
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. LeNet 배경
Yann LeCun이 1988년 발표한 Gradient-based learning applied to document recognition 논문에 실린 Net이 LeNet으로, CNN계열 아키텍쳐로는 최조에 속한다.
주 목적은 손글씨로 쓴 우편번호 인식을 위해 개발된 Net라 보면 된다.
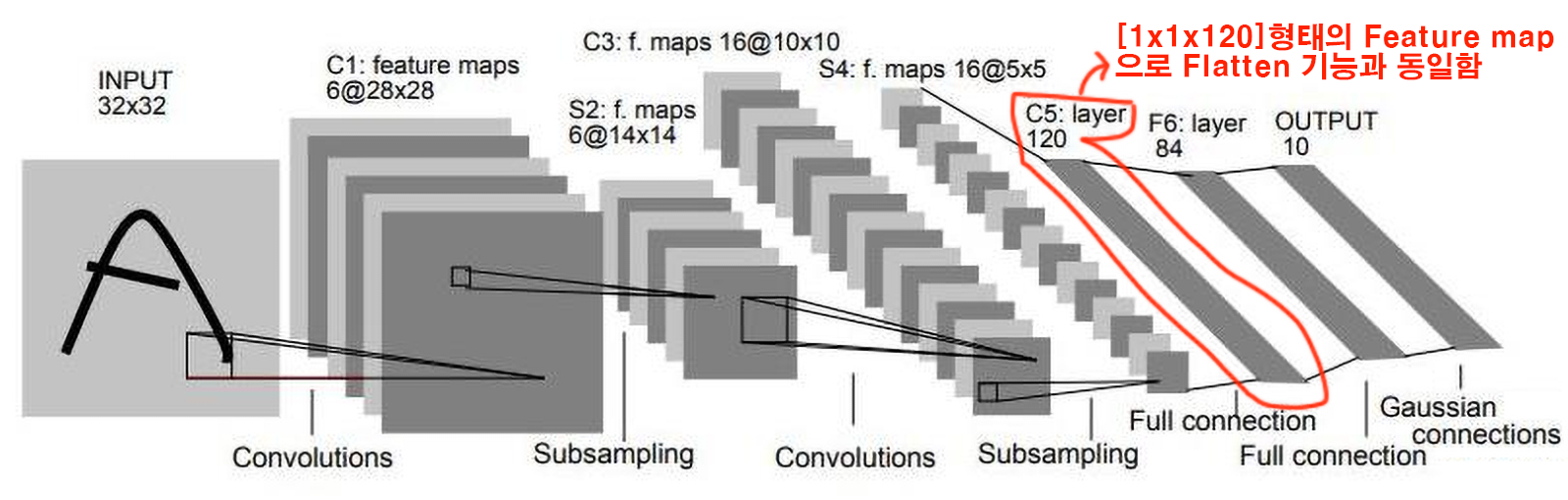
Convolution Layer, Subsampling(이게 Pooling 기법에 해당함), FCL(Fully Connected Layer)등을 도입했으며,
Activation Function은 Sigmoid
Pooling기법은 AvgPool을 사용했다.
2. 데이터셋-MNIST
LeNet으로 모델 훈련/검증/평가를 수행할 데이터셋으로는 MNIST를 사용하고자 한다
from torchvision import datasets
train_dataset = datasets.MNIST(root='./../00_pytest_img/MNIST',
train=True,
download=True)
test_dataset = datasets.MNIST(root='./../00_pytest_img/MNIST',
train=False,
download=True)데이터셋은 torchvision라이브러리에서 제공하는 MNIST데이터셋 다운로드 기능을 사용하였다.
 역시 다운로드 받은 파일을 확인하면 raw 데이터로 되어있으니 이걸 풀어서 img파일을 확인해보자
역시 다운로드 받은 파일을 확인하면 raw 데이터로 되어있으니 이걸 풀어서 img파일을 확인해보자
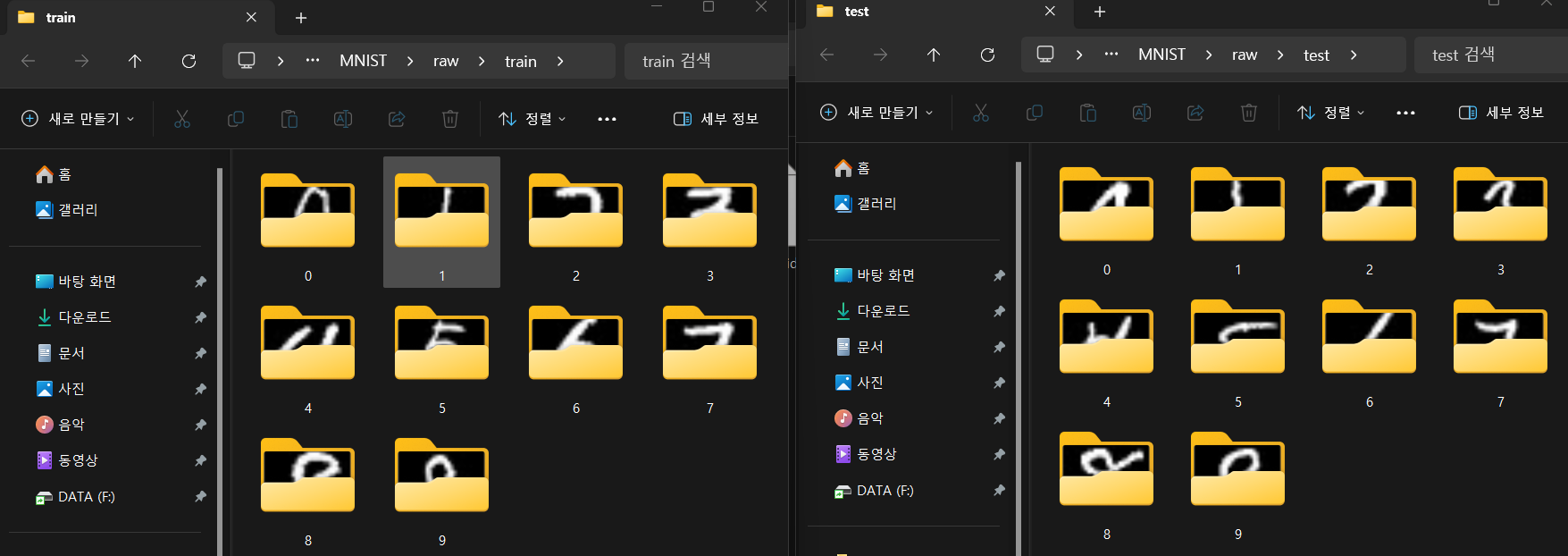 이미지 파일 추출 코드를 작성하여 이미지를 추출하면 0~9으로 라벨링 된 서브폴더에 각각의 이미지가 담기며
이미지 파일 추출 코드를 작성하여 이미지를 추출하면 0~9으로 라벨링 된 서브폴더에 각각의 이미지가 담기며
train에 6만장
test에 1만장 하여 총 7만장의 데이터셋이 담겨져 있다.
그리고 이미지의 개당 크기는 [28x28]픽셀이다.
데이터셋의 구성 및 정보는 아래의 코드를 통해서도 확인이 가능하다
import numpy as np
# 이미지와 라벨을 배열로 변환
train_images = train_dataset.data
train_labels = np.array(train_dataset.targets)
test_images = test_dataset.data
test_labels = np.array(test_dataset.targets)
num_classes = len(np.unique(train_labels))
# 정보 출력
print(train_images.shape) # torch.Size([60000, 28, 28])
print(test_images.shape) # torch.Size([10000, 28, 28])
print(num_classes) # train_labels 출력 = 10
print(len(np.unique(test_labels))) # test_labels 출력 = 10다음으로 해당 데이터셋을 딥러닝 모델에 입력 가능한 자료형인 Dataloader까지의 변환 코드는 아래와 같다.
from torchvision.transforms import v2
from torch.utils.data import DataLoader
# 데이터셋 로드 및 전처리
transformation = v2.Compose([
v2.Resize((32, 32)), # 이미지 크기를 32x32로 조정
v2.ToImage(), # 이미지를 Tensor-img 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #데이터타입 : float32, [0~1]로 스케일링
v2.Normalize((0.5,), (0.5,)) #데이터 정규화
])
#이미지에 위 변환방식을 적용
train_dataset.transform = transformation
test_dataset.transform = transformation
train_loader = DataLoader(train_dataset, batch_size=256, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=256, shuffle=False)# DataLoader의 크기 및 첫 번째 배치의 크기 확인
num_train_batches = len(train_loader)
num_test_batches = len(test_loader)
# 첫 번째 배치의 크기 확인
first_train_batch = next(iter(train_loader))
first_test_batch = next(iter(test_loader))
train_images, train_labels = first_train_batch
test_images, test_labels = first_test_batch
print(f"Type of train_loader: {type(train_loader)}")
print(f"Number of training batches: {num_train_batches}")
print(f"Number of test batches: {num_test_batches}")
print(f"First training batch shape (images): {train_images.shape}")
print(f"First training batch shape (labels): {train_labels.shape}")
print(f"First test batch shape (images): {test_images.shape}")
print(f"First test batch shape (labels): {test_labels.shape}")Type of train_loader: <class 'torch.utils.data.dataloader.DataLoader'>
Number of training batches: 235
Number of test batches: 40
First training batch shape (images): torch.Size([256, 1, 32, 32])
First training batch shape (labels): torch.Size([256])
First test batch shape (images): torch.Size([256, 1, 32, 32])
First test batch shape (labels): torch.Size([256])3.LeNet5 모델 설계
import torch.nn as nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self, num_classes=10):
super(LeNet5, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv3 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv5 = nn.Sequential(
nn.Conv2d(16, 120, kernel_size=5, stride=1, padding=0),
nn.ReLU(),
)
self.flatten = nn.Flatten()
self.fc1 = nn.Linear(120, 84)
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.conv3(x)
x = self.conv5(x)
x = self.flatten(x)
x = self.fc1(x)
x = self.fc2(x)
return x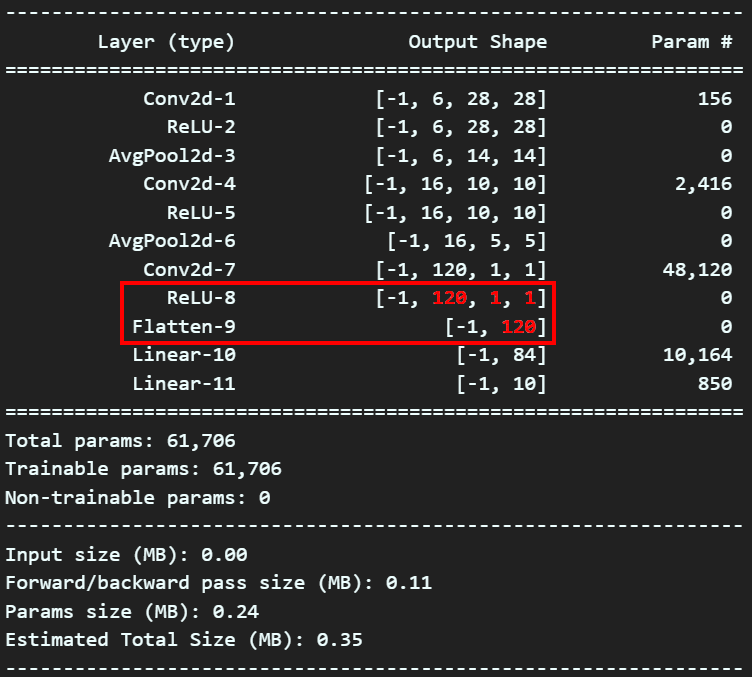 여기서 위 사진처럼
여기서 위 사진처럼 Conv block에서 Dense block로 넘어가는 과정에서 발생하는 Flatten의 인자값 계산이 어려워
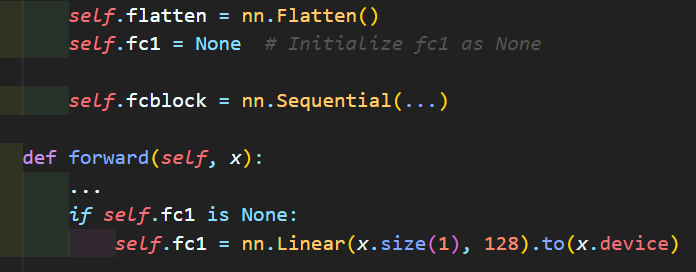 이런식으로 동적 연산이 첨가된 모델 작성에 관한 내용을 포스팅한 적이 있었다.
이런식으로 동적 연산이 첨가된 모델 작성에 관한 내용을 포스팅한 적이 있었다.
결론만 이야기하면 위와 같은 식의 모델설계는 지양하는 것이 좋다.
이유는...
torch.save(model.state_dict(), PATH)위 코드로 훈련이 완료된 모델을 저장할 시
모델에 동적으로 레이어를 설계하는 코드가 있으면
이 동적 레이어 설계 부분의 파라미터 값을 재대로 불러오지 못하는 참사가 발생한다.
모델 설계는 악으로 깡으로 레이어 별 인자값들을 사전에 계산해서 때려넣어야 한다....
아무튼 모델에 대한 설명은 위에 첨부했으니 넘어가고.. 설계한 모델은 Pytorch에서는 GPU에서 학습시킬지/CPU에서 학습시킬지 결정해야 하기에 아래의 코드를 적용하여 GPU 학습을 수행한다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#device.type를 print했을 때 'cuda'가 뜨면 GPU사용가능
ex_model = LeNet5(num_classes=num_classes)
ex_model.to(device)
summary(ex_model, input_size=(1,32,32), device=device.type)Loss Function은 다중분류용 손실함수인 crossEntropyLoss, RMSprop를 활용한다.
from torch import optim
criterion = nn.CrossEntropyLoss()
optimizer = optim.RMSprop(ex_model.parameters(), lr=0.001)4. Train/val함수
이번챕터에서는 이전에 설명하려다 넘어간
훈련, 검증에 관한 코드 설명을 진행하고자 한다
4.0 tqdm
모델의 훈련 및 검증을 수행하는 두개의 함수는 모두 tqdm라이브러리를 사용했는데
이 라이브러리는 아래의 이미지로 쉽게 설명이 가능할 듯 하다.
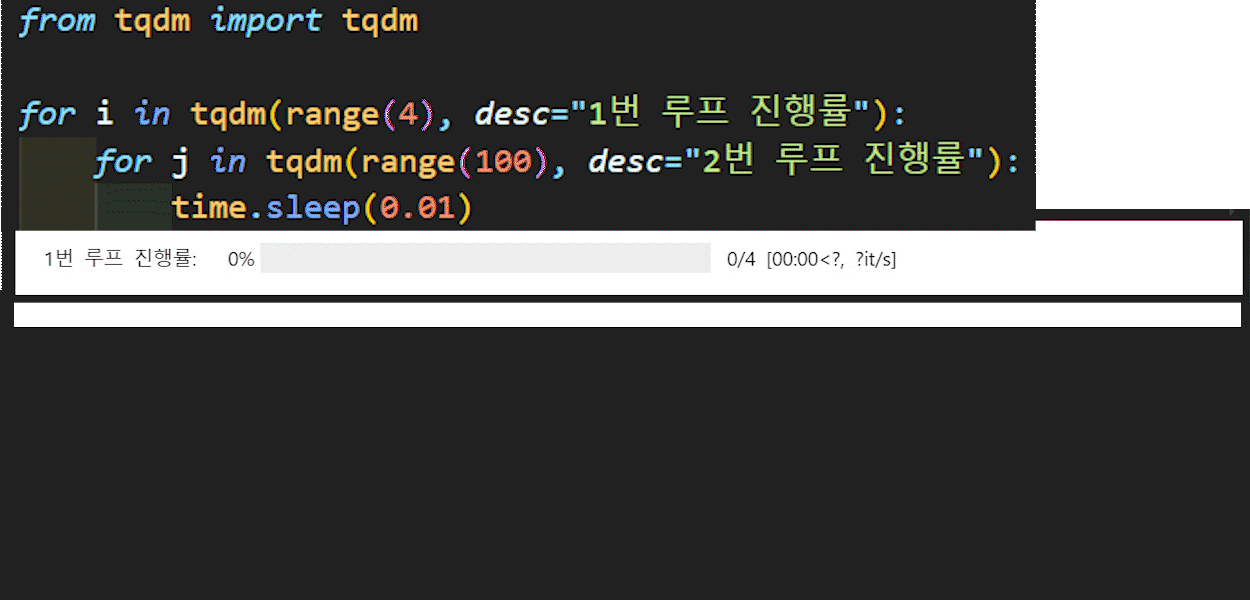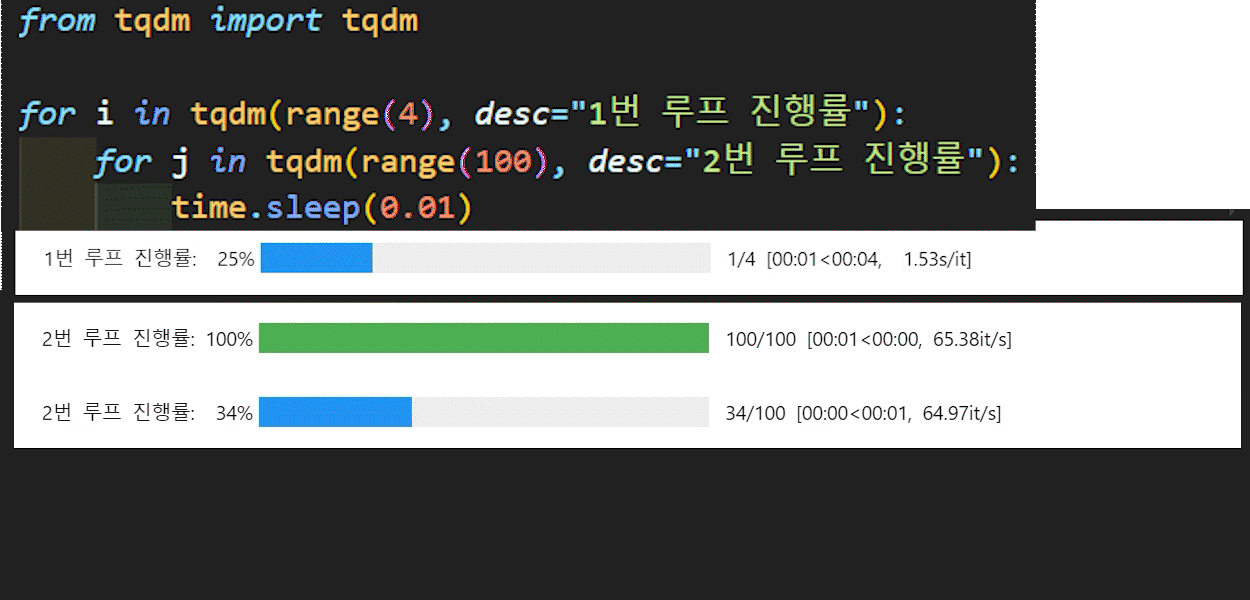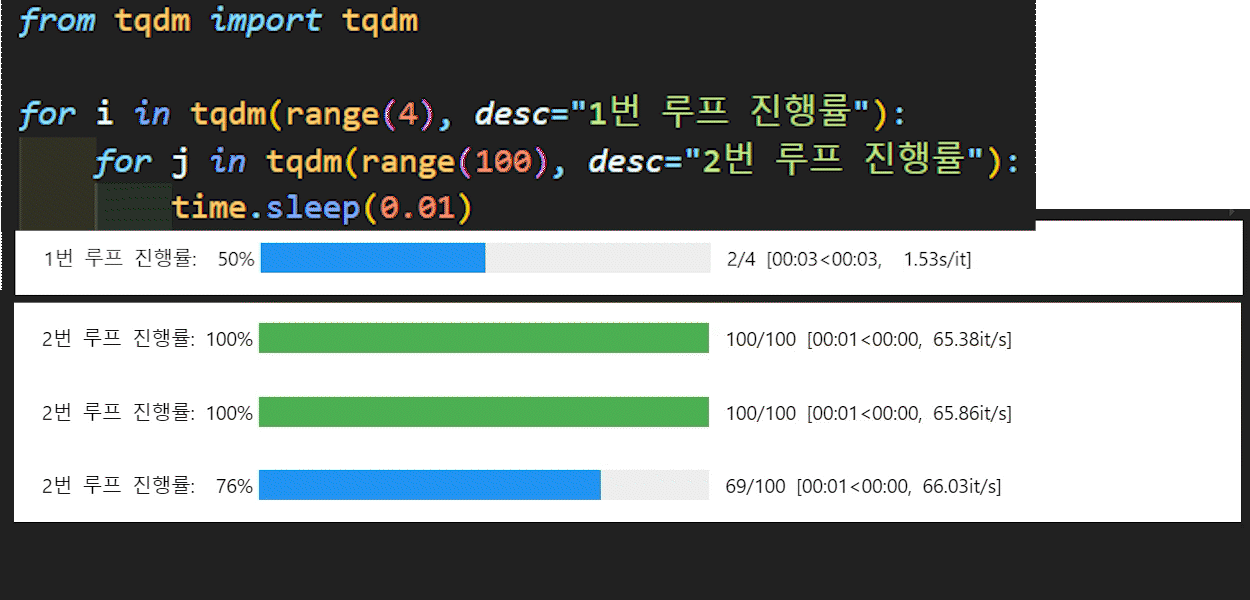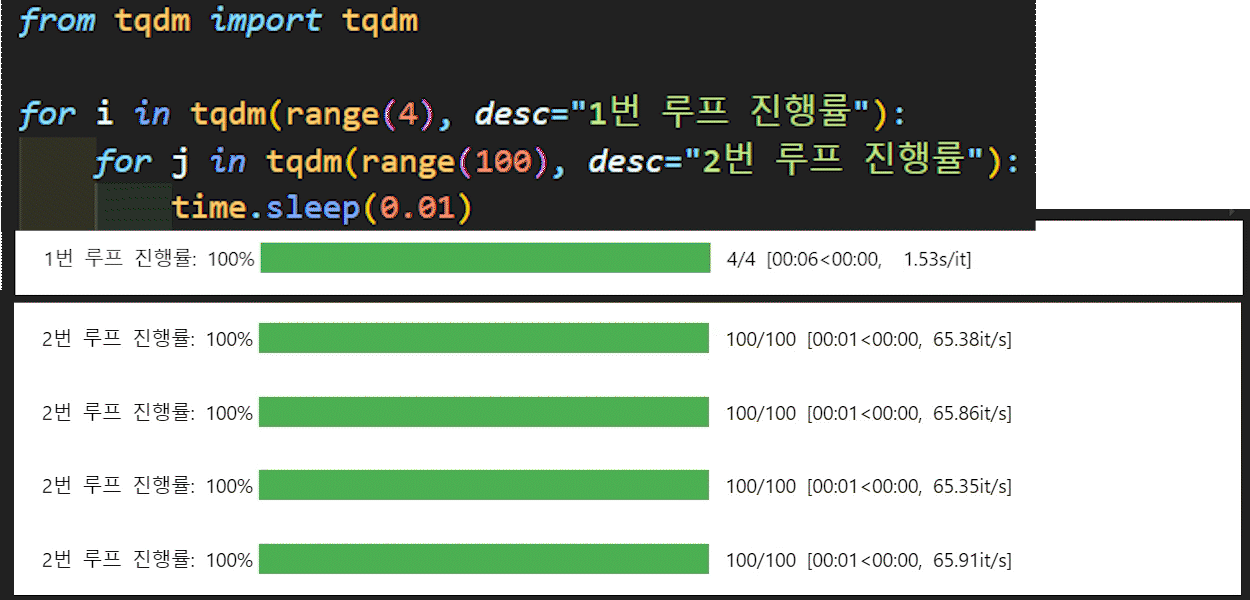 파이썬에서 for문으로 묶이는 반복문 구문에
파이썬에서 for문으로 묶이는 반복문 구문에
tqdm을 붙이면 이를 구동할 때 시각화 하여 해당 for문의 진행상황을 볼 수 있게 도와주는 라이브러리 이다.
정확하게는 iterable에 속하는 객체는 모두 tqdm 메서드에 인자로 넣을 시 해당 iterable의 진행상황을 체크할 수 있는 시각화 도구를 제공한다.
이 라이브러리는 model_train, model_evaluate함수에 모두 적용되어 있어서 먼저 설명하고 넘어간다.
4.1 Model_train_func
from tqdm import tqdm #훈련 진행상황 체크
def model_train(model, data_loader, loss_fn, optimizer_fn, processing_device):
model.train() #모델을 훈련모드로 설정
run_size, run_loss, correct = 0, 0, 0
progress_bar = tqdm(data_loader)
for image, label in progress_bar:
#입력 이미지를 GPU로 이전
image = image.to(processing_device)
label = label.to(processing_device)
#forward과정 수행
output = model(image)
loss = loss_fn(output, label)
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
#argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
progress_bar.set_description('[Training] loss: ' +
f'{run_loss / run_size:.4f}, accuracy: ' +
f'{correct / run_size:.4f}')
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
return avg_loss, avg_accuracy첫번째로 run_size, run_loss, corrcet 3가지 변수를 0으로 초기화한다.
run_size변수는 Accuracy와 Loss를 계산할 때 분모에 해당하는 전체 데이터 개수를 의미한다.
따라서
훈련이 진행되는 결과값을 실시간으로 출력할 때
progress_bar.set_description('[Training] loss: ' +
f'{run_loss / run_size:.4f}, accuracy: ' +
f'{correct / run_size:.4f}')이 코드는
print(f'지금 시점의 loss값 : {run_loss / run_size}')
print(f'지금 시점의 정확도값 : {correct / run_size}')로 볼 수 있다.
tqdm라이브러리로 실시간으로 Accuracy와 Loss의 변화를 같이 보려 하기에
tqdm의 progress_bar의 디스플레이 데이터를 조정할 수 있는 set_description메서드에 해당 구문을 넣은 것이다.
이 run_size변수는 훈련용 이미지는 6만장, 검증용 이미지는 1만장이니 0~60,000, 0~10,000까지 값이 올라갔다 떨어지는 값이라 보면 된다.
(이게 batch_size=256으로 설정했으니 progress_bar 상으로는 0~235, 0~40까지 값이 올라갔다 떨어지는 것처럼 보일것이다.)
model.train() #모델을 훈련모드로 설정모델을 훈련모드로 설정한 다는 것은
1) Dropout, BatchNormalization과 같이 학습 과정에서만 사용되는 정규화 기법이 동작하게 설정함
2) loss.backward()구문이 동작됨 -> 역전파 연산이 가능해짐
#forward과정 수행
output = model(image)
loss = loss_fn(output, label)딥러닝 모델에 x(독립변수)를 입력하여 예측된 값 를 만들고
이를 y(종속변수)와 비교하여 그 차이(Loss)를 계산하는 부분이다.
이를 forward과정이라 부른다.
#backward과정 수행
optimizer_fn.zero_grad() #파라미터 0으로 초기화
loss.backward()
optimizer_fn.step()backword 과정은
1) 옵티마이저의 Gradient를 계산한 값이 저장된 Tensor 자료객체를 0으로 초기화(아래 2), 3)과정을 계산하는데 사용하는 객체를 0으로 초기화 한다는 뜻임)
2) loss값의 정도에 따라 parameter(w, b)를 적절히 재조정 하기 위한 미분치 계산
3) 옵티마이저를 사전에 설정한 하이퍼 파라미터 learning_rate값과 미분치를 곱해서 이 곱한 값을 parameter(w, b)에 반영함
forward랑 backword 과정에 코드가 개입하는 부분을
각 항목별로 설명하면 아래와 같다.
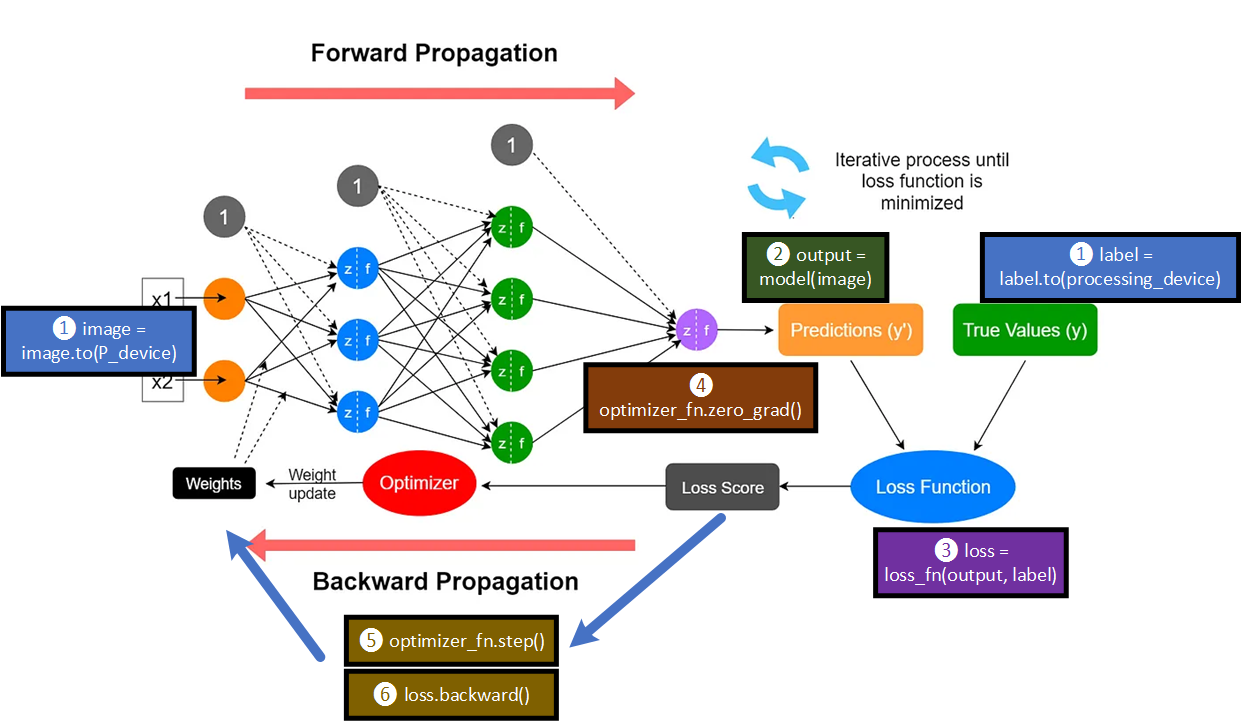
#argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()위 부분은 이미지로 설명하겠다.
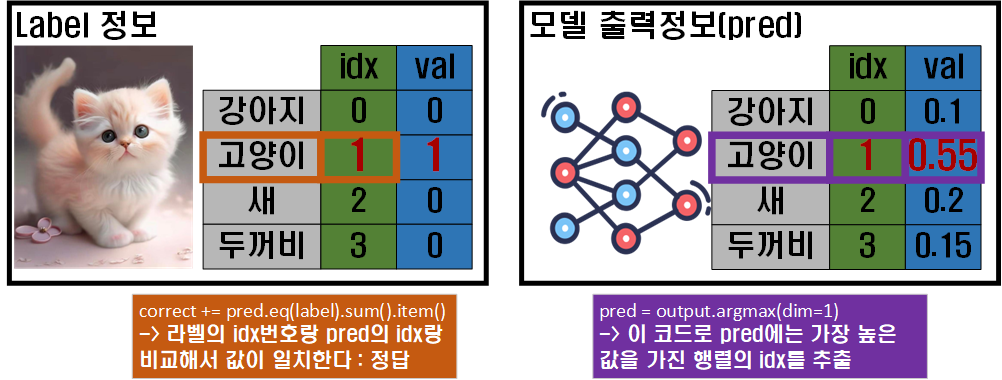 위 사진처럼 모델의 예측값은
위 사진처럼 모델의 예측값은 Softmax함수를 거치기에 라벨의 종류별로 확률 값이 나오고, 이 확률값 중 가장 큰 값이 들어있는 idx와 라벨(정답지)에서 정답이 있는 idx랑 비교하여 두 값이 같으면 correct를 +1하는 연산이다.
이 과정을 통해 model_train이 출력하는 데이터는
모델이 훈련을 진행하면서 얻은 Loss, Accuracy 정보를 반환한다.
4.2 Model_eval_func
def model_evaluate(model, data_loader, loss_fn, processing_device):
model.eval() # 모델을 평가 모드로 전환
#eval()으로 전환 시 설정되는 것들
#1. dropout 기능이 꺼진다
#2. batchnormalizetion 기능이 꺼진다.
with torch.no_grad():
# 여기서도 loss, accuracy 계산을 위한 임시 변수 선언
run_loss, correct = 0, 0
progress_bar = tqdm(data_loader)
for image, label in progress_bar:
#입력 이미지를 GPU로 이전
image = image.to(processing_device)
label = label.to(processing_device)
output = model(image)
pred = output.argmax(dim=1) #예측값의 idx출력
correct += torch.sum(pred.eq(label)).item()
run_loss += loss_fn(output, label).item() * image.size(0)
accuracy = correct / len(data_loader.dataset)
loss = run_loss / len(data_loader.dataset)
return loss, accuracy검증 부분에 해당하는 model_evaluate함수는 전체적인 구조는 model_train과 같다 볼 수 있으나
model.eval() # 모델을 평가 모드로 전환모델을 훈련모드가 아닌 평가모드에서 코드를 수행하는 것
with torch.no_grad():gradient 연산을 '중지'한 상태에서
아래의 구문을 수행하라
라고 보면 된다
따라서 with구문으로 묶인 코드를 수행하는 동안은 gradient 연산이 중지되고
구문을 통과하면 자동으로 다시 gradient 연산이 활성화된다.
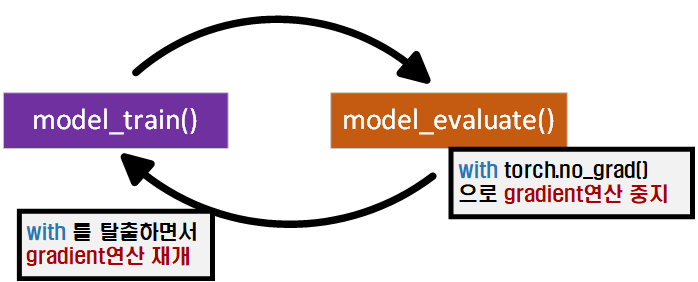 이걸 이미지로 표현하면 위 사진과 같은데
이걸 이미지로 표현하면 위 사진과 같은데 with구문은 gradient연산을 재개하는 시점을 with로 묶인 코드가 끝나면 자동으로 재개하게끔 만들어주는 코드라 보면 된다.
이 개념이 어디서 왔냐면 RAII(Resource Acquisition Is Initialization)에서 온건데...
자원의 할당과 해제를 자동화 해주는 방법론 이런 것 같은데...
잘 모르겟다..
아무튼 자동으로 gradient의 연산 ON/OFF를 해준다 보면 되겟다
4.3 Run
his_loss, his_accuracy = [], []
num_epoch = 50
for epoch in range(num_epoch):
# 훈련 손실과 정확도를 반환 받습니다.
train_loss, train_acc = model_train(ex_model, train_loader, criterion, optimizer, device)
# 검증 손실과 검증 정확도를 반환 받습니다.
test_loss, test_acc = model_evaluate(ex_model, test_loader, criterion, device)
# 손실과 정확도를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_accuracy.append((train_acc, test_acc))
#epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % 5 == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}, Training loss: {train_loss:.4f}, Training accuracy: {train_acc:.4f}")
print(f"Test loss: {test_loss:.4f}, Test accuracy: {test_acc:.4f}")모델에 대한 훈련/검증을 담당하는
model_train, model_evaluate함수 설계와 그 구조를 탐색했으니
이제 훈련을 실행하면 된다.
epoch는 훈련/검증을 반복하는 횟수라 보면 되고
매 회차마다 얻어낸 Loss, Accuracy 성능 결과치는
his_loss, his_accuracy = [], []이 변수에 저장해서 나중에 그래프 그릴때 써먹는다
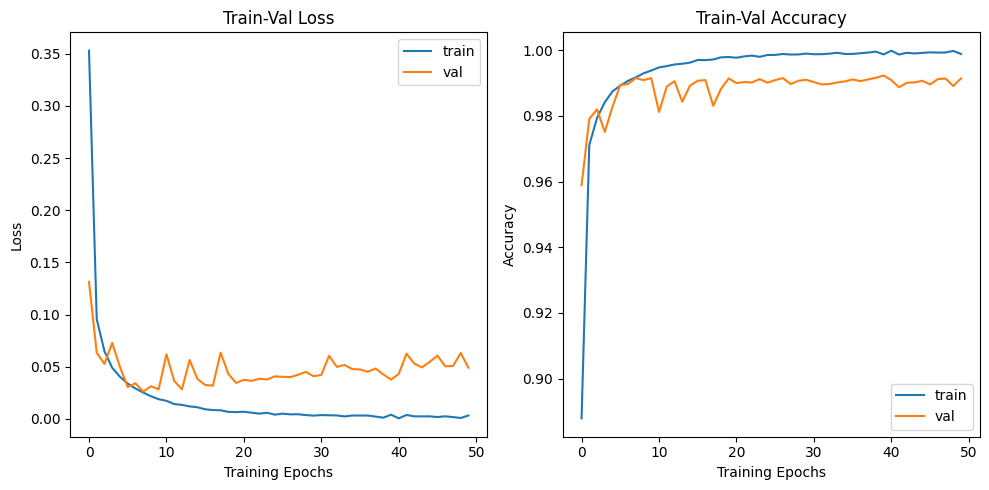
이런 식으로 말이다.
이렇게 LeNet5에 대한 모델 설계
그리고 이전 포스팅에서 넘어갔던
모델 훈련, 모델 검증 함수에 대한 코드리뷰를 마쳤다.
