
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. AlexNet배경
Alex Krizhevsky, Geoffrey Hinton이 공동으로 설계한 CNN아키텍쳐이며, ImageNet LSVRC-2012 대회에서 Top5 Error 성능결과 15.3%를 달성하고
CNN의 훈련에 GPU를 사용한 의미가 있는 논문이다.
AlexNet의 주요한 기여 라고 한다면
1) 5개의 Conv Layer -> 3개의 FCL
-> 일반적인 Conv Layer의 아키텍처가 정립됨
2) AF(Activation Function)에 Tanh, Sigmoid보다 더 성능이 좋다 평가되는 ReLU의 도입
3) Dropout 기법의 도입
으로 보면 된다
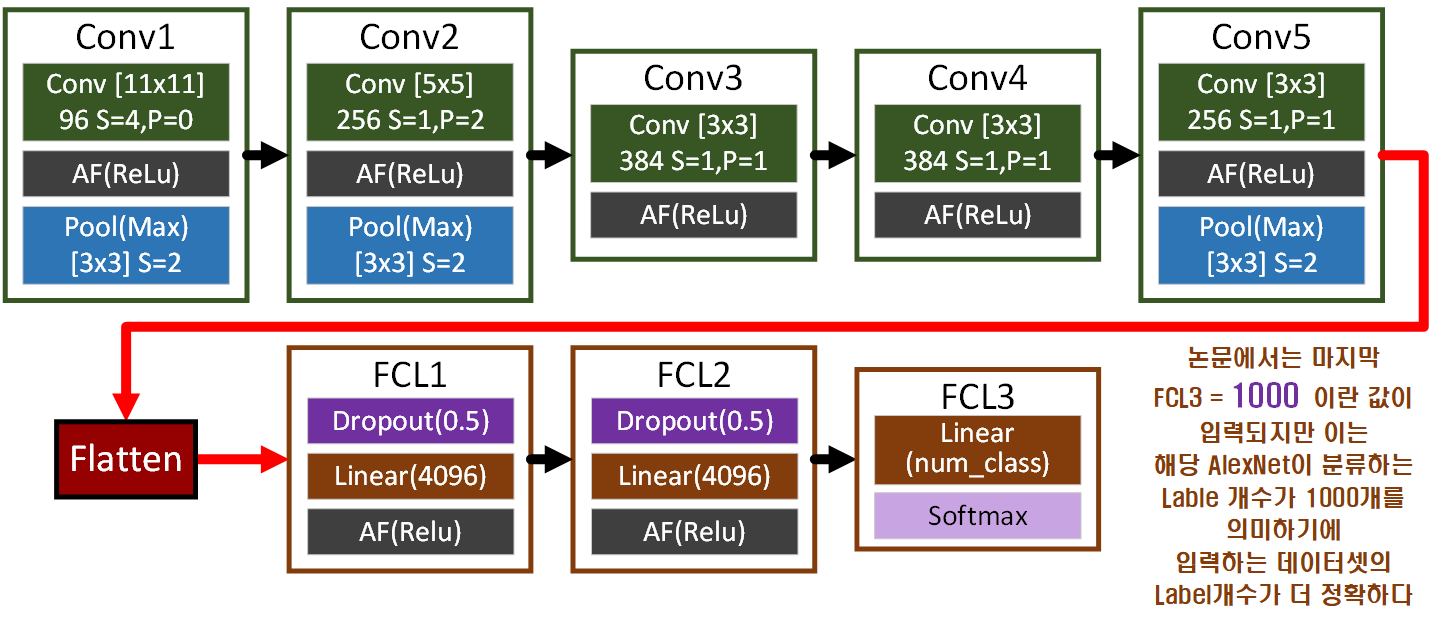
2. AlexNet의 아키텍쳐
2.0 아키텍쳐의 디버깅
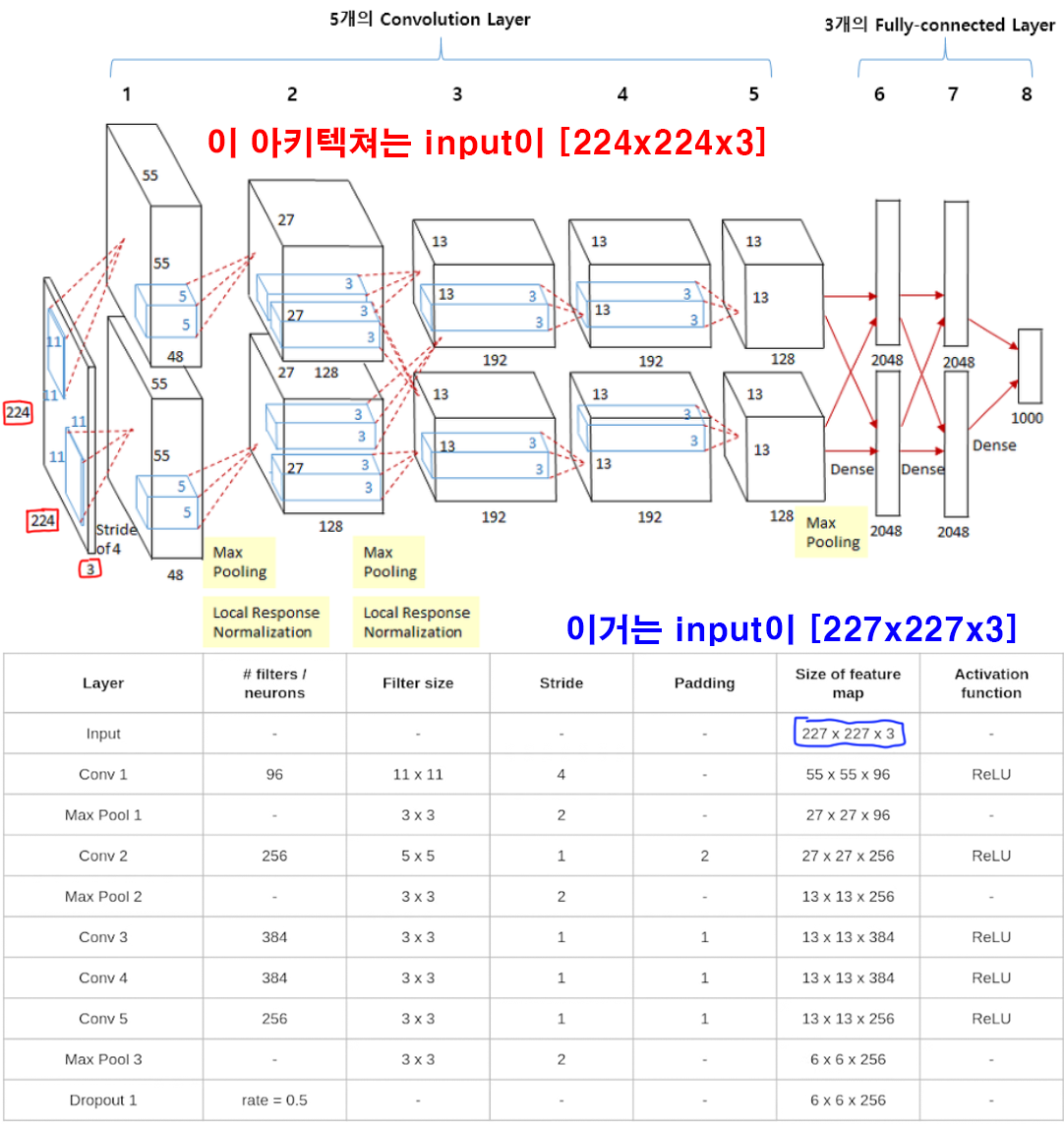 AlexNet는 워낙 잘 알려지기도 했고 CNN의 입문에 해당하는 아키텍쳐이기에 많은 사람들이 코드 및 논문 리뷰가 이뤄진 부분이다.
AlexNet는 워낙 잘 알려지기도 했고 CNN의 입문에 해당하는 아키텍쳐이기에 많은 사람들이 코드 및 논문 리뷰가 이뤄진 부분이다.
여기서 좀 주의를 해야 할게 어느 리뷰에서는 input_img의 구조가 [224x224x3] 다른데서는 [227x227x3] 이렇게 두가지로 되어 있는 코드가 있을 것이다.
결론만 말하면 둘다 AlexNet를 구현한 코드, 논문이기도 하다.
하지만 두 출처에서 코드를 섞어서 구현하면 큰 문제가 발생한다.
바로 Conv Flatten FLC 로 넘어갈 때 여기서 차원문제가 발생한다.
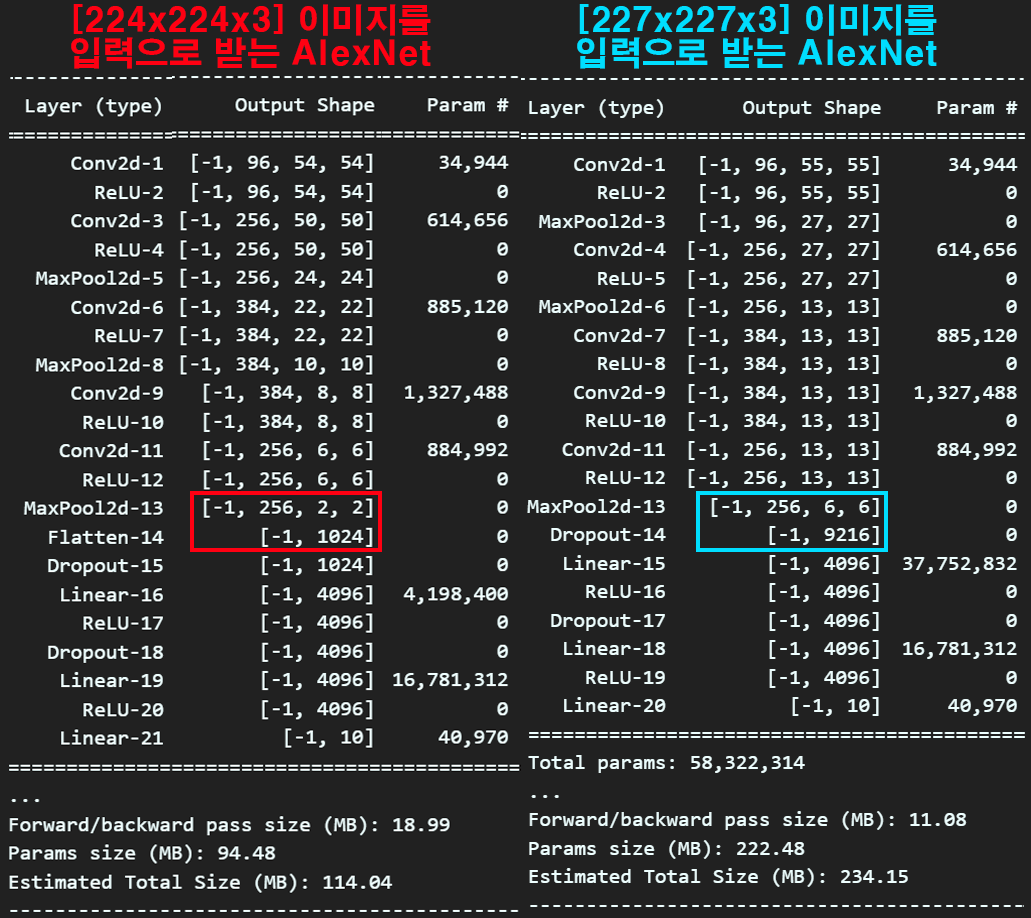 위 사진은 똑같이 AlexNet를 구현했는데 입력받는 이미지가 [224x224x3]인 경우, [227x227x3]에 대한 모델을 설계하고 이를 요약한 정보이다.
위 사진은 똑같이 AlexNet를 구현했는데 입력받는 이미지가 [224x224x3]인 경우, [227x227x3]에 대한 모델을 설계하고 이를 요약한 정보이다.
처음 부분 Conv의 출력 Feature map이 [96x54x54], [96x55x55]로 1씩 살짝 차이나던것이
[256x2x2] [1024]
[256x6x6] [9216]
으로 확 차이가 나게 되고, 여기서 코드에러가 신나게 터지게 될 것이다.
그래서 CNN모델 설계할 때 input_img 크기를 꼭 고정을 해야 하는 이유가 이미지 크기가 가변되면
Conv Flatten FLC 여기서 대응이 불가능해진다.
그래서 이미지의 전처리에 해당하는 transformation 과정에서 항상 Resize를 고정값 으로 두는 것이다.
딥러닝 모델은 꽤나 동적이지 못하게 설계가 되어 있다...
그래서 이 부분을 대처를 하려면 어떻게 해야할까?
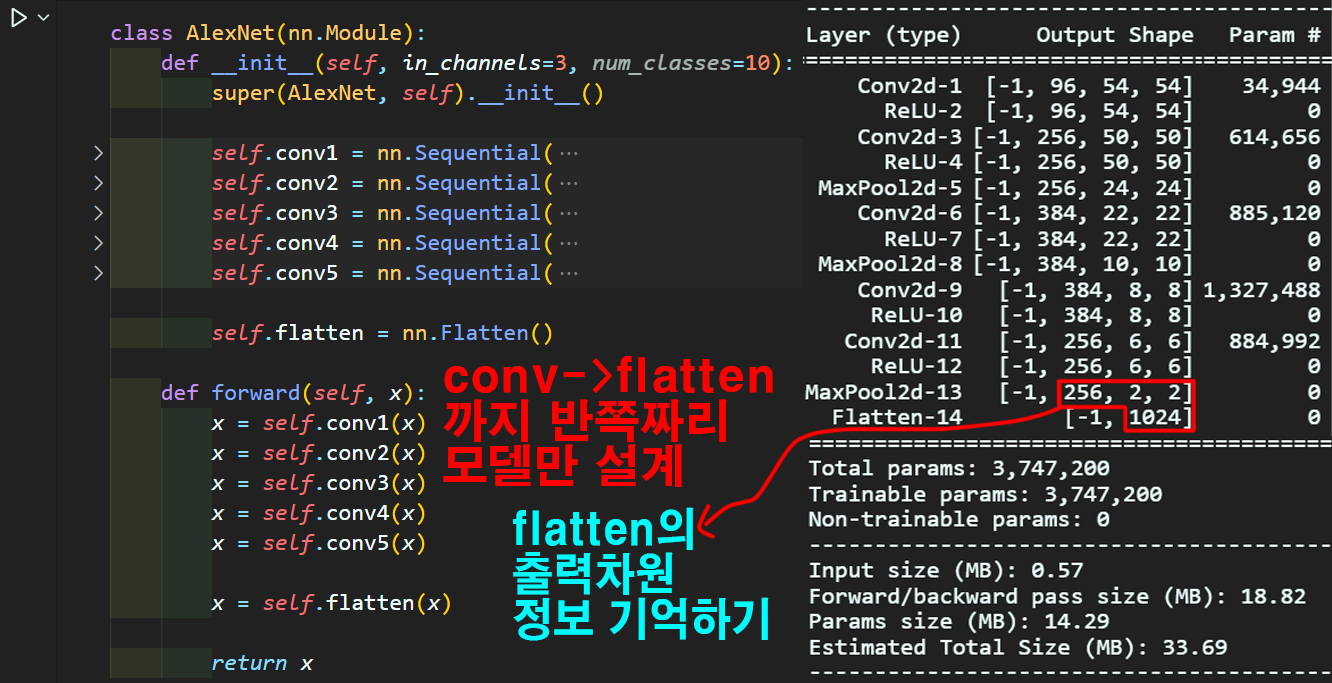
Conv Flatten 여기까지만 모델을 반쪽짜리로 설계해서
입력하고자 하는 이미지를 넣어서 summary 작업을 한 뒤,
출력되는 Flatten의 차원값을 저장해서 FCL의 시작 레이어(nn.Linear(입력feature, 출력feature))에 적용하면 된다.
이렇게 다른이의 코드를 리뷰할 때
여러 코드를 섞어서 개발을 수행한다면
코드오류가 발생할 만한 위치까지만
모델 설계 후 summary로 디버깅을 수행
이런식으로 에러를 잡고 코드를 섞어써야 한다.
요즘 ChatGPT가 워낙 성능이 좋아서 코드오류를 잡아주는데
이 차원 문제가 나는 부분까지 코드오류를 잡아달라고 하면
Semantic error을 잡아주는게 아니라 Runtime/Semantic/Syntax error을 잡는 것을 우선으로 하기에
잘못된 답변을 도출해내는 가능성이 매우 농후하다.
뭐.. 코드 돌려보면 이상하게 Train/val 부분의 코드가 동작을 안한다던가 Accuracy/Loss가 성능이 떨어진다던가 할거다...
2.1 AlexNet 설계
설계한 모델의 디버깅 기법에 대한 설명까지 진행했으니
AlexNet를 도식도를 그려가면서 설계를 진행해보자
import torch
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, in_channels=3, num_classes=10):
super(AlexNet, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
self.conv2 = nn.Sequential(
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
self.conv3 = nn.Sequential(
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
self.conv4 = nn.Sequential(
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU()
)
self.conv5 = nn.Sequential(
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
self.flatten = nn.Flatten()
self.dense1 = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 2 * 2, 4096),
nn.ReLU(inplace=True),
)
self.dense2 = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
)
self.dense3 = nn.Sequential(
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.flatten(x)
x = self.dense1(x)
x = self.dense2(x)
x = self.dense3(x)
return xfrom torchsummary import summary #설계한 모델의 요약본 출력 모듈
model = AlexNet()
summary(model, input_size=(3, 224, 224), device='cpu')설계한 모델은 GPU에서 학습을 진행하려 하니 이거 잊지말자
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
model = AlexNet()
model.to(device)
summary(model, input_size=(3, 224, 224), device=device.type)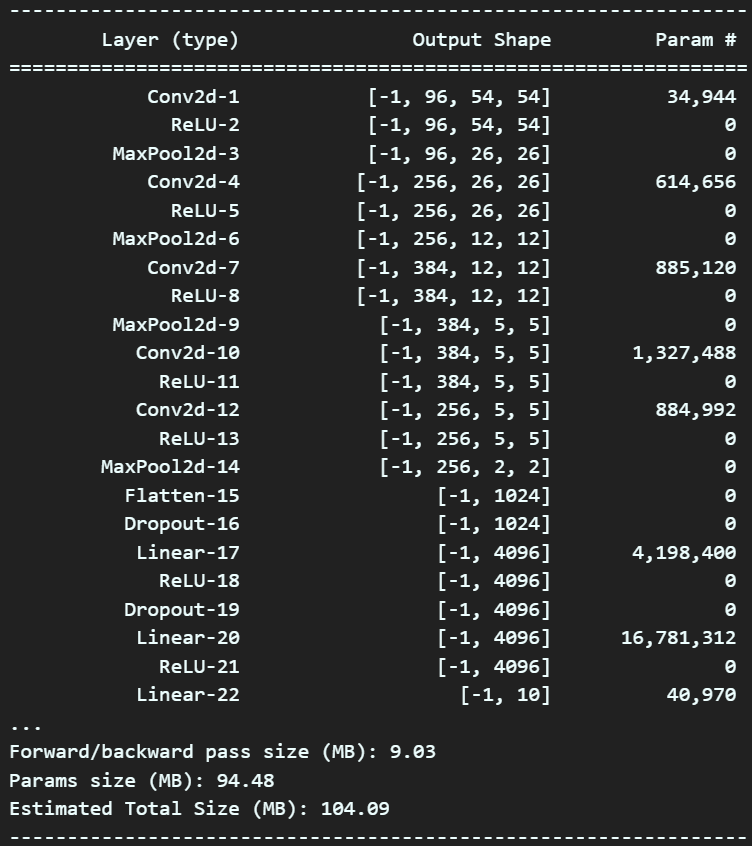
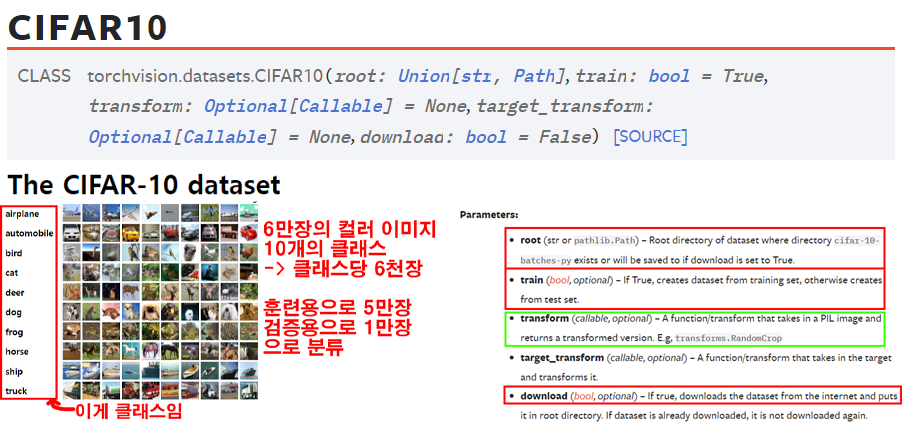
3.데이터셋 전처리
데이터셋은 9. CNN 모델 만들기 - 1) 데이터셋까지에 포스팅했던
CIFAR10을 그대로 사용하기로 한다.
[폴더경로]는 저장할 폴더 설정하면 된다(귀찮으면 ./data)
import torchvision
from torchvision import datasets
trainset = datasets.CIFAR10(root='[폴더경로]',
train=True,
download=True)
testset = datasets.CIFAR10(root='[폴더경로]',
train=False,
download=True)from torchvision.transforms import v2
#CIFAR-10의 정규화 파라미터
CIFAR_N_value = [[0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]]
#v2 API로 데이터 전처리 방식 정의
train_transformation = v2.Compose([
v2.RandomHorizontalFlip(p=0.5), #50퍼센트 확률로 이미지 반전
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=CIFAR_N_value[0], std=CIFAR_N_value[1])
])
test_transformation = v2.Compose([
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=CIFAR_N_value[0], std=CIFAR_N_value[1])
])
#이미지에 v2전처리 방식을 적용
trainset.transform = train_transformation
testset.transform = test_transformationfrom torch.utils.data import DataLoader
BATCH_SIZE = 256
#전처리가 완료된 데이터셋을 Mini-batch가 생성가능한 dataloader로 변환
train_loader = DataLoader(trainset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(testset,
batch_size=BATCH_SIZE,
shuffle=False)1) 데이터셋 불러오기 torchvision라이브러리 사용
2) 데이터셋 전처리 v2라이브러리 사용
3) 데이터셋 데이터로더 만들기
까지 했다
4. AlexNet의 하이퍼 파라미터
AlexNet의 손실함수(Loss Function)및 옵티마이저에 대한 하이퍼 파라미터의 설정은
1) 논문의 작성시점
2) 요즘 사용하는 하이퍼 파라미터
가 많이 달라졌다.
4.1 논문이 작성된 시점
Loss Function : softmax Loss를 적용했으며, 이것은 pytorch로 구현시 nn.CrossEntropyLoss()메서드로 구현되어 있다.
옵티마이저 : Stochastic Gradient Descent (SGD)를 사용했으며
- Learning : 0.01적용 후 학습 진행될 때마다 감소
- Momentum : 0.9
- Weight Decay : 0.0005
하이퍼 파라미터의 상세 설정값은 위와 같다.
이를 코드로 구현하면 아래와 같다.
import torch.optim as optim
# Loss 함수 정의
criterion = nn.CrossEntropyLoss()
# Optimizer 정의
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0005)
# 학습률 스케줄러 (선택사항)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=70, gamma=0.1)4.2 요즘 사용하는 하이퍼 파라미터
옵티마이저가 Adam 원툴이 된지가 오래다.
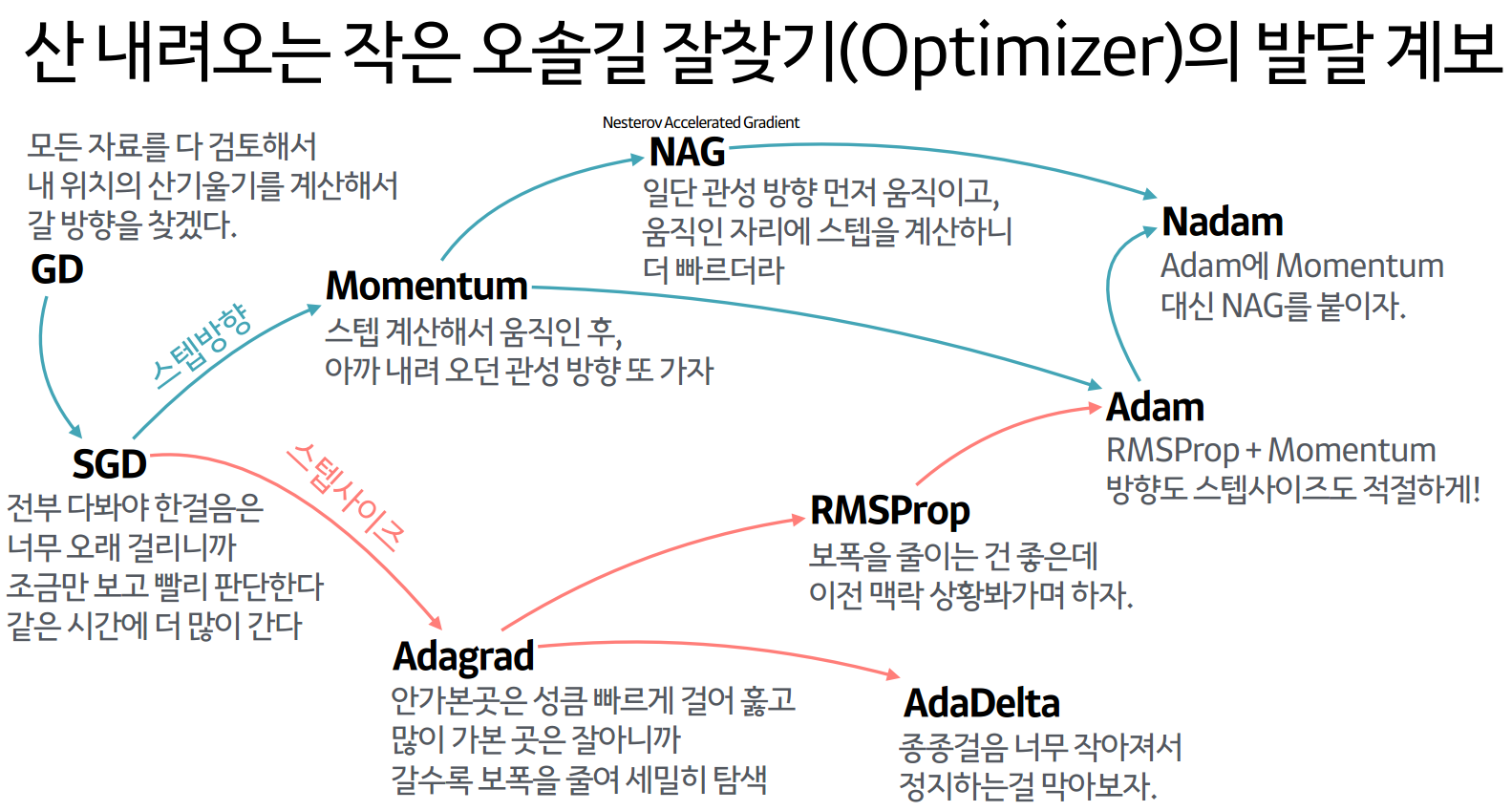 논문이 작성된 시점의 SGD는 위 사진의 옵티마이저 발달 계보를 본다면, 거의 초창기에 해당하는 옵티마이져이고, 요즘은 다
논문이 작성된 시점의 SGD는 위 사진의 옵티마이저 발달 계보를 본다면, 거의 초창기에 해당하는 옵티마이져이고, 요즘은 다 Adam을 사용한다.
이를 코드로 스케쥴러까지 유려하게 구현하면 아래와 같다.
import torch.optim as optim
##LossFn, Optimizer, scheduler 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=100)5. 훈련/검증/실행
12. 주요 CNN알고리즘 구현 : LeNet에서 설명한 Train/val/run 파트의 코드를 그대로 가져오며,
여기에 scheduler만 추가한다.
epoch_step = 5
from tqdm import tqdm #훈련 진행상황 체크
def model_train(model, data_loader,
loss_fn, optimizer_fn, scheduler_fn,
processing_device, epoch):
model.train() # 모델을 훈련 모드로 설정
global epoch_step
# loss와 accuracy를 계산하기 위한 임시 변수를 생성
run_size, run_loss, correct = 0, 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar:
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 전사 과정 수행
output = model(image)
loss = loss_fn(output, label)
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
# 스케줄러 업데이트
scheduler_fn.step()
#argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
#tqdm bar에 추가 정보 기입
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar.set_description('[Training] loss: ' +
f'{run_loss / run_size:.4f}, accuracy: ' +
f'{correct / run_size:.4f}')
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
return avg_loss, avg_accuracydef model_evaluate(model, data_loader, loss_fn,
processing_device, epoch):
model.eval() # 모델을 평가 모드로 전환 -> dropout 기능이 꺼진다
# batchnormalizetion 기능이 꺼진다.
global epoch_step
# gradient 업데이트를 방지해주자
with torch.no_grad():
# 여기서도 loss, accuracy 계산을 위한 임시 변수 선언
run_loss, correct = 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar: # 이때 사용되는 데이터는 평가용 데이터
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 평가 결과를 도출하자
output = model(image)
pred = output.argmax(dim=1) #예측값의 idx출력
# 모델의 평가 결과 도출 부분
# 배치의 실제 크기에 맞추어 정확도와 손실을 계산
correct += torch.sum(pred.eq(label)).item()
run_loss += loss_fn(output, label).item() * image.size(0)
accuracy = correct / len(data_loader.dataset)
loss = run_loss / len(data_loader.dataset)
return loss, accuracy크게 달라진 부분을 살펴보자면
model_train() 함수에서
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
# 스케줄러 업데이트
scheduler_fn.step()옵티마이저 이후 스케쥴러 함수를 통해 learning_rate가 조정되는 부분이 하나 추가 되었으며,
tqdm라이브러리로 인해 진행상황이 매 epoch마다 출력되는게 불편해서
epoch가 0, 5, 10,.. 이때만 출력되게
빈도를 좀 줄였다.
# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss, his_accuracy = [], []
num_epoch = 50
for epoch in range(num_epoch):
# 훈련 손실과 정확도를 반환 받습니다.
train_loss, train_acc = model_train(model, train_loader,
criterion, optimizer, scheduler,
device, epoch)
# 검증 손실과 검증 정확도를 반환 받습니다.
test_loss, test_acc = model_evaluate(model, test_loader,
criterion, device, epoch)
# 손실과 정확도를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_accuracy.append((train_acc, test_acc))
#epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}, Training loss: " +
f"{train_loss:.4f}, Training accuracy: {train_acc:.4f}")
print(f"Test loss: {test_loss:.4f}, Test accuracy: {test_acc:.4f}")스케쥴러가 도입된 model_train함수와 tqdm의 출력 빈도를 줄이고 이에 대한 학습/검증 루프를 실행하는 코드는 이전 포스팅의 코드와 동일하다.
코드에서 tqdm을 특정 epoch에서만 출력하게 작성을 안해놓으면
 이렇게 오른쪽처럼 상당히 긴 결과로그가 출력되는데... 이게 은근히 스크롤 압박이라서 필자는 줄여서 출력되게 코드를 좀 변조했다.
이렇게 오른쪽처럼 상당히 긴 결과로그가 출력되는데... 이게 은근히 스크롤 압박이라서 필자는 줄여서 출력되게 코드를 좀 변조했다.
솔직히 epoch 3 사이클만 돌려도 이 딥러닝 훈련/검증 구동에 문제가 있는지 없는지 왠만하면 다 판별이 되서
궂이 로그를 길게 볼 필요가 있나.. 싶어서 줄였다.
6. 평가(추론)
import matplotlib.pyplot as plt
# 손실 그래프
train_losses, val_losses = zip(*his_loss)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='train')
plt.plot(val_losses, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# 정확도 그래프
train_accuracies, val_accuracies = zip(*his_accuracy)
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='train')
plt.plot(val_accuracies, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Train-Val Accuracy')
plt.tight_layout()
plt.show()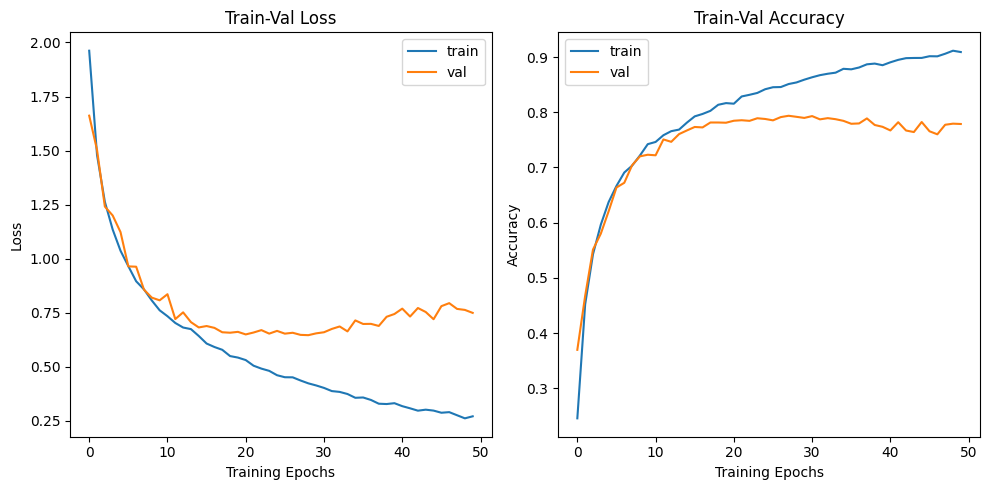 설계한 모델의 성능평가를 하려면 역시 제일 좋은건 각 epoch별 train/val loss와 accuracy를 찍어보는 것이다.
설계한 모델의 성능평가를 하려면 역시 제일 좋은건 각 epoch별 train/val loss와 accuracy를 찍어보는 것이다.
위 사진을 보니 뭐.. 크게 문제가 있어보이지 않으니
이제 훈련된 모델을 사용하어 App를 구현해보는 추론기능에 해당하는 코드를 작성해보고자 한다.
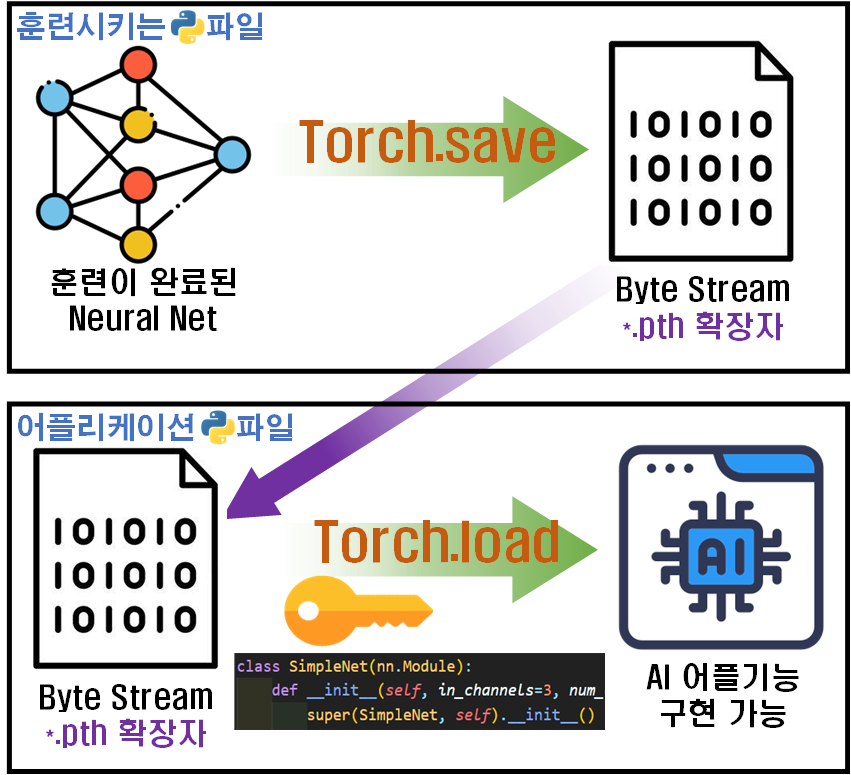 그림으로 표현하자면 위 과정에 해당한다.
그림으로 표현하자면 위 과정에 해당한다.
# 학습이 완료된 모델 저장
MODEL_NAME = 'AlexNet'
torch.save(model.state_dict(), f'{MODEL_NAME}.pth')훈련을 완료한 모델의 파라미터(w, b)를 저장하고
 모델의 설계부 코드는 따로 떼와서
모델의 설계부 코드는 따로 떼와서 *.py로 저장하자.
이제
1) 학습이 완료된 모델 파라미터 + 모델 불러오기
2) 임의의 라벨링된 이미지를 불러온 모델에 넣기
3) 넣은 결과값 확인하는 추론기능을 실습하기
를 수행하고자 한다.
참고로 추론과정은 CPU환경에서 수행하고자 한다.
import torch
from alexnet_model import AlexNet #모델만 따로 저장한 파일import
# CPU 디바이스 설정
device = torch.device('cpu')
model = AlexNet(num_classes=10) #훈련시킨 AlexNet의 num_class는 10이니 인자로 넣어줌
model.load_state_dict(torch.load('AlexNet.pth', map_location=device))
#map_location 인자를 통해 불러온 파라미터값도 CPU로 이전시킴
model.eval() #모델을 '평가'모드로 설정함다음으로 임의의 이미지를 하나 가져오는 코드를 작성한다
import os, random
from PIL import Image
import matplotlib.pyplot as plt
folder_path = '[이미지가 있는 폴더 경로]'
#폴더 내에 있는 파일을 랜덤하게 가져오는 코드
img_files = [f for f in os.listdir(folder_path) if os.path.isfile(os.path.join(folder_path, f))]
random_img_file = random.choice(img_files)
img_path = os.path.join(folder_path, random_img_file)
# 이미지 불러오기 및 디스플레이
image = Image.open(img_path)
plt.imshow(image)
plt.axis('off')
plt.show()
cifar-10에 있는 이미지를 불러오니 픽셀 크기가 작게 출력된다
그래서 다른 (이미지가 큰 자료가 있는)데이터셋에서 추론작업을 수행했다.

이미지를 불러왔으면 해당 이미지를 딥러닝 모델에 입력가능하게 전처리 및 자료형 변환을 수행해줘야 한다.
from torchvision.transforms import v2
transformation = v2.Compose([
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
])
#이미지 전처리 후 Mini-batch자료형에 맞게 맨 앞에 'N'에 해당하는 차원 추가
image = transformation(image).unsqueeze(0)이렇게 자료형 변환만 수행해준 뒤
#이미지 모델에 입력 후 추론
output = model(image)
print(output)tensor([[-3.7202, -5.8153, 1.9461, 2.8744, 0.5307, 0.4622, 0.5761, -1.1234,
-3.5115, -3.9412]], grad_fn=<AddmmBackward0>)출력되는 데이터 확인해 보고
# CIFAR-10 클래스 레이블
cifar10_classes = ['airplane', 'automobile', 'bird',
'cat', 'deer', 'dog', 'frog',
'horse', 'ship', 'truck']
# 결과 출력 (예측된 클래스 인덱스)
_, predicted = torch.max(output, 1)
print('Predicted class:', predicted.item())
predicted_label = cifar10_classes[predicted.item()]
print(f"예측한 이미지는 {predicted_label}이다")CIFAR10의 클래스 정보를 불러와서
비교하는 코드를 작성한다.
Predicted class: 3
예측한 이미지는 cat이다랜덤하게 이미지를 계속 돌려보면
잘 나올때도 있고 안 나올때도 있다 ㅎㅎ...
