
이전 포스트에서 TensorRT-LLM을 활용하여 LLM의 추론테스트를 진행했으니 이를 OpenAI Complaint API를 준수하는 Server로 서빙을 진행하고자 한다.
여기서부터는 크게 4가지 개념에 대해 정리를 할 필요성이 있는데
- TensorRT-LLM
- Triton Inference Server
- Fast API
- OpenAI Comatibility
이 4가지 항목이 어떻게 연동되는지를 알아야 한다.
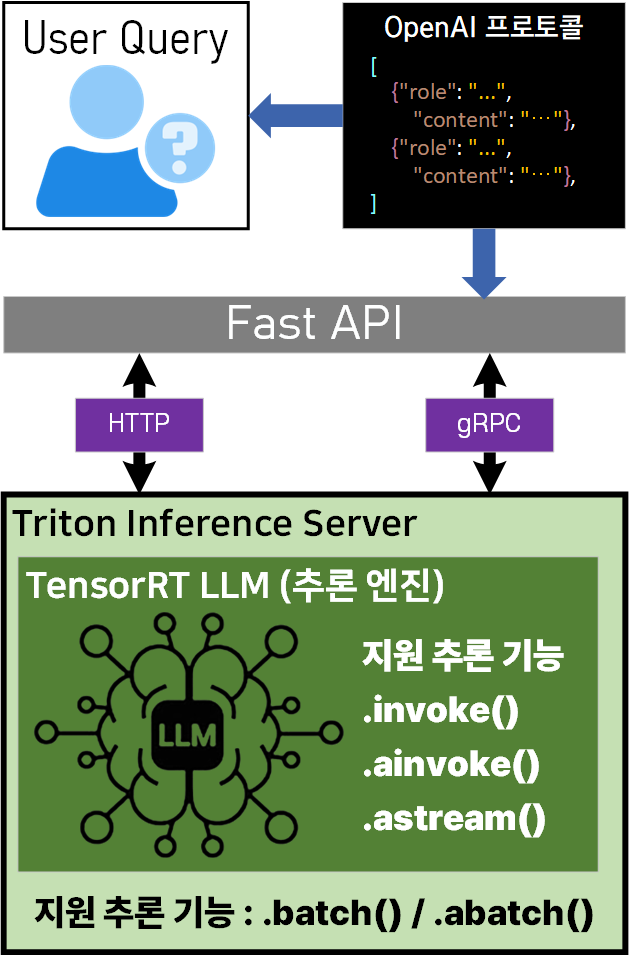
- TensorRT-LLM : LLM의 CUDA커널 기반 추론 최적화 엔진
- Trition Inference Serer : 다양한 LLM 포맷(TensorRT, Pytorch, ONNX)를 단일 서버에서 관리·배포 기능 제공
- FastAPI : 파이썬 기반의 비동기(Async)처리 성능이 우수한 웹 프레임워크
- OpenAI 호환 프로토콜 : Query를 OpenAI API 표준 형식으로 변환해주는 인터페이스
이렇게 개념을 정리했으니 Triton Inference Server / Fast API / OpenAI Compatibility Protocol 를 실습해보고자 한다.
1. Pytriton
Triton Inference Server을 구현하라고 하면 좀 막연한게 뭐 먼저 해야 하나? 라는 생각이 든다.
https://developer.nvidia.com/ko-kr/nvidia-triton-inference-server

이게 홈페이지 들어가 봐도 죄 광고문구밖에 없고, 뭘로 시작해야 할지 좀 막연하다.
그리고 뭐 좀 자료를 찾아 보면 결국 귀결되는게 NGC(Nvidia GPU Cloud) 컨테이너로 넘어가진다.
하지만 포스트의 목적이 어떻게든 WSL우분투 환경에서 서버를 구축하는 것이기에 다른 방안을 찾아보기로 했다.
https://triton-inference-server.github.io/pytriton/latest/
https://github.com/triton-inference-server/pytriton

첨부한 깃허브 자료랑 설명 구문들을 보면 확인할 수 있겠지만
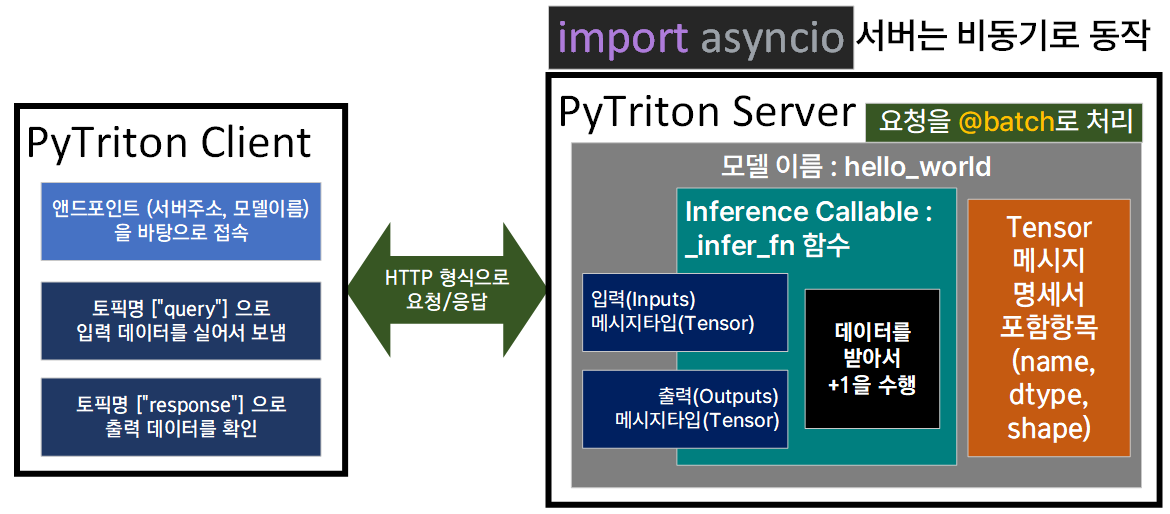
Triton Inference Server와 Flask/Fast API기능을 함께 제공하는 인터페이스라 보면 된다.
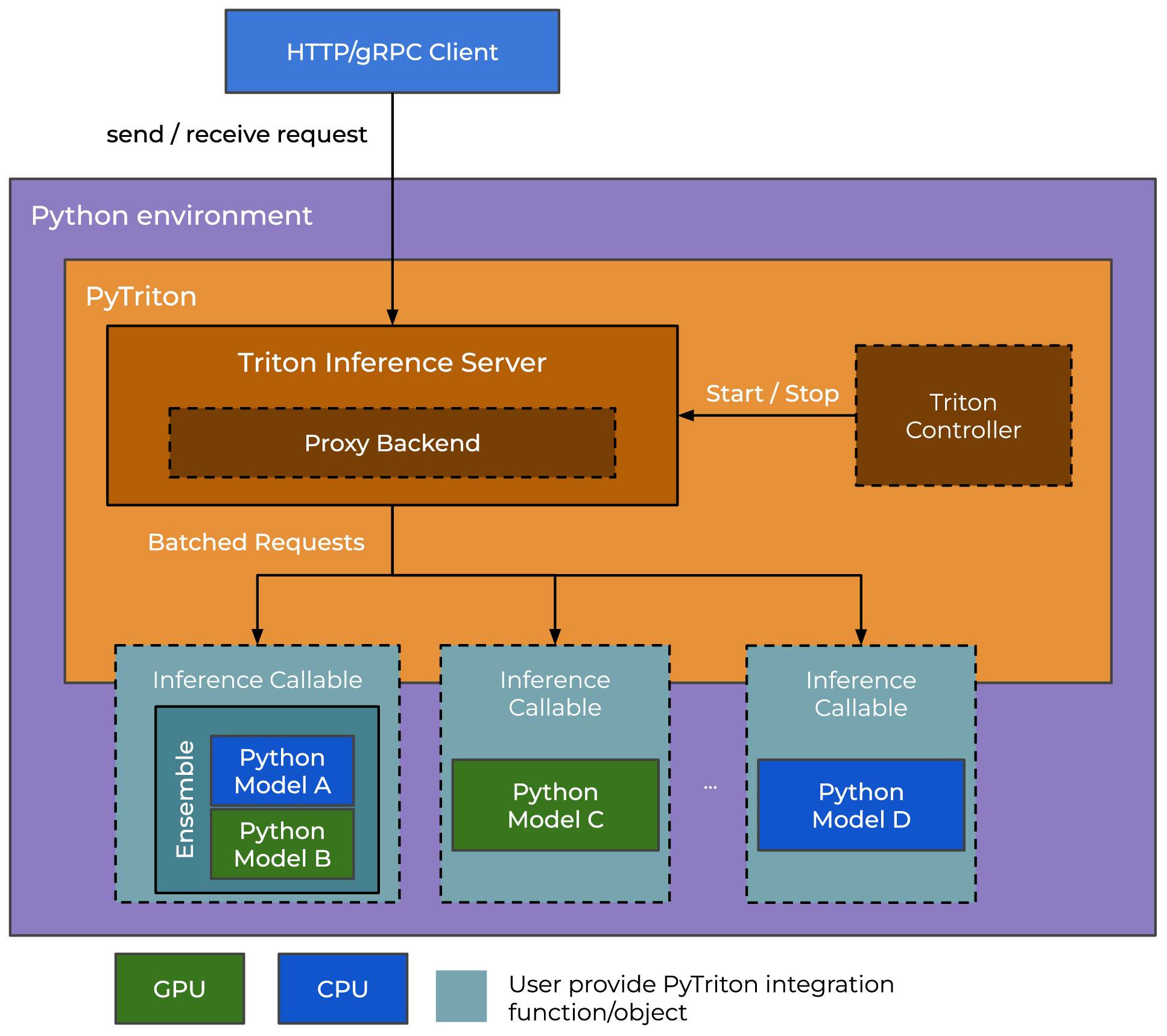
아키텍쳐 구성도를 보면 알 수 있지만 Triton Inference Server가 내부에 존재하는 Proxy Backend이 적절하게 LLM이 기동중인 Inference Callable을 최적화 하여 선택하는 작업을 진행한다
이때 Proxy Backend는 따지고 보면 Triton Inference Server의 핵심 기능이라 해당 모듈은 C++로 동작하기에 나머지 모듈은 파이썬 개발환경에서 용이하게 동작하도록 PyTriton으로 감싸져 있다 이렇게 보면 된다.
다음으로는 PyTriton이 Flask / Fast API와 유사성이 있다는 부분은
@app.post()와 같은 데코레이터를 사용해 특정 주소로 요청이 오면 해당 함수를 실행하라는 일련의 바인딩 과정을
triton.bind()라는 메서드를 통해 유사하게 구현했다 라는 부분을 설명하는 구문이라 보면 된다.
1.1 pytriton 설치
pytriton설치는 pip방식으로 설치가 가능하니 아래의 구문으로 설치를 진행하자
pip install nvidia-pytriton[all]여기서 마지막에 [all]구문은 해당 패키지의 모든 선택적 기능 및 추가 의존성도 설치하라는 뜻이다.
이왕이면 풀패키지로 설치를 진행한다.
설치 이후 pip show명령어를 통해 버전정보를 확인하자
현재 포스터 작성 시점 기준pytriton은 0.7.0이 가장 최신 버전이다.
1.2 pytriton numpy문제 해결방법
Pytriton예제 코드에 대한 검토는 차치하고
코드 실행을 하다보면 제일 빡치는 문제를 하나 마주하게 되는데
tritonclient.utils.InferenceServerException:
[400] load failed for model 'HelloWorld':
version 1 is at UNAVAILABLE state: Internal:
ModuleNotFoundError: No module named 'numpy'바로 위 기재한 코드처럼 numpy 모듈을 못 찾는 문제가 발생한다.
이게 pip list 명령어로

첨부한 사진처럼 numpy가 분명하게 설치가 되어 있어도 모듈을 못찾는 문제라서 해결하기가 좀 난감한데
PyTriton 자체가 실행되면서 임시 격리환경을 매번 생성하기에 해당 임시 격리 환경에 numpy가 없으니 계속 오류가 발생한다.
이거를 .bashrc의 환경변수로 numpy설치경로를 기입을 해줘도 안되고
.bind()로 모델을 붙일 때 numpy라이브러리를 참조하라고 설정을 해줘도 다 실패하는데
아래의 명령어로 시스템 패키지 레벨로 numpy, PyZMQ를 설치하면 문제가 해결된다.
sudo apt update
sudo apt install python3-numpy python3-zmq2. 코드 실습
이제 PyTriton의 서버 코드랑 클라이언트 코드를 각각 1개씩 만들어서 통신 테스트를 수행하고자 한다
triton_hw_server.py
import asyncio
import numpy as np
from pytriton.decorators import batch
from pytriton.model_config import Tensor
from pytriton.triton import Triton
@batch
def _infer_fn(**inputs):
data = inputs["query"]
outputs = {}
outputs["response"] = data + 1
return outputs
async def main():
with Triton() as triton:
triton.bind(
model_name="hello_world",
infer_func=_infer_fn,
inputs=[
Tensor(name="query", dtype=np.int32, shape=(1,)),
],
outputs=[
Tensor(name="response", dtype=np.int32, shape=(1,)),
],
)
print("hello_world 서버를 시작합니다.")
await triton.serve()
if __name__ == "__main__":
try:
asyncio.run(main())
except KeyboardInterrupt:
print("서버를 종료합니다.")triton_hw_client.py
import numpy as np
from pytriton.client import ModelClient
def main():
input_number = 10
print(f"숫자 {input_number}를 서버에 보냅니다.")
input_data = np.array([input_number], dtype=np.int32)
try:
with ModelClient("http://localhost:8000", "hello_world") as client:
result_dict = client.infer_sample(query=input_data)
output_number = result_dict["response"][0]
print(f"서버 응답: {output_number}")
if output_number == input_number + 1:
print("결과 확인: 성공! (서버가 1을 더했습니다) ✅")
else:
print("결과 확인: 실패! ❌")
except Exception as e:
print(f"서버에 연결하거나 요청하는 중 오류가 발생했습니다: {e}")
if __name__ == "__main__":
main()triton_hw_server.py 코드 실행장면
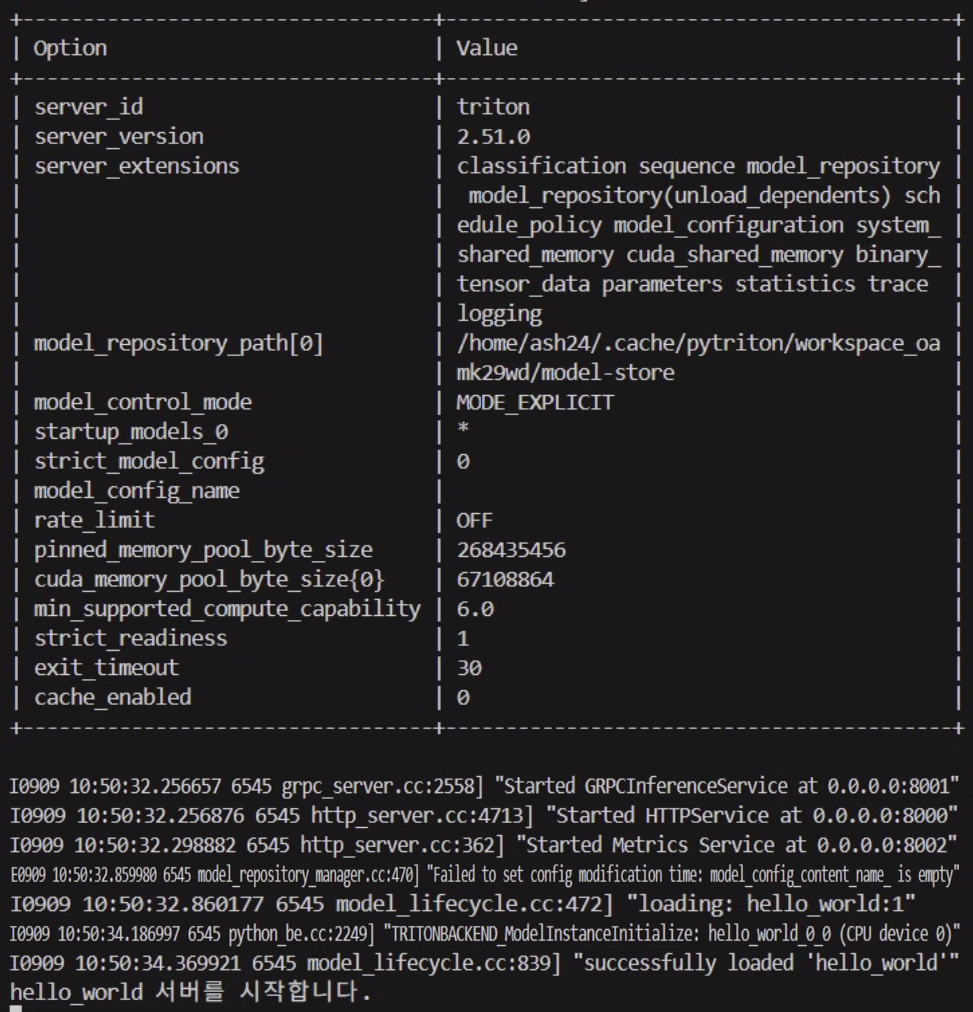
triton_hw_client.py 코드 실행장면

코드에 대한 설명은 뒤에 이어서 진행하겠다.
2.1 코드 설명
먼저 triton_hw_server.py 코드를 본다면 먼저 서버기동은 기본적으로 비동기 형식으로 동작해야 하기에
import asyncio비동기 파이썬 라이브러리를 import해준다
그 다음 Flask / Fast API 과정과 유사하게 동작하기 위해
@ 데코레이터로 Requset 발생 시 호출되는 함수를 명시한다.
이때 @batch 데코레이터는 요청이 요쳥이 한번에 들어오면 이를 순차처리가 아닌 한번에 처리하겠다는 의미이다.
다음으로
async def main():이 구문에서는 실제로 서버에서 요청시 비동기로 수행하고자 하는
Inference Callable을 바인딩 하는 과정이 수행되는데
제일 중요한 구문은 triton.bind()이라 볼 수 있다.
클라이언트가 어떤 모델을 사용할지? (model_name),
요청받은 모델이 어떤 함수를 수행해야 하는지? (infer_func)
모델이 어떻게 함수를 수행하는지는 관심이 없지만 입력과 출력의 형태는 어떤지? (inputs, outputs)
모델이 함수를 수행할 때 최대 동시 수행은 몇개까지 가능할지에 대한 고급설정(config)
등을 다룬다.
이때 입/출력 형태에서 예제 코드는 Tensor라는 구문이 들어있는데
이게 약간 혼동되는게 Tensor데이터 타입이 아니라
모델의 입출력 메세지 규격서를 Tensor로 명명한 것 뿐이다.
약간 ROS의 std_msgs 에 더 가깝다 보면 된다.
매핑을 하자면 토픽명 == 모델이름
메세지 필드 이름명 == Tensor(name)
토픽의 메세지(*.msg)의 내부 변수 타입 == Tensor(dtype)
여기서부터 갈리는게 ROS는 내부 변수가 n차원이면 vector로 묶지만
Tensor은 애초에 처음부터 튜플형식의 데이터를 받고 그것의 차원(shape)를 지정한다 라고 보면 된다.
클라이언트 코드는 딱히 분석은 안해도 될것 같으니 다음 챕터로 넘어가도록 하겠다.
3. OpenAI 프로토콜
https://platform.openai.com/docs/api-reference/introduction
첨부한 웹페이지의 설명을 보면

OpenAI 플랫폼과 상호작용하는 RESTful API로 스트리밍, 실시간 API를 구현하고 이를 HTTP통신으로 진행한다 라고 설명하고 있는데
RESTful API 대비 Fast API가 더 가볍고 개발이 편리하기에 이를 기반으로 코드개발을 수행한다 보면 된다.
어쨋든 LLM과 사용자가 통신하는 방식은 모두 요청 <-> 응답 을 기반으로 하니 이 요청/응답에 맞는 메세지 규격을 OpenAI 프로토콜 형식으로 개발하면 된다.
첨부한 페이지에서는 여러가지 항목들에 대한 메세지 프로토콜이 정의되어 있지만, https://platform.openai.com/docs/api-reference/chat/create
첨부한 페이지의

가장 기초적인 chat completion만 구현하면 된다.
chat completion - Default Request
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
]
}'
chat completion - Default response
{
"id": "chatcmpl-B9MBs8CjcvOU2jLn4n570S5qMJKcT",
"object": "chat.completion",
"created": 1741569952,
"model": "gpt-4.1-2025-04-14",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I assist you today?",
"refusal": null,
"annotations": []
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 19,
"completion_tokens": 10,
"total_tokens": 29,
"prompt_tokens_details": {
"cached_tokens": 0,
"audio_tokens": 0
},
"completion_tokens_details": {
"reasoning_tokens": 0,
"audio_tokens": 0,
"accepted_prediction_tokens": 0,
"rejected_prediction_tokens": 0
}
},
"service_tier": "default"
}
chat completion - streaming request
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-5",
"messages": [
{
"role": "developer",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Hello!"
}
],
"stream": true
}'
chat completion - streaming response
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"role":"assistant","content":""},"logprobs":null,"finish_reason":null}]}
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{"content":"Hello"},"logprobs":null,"finish_reason":null}]}
....
{"id":"chatcmpl-123","object":"chat.completion.chunk","created":1694268190,"model":"gpt-4o-mini", "system_fingerprint": "fp_44709d6fcb", "choices":[{"index":0,"delta":{},"logprobs":null,"finish_reason":"stop"}]}
이렇게 위에 총 4개
chat completion - Default Request
chat completion - Default response
chat completion - streaming request
chat completion - streaming response
요청/응답에 대한 프로토콜을 준수하여 모델과 송수신이 되는 코드를 작성하면 된다.
이거 같은 경우는 바이브 코딩으로 만들어 달라 하면 꽤 잘 만들어주는데
Pydantic 라이브러리를 바탕으로 여러개의 요청/응답 프로토콜을 준수하는 클래스를 작성해준다.
이때 Pydantic 라이브러리에 대해 간단하게 소개하자면
OpenAI 메세지 프로토콜을 준수하기 위해 각 데이터를 Type Hints(타입 힌트) 를 사용해 데이터 유효성 검사와 설정 관리용 라이브러리라 보면 된다.
간단히 설명하자면 Pydantic를 사용하지 않는다면
def process_user(user_data):
if not isinstance(user_data, dict):
raise TypeError("Dictionary required")
if "name" not in user_data or not isinstance(user_data["name"], str):
raise ValueError("Name is a required string")위 코드처럼 입력된 데이터의 데이터 타입과 키값이 올바르게 메세지 구조를 준수하는지를 모두 준수해야 하지만
from pydantic import BaseModel
class User(BaseModel):
name: str
age: int
email: strPydantic 라이브러리를 사용한다면 손쉽게 정의한 메세지 규격을 준수한 데이터만을 송수신에 사용하는게 가능해진다.
