
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
이번 챕터는 좀 쉬어가는 내용으로 포스팅을 작성하고자 한다.
주제는
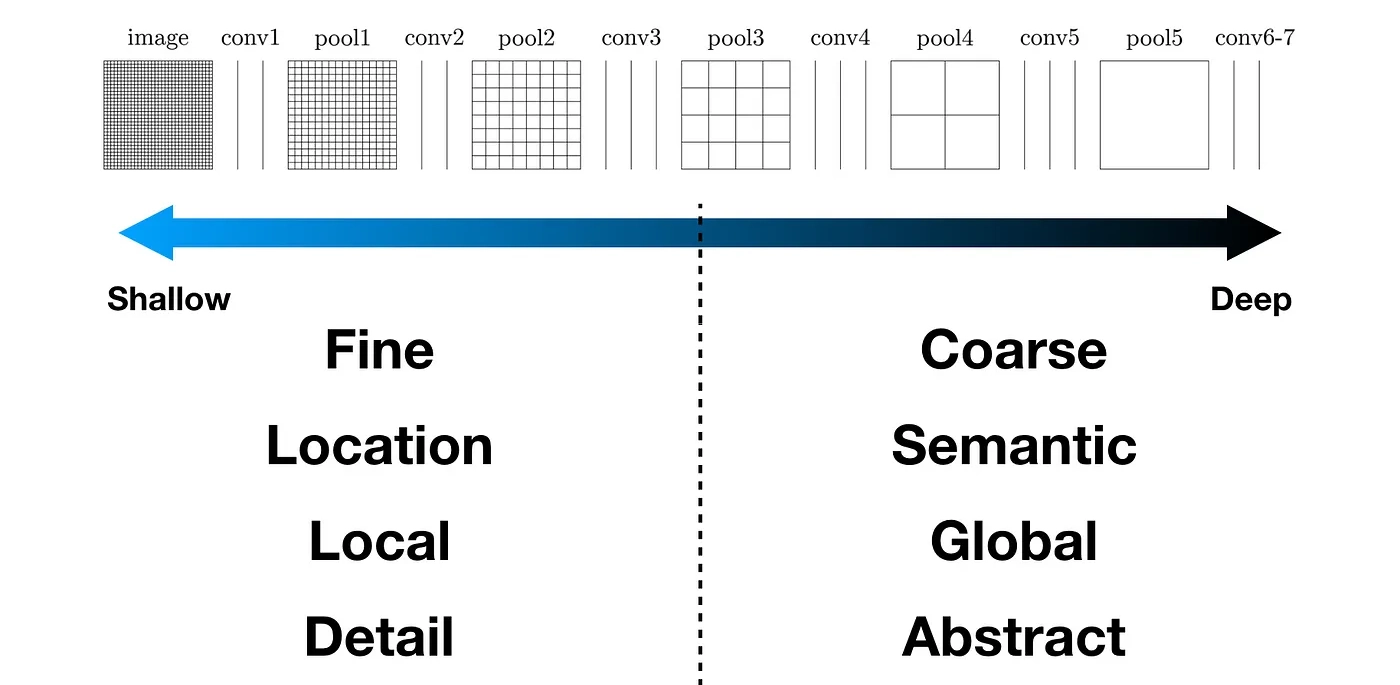 위 이미지처럼 CNN계열의 네트워크에서 출력되는 Feature Map이 어떤 특성을 가지고 있는지에 대한 강의 복기이다.
위 이미지처럼 CNN계열의 네트워크에서 출력되는 Feature Map이 어떤 특성을 가지고 있는지에 대한 강의 복기이다.
결론만 이야기 하자면
Shallow layer(얕은 층)에서 출력되는 Feature Map에서는 이미지의 자세, 위치같은 Loacl정보를 포함하고 있으며,
Deep layers(깊은 층)에서 출력되는 Feature Map는 이미지의 추상적, 종합적인 Global 정보를 주로 포함하고 있다.
라는 것을 시각적으로 확인해 보자... 라는 것이다.
그래서 이전 포스팅에서 학습이 완료된 모델을 아래의 코드로 저장
#모델의 가중치만 저장하기
MODEL_NAME = 'SimpleNet'
torch.save(ex_model.state_dict(), f'{MODEL_NAME}.pth')
# 모델 전체를 저장 (모델 구조와 가중치를 포함)
torch.save(ex_model, 'SimpleNe3_model.pth')이 부분부터 설명을 이어나가고자 한다.
딥러닝 모델의 훈련을 완료했으면, 완료한 모델을 저장하는 방법은 torch.save 메서드를 사용한다
이 torch.save 메서드는 직렬화(Serialization)된 객체를 디스크에 저장 하는 기능이라는데...
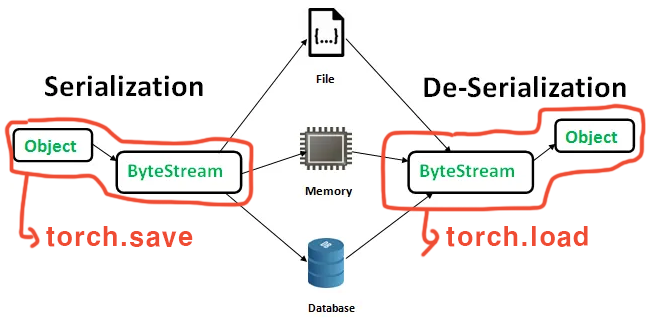 위 사진에서 Object에 해당하는 객체를 ByteStream으로 바꿔주는 작업을 해주는게
위 사진에서 Object에 해당하는 객체를 ByteStream으로 바꿔주는 작업을 해주는게 torch.save이고 이 반대과정이 torch.load 라고 보면 된다.
여기가 참 이해가 안되서 이곳저곳 자료를 찾아보니
대충 그림으로 표현하면 이렇게 될 것 같다.
 이렇게 모델을 저장할 때 바이너리 파일로 저장한다는데
이렇게 모델을 저장할 때 바이너리 파일로 저장한다는데
좀 낡은 사람이라면 이 바이너리 파일에 대해 한번은 접해봣을 것이다
바로 *.bin파일이다.
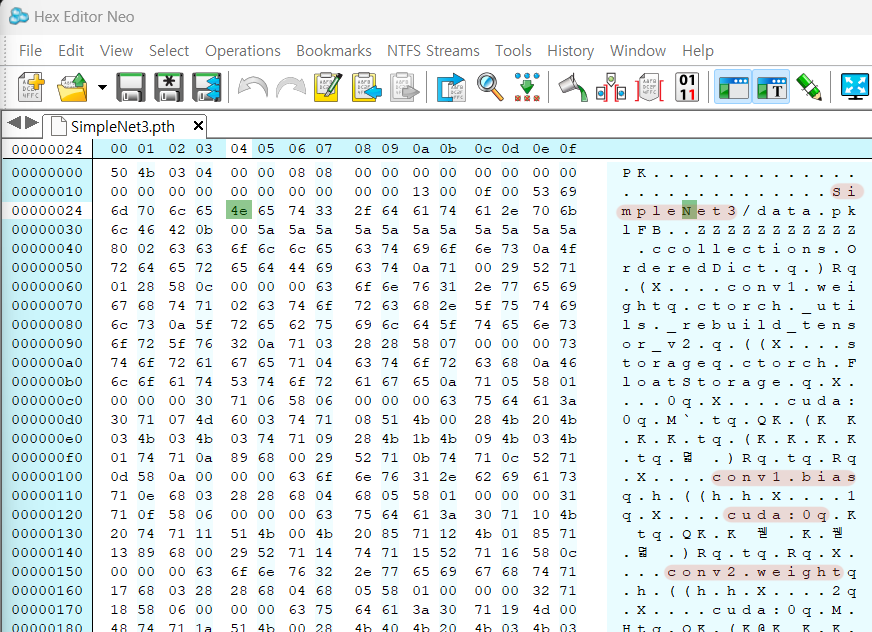 실제로 저장한
실제로 저장한 *.pth 파일을 Hex Editor으로 불러오는게 가능하고, 열었을 때 어느정도 저장된 모델의 정보를 유추해 보는게 가능하다.
실제로도
torch.save(ex_model.state_dict(), f'{MODEL_NAME}.pth')이 코드에서 *.pth 확장자로 지정하여 저장하는건 크게 의미가 없고 흔히 사용되는 바이너리 파일 확장자인 *.bin으로 저장해도 나중에 load할 때 문제가 발생하지 않는다.
이때 궂이 *.pth확장자로 저장을 권장하는건
저장된 딥러닝 모델이 PyTorch 라이브러리를 사용하여 설계된 모델이라는 것을 표현하기 위한 관례 라고 이해하고 넘어가면 될 것 같다.
이 바이너리 형식으로 저장된 것은 어떻게 보면 데이터의 '암호화'으로 볼 수 있으며,torch.load 메서드는 암호화된 데이터의 복호화으로 볼 수 있다.
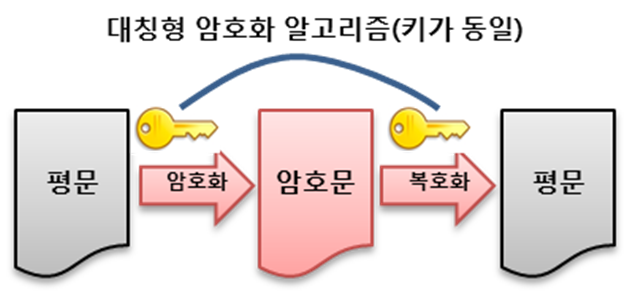 여기서 데이터를 복호화 하려면 '복호화 키'라는 것이 필요하다.
여기서 데이터를 복호화 하려면 '복호화 키'라는 것이 필요하다.
01010으로 이뤄진 이진수 데이터를 다시 사용 가능한 데이터 구조로 바꾸려면 어떤 구조로 설계되어 있는지를 알아야 데이터를 복원할 수 있기 때문이다.
그래서 torch.load 메서드를 사용하여 저장된 *.pth를 불러올 때는 항상 설계한 딥러닝 모델의 Class를 먼저 선언을 해줘야 한다.
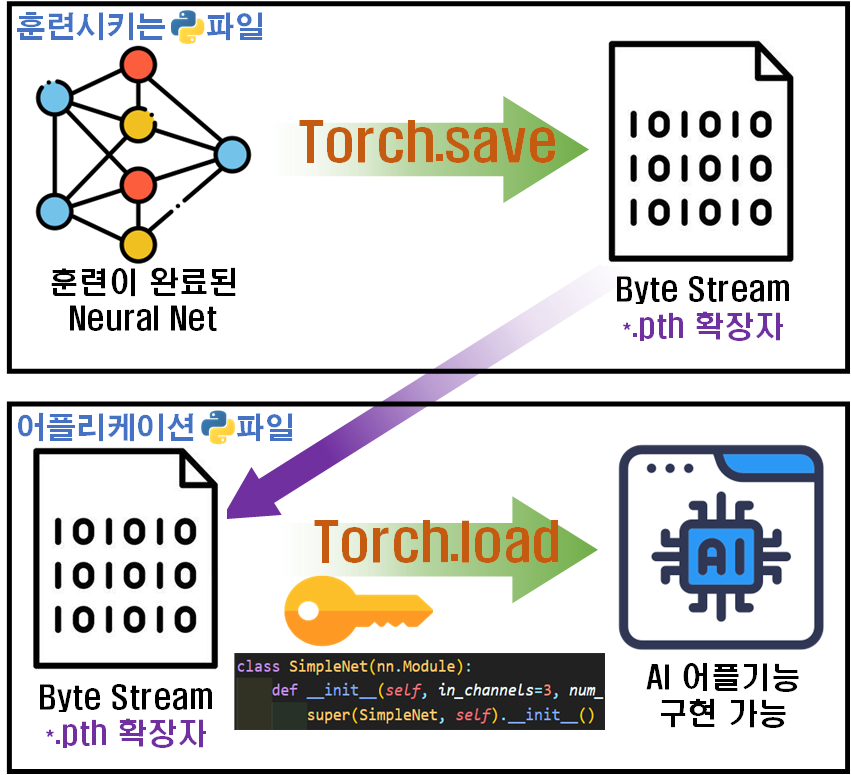 그림으로 표현하면 위 사진과 같으며
그림으로 표현하면 위 사진과 같으며
1) 딥러닝 모델의 훈련 train.py파일에서 훈련 수행+완료 후 바이너리 파일을 만들었다면
2) 훈련된 모델을 사용한 App.py파일에서 바이너리 파일을 불러오고 이를 사용 가능하게 복호화 할때는 train.py에서 설계한 딥러닝 모델의 클래스와 동일한 구조를 가진 모델 클래스 정보가 필요하다.
여기서 저장 옵션으로
torch.save(ex_model.state_dict(), f'{MODEL_NAME}.pth').state_dict() 메서드를 붙여서 저장하는 것을 권장하는데
이 이유는 나중에 torch.load메서드로 암호화된 *.pth를 복호화 할 때 복호화 키에 해당하는 모델의 클래스 정보(모델의 구조) 가 조금이라도 어긋나 있으면
복호화가 재대로 수행이 안된다.
음... 이게 확 와닿지 않는데
복호화에 사용된 모델의 클래스가 훈련때 사용된 모델의 클래스랑 비교하여 글씨 토씨 하나 다르면 안된다.
으로 이해하면 될 것 같다.
예를 들어 훈련시켰던 모델의 클래스 이름을
class SimpleNet(nn.Module):이렇게 정의 했고 이것의 저장을 torch.save로 했다면
torch.load로 불러오는 클래스 이름이
class Simple_Net(nn.Module):이런식으로 단어 하나만 차이나도 바로 에러를 뿜뿜하게 될 것이다.
그래서 공식 문서에서도
torch.save(model.state_dict(), PATH)위와 같이 .state_dict() 옵션을 붙여서 저장하는 것을 권장하고 있다.
모델의 저장에 .state_dict()옵션을 사용했으니
훈련이 완료된 모델의 불러오기 또한
model = TheModelClass(*args, **kwargs)
model.load_state_dict(torch.load(PATH))
model.eval()으로 진행하면 되며, 여기서 *args, **kwargs 인자값은
훈련이 완료된 모델에 필요한 인자값을 넣어주는 것인데
이전 포스팅에서 사용된 SimpleNet()은 딱히 인자값이 필요없게 설계햇으니
아무값도 안 넣어주면 된다.
그리고 훈련이 완료된 모델을 불러올 때
load_state_dict(torch.load()) 옵션으로 모델의 로딩 옵션을 설정하여 불러오면 된다.
그리고 마지막에
model.eval() 코드를 통하여
훈련이 완료된 모델을 사용하기 직전 Dropout, BatchNormalization 기능을 평가모드로 설정하여
위 두 기능을 비활성화 한다
이 기능을 비활성화 하고 모델의 추론을 수행해야
성능이 재대로 나온다.
이렇게 하고
추론 기능을 수행하기 위해
이런 강아지 사진을 불러와서 모델에 입력 후
각 Conv 레이어를 지나갈 때마다 이 강아지 사진이 어떻게 변하는지를 이미지로 시각화 하면 아래와 같다.
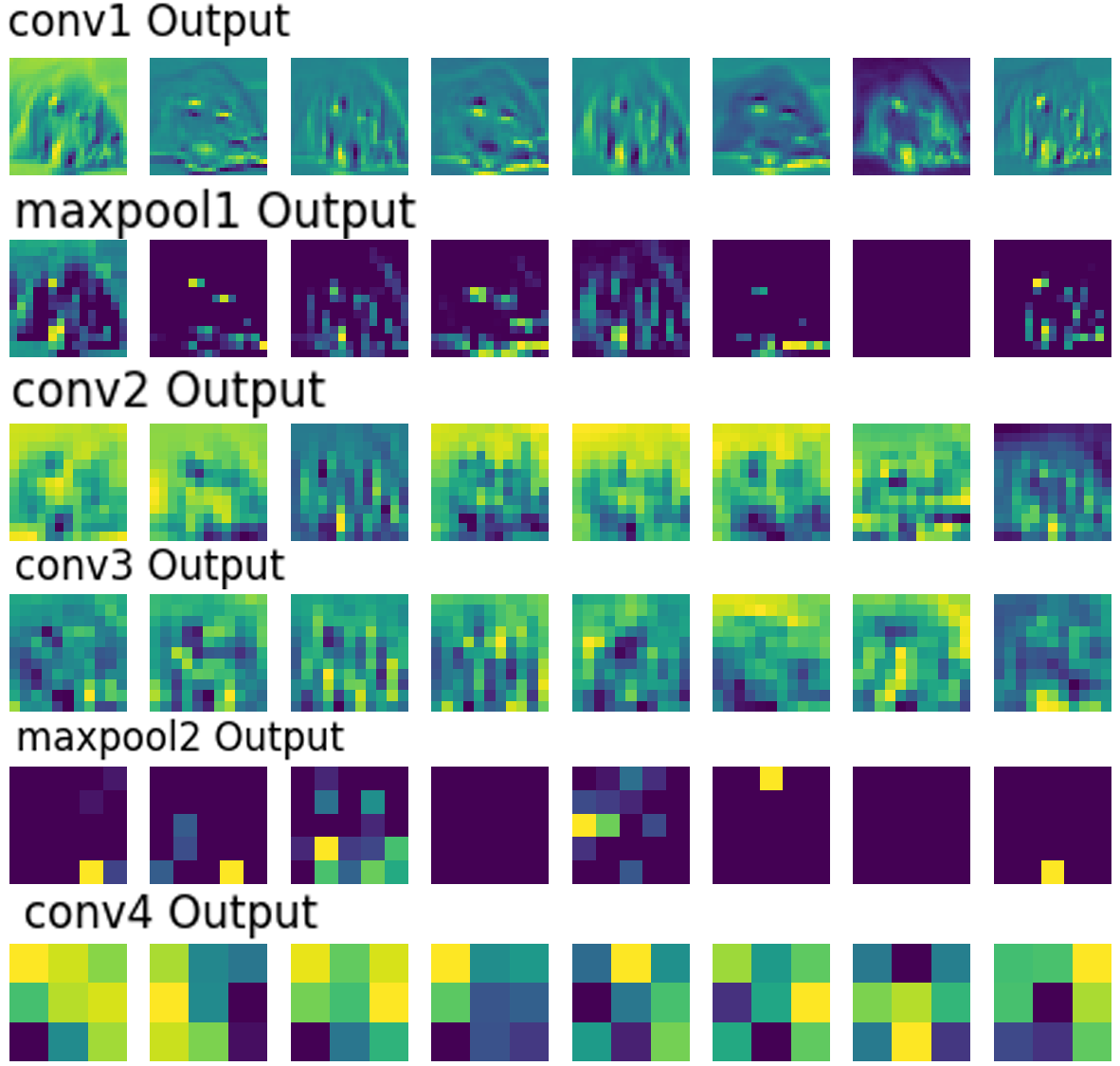
Shallow layer(얕은 층)에서 출력되는 Feature map은 그나마 사람이 알아볼 만한 이미지 정보로 Display이 가능하나.
Deep layers(깊은 층)에서 출력되는 Feature map은 알아보기 힘든 이미지 정보로 Display되는 것을 알 수 있다.
이렇게 각 층별 출력되는 Feature map 정보가 어떤 식으로 변형되는지 알아보는게
이번 강의의 복기이다...
사실 중간 과정물의 출력보다는
훈련이 완료된 모델의 저장 원리, 저장 후 불러오는 과정에 대한 이해가 더 어려운 파트였다...
