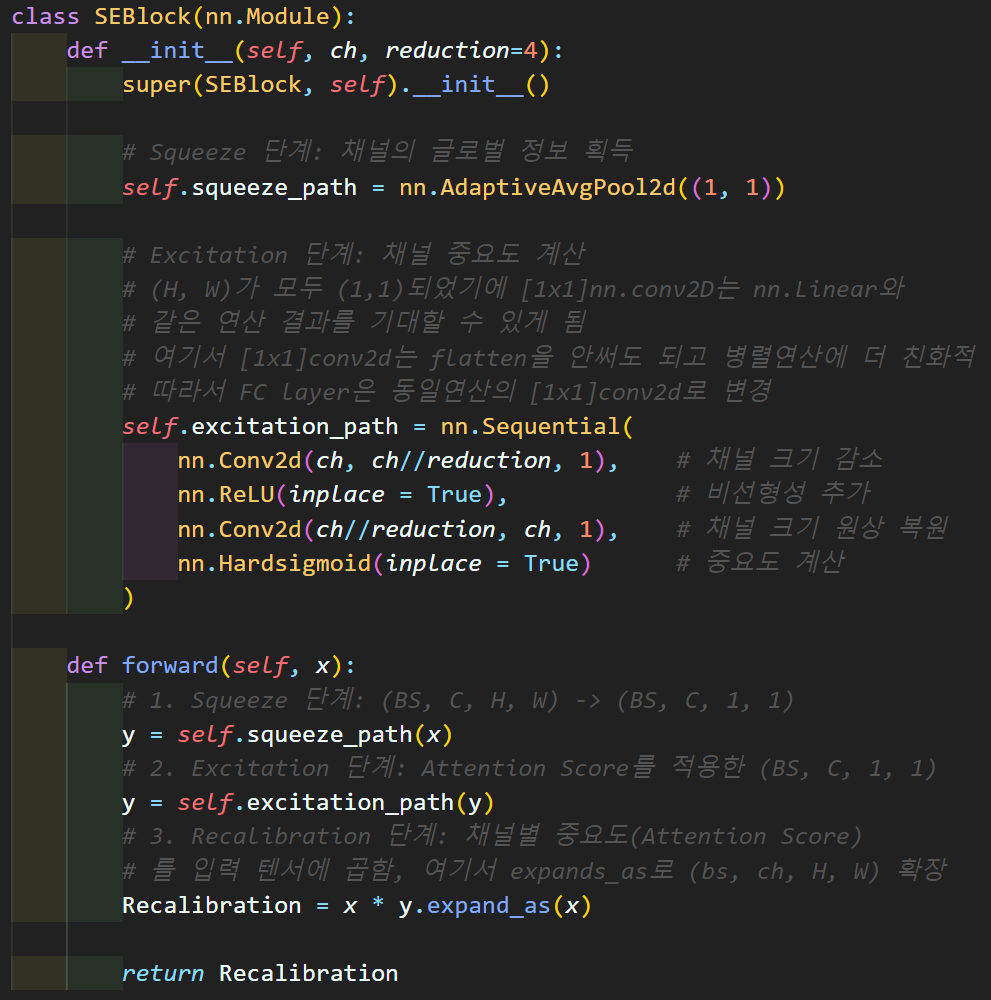
코드는 이전포스트에서 사용한 SE_Block과는 약간의 코드개선이 있는데
1️⃣ nn.Linear [1x1] nn.Conv2D로 변경
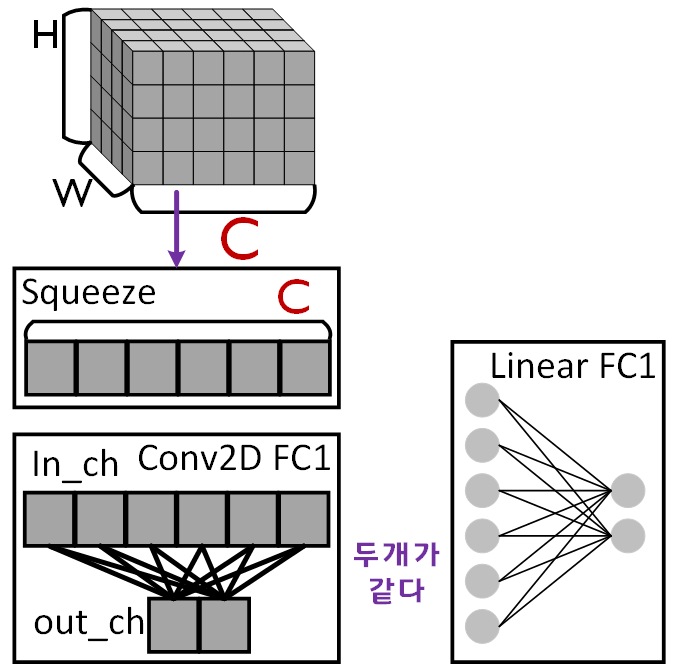
Squeeze Path의 nn.AdaptiveAvgPool2d((1, 1)) 메서드를 통해 (HxW) Feature가 (1x1)짜리 node로 변경되었기에
여기서부터는 [1x1]conv2d는 위 사진처럼 Linear연산이랑 동일해진다.
이렇게 되면 발생하는 장점이 Flatten연산을 [1x1]conv2d적용할 필요성이 없어지고, conv2d가 linear대비 GPU병렬연산에 좀 더 친화적이다.
따라서 위 과정을 통해서 코드 개선을 수행할 수 있다.
2️⃣ Attention Score를 계산하는 마지막 활성화 함수로
Sigmoid가 아닌 HardSigmoid적용
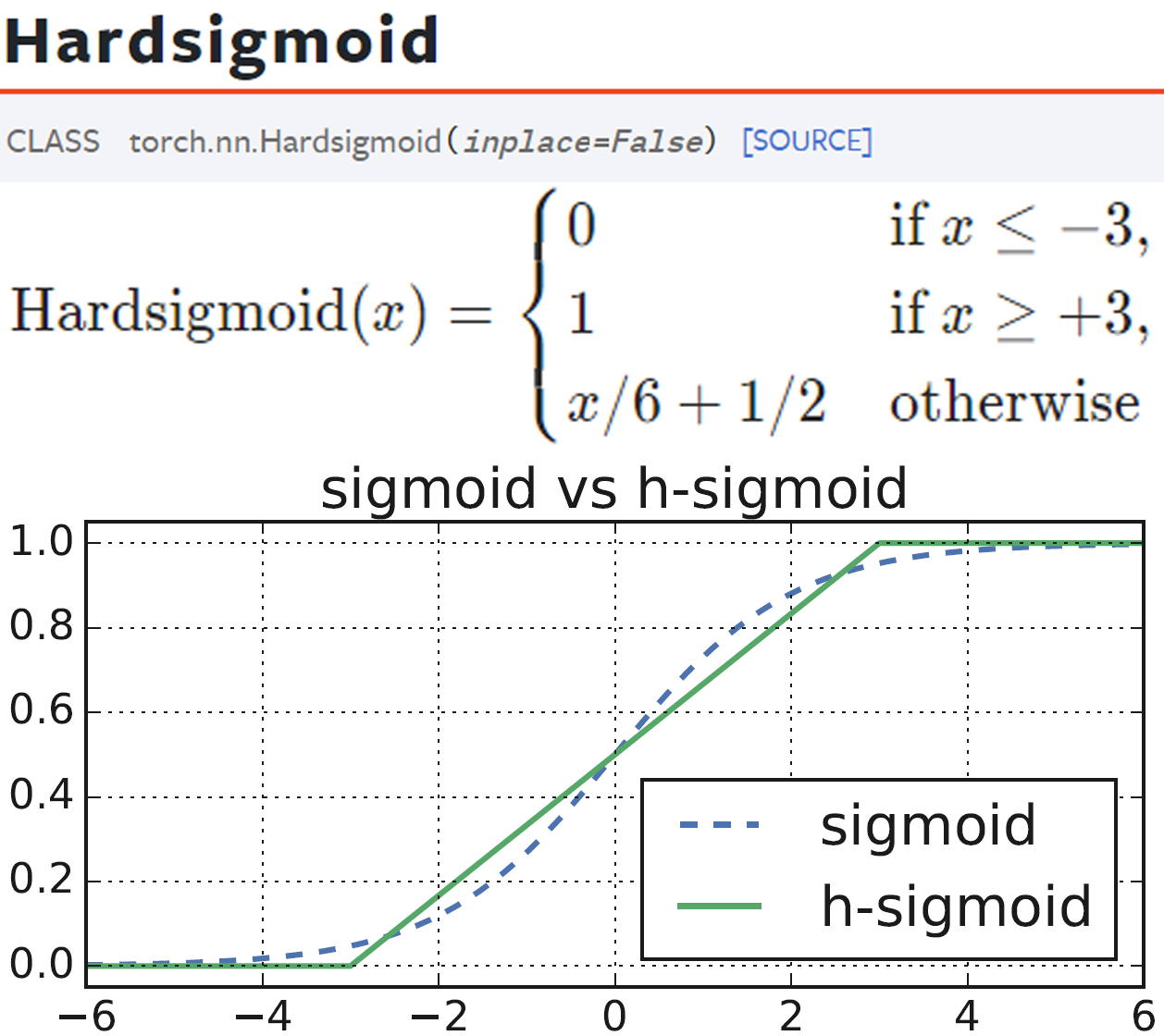
HardSigmoid는 위 사진에서 알 수 있듯이 ReLU6처럼 임베디드 환경에서 더 간편하게 연산이 가능한 활성화 함수다
따라서 MobileNet v3에는 Attention Score연산의 완성에 HardSigmoid를 적용한다.
2.3.4 MobileNet v3의 Bottleneck block
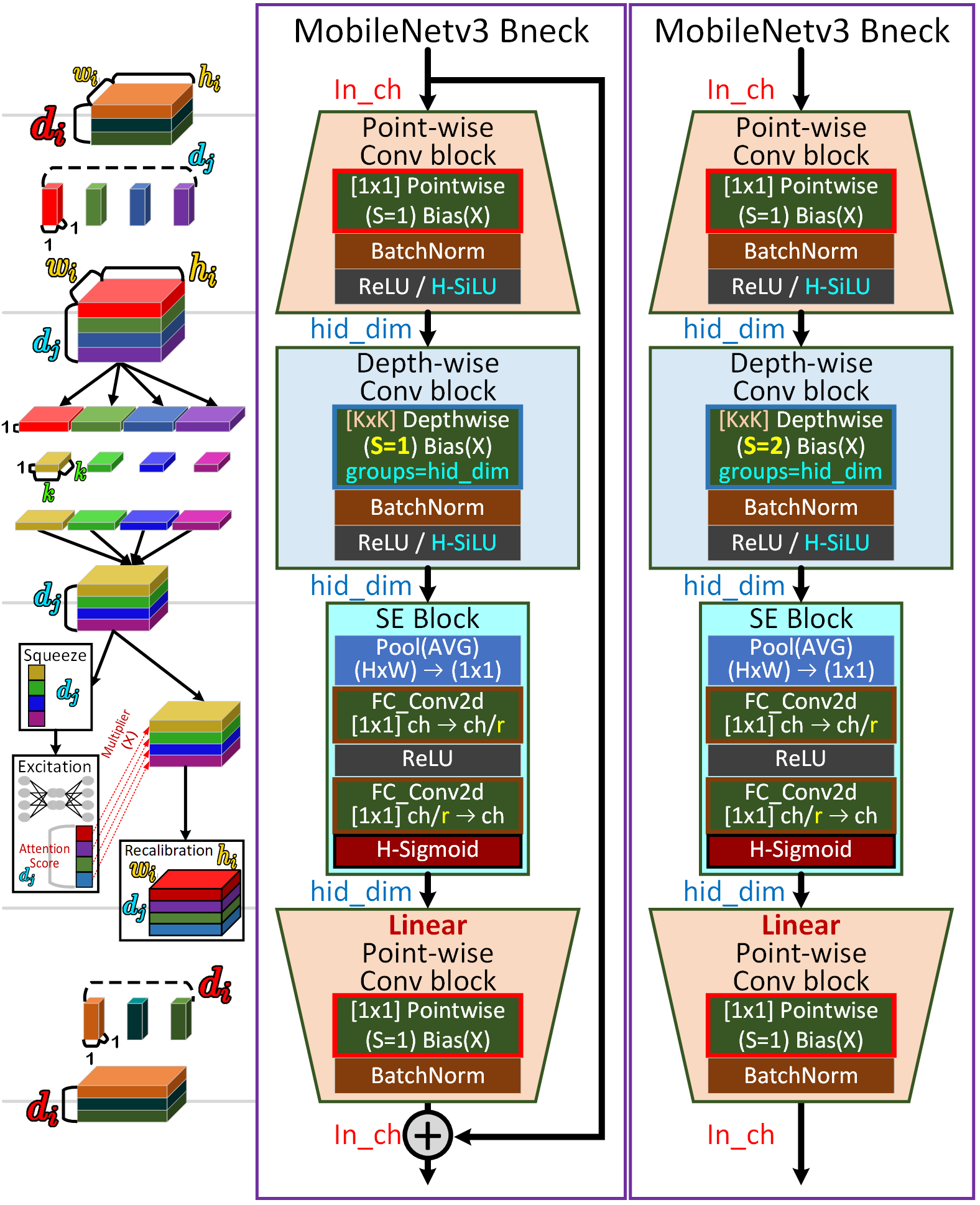
위 개선사항을 모두 적용한 MobileNet v3 Bneck 블럭의 구조는 위 그림으로 도식화 할 수 있으며
1️⃣NAS 최적화 방법에 따라 Depth-wise Conv의 Kenal_size가 3 or 5가 적용됨
2️⃣활성화 함수도 NAS 최적화 방법에 따라 ReLU or H-SiLU(Hard swish)가 적용됨
3️⃣SE block의 도입 (NAS에 따라 모든 블럭에 적용되는것은 아님)
이렇게 3가지의 주요 개선이 발생한다.
3. MobileNet v3 아키텍쳐
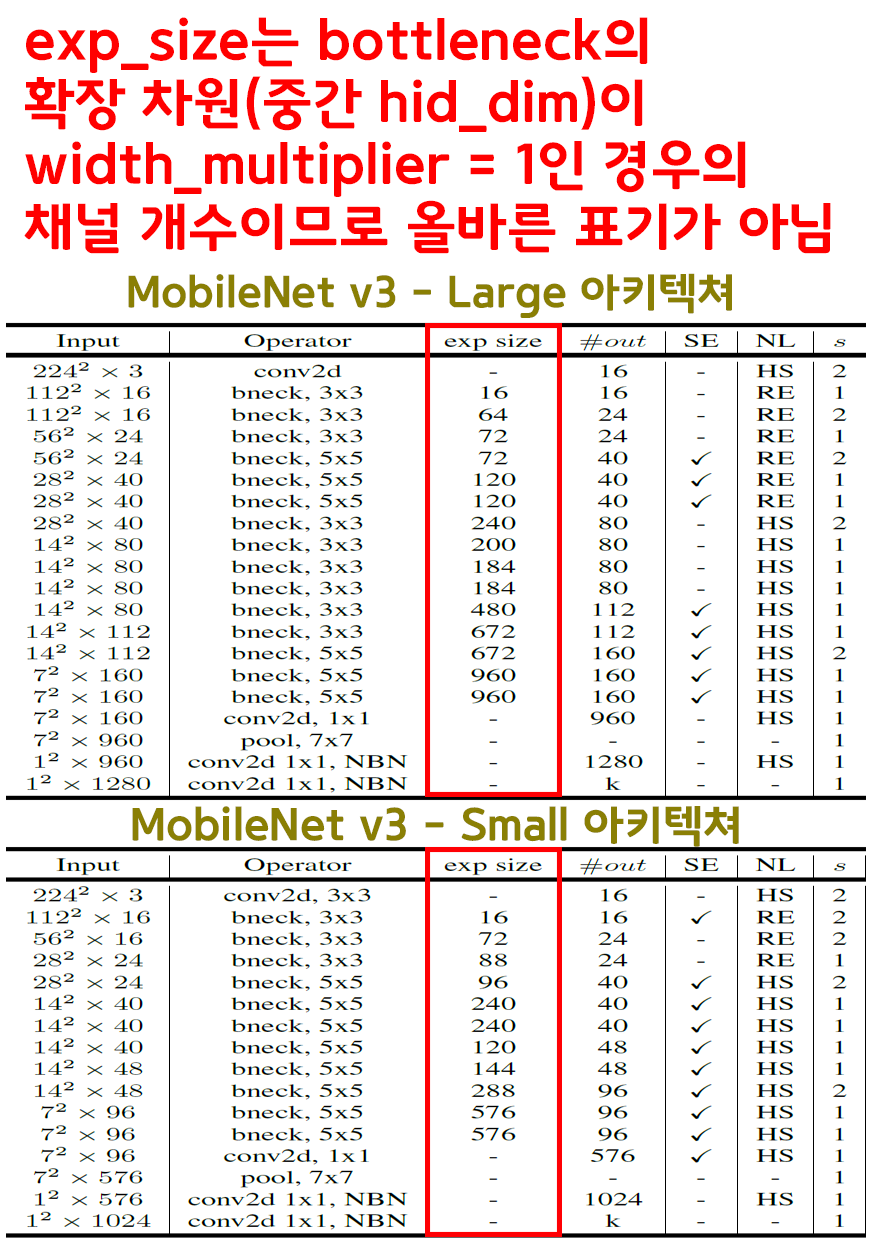
우선 논문에 기재된 고성능 버전(MobileNet v3 - Large), 저용량 버전(MobileNet v3 - Small)의 모델 아키텍쳐를 보면 열받는게
이전 모델 MobileNet v2의 모델 아키텍쳐 표기법을 또 갈아 엎은것도 문제지만 중대한 오류를 발생시키면서 갈아 엎은 문제가 있다.
바로 exp_size인데 MobileNet v3의 bneck block의 차원 확장 블럭인 Depth-wise conv block블럭의 hid_dim채널 개수 값이 기재되어있고
이게 골때리는게 Width multiplier = 1인 조건에서의 채널 개수값을 기재한 것이다.
Width multiplier는 당연히 하이퍼 파라미터에 속하는 가변인자값이고 그에 따라 hid_dim 채널 값이 조정받기에
MobileNet v2 처럼 ratio단위로 기재를 해야지 왜 뜬금없이 특정조건에서의 채널값을 기재하는지 이해하기 어렵다.

따라서 MobileNet v3-Large, MobileNet v3-Small의 아키텍쳐 표를 올바르게 다시 기재하고자 한다.
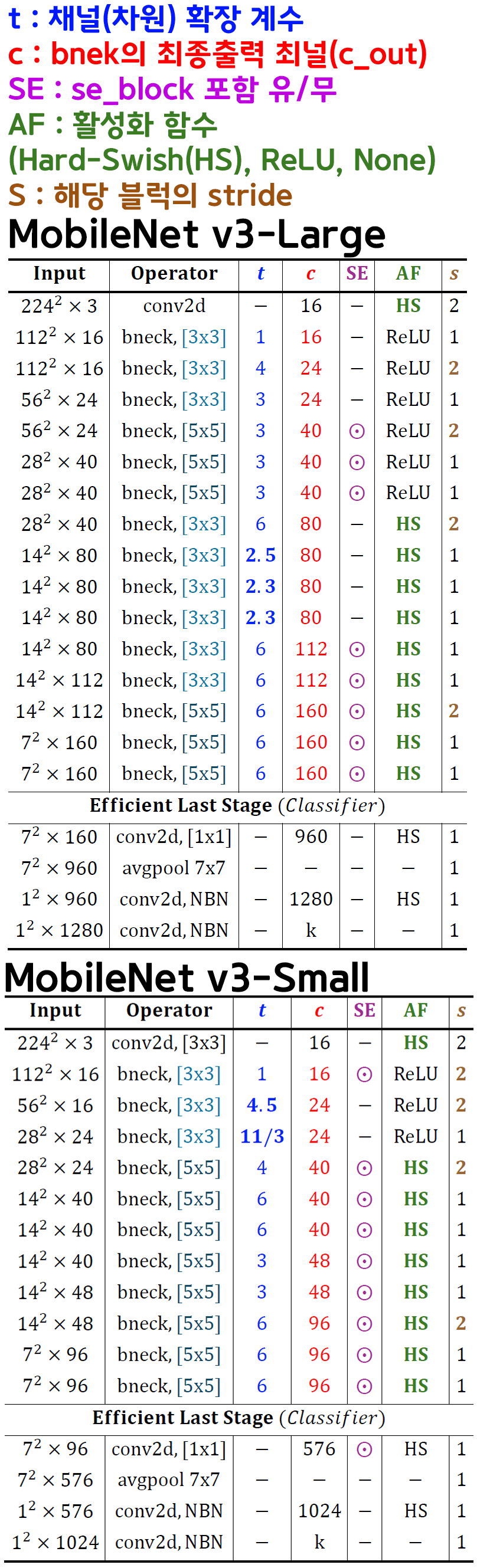
# 인자값 순서(Kernel, t, c, SE, AF, S)
# k: 커널사이즈(3x3 or 5x5)
# t: 확장 계수 (expand ratio)
# c: 출력 채널 수
# SE : SE블럭 삽입 유/무
# AF : 적용할 활성화 함수 종류
# s: 스트라이드 (S = 1 or 2)
# BN : Batchnormal 레이어 유/무
MobileNetV3_Feature_setting = {
'Large' : [
[
[3, 1, 16, False, 'RL', 1],
[3, 4, 24, False, 'RL', 2],
[3, 3, 24, False, 'RL', 1],
[5, 3, 40, True, 'RL', 2],
[5, 3, 40, True, 'RL', 1],
[5, 3, 40, True, 'RL', 1],
[3, 6, 80, False, 'HS', 2],
[3, 2.5, 80, False, 'HS', 1],
[3, 2.3, 80, False, 'HS', 1],
[3, 2.3, 80, False, 'HS', 1],
[3, 6, 112, True, 'HS', 1],
[3, 6, 112, True, 'HS', 1],
[5, 6, 160, True, 'HS', 1],
[5, 6, 160, True, 'HS', 1],
], #k, t, c, SE, AF, s
# Efficient Last Stage 인자값
[ #i_c, o_ch BN, SE, AF
[160, 960, True, False, 'HS'],
[960, 1280, False, False, 'HS'],
[1280, -1, False, False, None],
]
],
'Small' : [
[
[3, 1, 16, True, 'RL', 2],
[3, 4.5, 24, False, 'RL', 2],
[3, 11/3, 24, False, 'RL', 1],
[5, 4, 40, True, 'HS', 2],
[5, 6, 40, True, 'HS', 1],
[5, 6, 40, True, 'HS', 1],
[5, 3, 48, True, 'HS', 1],
[5, 3, 48, True, 'HS', 1],
[5, 6, 96, True, 'HS', 2],
[5, 6, 96, True, 'HS', 1],
[5, 6, 96, True, 'HS', 1],
], #k, t, c, SE, AF, s
# Efficient Last Stage 인자값
[ #i_c, o_ch BN, SE, AF
[96, 576, True, True, 'HS'],
[576, 1024, False, False, 'HS'],
[1024, -1, False, False, None],
]
]
}MobileNet v3-Large, MobileNet v3-Small는 모델 별로 복잡한 레이어 및 블록 세팅이 진행되니
세팅값을 위 코드처럼 딕셔너리로 따로 저장해서 사용하는게 제일 속편하다.
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, padding, AF=None, **kwargs):
super(BasicConv, self).__init__()
# padding='same'인 경우 padding 값 자동 계산
if padding == 'same':
padding = (kernel_size - 1) // 2
layers = [
nn.Conv2d(in_ch, out_ch, kernel_size=kernel_size,
padding=padding, bias=False, **kwargs),
nn.BatchNorm2d(out_ch)
]
# 활성화 함수는 총 3가지 조건으로 적용
# Default=None인 경우 활셩화 함수 적용 X
if AF == 'RL':
layers.append(nn.ReLU(inplace=True))
elif AF == 'R6':
layers.append(nn.ReLU6(inplace=True))
elif AF == 'HS':
layers.append(nn.Hardswish(inplace=True))
self.conv_block = nn.Sequential(*layers)
def forward(self, x):
x = self.conv_block(x)
return xMobileNet v3의 가장 기본 모듈인 BasicConv는 MobileNet 계열의 네트워크가 발전하면서 활성화 함수를 여러 종류를 사용하기에
아에 MobileNet v1도 호환이 가능하도록 코드를 작성했다.
class SEBlock(nn.Module):
def __init__(self, ch, reduction=4):
super(SEBlock, self).__init__()
# Squeeze 단계: 채널의 글로벌 정보 획득
self.squeeze_path = nn.AdaptiveAvgPool2d((1, 1))
# Excitation 단계: 채널 중요도 계산
# (H, W)가 모두 (1,1)되었기에 [1x1]nn.conv2D는 nn.Linear와
# 같은 연산 결과를 기대할 수 있게 됨
# 여기서 [1x1]conv2d는 flatten을 안써도 되고 병렬연산에 더 친화적
# 따라서 FC layer은 동일연산의 [1x1]conv2d로 변경
self.excitation_path = nn.Sequential(
nn.Conv2d(ch, ch//reduction, 1), # 채널 크기 감소
nn.ReLU(inplace = True), # 비선형성 추가
nn.Conv2d(ch//reduction, ch, 1), # 채널 크기 원상 복원
nn.Hardsigmoid(inplace = True) # 중요도 계산
)
def forward(self, x):
# 1. Squeeze 단계: (BS, C, H, W) -> (BS, C, 1, 1)
y = self.squeeze_path(x)
# 2. Excitation 단계: Attention Score를 적용한 (BS, C, 1, 1)
y = self.excitation_path(y)
# 3. Recalibration 단계: 채널별 중요도(Attention Score)
# 를 입력 텐서에 곱함, 여기서 expands_as로 (bs, ch, H, W) 확장
Recalibration = x * y.expand_as(x)
return RecalibrationMobileNet v3의 주요 개선사항이라 볼 수 있는 SEBlock코드는 앞서 언급한대로 FC layer은 [1x1] Conv2D로 구현했다.
class BNeckBlock(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, stride, expand_ratio,
AF=None, SE=False):
super(BNeckBlock, self).__init__()
# 중간 블럭의 채널개수(차원)은 확장계수로 조정됨
hidden_dim = int(in_ch * expand_ratio)
# Residual Connection이 활성화되는 조건
self.use_residual = (stride == 1 and in_ch == out_ch)
layers = [] #쌓을 레이어를 리스트에 담음
if expand_ratio != 1:
# 확장 단계 : 커널 사이즈가 1 + 채널크기가 변경되는 Point-wies Conv
layers.append(BasicConv(in_ch, hidden_dim, kernel_size=1,
stride=1, padding=0, AF = AF))
# Depthwise Conv -> groups 옵션을 사용하여 커널을 그룹별로 적용
layers.append(BasicConv(hidden_dim, hidden_dim,
kernel_size=kernel_size,
stride=stride, padding='same',
AF = AF, groups=hidden_dim))
if SE: # SE_block옵션이 True이면 SEblock를 추가한다
layers.append(SEBlock(hidden_dim))
# 축소단계 : 확장한 채널을 다시 감소시킴, 이때 활성화함수 적용X
# 이 부분 선형 Point-wise Conv이다.
layers.append(BasicConv(hidden_dim, out_ch, kernel_size=1,
stride=1, padding=0, AF = None))
self.res_block = nn.Sequential(*layers)
def forward(self, x):
if self.use_residual:
return x + self.res_block(x)
else:
return self.res_block(x)MobileNet v3의 Bneck Block은 사실상 MobileNet v2의
Inverted Residual Bottelneck Block에서 SE_Block 추가 및 활성화 함수 선택폭이 확장된 수준이다.
물론 레이어 조정 조건이 늘어난 만큼 코드가 조금 복잡해졌으며, MobileNet v2에도 호환되게 코드를 작성했다.
class LastStage(nn.Module):
def __init__(self, alpha=1.0, classifier_set = None,
num_classes=1000):
super(LastStage, self).__init__()
layers = []
for in_ch, out_ch, BN, SE, AF in classifier_set:
in_ch = int(in_ch * alpha)
if out_ch > 0:
out_ch = int(out_ch * alpha)
else:
out_ch = num_classes
layers.append(nn.Conv2d(in_ch, out_ch, kernel_size=1,
stride=1, padding=0, bias=False))
if BN: #Batch_norm 이 있으면 해당 레이어 추가
layers.append(nn.BatchNorm2d(out_ch))
if SE: #SE_block이 있으면 해당 블럭 추가
layers.append(SEBlock(out_ch))
# 활성화 함수는 조건별로 삽입
if AF == 'RL':
layers.append(nn.ReLU(inplace=True))
elif AF == 'R6':
layers.append(nn.ReLU6(inplace=True))
elif AF == 'HS':
layers.append(nn.Hardswish(inplace=True))
# 완성된 Layers 리스트의 1번째 자리에 AvgPool 넣기
layers.insert(1, nn.AdaptiveAvgPool2d((1,1)))
# 가장 마지막 레이어에 Flatten 레이어 넣기
layers.append(nn.Flatten())
self.Last_stage_block = nn.Sequential(*layers)
def forward(self, x):
x = self.Last_stage_block(x)
return x위 코드는 MobileNet v3의 NAS방법론을 통해 개선한 블럭인
Efficient Last Stage를 따로 클래스로 모듈화하여 구현한 코드이다.
Efficient Last Stage는 사실상 Classifier의 기능을 수행하는 코드이며, MobileNet v2도 원래 정석으로는 가장 마지막 블럭인 Classifer을 위와 같이 Last Stage 코드로 작성해야 더 병렬처리에 친화적으로 코드 구동이 가능하다.
class MobileNetV3(nn.Module):
def __init__(self, width_multiplier=1.0, Feature_ext_set = None,
num_classes=1000):
super(MobileNetV3, self).__init__()
#네트워크 각 층의 필터 개수를 조정하는 인자값
self.alpha = width_multiplier
# stem의 out_ch이자 Feature_ext의 Start in_ch
in_ch = int(16*self.alpha)
self.stem = BasicConv(3, in_ch, kernel_size=3,
stride=2, padding=1, AF='HS')
blocks = []
# 레이어 설계 세팅값이 정상적으로 들어올 경우 기동
if len(Feature_ext_set[0][0]) == 6:
for k, t, c, SE, AF, s in Feature_ext_set[0]:
out_ch = int(c * self.alpha)
blocks.append(BNeckBlock(in_ch=in_ch, out_ch=out_ch,
kernel_size=k, stride=s,
expand_ratio=t, AF = AF, SE = SE))
in_ch = out_ch # 세팅된 블럭 추가 후 in_ch업데이트
self.feature_ext = nn.Sequential(*blocks)
self.classifier = LastStage(self.alpha, Feature_ext_set[1],
num_classes)
def forward(self, x):
x = self.stem(x)
x = self.feature_ext(x)
x = self.classifier(x)
return x코드가 지저분해질만한 항목들은 전부 모듈로 분리를 했고
복잡한 아키텍쳐 블록 별 설정값은 MobileNetV3_Feature_setting으로 한번에 관리하기에 최종 MobileNet v3부모코드는 꽤 간결하게 작성하는 것이 가능하다.
3.1 간단 성능평가
이전 포스트 26. 주요 CNN알고리즘 구현 : MobileNet v2 (1) - 인공지능 고급(시각) 강의 복습,
23. 주요 CNN알고리즘 구현 : MobileNet (1) - 인공지능 고급(시각) 강의 복습에서
MobileNet v2, MobileNet v1를 너무 빡세게 파생 네트워크 별로 성능평가를 진행했기에 MobileNet v3까지 동일하게 성능평가를 하는건 비효율적이라 생각한다.

절대 하기 싫어서 안하는게 아니다...
따라서 width multiplier=1, resolution multiplier=224으로만 간단하게 성능평가하고 턴을 종료하려 한다.
사용 데이터셋은 이전과 동일하게 Animlas-10으로 한다.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MobileNetV3(1, MobileNetV3_Feature_setting['Large'], 1000).to(device)# 데이터 전처리 방법론 정의
from torchvision.transforms import v2
animals_val = {'mean' : [0.5177, 0.5003, 0.4126],
'std' : [0.2133, 0.2130, 0.2149]
}
def define_transform(img_size, normal_val, augment=False):
transform_list = []
if augment:
transform_list += [ #데이터 증강은 반전, 색상밝기채도, 아핀 3가지
v2.RandomHorizontalFlip(p=0.5),
v2.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4,
hue=0.1),
v2.RandomAffine(degrees=(30, 70),
translate=(0.1, 0.3),
scale=(0.5, 0.75)),
]
transform_list += [
v2.Resize((img_size, img_size)), #이미지 사이즈별로 리사이징
v2.ToImage(), #이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=normal_val['mean'], std=normal_val['std']) #데이터셋 표준화
]
return v2.Compose(transform_list)train_transform = define_transform(img_size=224, normal_val=animals_val, augment=True)
val_transform = define_transform(img_size=224, normal_val=animals_val, augment=False)import os
from torchvision import datasets
from torch.utils.data import DataLoader
root = './Animals-10'img_dataset = {}
img_dataloader = {}
img_dataset['train'] = datasets.ImageFolder(os.path.join(root, 'train'),
transform=train_transform)
img_dataset['val'] = datasets.ImageFolder(os.path.join(root, 'val'),
transform=val_transform)
bs = 192
img_dataloader['train'] = DataLoader(img_dataset['train'],
batch_size=bs, shuffle=True)
img_dataloader['val'] = DataLoader(img_dataset['val'],
batch_size=bs, shuffle=False)import torch.optim as optim
#손실함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
num_epoch = 10 #총 훈련/검증 epoch값
ES = 2 # 디스플레이용 에포크 스텝
# BC_mode = True(이진), False(다중)
# aux = 보조분류기 유/무
# wandb = 완디비에 연결 안하면 None
trainer = ModelTrainer(epoch_step=ES, device=device, BC_mode=False, aux=False)for epoch in range(num_epoch):
train_loss, train_acc = trainer.model_train(
model, img_dataloader['train'],
criterion, optimizer, epoch
)
val_loss, val_acc = trainer.model_evaluate(
model, img_dataloader['val'],
criterion, epoch
)
# Epoch_Step(ES)일때 print하기
if (epoch+1) % ES == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
4. 코드배포
MobileNet v3, MobileNet v2, MobileNet v1
3개 모델을 다 구현해보고 실험도 해봣으니 각 버전별로 모델 인스턴스화가 가능한 통합 코드를 배포하고자 한다.
https://github.com/tbvjvsladla/MobileNet_pytorch
작성한 코드는 위 깃허브에 업로드 하였으며
사용방법은 아래와 같다
from mobile_net import MobileNetV1, MobileNetV2, MobileNetV3, V3_setting, V2_setting, V1_setting, mobile_debug# 임의의 MobileNet계열 모델 인스턴스화
exam_model = MobileNetV3(1, V3_setting['Large'], 1000)# 모델 성능 측정
mobile_debug(exam_model, 192)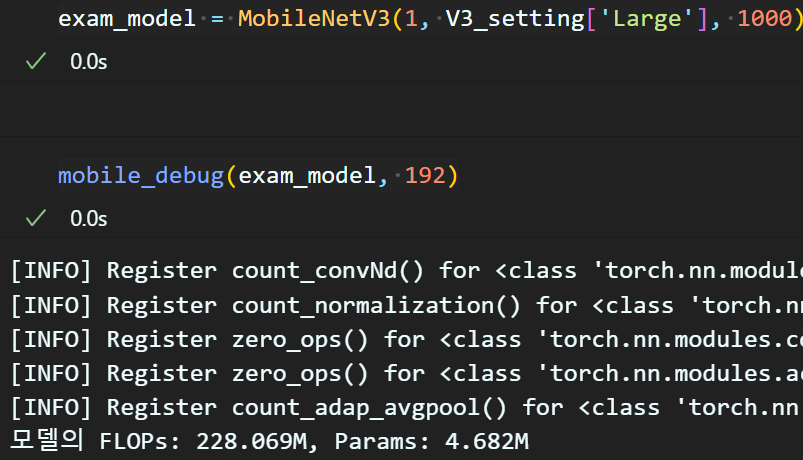
MobileNet v3, MobileNet v2, MobileNet v1 모델별로
구현 및 간단 성능측정은
mobile_net.py의 main구문을 참조 바란다.
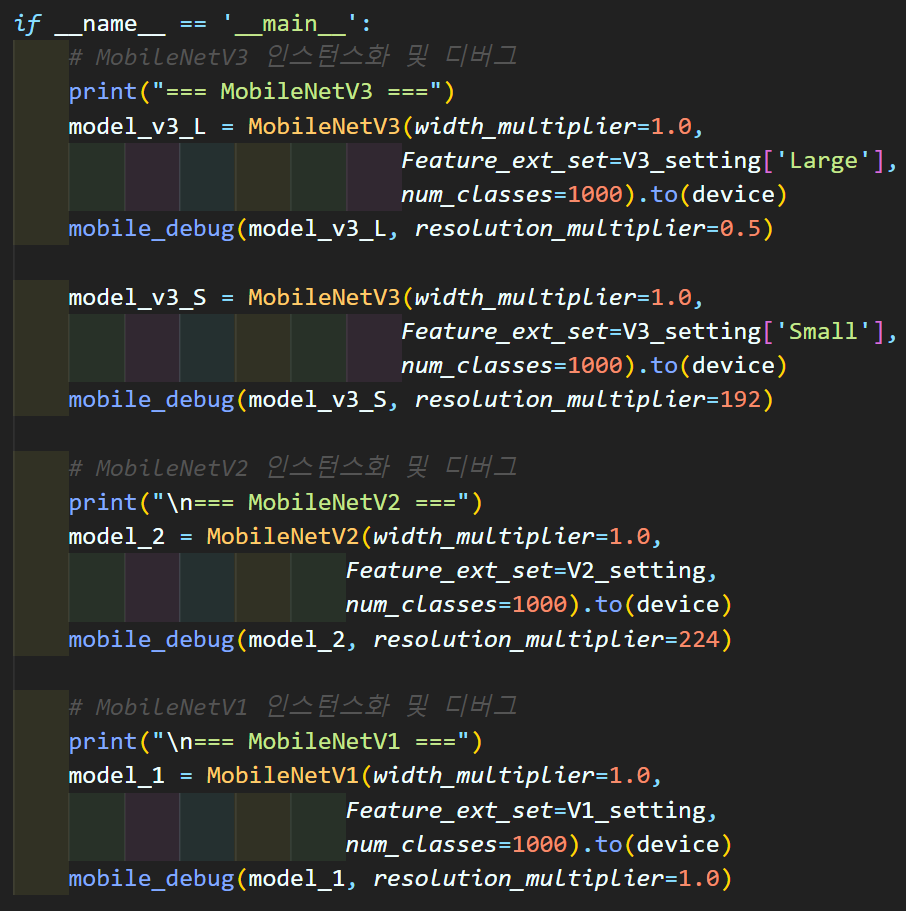
종류별로 인스턴스화가 가능하게 파일을 배포한다.

버전 3개를 내리 코드실습하니까 어질어질하다;;;
