
이제 TensorRT-LLM을 활용하여 양자화를 진행하고자 한다.
1. Quantconfig 양자화
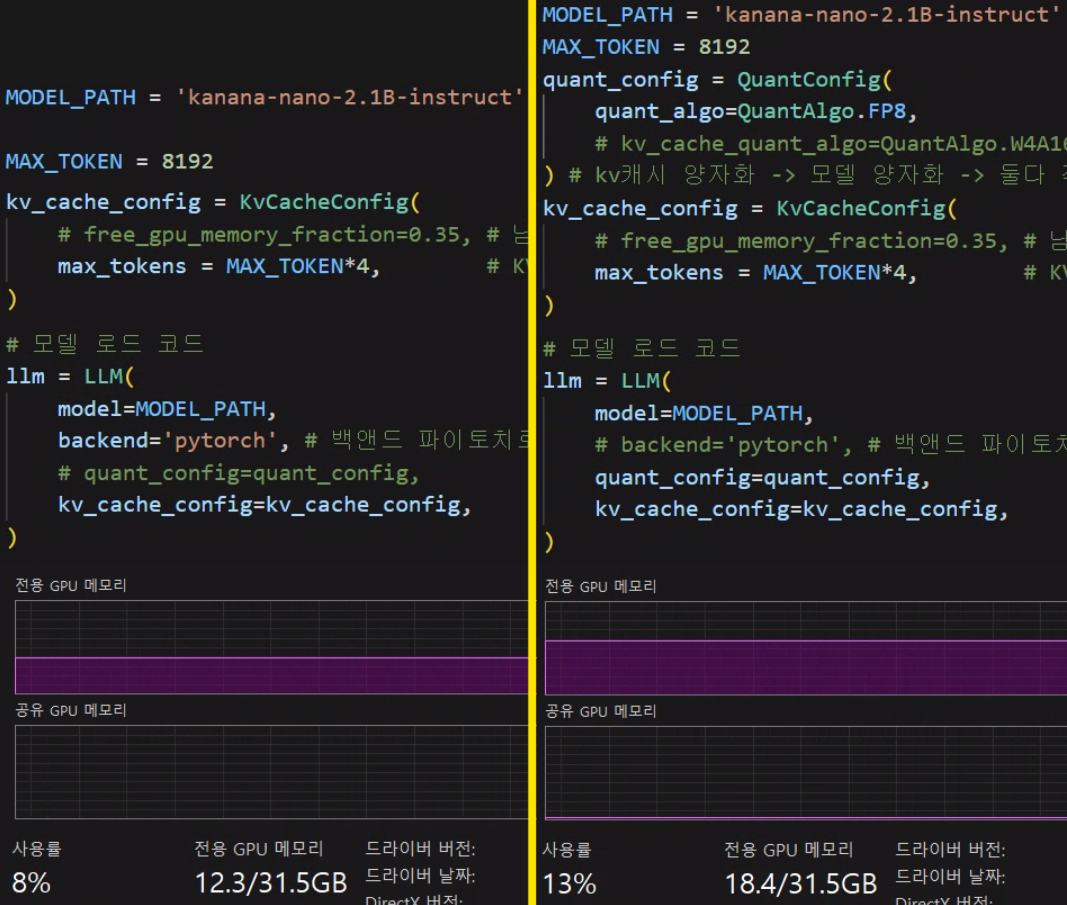
가장 기본적인 양자화 방법론은
from tensorrt_llm.llmapi import QuantConfig, QuantAlgo, CalibConfig
# 양자화 설정 (FP16 / FP8 / W4A16_AWQ) 이거 3개가 가장 중요
quant_config = QuantConfig(
quant_algo=QuantAlgo.FP8,
# kv_cache_quant_algo=QuantAlgo.W4A16
) # kv캐시 양자화 -> 모델 양자화 -> 둘다 적용 순으로도 할 수 있음
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
# backend='pytorch', # 백앤드 파이토치로 다시 조정
quant_config=quant_config,
kv_cache_config=kv_cache_config,
)위 코드블럭에 있는 QuantConfig옵션을 활성화하여 PTQ(Post Training Quantization, 사후 양자화)를 바로 적용할 수 있지만
첨부한 사진처럼
허깅페이스 체크포인트 모델
-> 사후 양자화
-> Tensor-RT LLM 체크포인트
-> Tensor-RT 엔진
이렇게 복잡한 과정을 거쳐서 모델 로드 및 추론을 수행하기에
그만큼 중간에 사용되고 유기되는 VRAM이 필히 존재한다.
문제는 양자화를 적용하면 VRAM이 줄어야 하는데 오히려 더 들어나는 점이다.
그리고 모델 로드를 수행하면서 양자화까지 수행하다 보니 로딩 시간도 상당히 오래 소요된다.
2. TensorRT Modelopt
이 문제를 해결하는데는
https://github.com/NVIDIA/TensorRT-Model-Optimizer
첨부한 TensorRT-Model-Optimizer를 활용하여 LLM모델을 양자화 하면 된다.
참고로 설치명령어는
pip install nvidia-modelopt이나 TensorRT-LLM을 온전하게 설치했다면
위 사진처럼 이미 설치된 라이브러리인 것으로 확인 될 것이다.
양자화의 경우 라이브러리를 직접 import해서 양자화를 적용 후
Tensor-RT LLM 체크포인트로 저장하는 방법과
TensorRT-LLM의 example/quantization에 있는
TensorRT-LLM Quantization Toolkit을 활용해서 양자화를 적용해도 된다
참고로 TensorRT-LLM Quantization Toolkit는 기본적으로
TensorRT-Model-Optimizer를 호출하여 양자화를 진행하는 것이기에 양자화 과정은 큰 차이는 발생하지 않는다.
2.1 라이브러리로 양자화
먼저 원본 모델이 허깅페이스 체크포인트 모델 규격이기에
HuggingFace Text Generation Inference(허깅페이스 TGI엔진)으로 모델을 로드한다.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = 'kanana-nano-2.1B-instruct'
# 허깅페이스에서 모델과 토크나이저 직접 로드
tokenizer = AutoTokenizer.from_pretrained(
MODEL_PATH,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)다음으로 TensorRT-Model-Optimizer 에서 지원하는 라이브러리인 modelopt으로 양자화를 수행한다.
이때 양자화는 FP8로 양자화를 진행한다.
import modelopt.torch.quantization as mtq
from modelopt.torch.export import export_tensorrt_llm_checkpoint
quant_cfg = mtq.FP8_DEFAULT_CFG
# 캘리브레이션 없이 직접 양자화 (빠른 변환)
model = mtq.quantize(model, quant_cfg)
export_tensorrt_llm_checkpoint(
model=model,
decoder_type='llama', # kanana-nano는 LLama 아키텍처 기반
export_dir='./kanana-nano-2.1B-instruct-fp8',
inference_tensor_parallel=1,
inference_pipeline_parallel=1,
dtype=torch.float16 # FP16 기본 타입 사용
)이렇게 수행하면 당연히 안된다.
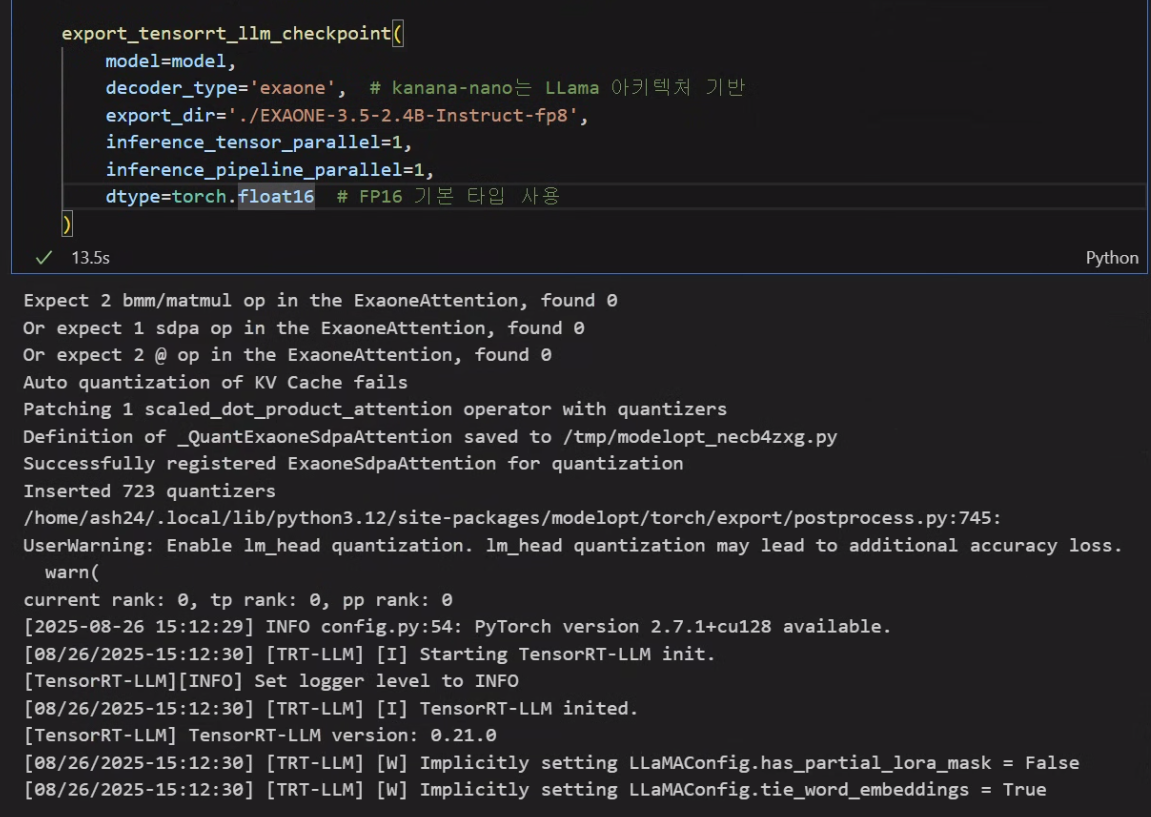
보이는 것처럼 양자화는 성공하지만
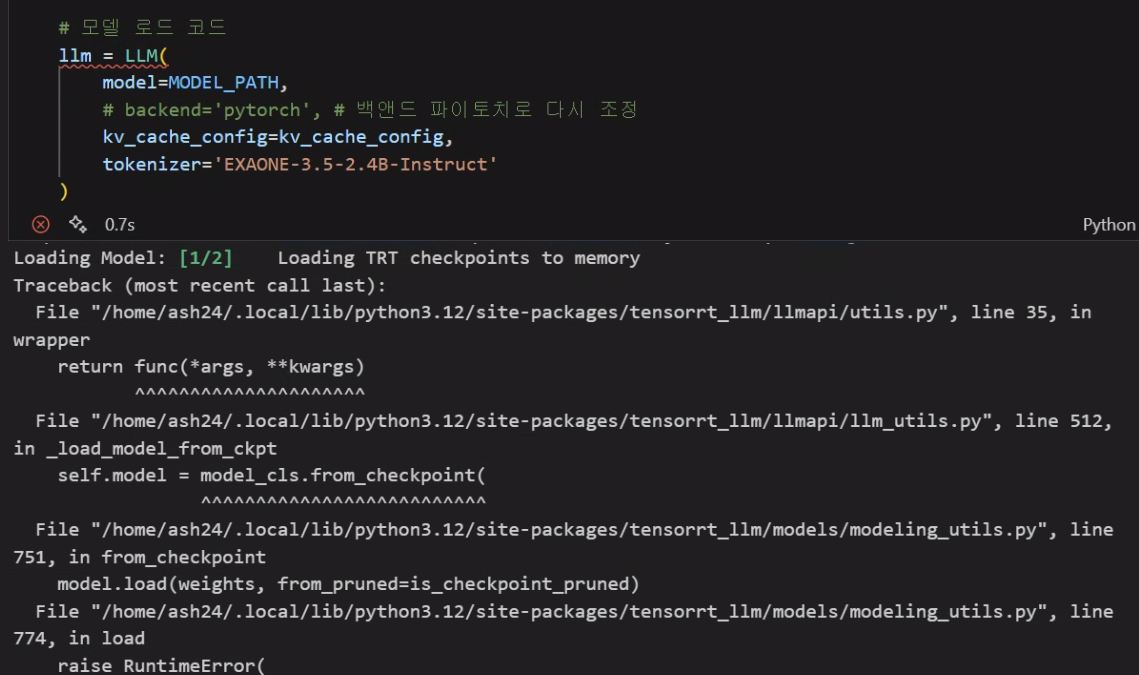
모델 로드 부분에서 에러가 발생한다.
https://nvidia.github.io/TensorRT-Model-Optimizer/getting_started/3_quantization.html
첨부한 사진을 보면 켈리브레이션용 데이터가 있어야 하는데
역할은 Activation scalling factor 정보를 켈리브레이션용 데이터로 유추해야 하는데 그때 사용된다 보면 된다.
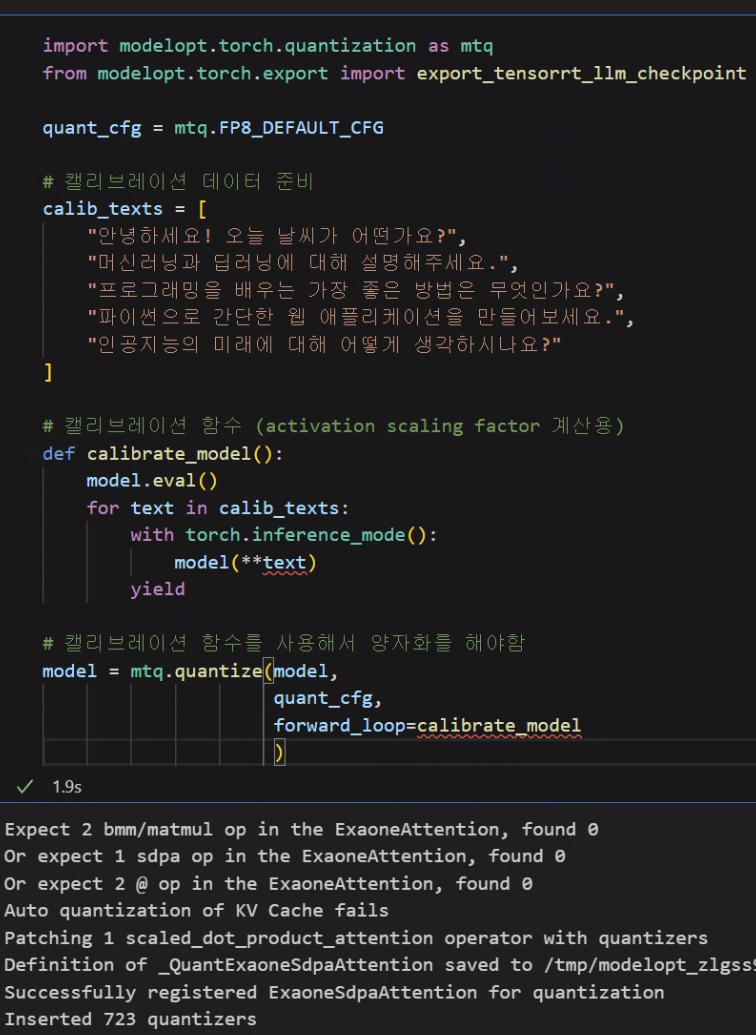
켈리브레이션 데이터를 바탕으로 양자화까지는 어찌저찌 수행이 가능하지만...
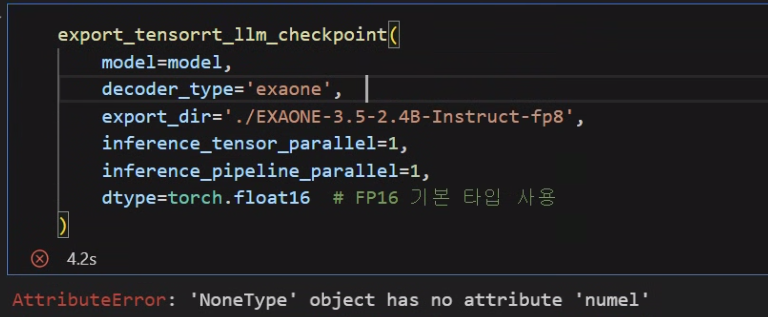
export_tensorrt_llm_checkpoint 메서드로는 좀처럼 모델 변환이 되지 않는다...
이것 말고도 export_hf_checkpoint라는 메서드도 있는데
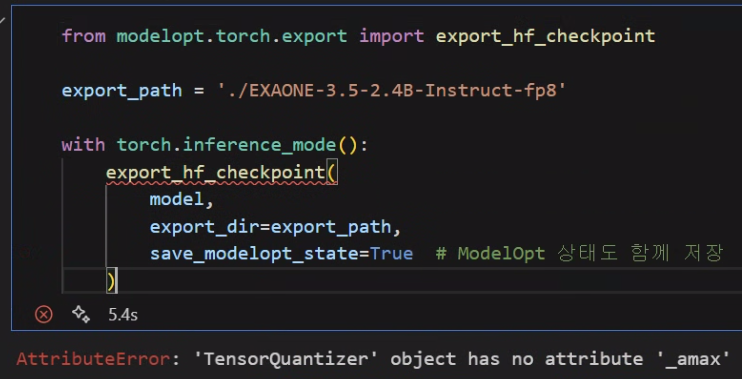
음... 둘다 문제가 있는 메서드다...
2.2 Quantization Toolkit
https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/quantization
첨부한 웹페이지에 나와있는 데로 양자화를 수행하면 되긴한데
필수 옵션은 --model_dir, --output_dir, --qformat 3가지이다.

이렇게 양자화를 수행하면 Tensor-RT LLM 체크포인트모델 규격으로 변환되며, 어차피 TensorRT-LLM라이브러리에서는 Tensor-RT 엔진규격으로 모델변환을 수행하기에
trtllm-build까지 같이 수행하는게 제일 마음이 편하다

from tensorrt_llm import LLM, SamplingParams
from tensorrt_llm.llmapi import KvCacheConfig
kv_cache_config = KvCacheConfig(
# free_gpu_memory_fraction=0.35, # 남은 VRAM의 35% 를 KV캐시에 할당
max_tokens = MAX_TOKEN*2 # KV 캐시 용량을 “토큰 절대값”으로 계산함
)
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
# backend='pytorch', # 백앤드 파이토치로 다시 조정
kv_cache_config=kv_cache_config,
tokenizer='EXAONE-3.5-7.8B-Instruct',
trust_remote_code=True
)위 기본 TensorRT-LLM 모델 로드 코드로 VRAM소비를 측정하면 아래와 같은 결과가 도출됬다.
이제 양자화 테스트를 수행하려 하는데 대상 LLM은

LG exaone-3.5-7.8B 모델을 선정하여 양자화 테스트를 진행했다.
VRAM 소비 항목별 비교 (GB)
| 항목 | FP16 (기본) | FP8 (ModelOpt) | INT4 AWQ |
|---|---|---|---|
| 엔진 사이즈(Loaded engine) | 15.68 | 8.69 | 5.31 |
| 실행 컨텍스트 메모리(Execution context) | 1.21 | 1.06 | 0.84 |
| 런타임 버퍼(Runtime buffers) | 2.03 | 1.64 | 1.64 |
| 디코더(Decoder) | 4.25 | 3.05 | 3.05 |
| Paged KV 캐시(Allocated) | 2.15 | 1.07 | 1.07 |
| 총 소비 VRAM | 25.32 | 15.51 | 11.91 |
이게 모델마다 양자화를 적용했을 때 확실하게 VRAM이 절약되기도 하고 거의 안먹히는 모델도 있고 천차만별이다
WSL 우분투에서 파일 복붙시 팁
WSL-우분투는 어쨋든 윈도우 위에서 동작하는 가상환경이기에
윈도우 상에서 wsl-우분투 경로를 파일탐색기로 접근이 가능하다.
이때 아래 사진처럼 그냥 윈도우 -> WSL 우분투 상으로 파일 복사를 수행하면 *.Zone.Identifier이라는
메타데이터 파일이 자동으로 생성된다.
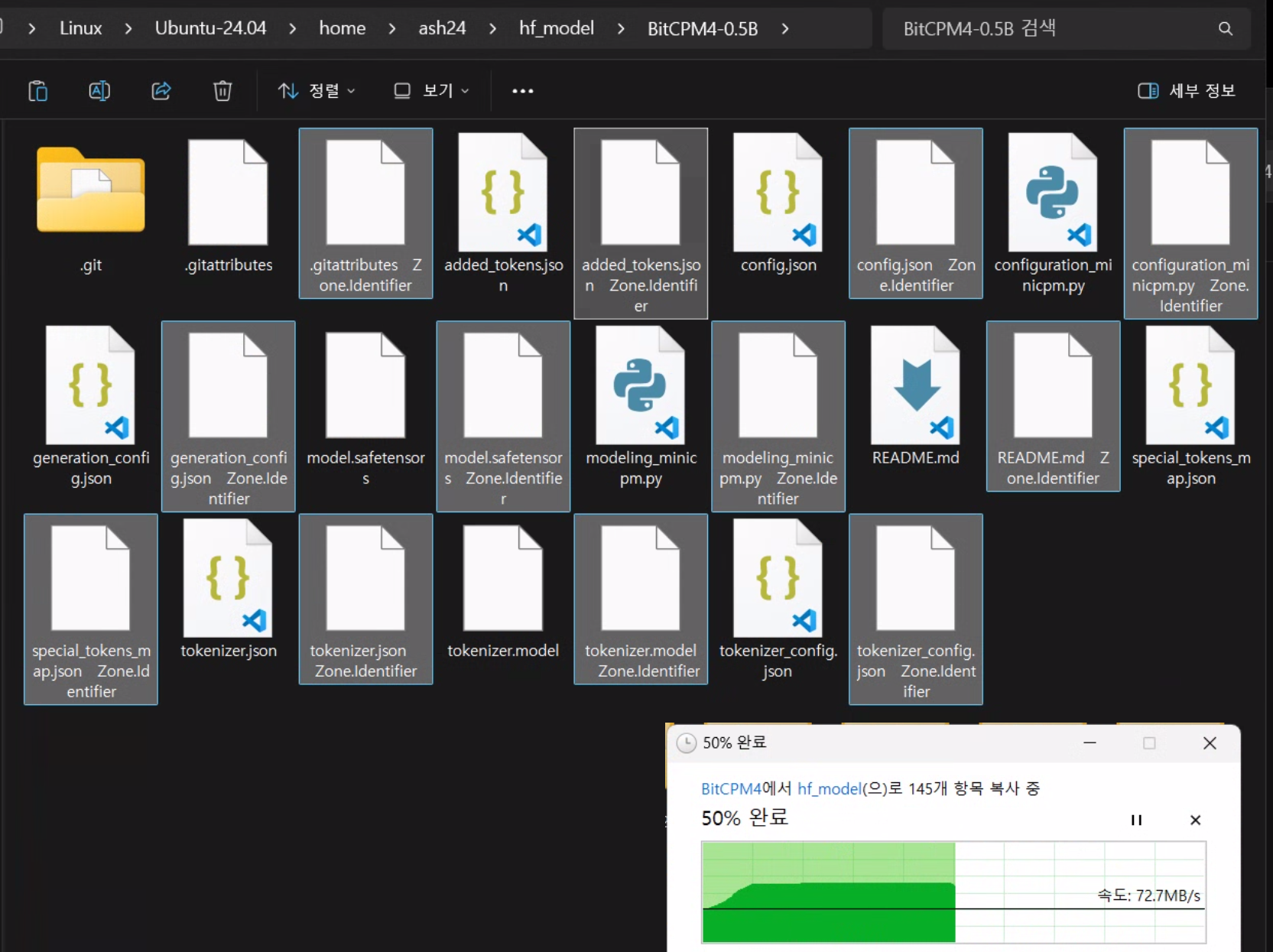
이게 필요가 없는 파일인데 워낙 많이 생성되기에 일괄 삭제를 해야 할 필요가 있다.
윈도우 탐색기에서 일일이 다 찾아서 삭제하는것도 방안이지만
wsl-우분투의 커맨드 창에서 아래의 명령어로 한큐에 삭제가 가능하다.
# 복사한 폴더에서
find . -type f -name "*Zone.Identifier*" -delete