
0. 파이썬 asyncio 라이브러리 설명
TensorRT-LLM에서 추론방식은
1) 동기 추론(Synchronous Inference)
2) 비동기 추론 (Asynchronous Inference)
3) 비동기 스트리밍 추론(Asynchronous Streaming)
3가지를 지원한다. 이 중 동기 추론은 구현하는데 어려움이 없으나, 문제는 비동기 추론인데 이를 제대로 구현하기 위해서는 먼저 파이썬 비동기 프로그래밍을 위한 라이브러리 asyncio에 대한 숙지가 필요하다.
0.1 asyncio 개요
asyncio는 하나의 쓰레드에서 여러 Task를 동시에 처리할 수 있도록 해주는 이벤트 루프기반의 라이브러리 이다.
- 이벤트 루프 : 비동기 작업을 관리하고 실행하는 핵심 메커니즘, Task를 순서대로 처리하면서, I/O 대기시간에는 다른 작업 실행이 가능하다.
- 코루틴(Coroutin) :
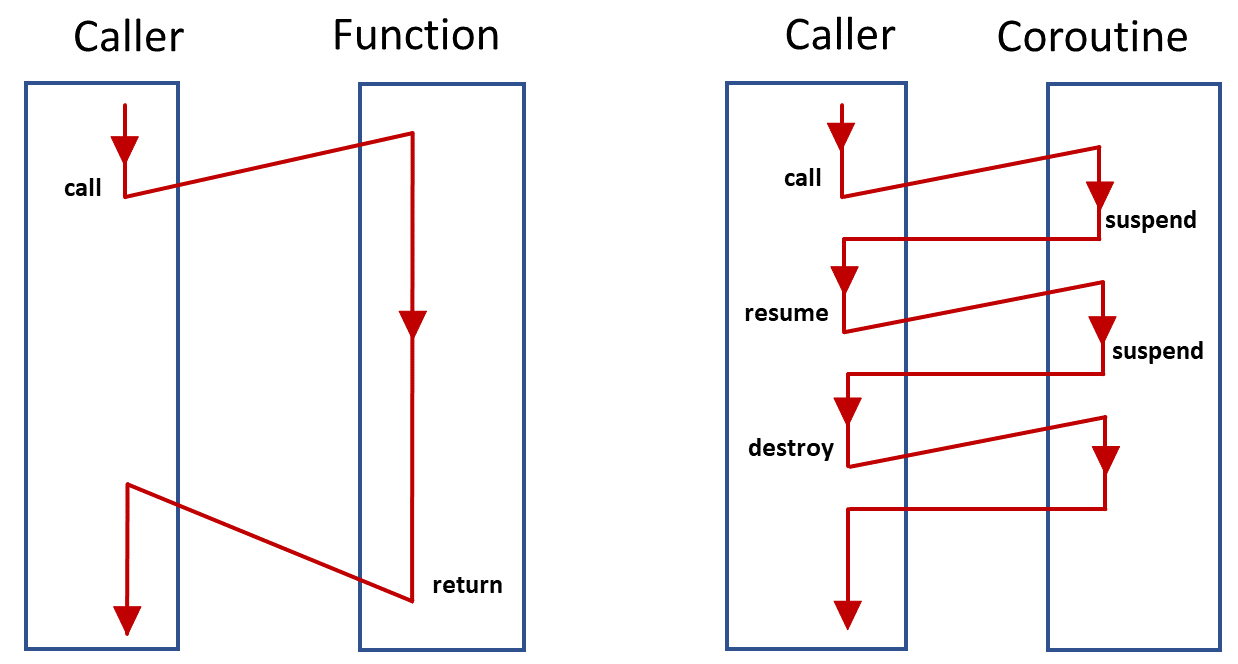
그림으로 보면 한번에 이해가 가능할 것 같은데 작업이 실행될 때 이를 중단하고(중단된 시점의 상태는 저장됨) 이를 다시 실행 가능하게끔 구성된 프로그래밍 구조이다.
그냥 간단하게 함수는 함수인데 중단/재개가 가능한 함수라 보면 된다.
따라서 함수 선언이랑 비슷하게async def으로 선언해주면 된다. await: 파이선 비동기 프로그래밍의 핵심 키워드로 실행하고 기다림의 트리거가 되는 키워드 이다. 즉, 작업을 진행하다가 다른 Task에게 제어권을 양보하는 기능이라 보면 된다.
사진으로 설명한다면syspend로 작업을 넘기는데await이 키워드가 트리거가 된다 보면 된다.
0.2 비동기 코드 테스트
아래 exam.py코드는 가장 기본적인 비동기 테스트 코드이다.
import asyncio
import time
# 'async def'로 비동기 함수를 정의합니다.
async def make_coffee():
print("커피를 내리기 시작합니다.")
# 'await asyncio.sleep(3)'은 3초 동안 기다리는 작업입니다.
# 이 시간 동안 파이썬은 다른 일을 할 수 있습니다.
await asyncio.sleep(3)
print("커피가 완성되었습니다!")
return "아메리카노"
# 비동기로 정의한 함수를 실행하면서 실행시간을 측정하는 함수입니다.
async def main():
start_time = time.time()
# 'await'로 make_coffee 작업이 끝날 때까지 기다립니다.
result = await make_coffee()
print(f"주문한 음료: {result}")
end_time = time.time()
print(f"총 걸린 시간: {end_time - start_time:.2f}초")
# 'asyncio.run()'으로 main 함수를 실행합니다.
# 이때 asyncio.run()은 이벤트 루프의 생성, 실행, 소멸을 한번에
# 수행하는 메서드이다.
if __name__ == "__main__":
asyncio.run(main())여기서 asyncio에서 제공하는 핵심 메서드는 알아 둘 필요성이 있다.
| 메서드 | 기능 |
|---|---|
| asyncio.run() | 비동기 프로그램 진입점 (이벤트 루프 자동 관리) |
| asyncio.create_task() | 코루틴을 태스크로 변환하여 동시 실행 |
| asyncio.sleep() | 비동기 대기 (다른 작업에 제어권 양보) |
| asyncio.gather() | 여러 코루틴을 동시 실행하고 모든 결과 대기 |
| asyncio.wait_for() | 타임아웃이 있는 코루틴 실행 |
| asyncio.wait() | 태스크들의 완료 조건을 세밀하게 제어 |
| asyncio.as_completed() | 완료되는 순서대로 결과 처리 |
| asyncio.Lock() | 비동기 뮤텍스 락 (공유 자원 보호) |
| asyncio.Semaphore() | 동시 실행 개수 제한 |
| asyncio.Event() | 비동기 이벤트 신호 전달 |
| asyncio.Queue() | 비동기 FIFO 큐 (생산자-소비자 패턴) |
| asyncio.open_connection() | TCP 클라이언트 연결 생성 |
| asyncio.start_server() | TCP 서버 생성 및 시작 |
asyncio.run(), asyncio.create_task(), asyncio.sleep(), *asyncio.gather() 4개의 메서드를 섞어서 고급 exam2.py를 설계해서 실습해보면 느낌이 확 올것이다.
import asyncio
"""
한개의 정의한 코루틴을 N개의 작업으로 생성한 뒤(create_task)
N개의 작업을 동시에 실행(gather)
이때 작업에는 지연시간을 달리해서 수행(sleep)
"""
async def my_coroutine(name, delay=0):
if delay > 0:
await asyncio.sleep(delay) # 지연시간 적용
print(f"{name} 작업 시작")
await asyncio.sleep(2) # 실제 작업 시간
print(f"{name} 작업 완료")
return f"{name} 결과"
async def main():
# 같은 코루틴으로 2개 태스크 생성 (한 개는 1초 지연)
task1 = asyncio.create_task(my_coroutine("작업1", delay=0)) # 즉시 시작
task2 = asyncio.create_task(my_coroutine("작업2", delay=1)) # 1초 후 시작
# 두 작업을 동시에 실행
results = await asyncio.gather(task1, task2)
print(results)
asyncio.run(main())0.3 ipynb파일에서 유닛 테스트
이 비동기 시스템을 구성하다 보면 유닛 테스트 코드를 설계할 때 *.ipynb와 같은 주피터 노트북 기반으로 코드작성 및 실습을 할 때가 있다.
이때 아래와 같이 exam.py를 적당히 코드셀로 나누어서 실행하도록 exam.ipynb를 생성하고 실행하면 런타임 에러가 발생한다.
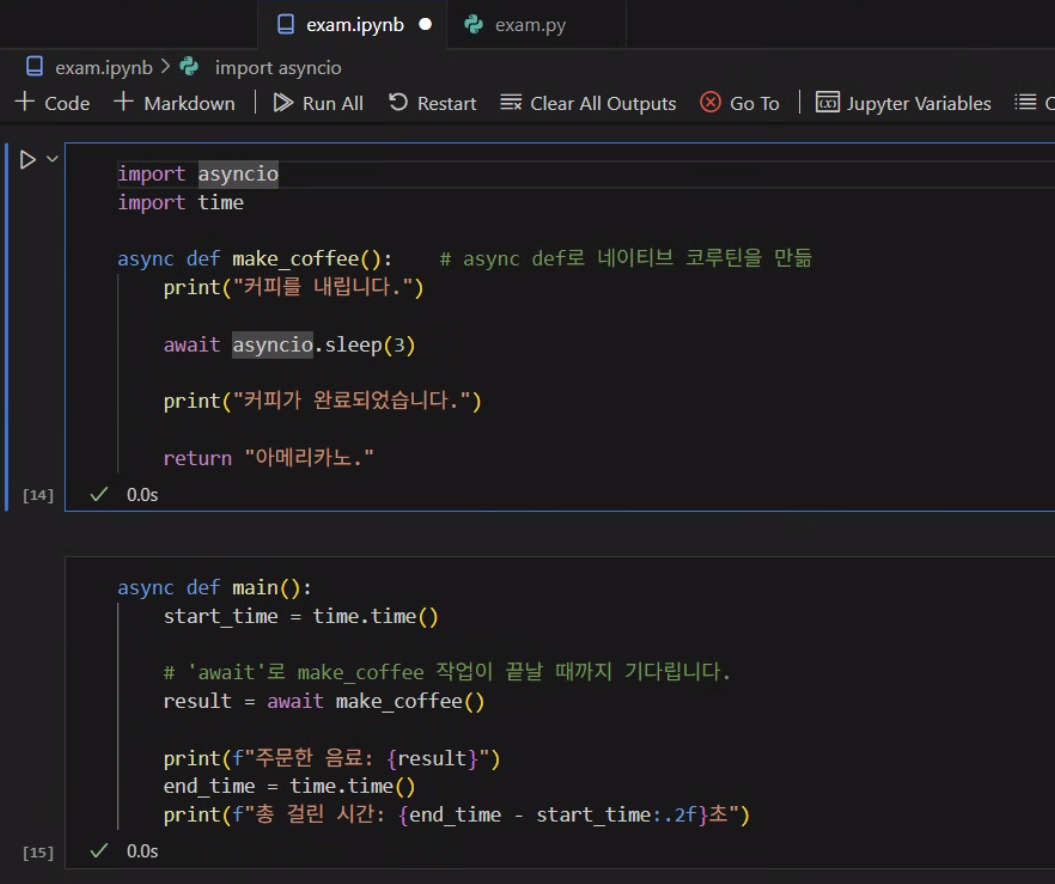
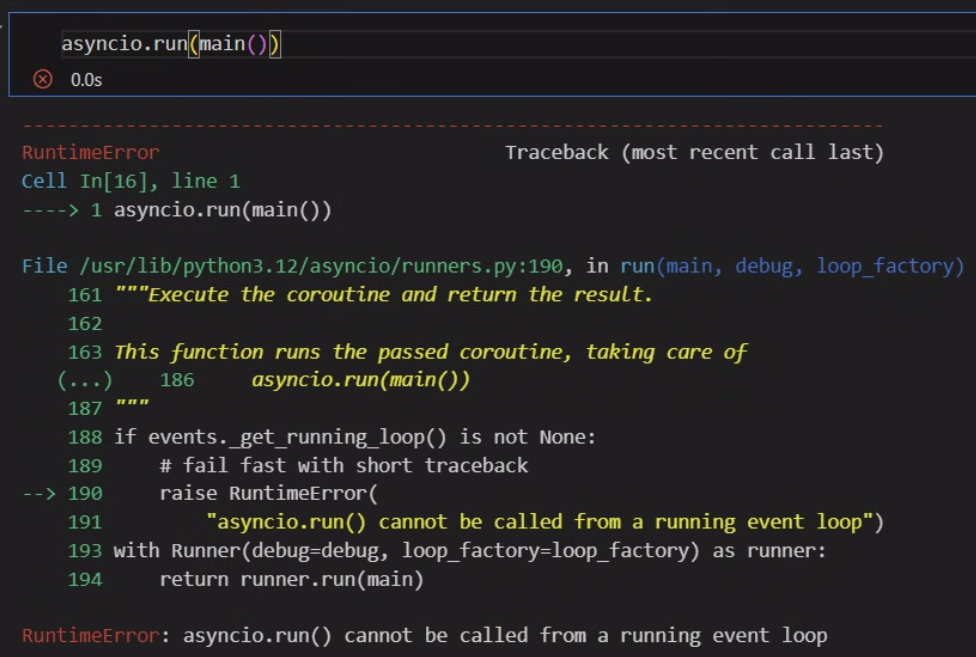
이 이유는 일반적인 파이썬 스크립트exam.py는 비동기 작업 관리자(이벤트 루프)가 동작하지 않지만, exam.ipynb에서는 이벤트 루프 작업 관리자가 기본적으로 동작한다.
(애초에 ipynb가 비동기 환경에서 코드실행을 의미한다)
따라서 새로운 이벤트 루프 관리자를 생성하는 asyncio.run() 명령어를 사용하면 이미 실행중인 이벤트 루프에서 다시 호출을 하기에 런타임 오류가 발생하는 것이다.
실제로 *.ipynb에서 이벤트 루프 관리자가 있는지는 아래의 코드로 확인할 수 있다.
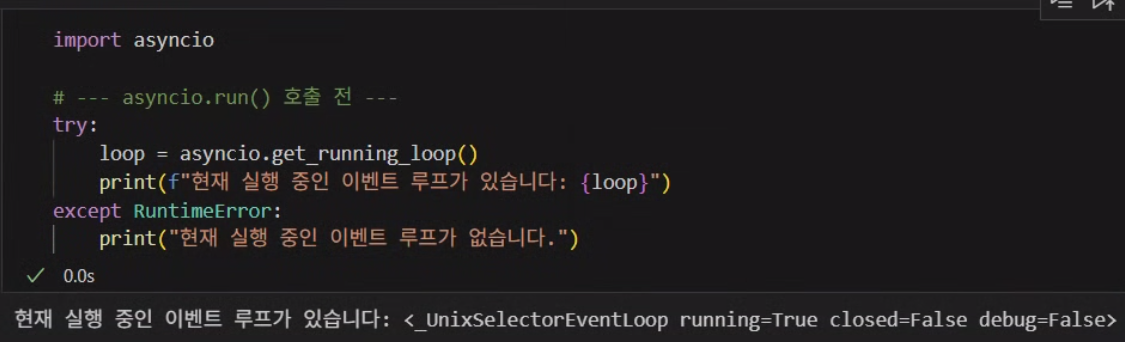
따라서 asyncio.run({여기에 비동기 함수 기입})구문은
이미 비동기 환경이 셋업된 exam.ipynb에서는 런타임 오류가 발생하기에 그냥 아래의 코드로
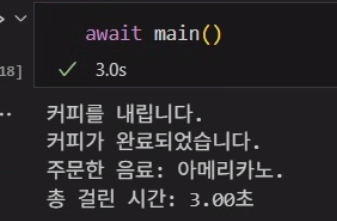
await main()위 코드로 코루틴 main()을 실행하고 완료가 될때까지 기다리라는 키워드를 적용한다.
await가 실행하고 기다림임을 잊지말자
*.ipynb 에서는
코드셀을 실행하는 ▶️ 이 버튼 자체가 따지고 본다면
await 코드셀 실행() 이렇게 기능한다.
그러니 그 안에서 또다른 await main()을 만나니 ▶️는 잠시 중단되고 제어권이 main()으로 넘어가서 실행 -> 완료까지 기다리는 것이다.
이제 2개의 함수를 정의하고 비동기로 순차실행
비동기로 동시실행 코드를 작성해보자
import asyncio
import time
async def make_coffee():
print("커피를 내립니다.")
await asyncio.sleep(3)
print("커피가 완료되었습니다.")
return "아메리카노."
async def toast_bread():
print("토스트를 굽습니다.")
await asyncio.sleep(2)
print("토스트가 완료되었습니다.")
return "토스트."비 동기로 순차 실행
async def main():
start_time = time.time()
print("--- 순차적 실행 시작 ---")
coffee_result = await make_coffee()
print(f"주문 1: {coffee_result}")
toast_result = await toast_bread()
print(f"주문 2: {toast_result}")
end_time = time.time()
print(f"총 걸린 시간: {end_time - start_time:.2f}초")비 동기로 동시 실행
async def gather_main():
start_time = time.time()
print("--- 함께 동시 실행 시작 ---")
results = await asyncio.gather(
make_coffee(),
toast_bread()
)
end_time = time.time()
print(f"받은 결과: {results}")
print(f"주문 1: {results[0]}")
print(f"주문 2: {results[1]}")
print(f"총 걸린 시간: {end_time - start_time:.2f}초")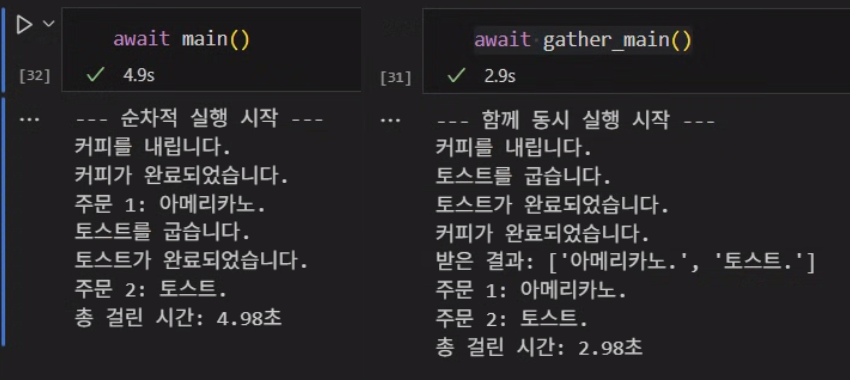
대충 이정도 했으면 파이썬의 비동기 라이브러리 asyncio에 대한 이해는 완료했을 것이다. 이제 다음단계로 넘어가자
1. TensorRT LLM 추론
1.1 모델 로드 및 기본 설정
import os
# RTX 5090용 CUDA 아키텍처 설정
os.environ['TORCH_CUDA_ARCH_LIST'] = '12.0'
# 로그 정보를 좀더 자세하게 출력
os.environ['TLLM_LOG_LEVEL']= 'ERROR'
from tensorrt_llm import LLM, SamplingParams
from tensorrt_llm.llmapi import KvCacheConfigMODEL_PATH = 'kanana-nano-2.1B-instruct'
MAX_TOKEN = 8192
kv_cache_config = KvCacheConfig(
# free_gpu_memory_fraction=0.35, # 남은 VRAM의 35% 를 KV캐시에 할당
max_tokens = MAX_TOKEN*4, # KV 캐시 용량을 “토큰 절대값”으로 계산함
)
# 모델 로드 코드
llm = LLM(
model=MODEL_PATH,
backend='pytorch', # 백앤드 파이토치로 다시 조정
kv_cache_config=kv_cache_config,
)
# LLM의 응답 출력을 위한 Output Parm 설정
sampling_params = SamplingParams(
temperature=0.8,
top_p=0.95
)먼저 모델 로드랑 추론을 위한 Output Parm설정은 위와 같이 진행한다
1.2 동기 추론
# LLM의 동기 추론 테스트
for output in llm.generate(prompts, sampling_params):
print("-"*50)
print(f"입력 Query: {output.prompt}")
print(f"생성 Response: {output.outputs[0].text}")
print("-"*50)이거는 뭐 누구나 알법한 쉬운 코드일 것이다.
참고로 llm.generate을 통해 반환되는 output은
https://nvidia.github.io/TensorRT-LLM/0.21.0/_modules/tensorrt_llm/llmapi/llm.html#RequestOutput
RequesOutput클래스를 상속받으며
이 클래스의 구조는 아래와 같다.
class RequestOutput(DetokenizedGenerationResultBase, GenerationResult):
"""The output data of a completion request to the LLM.
Attributes:
request_id (int): 추론 요청 작업에 할당되는 고유 ID
prompt (str, optional): 추론 요청 작업에 사용된 프롬프트
prompt_token_ids (List[int]): 추론 요청작업에 사용된 프롬프트를 토큰 ID로 변환한 값
outputs (List[CompletionOutput]): 추론 요청작업으로 얻어낸 추론 결과,
Beam Search나 다중 출력 시, 추론결과가 리스트 형태로 쌓임
context_logits (torch.Tensor, optional): 프롬프트를 모델이 토큰단위로 예측한 메타데이너
finished (bool): 전체 추론 요청이 끝낫는지 확인하는 Flag
"""여기서 물론 가장 중요한 값은 outputs이고 이 변수 또한 CompletionOutput클래스를 상속받은 객체이다
class CompletionOutput:
"""The output data of one completion output of a request.
Args:
index (int): 추론 요청 내에서 생성한 응답에 대한 또다른 인덱스 번호.
text (str): 실제 생성한 추론 텍스트 -> str로 생성됨.
token_ids (List[int], optional): 위 생성한 출력 텍스트들의 토큰 ID.
cumulative_logprob (float, optional): 생성한 텍스트들의 누적 로그 확률
logprobs (TokenLogprobs, optional): 생성한 텍스트들의 로그 확률
prompt_logprobs (TokenLogprobs, optional): 프롬프트의 토큰별 로그 확률
finish_reason (Literal['stop', 'length', 'timeout', 'cancelled'], optional): 시퀀스가 완료된 이유
stop_reason (int, str, optional): 추론을 종료시킨 문자열의 토큰 ID
generation_logits (torch.Tensor, optional): 추론 토큰 ID들에 대한 logits값
disaggregated_params (tensorrt_llm.disaggregated_params.DisaggregatedParams, optional): 분산 서빙에 필요 매개변수 메타데이터
Attributes:
length (int): 생성한 토큰의 개수
token_ids_diff (List[int]): 새로 생성한 토큰 ID
logprobs_diff (List[float]): 새로 생성한 토큰들의 로그 확률
text_diff (str): 새로 생성한 들
"""딱 봐도 추론 요청이 수행될 때 굉장히 많은 데이터가 생성됨을 알 수 있다...
1.2 비동기 추론
비 동기 추론부터는 generate 메서드가 아닌 generate_async을 사용하며
기본적으로 입출력 구조는 generate와 같으나
코루틴 인 점을 기억해야 한다
따라서 코루틴을 따로 정의해서 사용하는게 가장 마음이 편하다
import asyncio
async def textgeneration(prompt):
response = await llm.generate_async(prompt, sampling_params)
return response이렇게 코루틴을 하나 선언하고 asyncio.gather를 사용하면 비동기 추론으로 batch추론을 한번에 수행g할 수 있다..
import asyncio
task_list = []
for prompt in prompts:
task_list.append(textgeneration(prompt))
# 리스트 내용을 개별 인자로 펼쳐서 전달하는 연산자
# 따지고 보면 비동기 배치 추론이 진행됨
outputs = await asyncio.gather(*task_list)
for output in outputs:
print("-"*50)
print(f"입력 Query: {output.prompt}")
print(f"생성 Response: {output.outputs[0].text}")
print("-"*50)1.3 비동기 스트리밍 추론
마지막으로 비동기 스트리밍 추론 또한 generate_async을 사용하지만
인자값으로 streaming=True을 적용하면 된다.
import asyncio
async def textgeneration(prompt):
response = llm.generate_async(prompt, sampling_params,
streaming=True)
return response스트리밍 추론의 경우 어쨋든 추론 텍스트 결과값은
outputs[0].text을 통해서 얻어내면 되는데
이 메서드의 문제점이 과거 시점에서 추론한 텍스트가 계속 누적해서 쌓인다는 부분이 있다.
따라서 과거 시점에 쌓여있던 텍스트는 삭제하고 현재 시점에서 새로이 생성한 텍스트만 print(str, end='', flush=True)이렇게 처리해야만 제대로 추론 결과를 스트리밍 방식으로 얻어 낼 수 있다.
for prompt in prompts:
print("-"*50)
response = await textgeneration(prompt)
print(f'입력 Query : {response.prompt}')
prev_txt = ""
print(f'생성 response : ', end='')
async for chunk in response:
curr_txt = chunk.outputs[0].text
token_txt = curr_txt[len(prev_txt):]
print(token_txt, end='', flush=True)
prev_txt = curr_txt
print()
print("-"*50)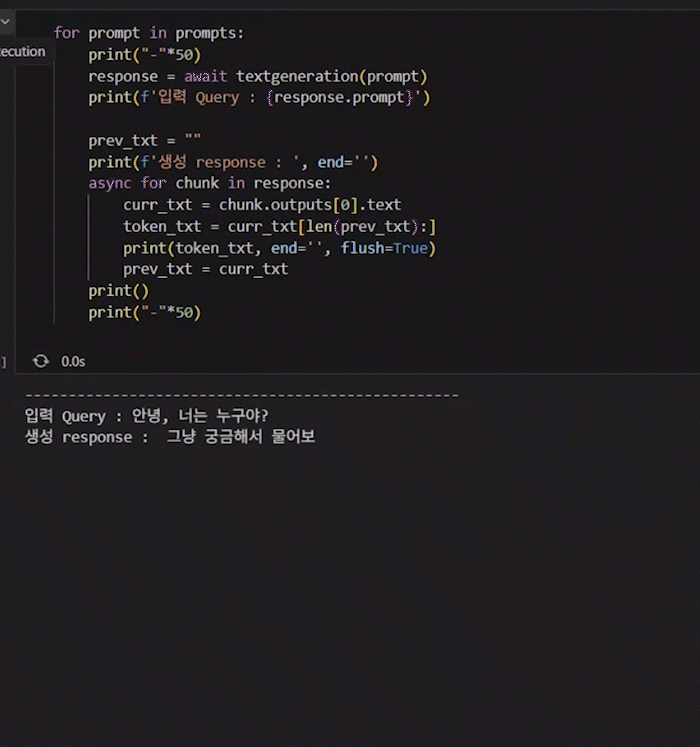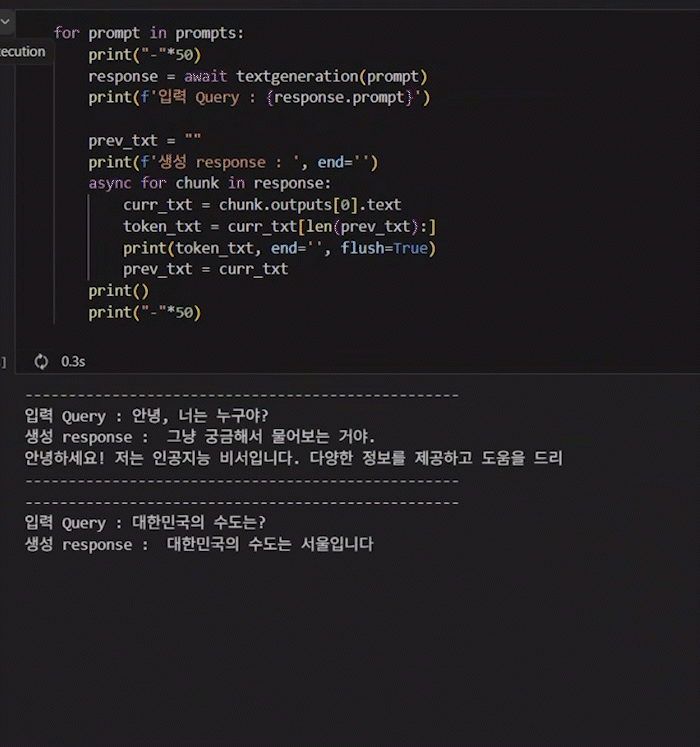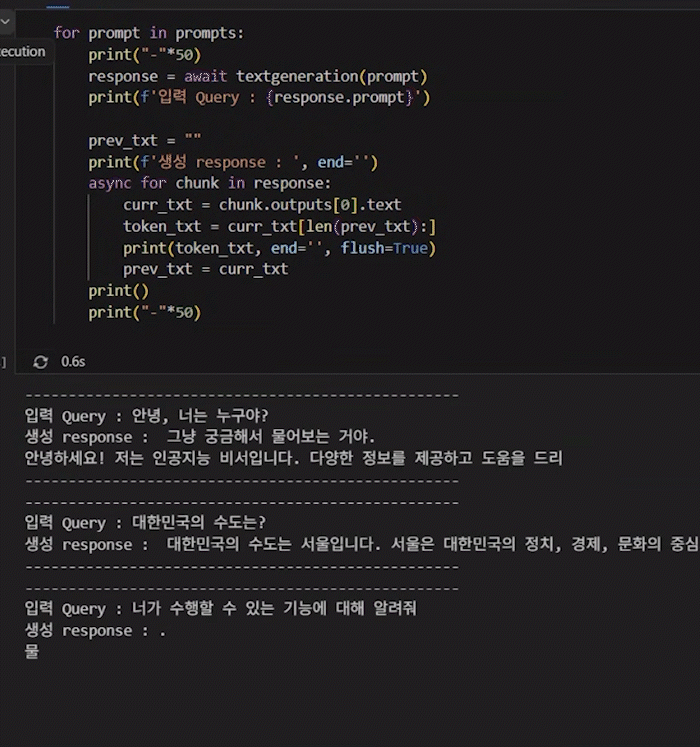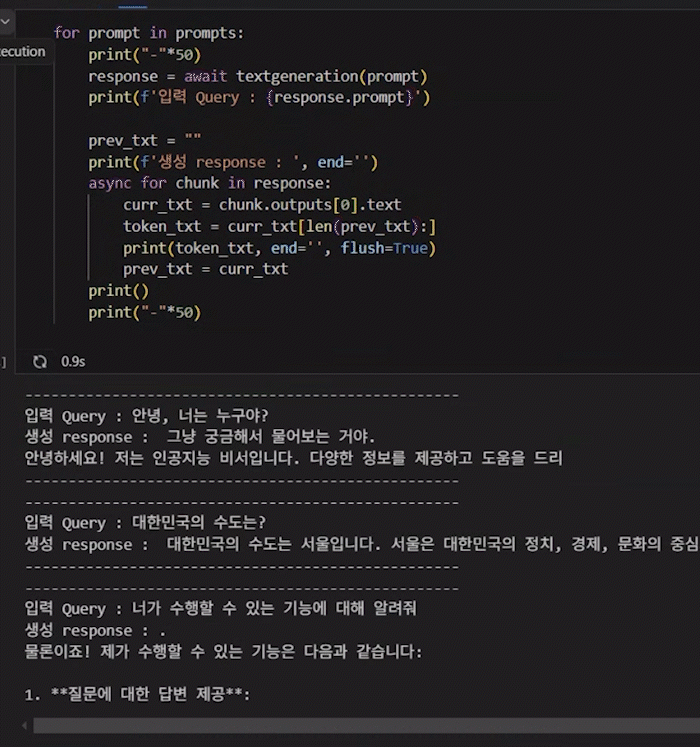
마지막 비동기 스트리밍은 애니메이션으로 첨부했는데 TenserRT-LLM이 워낙 빠르게 추론을 수행하니 속도는 0.5배속으로 결과를 첨부한다.
