
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. MobileNet v2 개요
이전 포스트 23. 주요 CNN알고리즘 구현 : MobileNet (1) - 인공지능 고급(시각) 강의 복습에서 언급한 MobileNet을 개발한 Google팀이 기존 모델을 개선하여 더 원할하게 임베디드 디바이스 및 모바일 장치에서 CV작업을 수행할 수 있도록 개선한 경량 심층 신경망이 MobileNet v2이다.
따라서 MobileNet의 주요 설계 기법(경량화 기법)인
1) DSC(Depthwise Separable Convolutions)
2) Width & Resolution Multiplier(, )
은 그대로 적용하면서
Inverted Residual Bottelneck Block이란 특별한 레이어 블럭을 제안한다.
이 블럭은 ResNet의 핵심 구조인 Residual block, Bottleneck을 합성한
Residual Bottleneck Block에 DSC를 적용하고, 적용 과정에서 모델의 연산복잡도와 성능을 최대한 최적화 할 수 있는 방안을 연구하다 보니 Inverted, 차원 축소 블럭에서는 활성화 함수 사용없이 선형변환 수행 등..
아주 딥러닝 모델 설계에 있어 골때리게 어려운 여러가지 개념들을 체득한 사람들이나 이해할 수 있는 원리를 집약하고 체화한 사람들이나 생각 할 수 있는 아이디어를
Inverted Residual Bottelneck Block로 구현한 것이다.
그래서 코드를 본다면 그렇게 어려운 부분은 존재하지 않는다.
ResNet의 ResNet-101, ResNet-152에 사용되는 기본 블럭인
Residual Bottleneck Block를 Pytorch로 구현해 봤다면
Inverted Residual Bottelneck Block를 코드화 하는건 어렵지 않다.
문제는 왜Inverted Residual Bottelneck Block이 블럭이 성능은 좋으면서 연산량을 최적화 하는지 그걸 설명하는게 어렵고
설명을 마치고 나면 이런 논리적인 베이스가 있는 사람만이 생각할 수 있는 아이디어구나..
라는 생각이 들 뿐인 것이다.

약간 이런 느낌이다.
왜 Inverted Residual Bottelneck Block이 연산량은 줄어들면서 성능은 그대로 유지가 되는지에 대한 설명은 길고 장황하고 어렵고 이것저것 다른 개념을 알아야 하지만
코드로 구현하면 몇줄 안되는 짧은 블럭 하나...
아무튼 MobileNet v2는 MobileNet와 비교했을 때 동일한 연산Cost라면 5~7% 더 높은 정확도를 보여준다.
2. Inverted Residual Bottleneck 구조
MobileNet v2의 핵심 구조라 볼 수 있는 Inverted Residual Bottelneck Block는 설계 기반 개념을 설명하기 보다는 코드와 구조를 먼저 설명 후 왜 이런 코드와 구조로 만들어 지는지 설명하고자 한다. (이래야 마음이 편해진다)
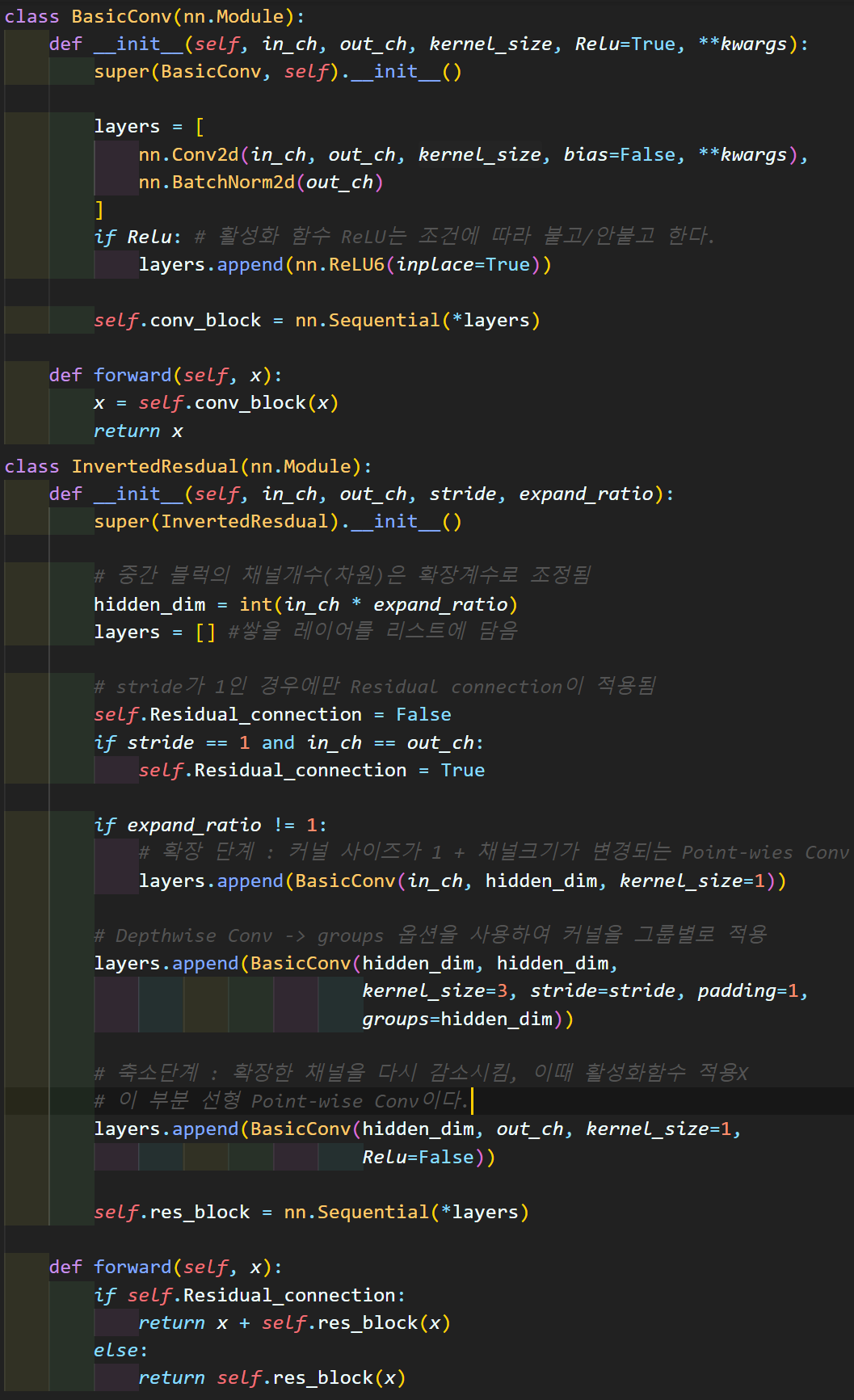
코드를 붙여넣었지만 도식으로 표현하면 아래와 같다.
우선 첫번째로 BasicConv은 두가지 버전이 있으며, 차이는 Relu 활성화 함수가 마지막 레이어 층에 붙어있는지의 유/무이다.
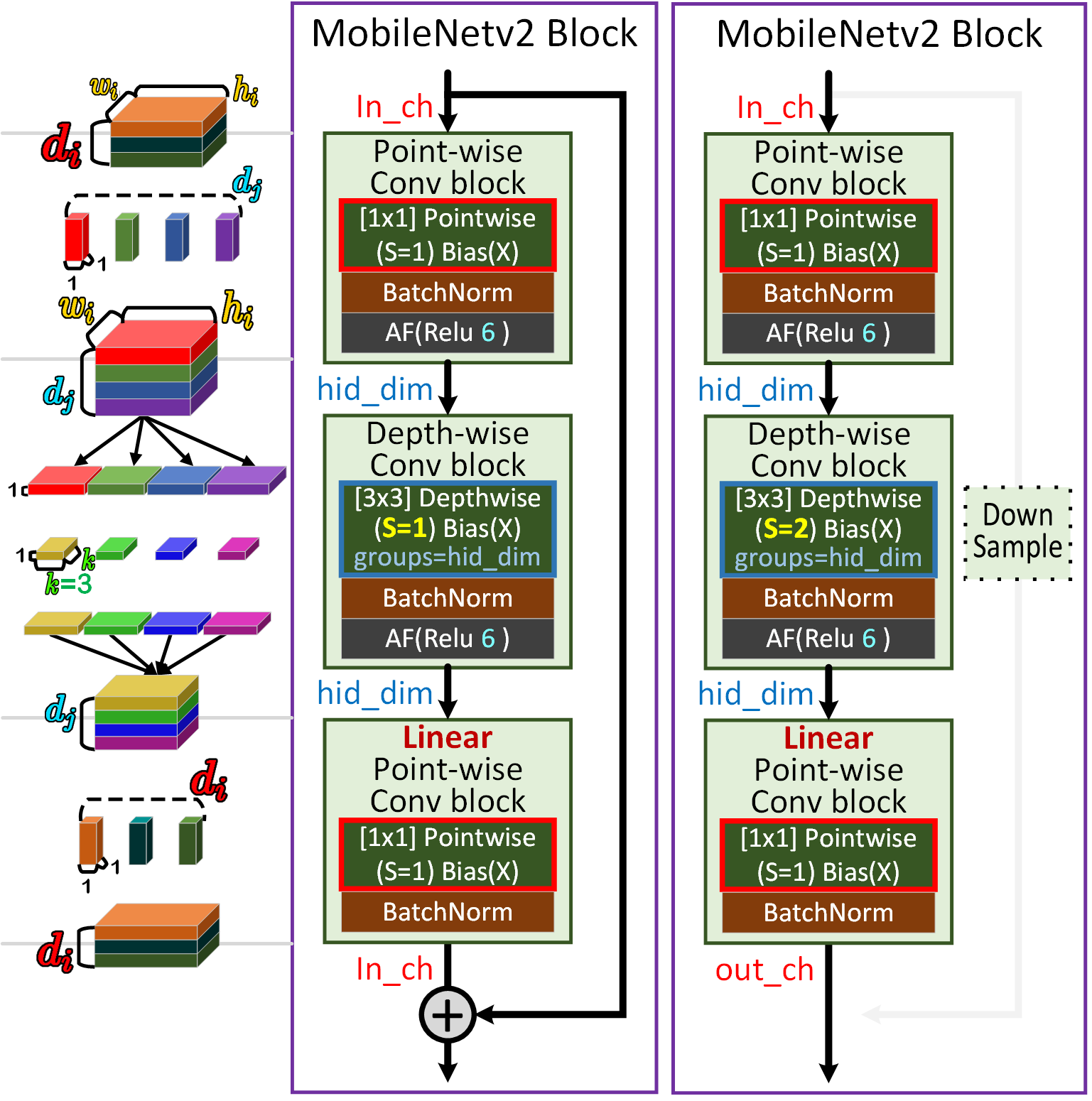
위 BasicConv를 바탕으로 Inverted Residual Bottelneck Block이 설계되는데 주요 차이점은 가운데 확장(Depth-wise Conv)블럭 인자값이 Stride=2인 경우에는 Residual Connection이 비활성화 된다.
통상적으로 Residual block에서 Stride=2가 적용됨으로 인해 in_ch와 out_ch이 차이가 발생하는 경우에는 Down Sample Conv를 적용해서 보정하는데 MobileNet v2에서는 Residual Connection을 날려버리는 선택을 했다.
그리고 DSC(Depthwise Separable Convolutions)는
Point-wise Depth-wise LinearPoint-wise 이렇게 3가지 항목으로 나뉘어서 각각 DSC가 적용되고 있음을 알 수 있다.
구조에 대한 설명을 진행했으니 이제 의문점을 해소할 시간이다.
2.1 기존 Bottleneck 구조와 차이점
우선 ResNet에 적용된 Residual Bottleneck 구조와
MobileNet v2의 Inverted Residual bottleneck 구조를 그림으로 비교하면 아래의 두가지 주요 차이점이 발생한다.
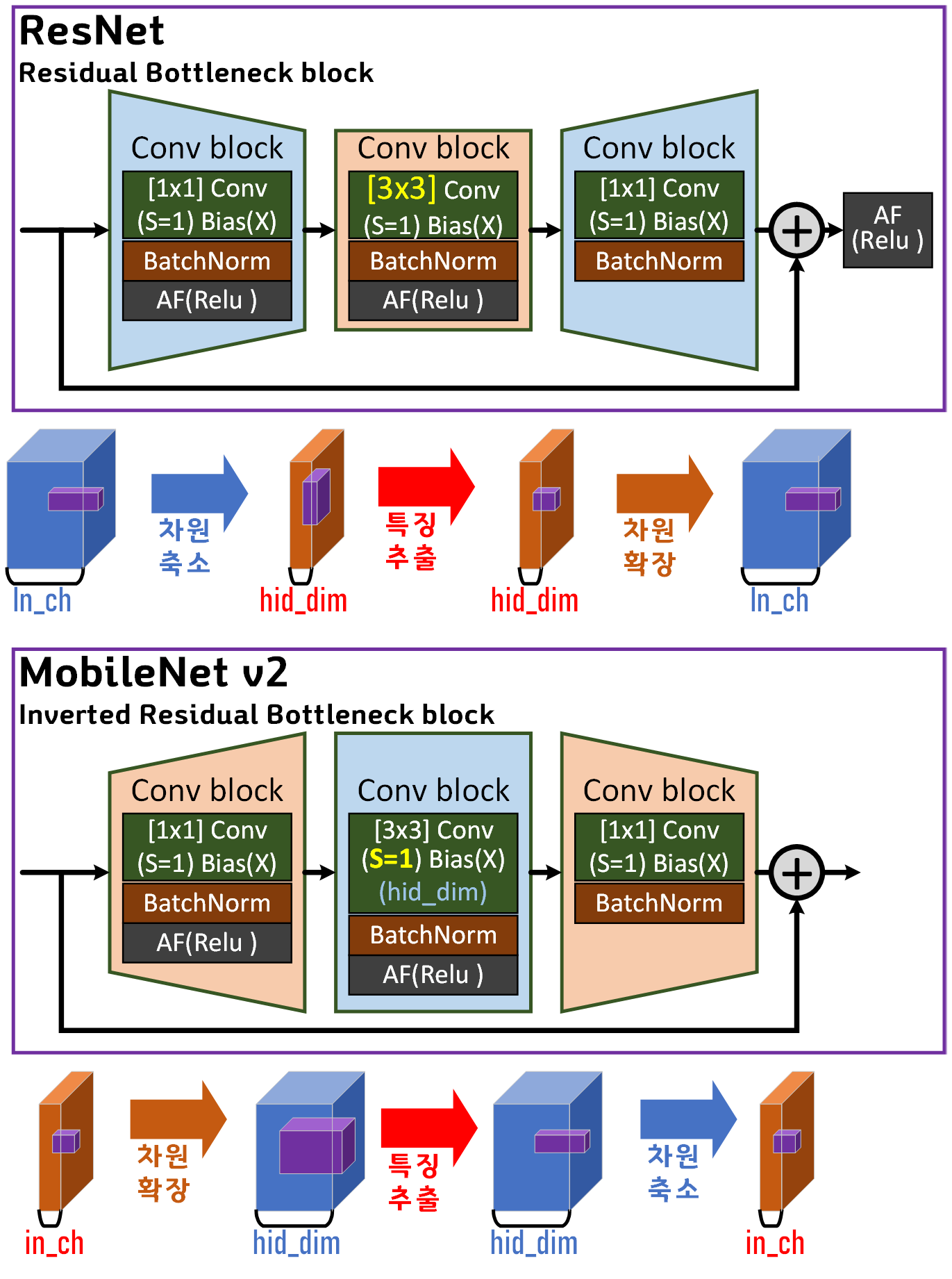
1) ResNet는 차원을 축소한 뒤 특징을 추출하지만,
MobileNet v2는 차원을 확장하여 고차원 환경에서 특징을 추출한다.
2) MobileNet v2는 차원을 축소한 마지막 Feature에 대하여
Activation Layer를 적용하지 않는다.
2.1.1 1번 구조 차이 해석
첫번째로 ResNet의 Residual block에 Bottleneck 구조를 도입하는 이유는 연산코스트를 줄이면서도 충분히 특징 정보를 추출할 수 있는 장점이 있어서이다.
이때 연산코스트가 가장 기본 Conv연산인
Standard Conv block의 연산코스트를 비교해보자
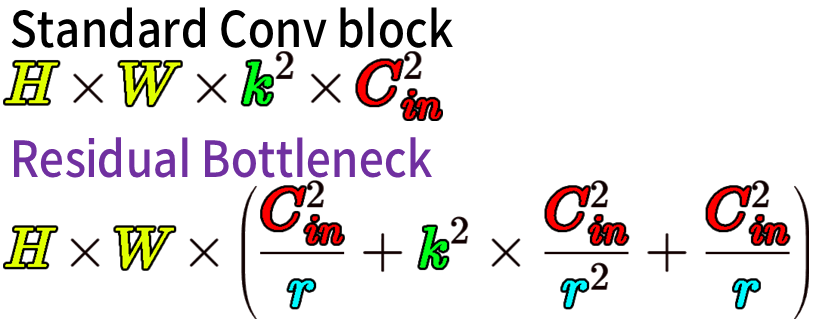
위 수식에서 k=kernel_size, 1/r = Reduction ratio(축소계수)이고
입력 채널과 출력 채널은 동일하다 가정했을 때 (C_in = C_out)
위 도식으로 줄어드는 계산 비용은
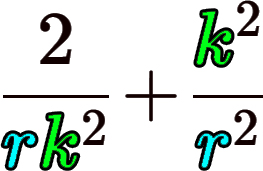
으로 ResNet에 적용된 계수값k=3, r=4 이면 약 8.5배 연산 cost 감소가 발생한다.
문제는 Residual block에 Inverted Bottleneck 을 적용하게 되면
1/r = Reduction ratio r = Expension ratio(확장 계수)로 역수가 되기에
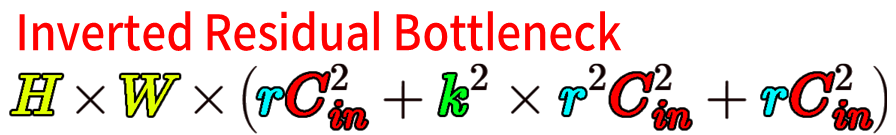
오히려 연산 cost가 증가하는 불상사가 발생한다.
여기서 증가하는 연산 cost을 억제하는 용도로 Depth-wise Conv가 적용된다.
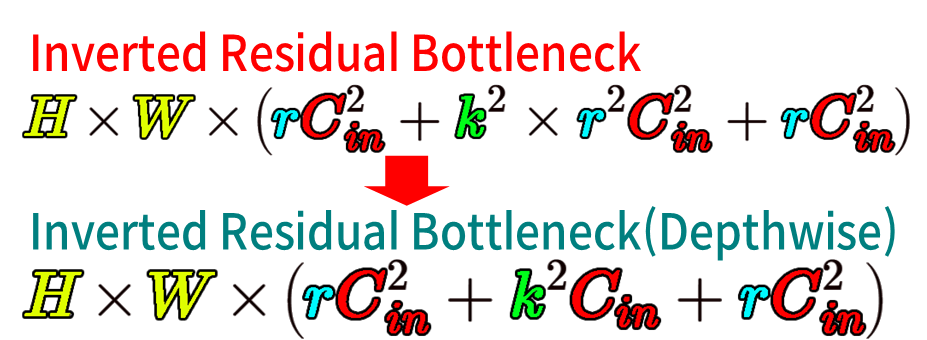
따라서 Standard Conv block대비
MobileNet v2에 적용된 Inverted Residual Bottelneck Block의
연산 Cost는
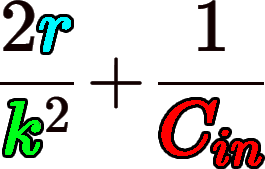
으로 k=3, r=4로 가정하면 얼추 1.1배 연산 코스트 감소를 기대할 수 있다.
그럼 여기서 드는 의문이 있다.
그냥 ResNetResidual Bottleneck block을 적절히 응용해서 MobileNet v2에 적용하면 될거 같은데
궂이 Inverted Residual Bottelneck Block을 만들고 연산 Cost가 늘어나니까
이걸 Depth-wise Conv를 적용시켜서 억제시켜
사실상 Inverted Residual Bottelneck Block (with Depthwise)인 복잡한 구조는 왜 만드는 것일까?
이는 ResNet과 MobileNet v2전체 모델 구조를 비교해 봐야 납득이 된다.
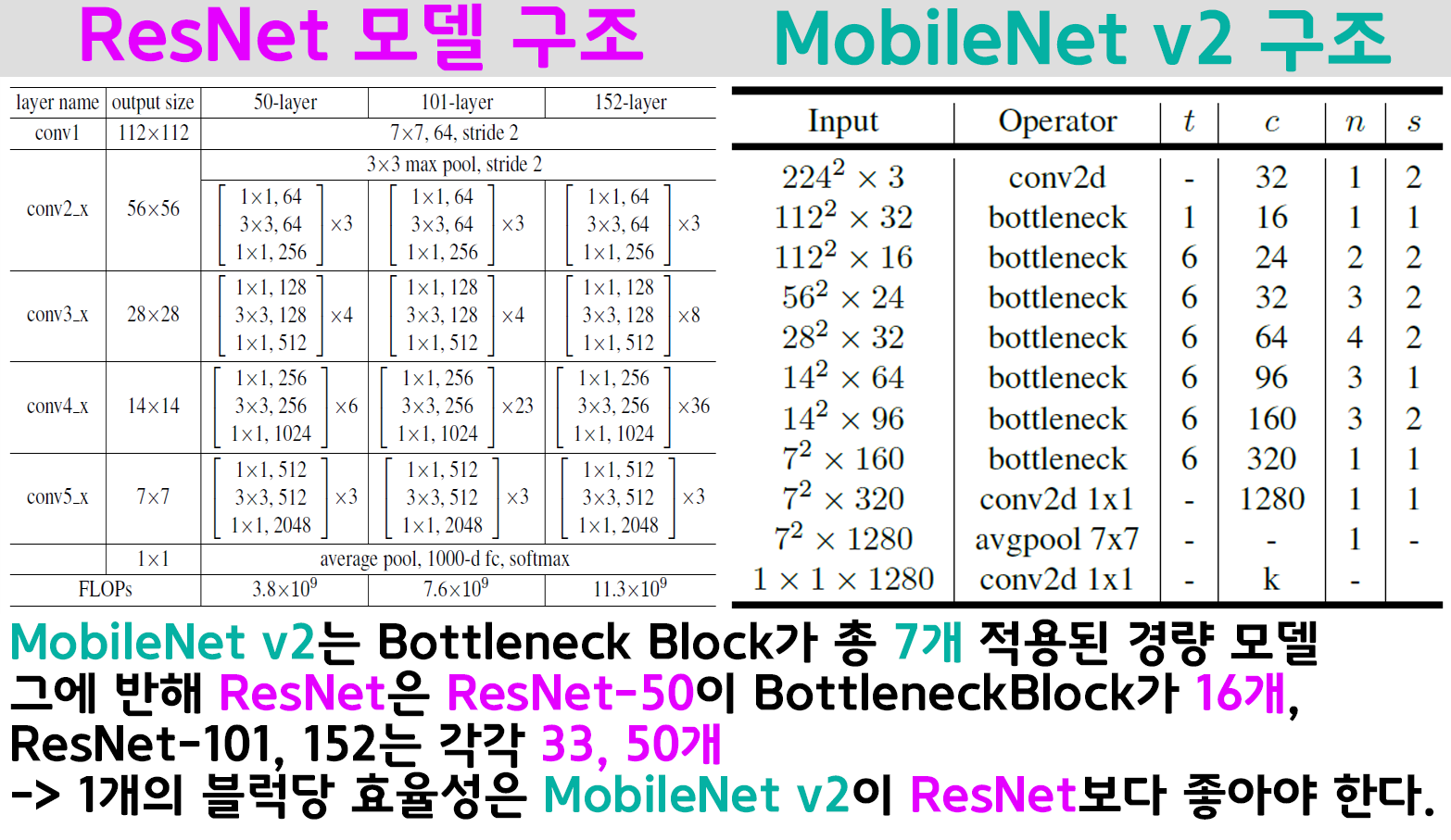
MobileNet v2의 전체 구조를 보면 Bottleneck block가 총 7개 (첫번째 블럭은 확장계수가 1이기에 사실상 6개)이고
ResNet은 Bottleneck block이 각각 16, 33, 50개가 적용된 모델이다.
따라서 MobileNet v2은 층의 깊이(Depth)를 줄이면서 한 층당의 효율을 높여야 하니 너비(Width)가 늘어나는 선택압을 받았다 볼 수 있다.
하지만 이전 포스트 24. 주요 CNN알고리즘 구현 : ResNeXt (1) - 인공지능 고급(시각) 강의 복습에서도 설명했듯이
ResNet 계열의 모델은 Width가 늘어나면 연산 코스트가 기하급수적으로 늘어나는 문제점이 있다.
이를 MobileNet v2은 Depth-wise Conv를 중간레이어에 적용함으로써
연산코스트의 증가를 억제한 것이다.
이렇게 Width 가 늘어나는 것은 고 차원에서 입력된 Feature의 특징을 추출하기에 더 많은 특징정보의 추출이 발생하고
전반적인 Feauture의 표현력이 증가하는 효과를 기대할 수 있다.
2.1.2 2번 구조 차이 해석
두번째로 Inverted Residual Bottelneck의 가장 마지막 레이어에는
Activation Function인 ReLU를 적용하지 않았다.
이는 MobileNet v2 뿐만 아니라 대다수의 CNN계열 활성화 함수에 적용되는 ReLU ReLU6, Leaky Relu의 비선형성을 다시 확인해야 한다.
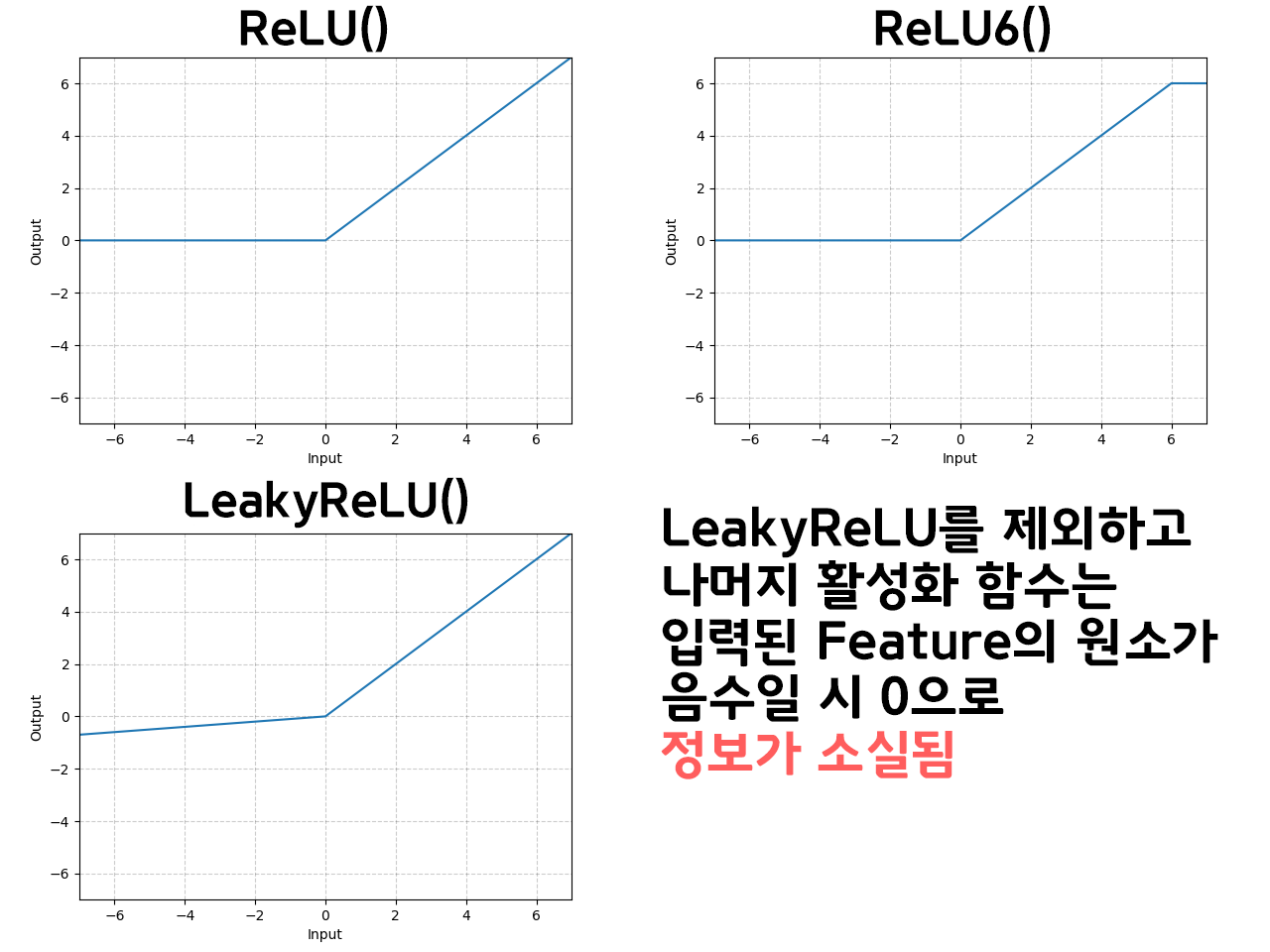
위 음수로 이뤄진 정보는 소실되는 문제가 특히
저차원(채널 개수가 적은 Feature)에서는 정보 소실문제가 두드러지게 발생하기에 부득이하게 ReLU를 Inverted Residual Bottelneck의 가장 마지막 레이어에 적용하지 아니했다. 라고 논문에서 언급하고 있다.
그래서 논문에서는 어떤 실험을 수행했는데 실험의 개요 및 결과는 아래와 같다.
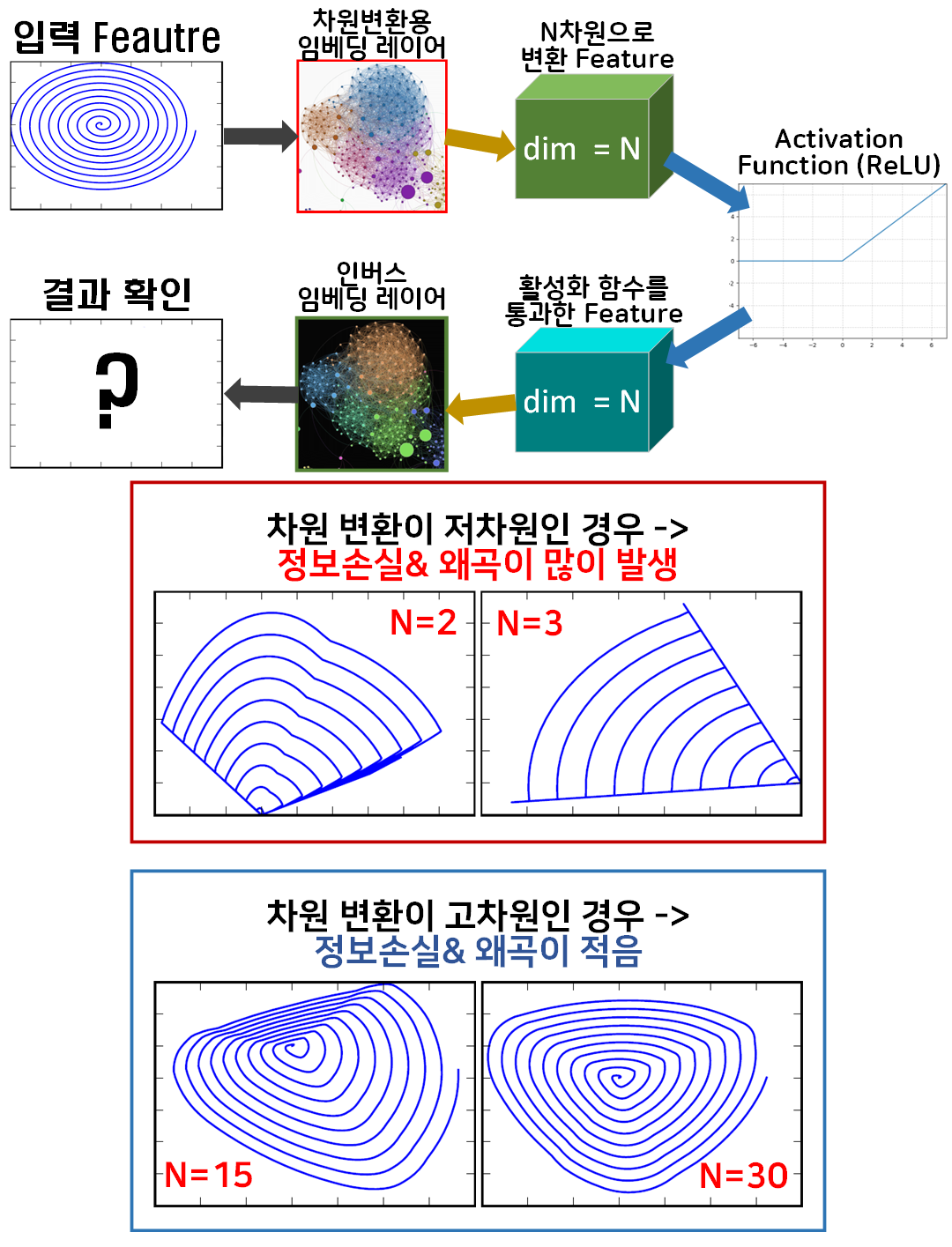
임의의 Feature를 생성하고(해당 Feature에는 다양한 원소값이 있으며, 논문의 실험에서는 원소군집이 나선형 구조로 모여 있음)
이를 차원변환을 위한 임베딩 레이어로 통과시켜서
N차원으로 차원 확장(축소)를 수행한다.
그 다음 N차원 Fature를 Activation Function(ReLU)로 통과시켜 비선형 Feature로 활성화 한 뒤
다시 원래 차원으로 원복되는 인버스 임베딩 레이어를 통과시켜 그 결과물을 Origin과 비교해보는 실험을 수행한 것이다.
실험결과를 본다면 임베딩 레이어가 매우 높은 고차원으로 차원확장을 수행한 결과물은
임베딩레이어의 차원변환수가 낮은 저차원으로 차원변환(축소)를 수행한 결과물과 비교했을 때
정보손실이 덜 하다라는 결과를 얻었다.

그러나 필자가 보기에는 조금 끼워맞추는 식으로 논리를 전개한게 아닌가 하는 생각이 든다.
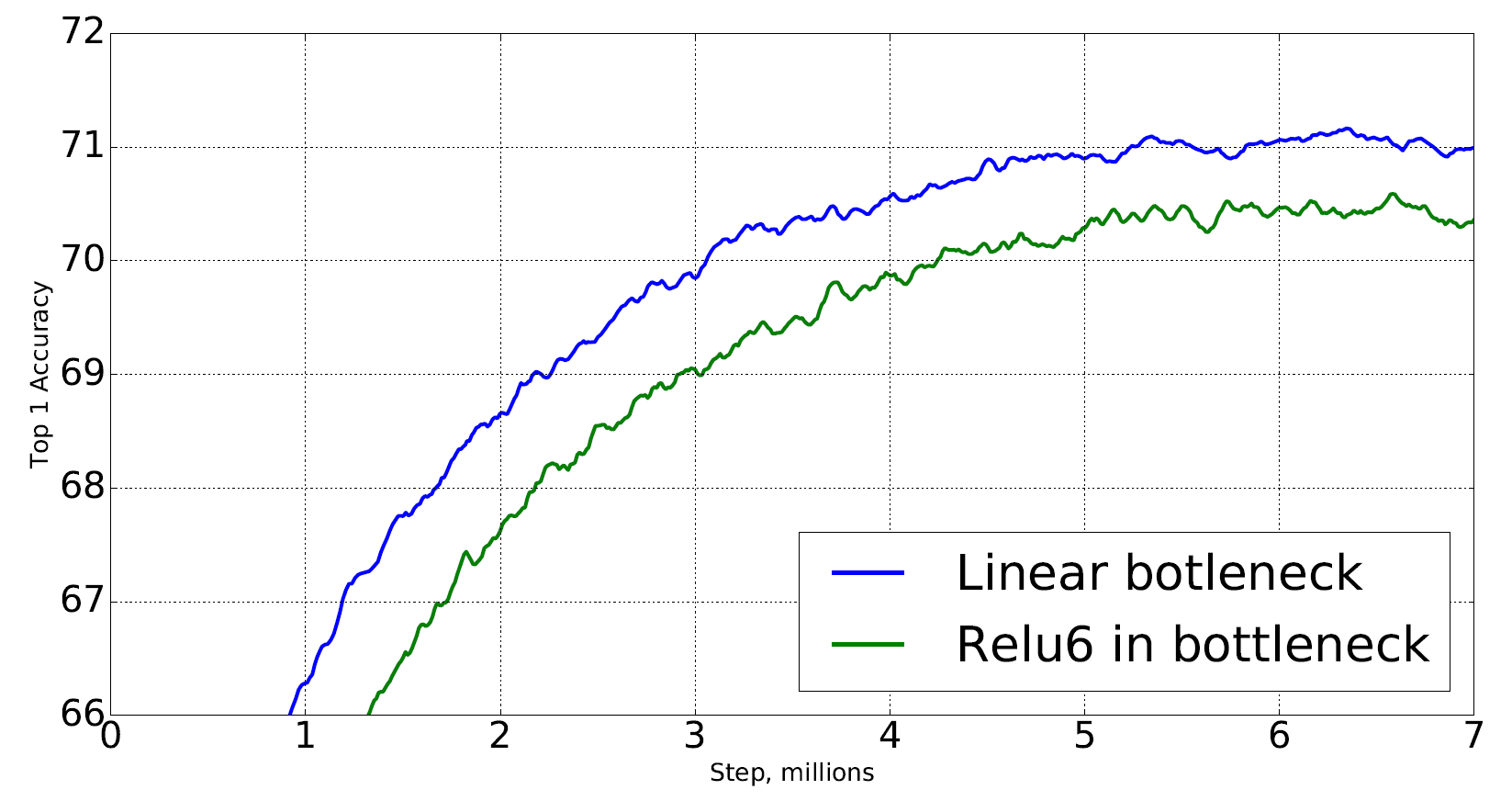
위 그래프는 Inverted Residual Bottelneck 구조에서 가장 마지막 레이어에 ReLU6의 적용 유/무에 따른 성능 그래프로
ReLU6를 적용 안한 버전인 Linear bottleneck의 성능이
ReLU6를 통상적인 Residual Bottleneck처럼 가장 마지막에 적용시킨
Relu6 in bottleneck버전보다 더 성능이 좋게 나왔기에
왜 성능이 더 좋게 나왔나를 논리적으로 설명하다 보니 논문과 동떨어진
Unit Test 까지 해가면서 빈약한 논리구조를 보완한게 아닌가 싶다.
2.1.2.1 Manifold of interest
Inverted Residual Bottelneck의 마지막 레이어에 Activation Function이 적용이 안된부분은
솔직히 실험결과가 적용을 안했을 때 더 좋게 나왔다
이렇게 퉁치고 넘어가도 될 법한 사안이기도 한데
이걸 궂이 Manifold라는 개념까지 거론하면서 논문이 아니라 개념강의를 진행하고 있다.
이것은 Intent vector, Intent Space에 대해서도 좀 알아야 하는데
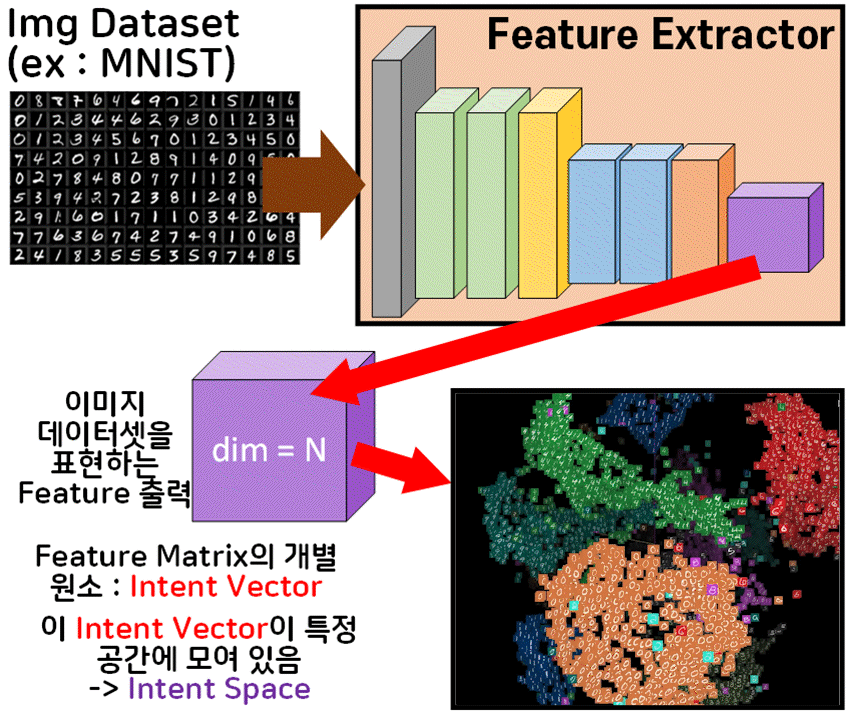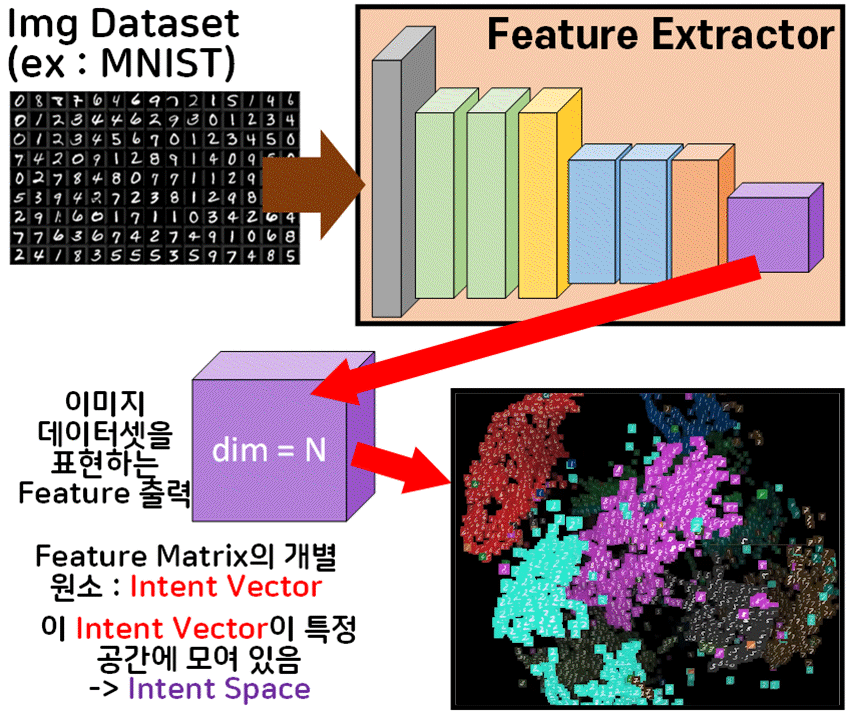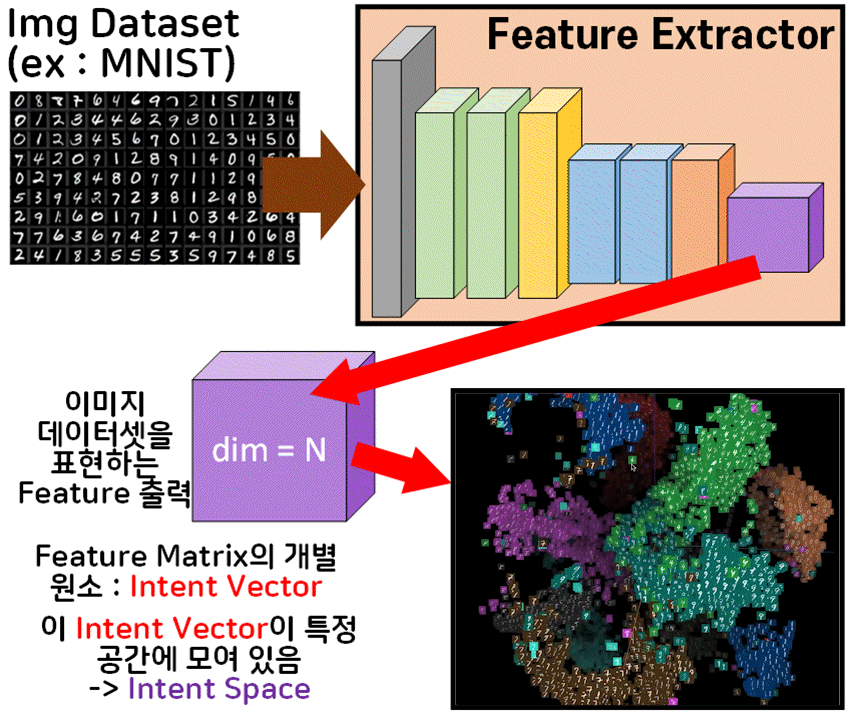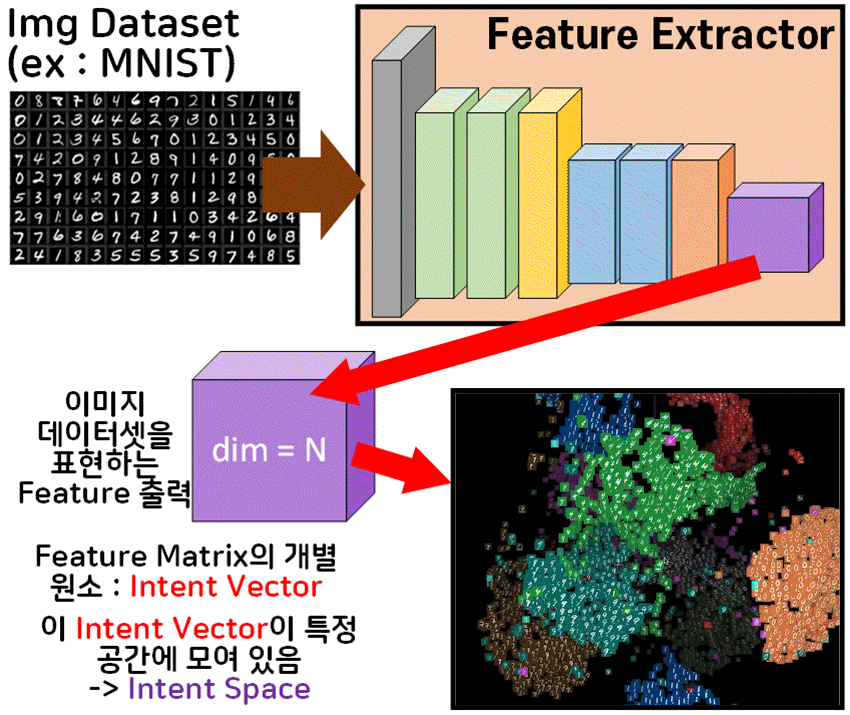
위 사진처럼 CNN의 Feature Extractor만 떼어내서
이미지 데이터셋으로 학습을 시키고 가장 말단 레이어의 출력물인
Feature를 출력하면
N차원의 Matrix 형태를 갖출 것이다.
이를 위 gif처럼 3차원으로 Display를 하게 되면
각 Matrix의 원소가 3차원 공간에 위치할 수 있는데
이를 Intent Vector이라 볼 수 있다
지금은 눈으로 보기 위해 3차원 공간으로 Projection을 수행한 것이지만
통상적으로 Feature Map이 생성될 때 각 원소는 해당 Feature의 차원인 N차원 공간에 위치한다.
이때 Intent Vector 모음을 잘 보면 특정 공간에 벡터들이 밀집하는 경우가 많다.
이 벡터의 밀집 정보를 보면 같은 데이터로 모여있는 경우가 많은데
가령 MNIST 이미지 데이터셋을 학습시키면
1, 2, 3 ... 0에 해당 하는 숫자를 표현하는 Intent Vector 는 각 숫자별로 집단이 모여있는 것이다.
그러니까 1을 표현하는 Intent Vector는 자기들끼리 특정 공간에 모여있음을 알 수 있다.
이 유사한 Intent Vector끼리 모여있는 공간을 Intent Space라 부르는 것이다.
이제 여기서 아래의 그림처럼 사고실험을 진행하자
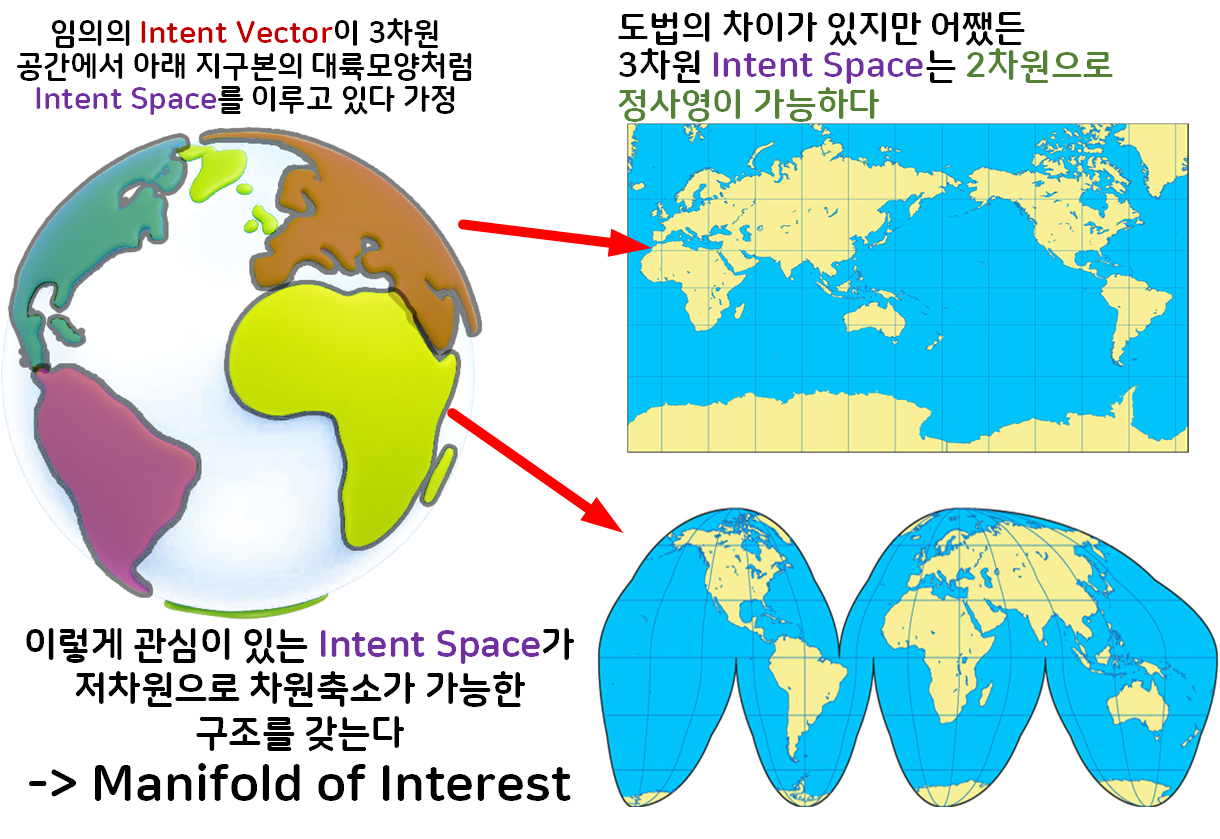
1) 임의의 Intent Vector의 군집이 3차원으로 표현했을 때
지구본의 각 대륙(유라시아, 아프리카, 남미, 북미) 모양처럼
Intent Space를 이루고 있음
2) 이 각각의 Intent Space는 2차원으로 차원 축소가 가능하며,
이 차원 축소가 가능한 구조를 갖는다 라고 볼 수 있다.
이렇게 고차원 영역에 존재하지만 충분히 저차원으로 저차원으로 차원축소가 가능하다면 해당 영역을 Maniford(다양체 구조)라 부르고
지금은 의미가 있는 영역이 Intent vector이 모인 Intent Space이
이렇게 저차원으로 차원축소가 가능한 Intent Space를
Maniford of interest라 부르는 것이다.
딥러닝 모델은 차원변환 연산을 기초로 하기에
대부분의 Intent Space는 저차원으로 차원 축소가 가능하다.
여기서 문제는 가장 적합하게 저차원 구조로 축소하기 이다.
위 gif처럼 차원축소를 적용했지만 정보왜곡이 많이 발생했다면
좋은 차원축소는 아닐것이다.
이게 흔히 Manifold learning 하면 항상 나오는

고차원 공간상에서 Swiss Roll(나선형으로 말려있는 구조) 구조를 띄고 있는 Manifold를 가장 적합하게 저차원으로 차원축소한 결과물
로 자주 설명이 된다.
그러면서 위 사진처럼 Swiss Roll의 A좌표랑 B좌표는 고차원 공간상에서는 가까워 보이지만
실제로는 오른쪽 이미지처럼 A와 B는 상당히 멀리 떨어진 유클리드 기하 거리를 갖는다
이렇게 표현하는데 간단하게 이해해 보자면

이런 느낌으로 이해하면 된다.
한국의 반대편인 우루과이로 고차원(지구본)상에서 가장 빠르게 가는 방법은
구멍 뚫어서 가는 것 이지만
한국(인천) 영국(런던) 브라질(상파울로) 우루과이
이렇게 유럽, 남미를 찍고 가는게 가장 현실적인 항공편
(Manifold구조를 고려한 유클리드 기하거리)
으로 볼 수 있다.
그래서 MobileNet v2에서 Manifold를 왜 설명하냐면...
MobileNet v2의 Inverted Residual Bottelneck는 위 개념을 기반으로 차원축소나 확장 그리고 저차원에서 ReLU를 안붙인다...
이런걸 설명하기 위해서 실제로 논문에서 저런 개념을 들고온다

이렇게 연관성을 찾기 힘든걸.. 궂이 논문에 녹여낼 필요가 있나.. 라는 생각이 든다..
3. MobileNet v2 아키텍쳐
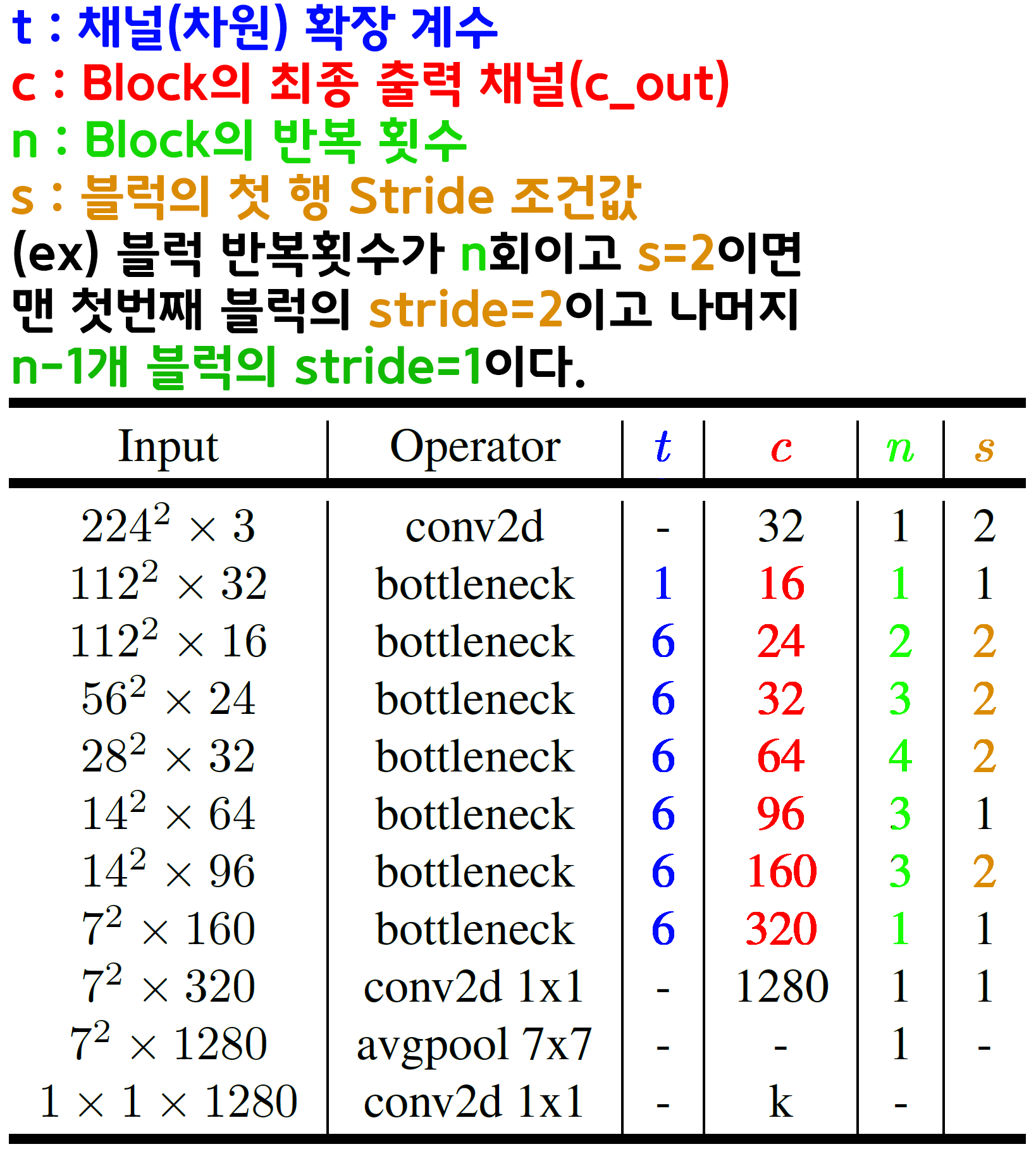
위 Stride옵션을 주의하면서 코드를 작성하면 무리없이
MobileNet v2 전체 모델 설계가 가능할 것이다.
MobileNet V2 모델 설계 부
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, Relu=True, **kwargs):
super(BasicConv, self).__init__()
layers = [
nn.Conv2d(in_ch, out_ch, kernel_size, bias=False, **kwargs),
nn.BatchNorm2d(out_ch)
]
if Relu: # 활성화 함수 ReLU는 조건에 따라 붙고/안붙고 한다.
layers.append(nn.ReLU6(inplace=True))
self.conv_block = nn.Sequential(*layers)
def forward(self, x):
x = self.conv_block(x)
return xclass InvertedResidual(nn.Module):
def __init__(self, in_ch, out_ch, stride, expand_ratio):
super(InvertedResidual, self).__init__()
# 중간 블럭의 채널개수(차원)은 확장계수로 조정됨
hidden_dim = int(in_ch * expand_ratio)
layers = [] #쌓을 레이어를 리스트에 담음
# stride가 1인 경우에만 Residual connection이 적용됨
self.Residual_connection = False
if stride == 1 and in_ch == out_ch:
self.Residual_connection = True
if expand_ratio != 1:
# 확장 단계 : 커널 사이즈가 1 + 채널크기가 변경되는 Point-wies Conv
layers.append(BasicConv(in_ch, hidden_dim, kernel_size=1))
# Depthwise Conv -> groups 옵션을 사용하여 커널을 그룹별로 적용
layers.append(BasicConv(hidden_dim, hidden_dim,
kernel_size=3, stride=stride, padding=1,
groups=hidden_dim))
# 축소단계 : 확장한 채널을 다시 감소시킴, 이때 활성화함수 적용X
# 이 부분 선형 Point-wise Conv이다.
layers.append(BasicConv(hidden_dim, out_ch, kernel_size=1,
Relu=False))
self.res_block = nn.Sequential(*layers)
def forward(self, x):
if self.Residual_connection:
return x + self.res_block(x)
else:
return self.res_block(x)class MobileNetV2(nn.Module):
def __init__(self, width_multiplier=1.0, num_classes=1000, init_weight=True):
super(MobileNetV2, self).__init__()
self.alpha = width_multiplier #네트워크 각 층의 필터 개수를 조정하는 인자값
self.stem = BasicConv(3, int(32*self.alpha),
kernel_size=3, stride=2, padding=1)
# MobileNet v2설정 계수값 (t, c, n, s)
# t: 확장 계수 (expand ratio)
# c: 출력 채널 수
# n: 반복 횟수
# s: 스트라이드 조건연산자
feature_ext_setting = [
# t, c, n, s
[1, 16, 1, False],
[6, 24, 2, True],
[6, 32, 3, True],
[6, 64, 4, True],
[6, 96, 3, False],
[6, 160, 3, True],
[6, 320, 1, False],
]
blocks = []
in_ch = int(32*self.alpha) #stem의 out_ch랑 같은값으로 시작
for t, c, n, s in feature_ext_setting:
out_ch = int(c * self.alpha)
# 첫 번째 블록만 stride 값을 s에 따라 설정, 이후 블록들은 stride=1
stride = 2 if s else 1
blocks.append(InvertedResidual(in_ch, out_ch,
stride=stride, expand_ratio=t))
in_ch = out_ch # 첫 블록 생성 후 in_ch 업데이트
# 나머지 블록들은 stride=1로 설정
for _ in range(1, n):
blocks.append(InvertedResidual(in_ch, out_ch,
stride=1, expand_ratio=t))
self.feature_ext = nn.Sequential(*blocks)
self.tail = BasicConv(in_ch, int(1280*self.alpha),
kernel_size=1, stride=1, padding=0)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(int(1280*self.alpha), num_classes)
)
if init_weight: #초기화 구동함수 호출
self._initialize_weight()
def forward(self, x):
x = self.stem(x)
x = self.feature_ext(x)
x = self.tail(x)
x = self.classifier(x)
return x
#모델의 가중치 초기화를 커스텀으로 수행하는 함수
def _initialize_weight(self):
for m in self.modules(): #설계한 모델의 모든 레이어를 순회
if isinstance(m, nn.Conv2d): #conv의 파라미터(weight, bias)의 초가깂설정
# Kaiming 초기화를 사용한 이유:
# Kaiming 초기화는 ReLU 활성화 함수와 함께 사용될 때 좋은 성능을 보임
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d): #BN의 파라미터(weight, bias)의 초가깂설정
# BatchNorm 레이어의 가중치와 바이어스를 간단한 값으로 초기화
nn.init.constant_(m.weight, 1) # 1로 다 채움
nn.init.constant_(m.bias, 0) # 0으로 다 채움
elif isinstance(m, nn.Linear): #FCL의 파라미터(weight, bias)의 초기값 설정
# 선형 레이어의 가중치를 정규 분포로 초기화
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)MobileNet V1 코드 개선
참고로 이전 포스트 23. 주요 CNN알고리즘 구현 : MobileNet (1) - 인공지능 고급(시각) 강의 복습
에서 설명한 MobileNet v1의 모델 아키텍쳐는 논문에서 표현한 방식은 꽤 지저분하게 표현되었는데 MobileNet V2의 논문에 표현한 방식대로 간편하게 정리할 수 있다.
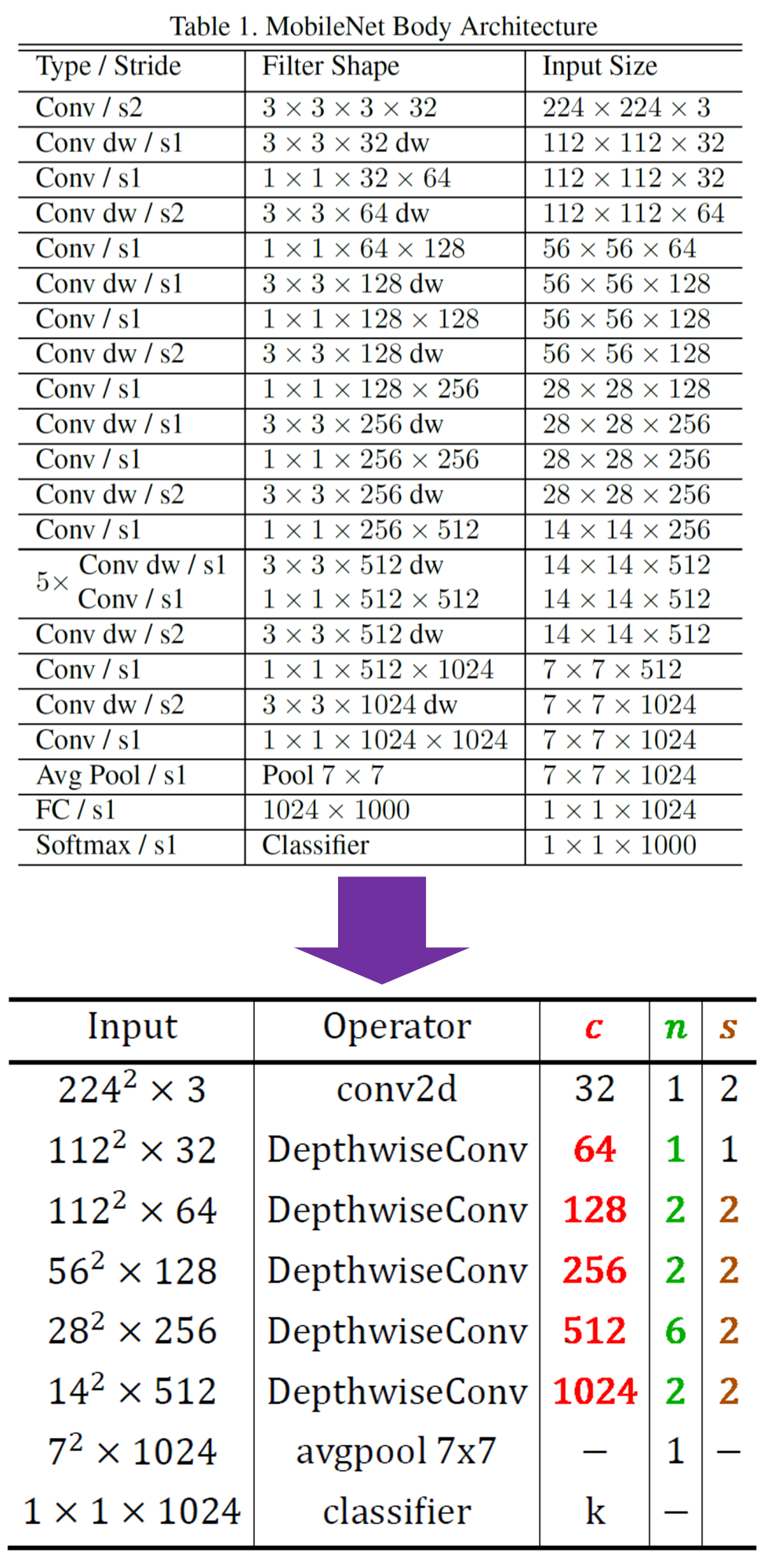
개선한 아키텍쳐 설계도를 바탕으로 이전 포스트에 작성한 MobileNet v1 코드도 개선을 수행하고자 한다.
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, kernel_size, Relu=True, **kwargs):
super(BasicConv, self).__init__()
layers = [
nn.Conv2d(in_ch, out_ch, kernel_size, bias=False, **kwargs),
nn.BatchNorm2d(out_ch)
]
if Relu: # 활성화 함수 ReLU는 조건에 따라 붙고/안붙고 한다.
layers.append(nn.ReLU6(inplace=True))
self.conv_block = nn.Sequential(*layers)
def forward(self, x):
x = self.conv_block(x)
return xclass DepthSep(nn.Module):
def __init__(self, in_ch, out_ch, stride):
super(DepthSep, self).__init__()
self.depthwise = BasicConv(in_ch, in_ch,
kernel_size=3, stride=stride, padding=1,
groups = in_ch)
self.pointwise = BasicConv(in_ch, out_ch,
kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return xclass MobileNetV1(nn.Module):
def __init__(self, width_multiplier=1.0, num_classes=1000, init_weight=True):
super(MobileNetV1, self).__init__()
self.alpha = width_multiplier #네트워크 각 층의 필터 개수를 조정하는 인자값
self.stem = BasicConv(3, int(32*self.alpha),
kernel_size=3, stride=2, padding=1)
# MobileNet v1설정 계수값 (c, n, s)
# c: 출력 채널 수
# n: 반복 횟수
# s: 스트라이드 조건연산 (뒤 설명 참조)
feature_ext_setting = [
# c, n, s
[ 64, 1, False],
[ 128, 2, True],
[ 256, 2, True],
[ 512, 6, True],
[1024, 2, True],
]
blocks = []
in_ch = int(32*self.alpha) #stem의 out_ch랑 같은값으로 시작
for c, n, s in feature_ext_setting:
out_ch = int(c * self.alpha)
# 첫 번째 블록만 stride=s에 따라 설정, 나머지는 stride=1
stride = 2 if s else 1
blocks.append(DepthSep(in_ch, out_ch, stride=stride))
in_ch = out_ch # 블럭 생성 후 in_ch를 업데이트
# 나머지 블록들은 항상 stride=1
for _ in range(1, n):
blocks.append(DepthSep(in_ch, out_ch, stride=1))
self.feature_ext = nn.Sequential(*blocks)
self.classifier = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(in_ch, num_classes)
)
if init_weight: #초기화 구동함수 호출
self._initialize_weight()
def forward(self, x):
x = self.stem(x)
x = self.feature_ext(x)
x = self.classifier(x)
return x
#모델의 가중치 초기화를 커스텀으로 수행하는 함수
def _initialize_weight(self):
for m in self.modules(): #설계한 모델의 모든 레이어를 순회
if isinstance(m, nn.Conv2d): #conv의 파라미터(weight, bias)의 초가깂설정
# Kaiming 초기화를 사용한 이유:
# Kaiming 초기화는 ReLU 활성화 함수와 함께 사용될 때 좋은 성능을 보임
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d): #BN의 파라미터(weight, bias)의 초가깂설정
# BatchNorm 레이어의 가중치와 바이어스를 간단한 값으로 초기화
nn.init.constant_(m.weight, 1) # 1로 다 채움
nn.init.constant_(m.bias, 0) # 0으로 다 채움
elif isinstance(m, nn.Linear): #FCL의 파라미터(weight, bias)의 초기값 설정
# 선형 레이어의 가중치를 정규 분포로 초기화
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)주요 개선사항은 아래의 그림과 같으며
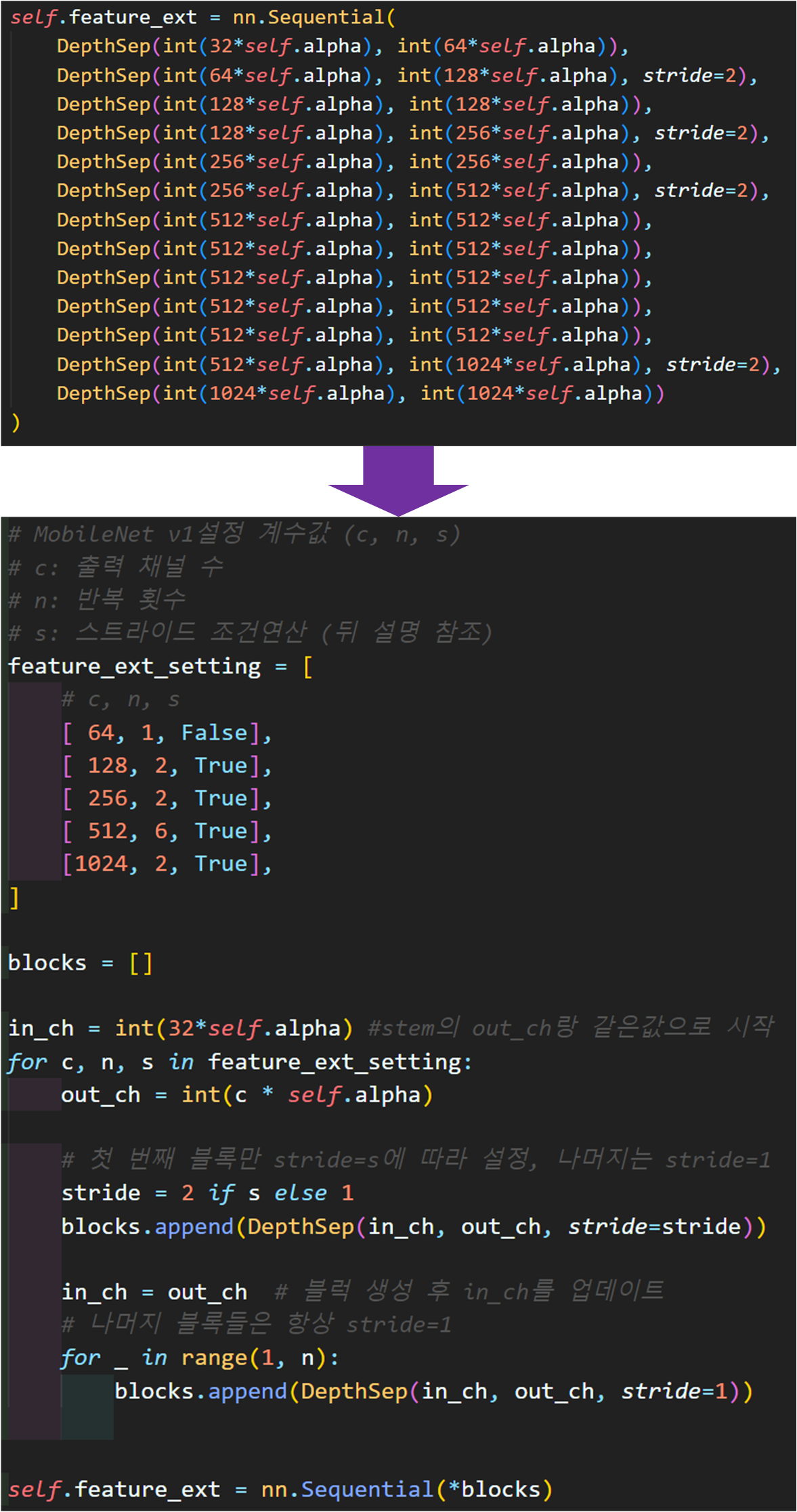
전반적으로 좀 고수같아 보이게 코드가 됬다.

아무튼 고수같아 보인다.
4. MobileNet v2 실습
MobileNet v2 아키텍쳐를 설명하면서 뜬금없이 MobileNet V1 코드개선을 수행한 이유는
아래의 실험 및 실습 환경 때문이다.

실험 조건이 Width Multiplier, Resolution Multilier이 각각 4, 5 이기에 하나의 모델에 대하여 20번 실험을 수행하며, 측정하고자 하는 지표는
연산복잡도 : FLOPs
모델의 무거운 정도 : Parameters개수 = Params
훈련/검증의 정확도 및 Loss : train_acc, train_loss, val_acc, val_loss
으로 총 6가지이다.
4.1 추가 실험 조건 설계
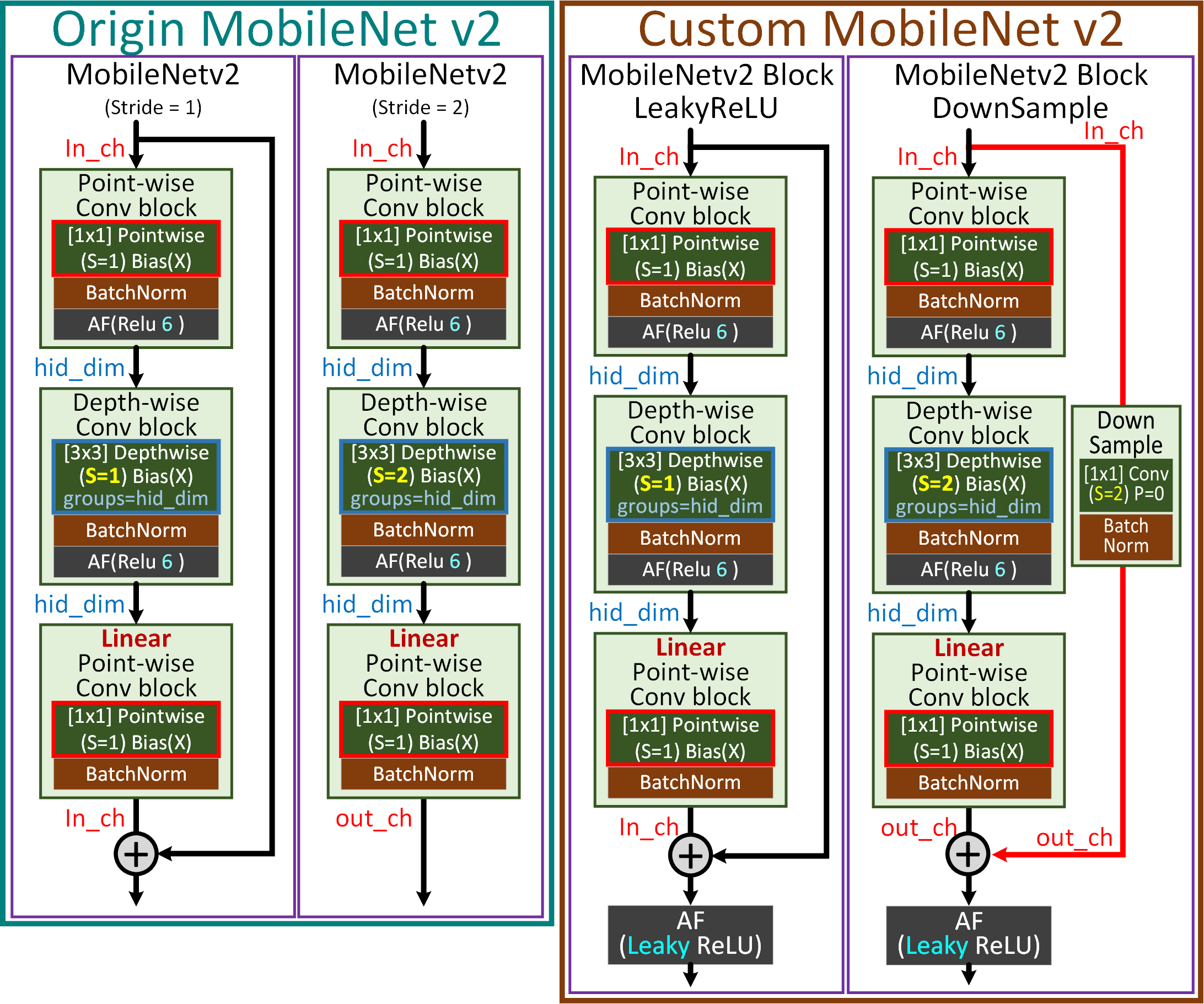
MobileNet v2 논문의 핵심인 Inverted Residual Bottelneck에 대해 설계이론이 자세하게 설명되긴 했지만
설명이 됬다고 해서 그게 납득이 되는 것과는 다르다 생각한다.
ResNet에서는 가장 마지막 레이어에 활성화 함수인 Relu를 포함시켰고
Stride = 2인 조건에서는 In_ch와 Out_ch의 차이가 발생할 때 Residual connection Path이 구현이 안되니
이를 Down Sample block를 도입해서 Path의 연결을 만들어낸다.
따라서
1) ReLU 블럭 추가
2) Down Sample block추가를 통하여 Stride = 2인 조건에서도 Residual connection이 구동되게 설계
과정을 추가한 custom MobileNet v2 (C_MobileNet v2)을 설계하여
성능비교를 수행하고자 한다.
여기서 1) 항목의 경우 저차원에서 정보손실이 크게 발생하여 ReLU를 제거한다는 논문의 논리를 대응하기 위해 LeakyReLU 활성화 함수를 사용하고자 한다.
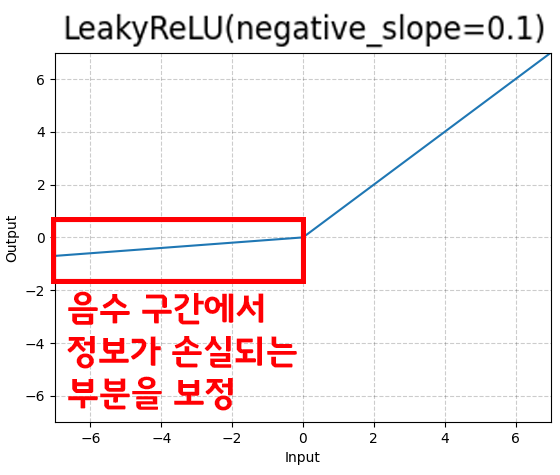
LeakyReLU라면 저차원에서 정보손실이 크게 발생하는 문제를 어느정도 보정할 것이라 기대되고
또 LeakyReLU나 Down Sample block을 추가시킨다 하더라도
MobileNet v2의 주 목적인 임베디드 환경에서 안정적으로 구동되는 경량화 모델
이라는 주 목적을 위배하지 않는다 생각한다.
애초에 Down Sample block이 [1x1] 커널을 기반으로 연산을 수행하는 레이어이기에 연산코스트가 Point-wies conv랑 동일하고
Activation Function 중 ReLU계열은 전반적으로 연산 복잡도가 그리 높은 편은 아니다. (LeakyReLU는 임베디드 환경에서 구동되는 Obj Detection 모델인 YOLO에도 채택이 되니 크게 문제가 없으리라 생각한다)
따라서 전체 실험 대상 모델은
MobileNet V1, MobileNet v2, C_MobileNet v2
3종이다.
구현한 C_MobileNet v2의 코드는 아래와 같다
class C_InvertedResidual(nn.Module):
def __init__(self, in_ch, out_ch, stride, expand_ratio):
super(C_InvertedResidual, self).__init__()
# 중간 블럭의 채널개수(차원)은 확장계수로 조정됨
hidden_dim = int(in_ch * expand_ratio)
layers = [] #쌓을 레이어를 리스트에 담음
if expand_ratio != 1:
# 확장 단계 : 커널 사이즈가 1 + 채널크기가 변경되는 Point-wies Conv
layers.append(BasicConv(in_ch, hidden_dim, kernel_size=1))
# Depthwise Conv -> groups 옵션을 사용하여 커널을 그룹별로 적용
layers.append(BasicConv(hidden_dim, hidden_dim,
kernel_size=3, stride=stride, padding=1,
groups=hidden_dim))
# 축소단계 : 확장한 채널을 다시 감소시킴, 이때 활성화함수 적용X
# 이 부분 선형 Point-wise Conv이다.
layers.append(BasicConv(hidden_dim, out_ch, kernel_size=1,
Relu=False))
self.res_block = nn.Sequential(*layers)
# 블럭의 가장 마지막에 활성화 함수(Leaky) 붙여넣음
self.relu = nn.LeakyReLU()
# 채널 및 Feature변화에 유연하게 대응하는 Downsample Path
self.downsample = None
if in_ch != out_ch or stride != 1:
self.downsample = BasicConv(in_ch, out_ch, kernel_size=1, stride=stride)
def forward(self, x):
if self.downsample is not None:
identity = self.downsample(x)
else:
identity = x
out = self.res_block(x)
out += identity #여기가 Residual connection
out = self.relu(out)
return outC_MobileNet v2는 Inverted Residual Bottelneck만 보정한 모델이기에
해당 블럭의 코드만 첨부한다.
4.2 실험 코드 작성
실험 하이퍼 파라미터 설정
# MobileNet의 Width_multiplier과 Resolution_multiflier 결정
alpha_key = {'W100%' : 1.0,
'W75%' : 0.75,
'W50%' : 0.5,
'W35%' : 0.35,}
rho_key = {'R224' : 224,
'R192' : 192,
'R160' : 160,
'R128' : 128,
'R96' : 96,}이미지 데이터셋 선정
이미지 데이터셋은 이전 포스트에서 사용한 Animals-10을 그대로 사용한다.
# 데이터 전처리 방법론 정의
from torchvision.transforms import v2
animals_val = {'mean' : [0.5177, 0.5003, 0.4126],
'std' : [0.2133, 0.2130, 0.2149]
}
def define_transform(img_size, normal_val, augment=False):
transform_list = []
if augment:
transform_list += [ #데이터 증강은 반전, 색상밝기채도, 아핀 3가지
v2.RandomHorizontalFlip(p=0.5),
v2.ColorJitter(brightness=0.4,
contrast=0.4,
saturation=0.4,
hue=0.1),
v2.RandomAffine(degrees=(30, 70),
translate=(0.1, 0.3),
scale=(0.5, 0.75)),
]
transform_list += [
v2.Resize((img_size, img_size)), #이미지 사이즈별로 리사이징
v2.ToImage(), #이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 정규화
v2.Normalize(mean=normal_val['mean'], std=normal_val['std']) #데이터셋 표준화
]
return v2.Compose(transform_list)
#데이터 전처리 방법론을 Resolution_multiflier별로 초기화
transforms = {'train': {}, 'val': {}}
for key, vel in rho_key.items():
transforms['train'][key] = define_transform(img_size=vel,
normal_val=animals_val,
augment=True)
transforms['val'][key] = define_transform(img_size=vel,
normal_val=animals_val,
augment=False)import os
from torchvision import datasets
from torch.utils.data import DataLoader
root = './Animals-10'
# 데이터로더를 Resolution_multiflier별로 생성하기
bs = 192 #배치사이즈 크기
img_dataset = {'train': {}, 'val': {}}
img_dataloaders = {'train': {}, 'val': {}}
for key in rho_key.keys():
# 각 해상도와 변환에 맞는 새로운 데이터셋 생성
img_dataset['train'][key] = datasets.ImageFolder(os.path.join(root, 'train'),
transform=transforms['train'][key])
img_dataset['val'][key] = datasets.ImageFolder(os.path.join(root, 'val'),
transform=transforms['val'][key])
img_dataloaders['train'][key] = DataLoader(img_dataset['train'][key],
batch_size=bs, shuffle=True)
img_dataloaders['val'][key] = DataLoader(img_dataset['val'][key],
batch_size=bs, shuffle=False)
위 두 코드를 통해 Animals-10의 이미지 전처리(DataLoader)까지 생성한다.
이때 주요 하이퍼 파라미터 : Batch_size = 192로 설정하고, 훈련 데이터셋은 이미지 증강을 적용했다.
모델 인스턴스화 + GPU이전
import copy
# GPU사용 가능여부 확인
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
models = {} #Width_multiplier 조건별로 모델 인스턴스화 + GPU이전
for key, vel in alpha_key.items():
# 여기서 MobileNetV2, MobileNetV1, C_MobileNetV2 별로 인스턴스화
models[key] = MobileNetV2(width_multiplier=vel, num_classes=10).to(device)
init_weights = {} #선언한 모델의 초기가중치를 저장하기
for key in alpha_key.keys():
init_weights[key] = copy.deepcopy(models[key].state_dict())모델은 총 3종 MobileNet V1, MobileNet v2, C_MobileNet v2이고 실험을 여러대의 PC에서 나누어서 진행하다 보니
동일한 ipynb 파일을 여러 PC에 나누어서 코드를 작성했다
그리고 models는 width multiplier의 조건이 총 4종이니 4종의 파생 모델이 생성된다 보면 된다.
이때 하나의 파생모델은 5종의 Resolution multiplier 별로 생성된 Dataloader별로 학습/검증을 수행하니
매 조건마다 모델의 초기 가중치를 초기화 하고 재현성을 맞추기 위해 가중치 초기화는 저장된 가중치를 불러오는 식으로 수행한다.
손실함수, 옵티마이저, 훈련/검증 라이브러리
import torch.optim as optim
#손실함수 및 옵티마이저 설정
criterion = nn.CrossEntropyLoss()
Lr = 0.001 #러닝레이트 설정
optimizers = {}
for key in alpha_key.keys():
optimizers[key] = optim.Adam(models[key].parameters(), lr=Lr)# 사전에 모듈화 한 학습/검증용 라이브러리 import
from C_ModelTrainer import ModelTrainer
num_epoch = 10 #총 훈련/검증 epoch값
ES = 2 # 디스플레이용 에포크 스텝
# BC_mode = True(이진), False(다중)
# aux = 보조분류기 유/무
# wandb = 완디비에 연결 안하면 None
trainer = ModelTrainer(epoch_step=ES, device=device, BC_mode=False, aux=False)손실함수, 옵티마이저는 동일한 조건으로 인스턴스화 하며
훈련 검증 코드는 model_train, model_evaluate 함수를 모듈화한 C_modelTraniner.py 외부 코드를 사용한다.
해당 코드는 https://github.com/tbvjvsladla/ResNext_wandb/blob/main/C_ModelTrainer.py
에 업로드하였다.
실험 조건별 훈련/검증 실행
# 학습/검증 정보 저장
history = {mk: {dk: {'loss': [], 'accuracy': []}
for dk in rho_key.keys()}
for mk in alpha_key.keys()}# 여러 조건별 모델 훈련 및 검증 코드
for mk in alpha_key.keys(): #Width_multiplier 조건
for dk in rho_key.keys(): #Resolution_multiplier조건
#학습/검증을 수행하기 전 모델 파라미터는 재 초기화 한다.
models[mk].load_state_dict(init_weights[mk])
#모델 훈련/검증 코드
for epoch in range(num_epoch):
# epoch별 훈련 손실&성과지표
train_loss, train_acc = trainer.model_train(
models[mk], img_dataloaders['train'][dk],
criterion, optimizers[mk], epoch
)
# epoch별 검증 손실&성과 지표
val_loss, val_acc = trainer.model_evaluate(
models[mk], img_dataloaders['val'][dk],
criterion, epoch
)
# 손실 및 성과지표를 history에 저장
history[mk][dk]['loss'].append((train_loss, val_loss))
history[mk][dk]['accuracy'].append((train_acc, val_acc))
# Epoch_Step(ES)일때 print하기
if (epoch+1) % ES == 0 or epoch == 0:
if epoch == 0:
print(f"현재 훈련중인 조건: [{[mk]} {[dk]}]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"훈련 [Loss: {train_loss:.3f}, " +
f"Acc: {train_acc*100:.2f}%]")
print(f"epoch {epoch+1:03d}," + "\t" +
f"검증 [Loss: {val_loss:.3f}, " +
f"Acc: {val_acc*100:.2f}%]")
print(f"\n----조건[{[mk]} {[dk]}] 훈련 종료----\n")위 코드를 구동하면
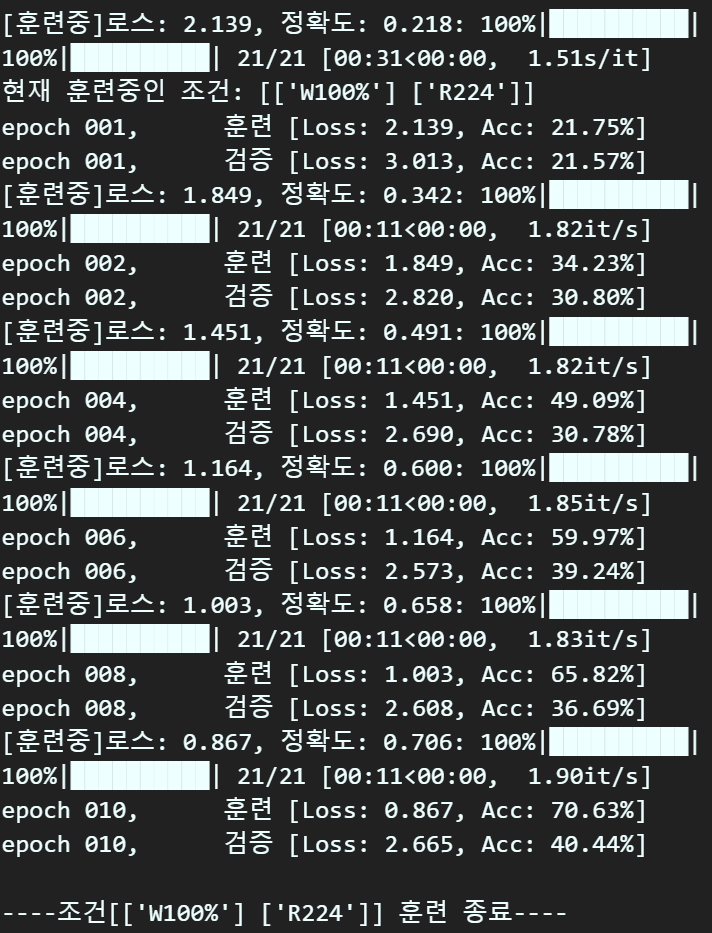
이렇게 조건별로 훈련/검증의 수행결과를 디스플레이해준다.
이런 조건이 총 20개이니 epoch=10으로 돌려도 전체 시간은
모델 당 한나절 이상은 걸린다....
4.3 실험 결과 분석
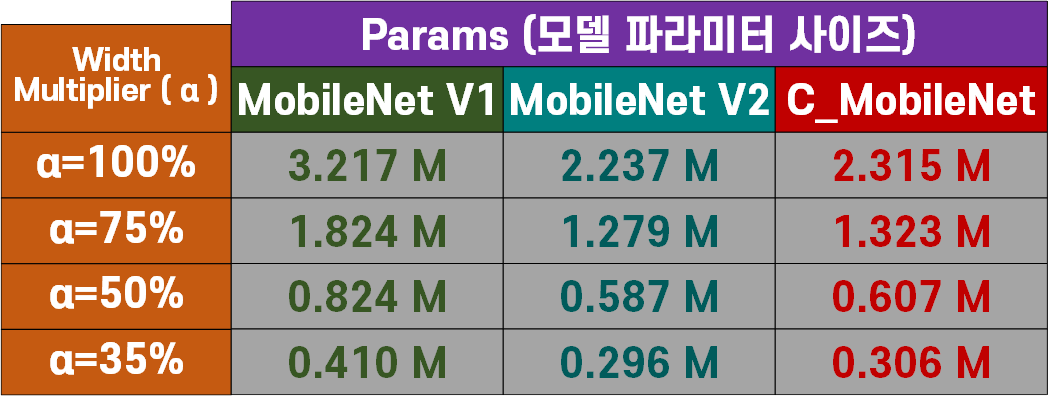
모델별 파라미터 개수(Params)
모델별 연산복잡도(Flops)
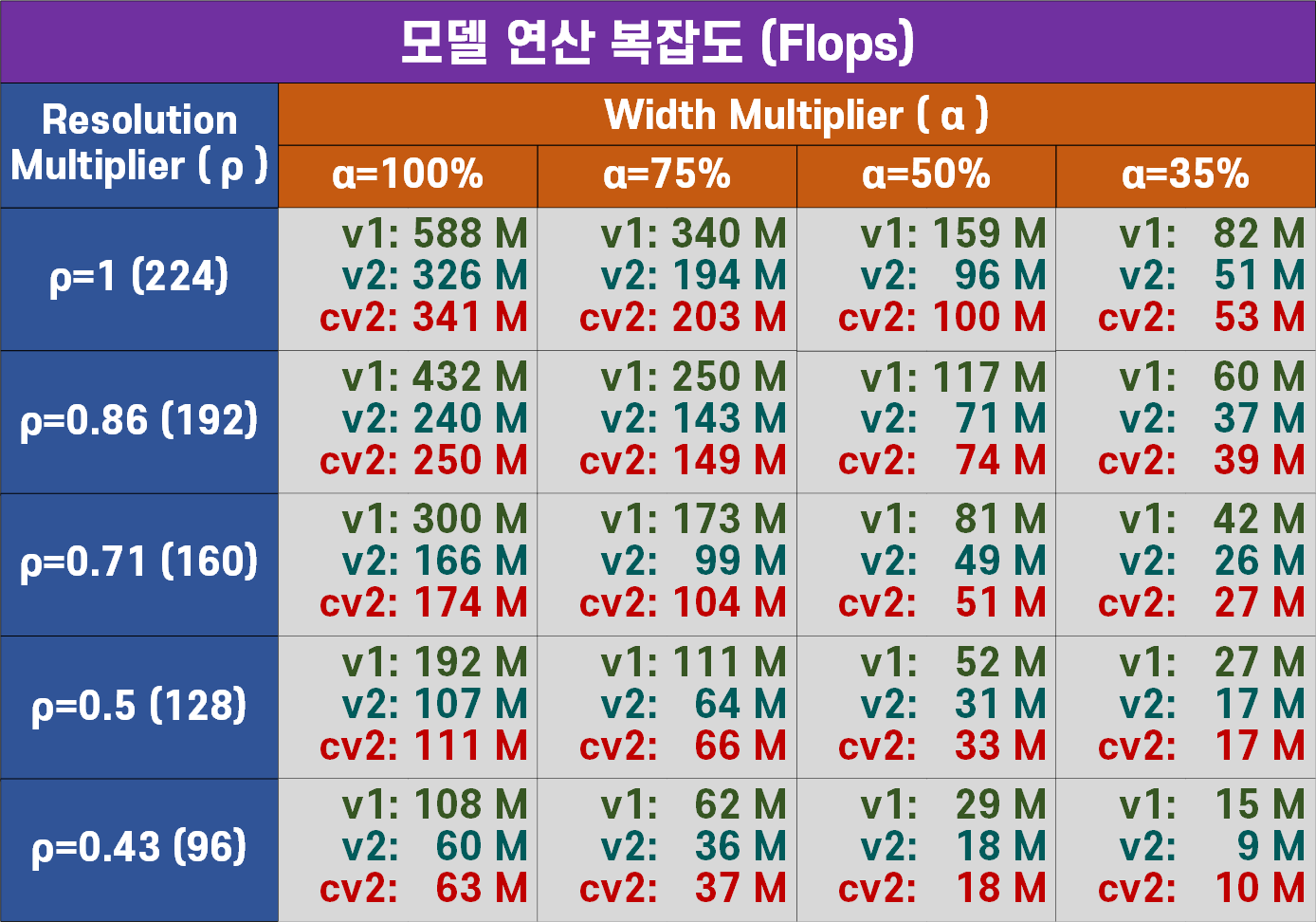
모델의 무게라고 볼 수 있는 모델 파라미터 개수(params)와 해당 모델을 실행시키는데 필요한 연산(자원)소모량인 연산 복잡도(Flops)를 비교한다면 전반적으로 MobileNet V1대비 MobileNet v2가 많이 경량화를 이뤄낸 것을 확인할 수 있다.
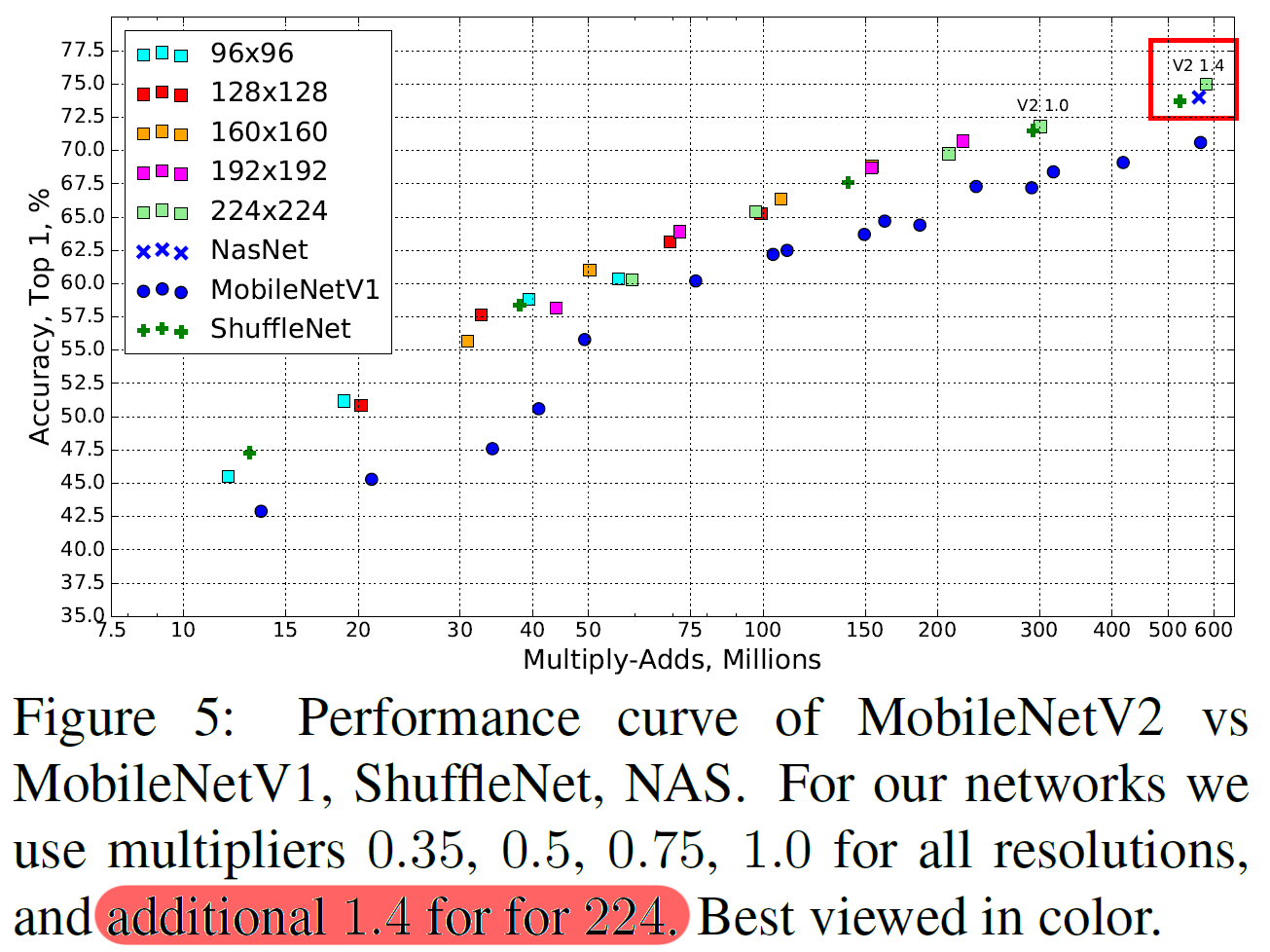
논문에서 MobileNet v2의 width mulitplier을 1이 아닌 1.4로 설계한 모델의 width를 더 크게 증폭시킨 결과값을 첨부했는데
왜 1.4로 증폭한 결과값을 첨부한지 알것 같기도 하다.
경량화가 적어도 30% 이상 크게 진행되다보니 이로 인한 성능 하락이 많이 발생한 듯 하여 MobileNet V1와 비슷한 파라미터 사이즈 및 연산복잡도를 맞춘 값을 찾다 보니 1.4배로 늘린 듯 하다...
모델별 성능(Accuracy)
모델은 훈련모드, 검증모드로 각각 성능지표(정확도, Loss)를 측정했으나 num_epoch = 10으로 충분히 모델을 학습시키지는 않았기에
훈련모드 - 정확도 지표만 첨부하도록 하겠다.
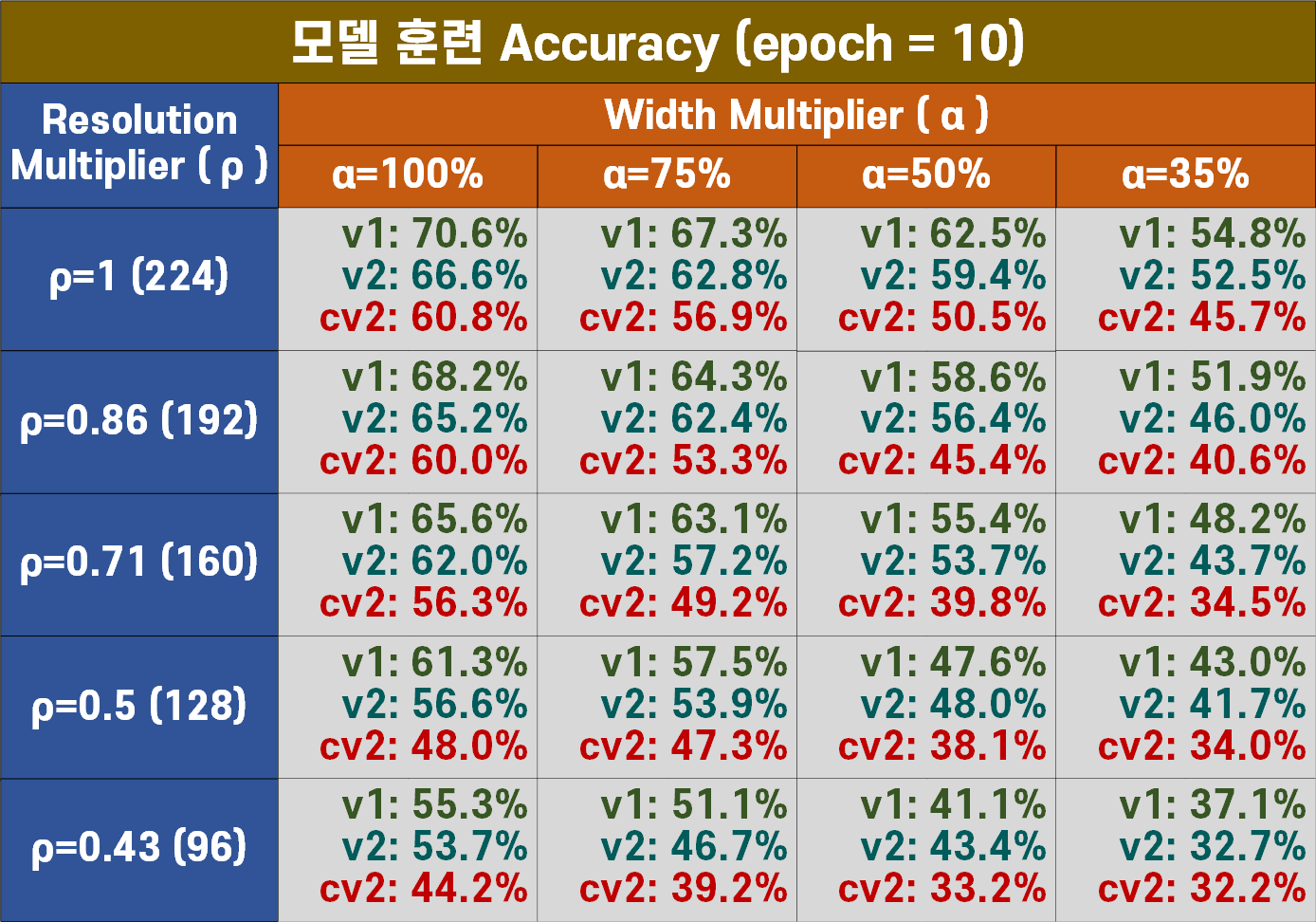
전체적인 성능지표는 MobileNet V1이 더 좋게 측정되는 것으로 보이나
해당 지표는 모델의 연산복잡도(Flops)와 연계하여 모델 성능을 자세하게 분석해야 한다.
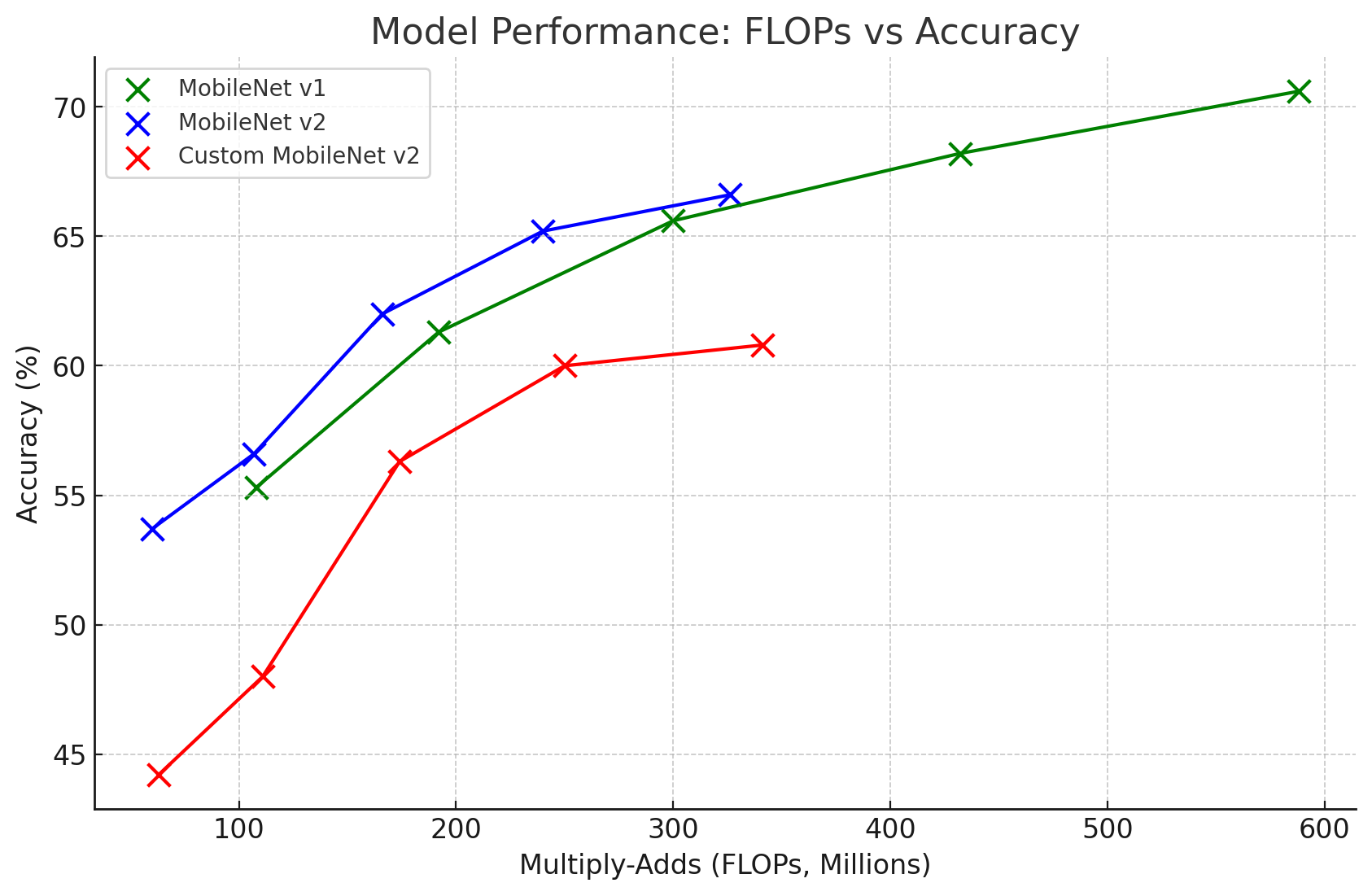
모델의 연산복잡도(Flops)와 연계하여 각 모델별 성능을 분석한다면 위 그래프처럼 MobileNet v2이 전반적으로 좌상단에 위치하는 것을 확인할 수 있다.
이는 MobileNet v2는 전체적으로 MobileNet V1보다 더 많이 경량화된 모델임을 알 수 있을 것이다.
문제는 경량화를 너무 많이 진행했기에 아래의 그래프처럼 MobileNet V1와 동일 연산복잡도 환경일 때 MobileNet v2의 성능이 더 우수하게 나오는 것을 어필하려고 1.4배로 width mulitplier조건을 적용한 것으로 생각한다.
그리고 추가로 필자가 의문을 가졌던 LeakyReLU + Downsample Path를 적용한 C_MobileNet v2는 필자의 예상과 다르게 성능이 많이 저조한 결과값이 도출됬다.
Inverted Residual Bottelneck의 가장 마지막 블럭인
Linear Point-wise Conv는 저차원으로 차원이 Feature를 배출하기에 논문에서 언급한 저차원 + 활성화 함수로 인한 정보왜곡을
Leaky ReLU로도 크게 해결하지 못하는 듯 하며, Stride=2인 경우에도 억지로 적용한 잔차연결도 퍼포먼스의 향상을 불러오지 못했다.
저차원 Feature간의 잔차연결은 예상과는 다르게 성능하락을 가져온 것이 참 흥미로운 사안인 듯 하다.
