
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
0. 실습 전 세팅
강의 내용은 PIL라이브러리와 opencv, numpy라이브러리 간 자료 변환 및 이미지 픽셀 데이터의 확인
MNIST 데이터셋의 이미지 파일 및 데이터셋 구조 분석
훈련/검증 데이터셋을 라이브러리 없이 불러오는 방법론
등이 진행되었으나
조금 더 난이도가 높은 예제를 만들어서 데이터셋을 만들어 보고자 한다.
 예시 데이터는 SLT10을 선정했으며, rawdata를 받을 수 있는 출처에서 데이터를 받으니 라벨링 정보 없이 이미지가 섞여 있어서
예시 데이터는 SLT10을 선정했으며, rawdata를 받을 수 있는 출처에서 데이터를 받으니 라벨링 정보 없이 이미지가 섞여 있어서
torchvision 라이브러리를 통해서 데이터를 다운로드 받고자 한다.
from torchvision import datasets
trainset = datasets.STL10(root=[파일경로] -> 귀찮으면'./data',
str = 'train',
download=True)
testset = datasets.STL10(root=[파일경로] -> 귀찮으면'./data',
str = 'test',
download=True)위 코드를 통해서 데이터를 다운받으면
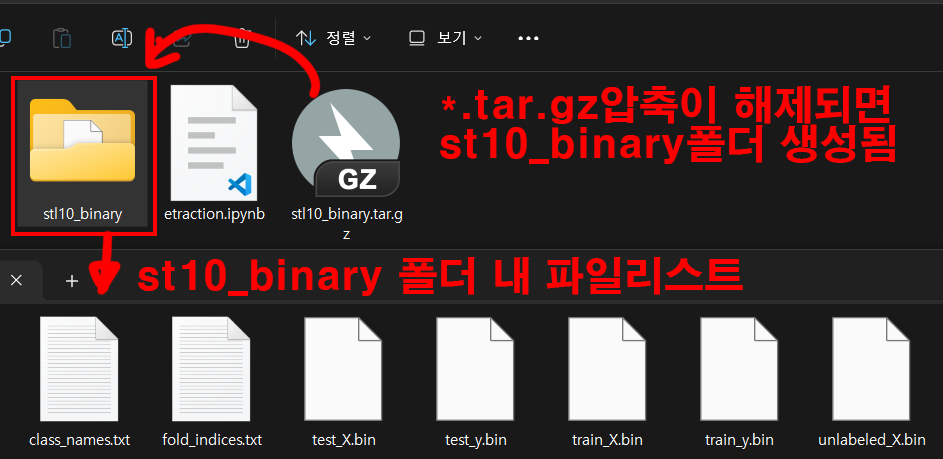 위 사진처럼
위 사진처럼 st10_binary.tar.gz압축파일을 다운받고 이를 해제하는데 해제하면 여러 메타 데이터 리스트랑 클래스 이름이 저장된 텍스트 파일이 존재한다
이제 이 메타데이터파일을 해제해서 각각의 이미지 파일을 뽑아내고자 한다.
전체 코드를 항목별로 분할하고 각 명령어에 대한 설명을 첨부하고자 한다.
코드의 작성은 폴더 내에 extraction.ipynb파일을 생성하고 이 파일에서 코드를 실행한다.
import os
import numpy as np
import matplotlib.pyplot as plt# 데이터셋 파일 경로
data_dir = './stl10_binary/'
# 클래스 이름 로드
with open(os.path.join(data_dir, 'class_names.txt'), 'r') as f:
class_names = f.read().splitlines()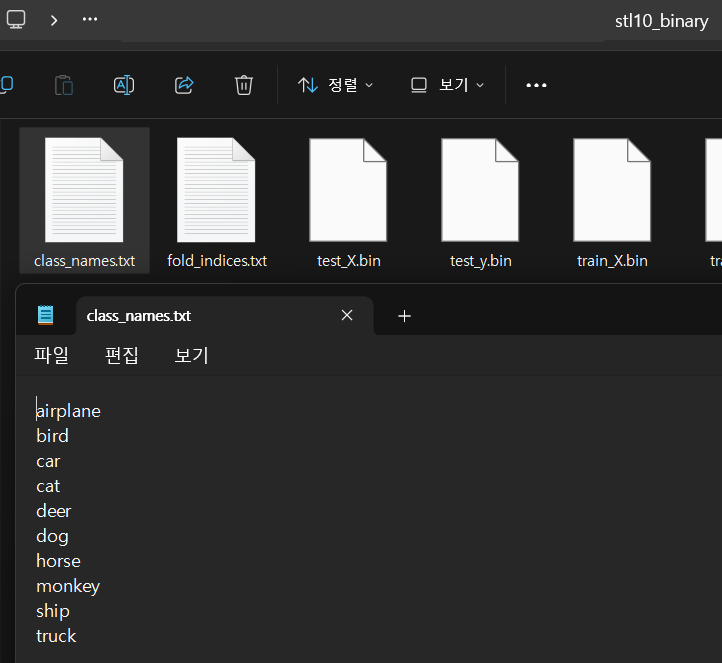 위 코드는 데이터셋의 파일 경로인
위 코드는 데이터셋의 파일 경로인 stl10_binary 폴더 안에 있는 class_names.txt파일을 with 구문이 진행되는 동안만 파일을 열람하겠다는 뜻이며, 이 파일에 대한 접근은 f 변수로 진행하겠다는 뜻이다.
파일의 열람은 open메서드로 수행하며, r=read 옵션이다.
os.path.join은
print("join(): " + os.path.join("/A/B/C", "file.py"))join(): /A/B/C/file.py위 함수 결과처럼 경로를 관리하는 모듈인 os.path 의 경로 단어 잇는 join메서드를 사용한 것이다.
그리고 파일을 열람하면 라벨 정보가 enter키로 나뉘어져 있으니 이를 인식하여 리스트로 저장하는 .splitlines()메서드를 사용했다.
따라서 class_names에 저장된 정보는 아래와 같다.
['airplane', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck']# 바이너리 파일 읽기 함수
def read_stl10_binary(file_path, img_size, num_channels):
with open(file_path, 'rb') as f:
images = np.fromfile(f, dtype=np.uint8)
images = images.reshape(-1, num_channels, img_size, img_size)
images = np.transpose(images, (0, 2, 3, 1))
return images 다음으로는 위 4개의 파일 중 독립변수인
다음으로는 위 4개의 파일 중 독립변수인 x.bin파일을 열람하고, 열람한 파일의 이미지 정보를 추출하기 위한 함수로 바이너리 파일이기에 읽기 옵션을 rb로 해야 한다.
SLT10데이터셋의 이미지는 [96x96x3]이기에
1) 바이너리로부터 이미지의 데이터 타입 알려주기dtype=np.uint8
2) 불러온 바이너리를 4차원 numpy배열로 재 정의하기
-> [이미지 개수, 채널 수, 이미지 높이, 이미지 너비)] 순
3) 4차원 배열의 순서 바꾸기 -> [이미지 개수, 이미지 높이, 이미지 너비, 채널 수]
이렇게 순서를 바꿔야 이미지로 저장가능한 배열 형태인이미지 높이, 이미지 너비, 채널 수를 만족한다.
# 레이블 읽기 함수
def read_labels(file_path):
with open(file_path, 'rb') as f:
labels = np.fromfile(f, dtype=np.uint8) - 1
# 라벨은 1부터 시작하므로 0부터 시작하도록 조정
return labels 다음으로는 종속변수인
다음으로는 종속변수인 y.bin파일을 열람하며, 라벨의 정보가 1부터 시작하기에 idx의 시작을 0부터 시작해 9로 끝나도록 라벨값에 -1을해준다.
# 이미지 저장 함수
def save_images(images, labels, base_dir, split):
for i, (img, label) in enumerate(zip(images, labels)):
class_name = class_names[label]
class_dir = os.path.join(base_dir, split, class_name)
os.makedirs(class_dir, exist_ok=True)
img_path = os.path.join(class_dir, f'image_{i}.png')
plt.imsave(img_path, img)이 함수는 클래스 라벨 정보로 train,test의 서브폴더를 각각 만들고(os.makedirs(class_dir, exist_ok=True)), 만든 폴더에
image_{i}.png이름으로 이미지를 저장하는 기능을 수행한다.
# 디렉토리 생성
train_dir = os.path.join(data_dir, 'train_images')
test_dir = os.path.join(data_dir, 'test_images')
unlabeled_dir = os.path.join(data_dir, 'unlabeled_images')
os.makedirs(train_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
os.makedirs(unlabeled_dir, exist_ok=True) 3개의 폴더를 만들어 주는 코드
3개의 폴더를 만들어 주는 코드
# 트레인 데이터 로드 및 저장
train_images = read_stl10_binary(os.path.join(data_dir, 'train_X.bin'), 96, 3)
train_labels = read_labels(os.path.join(data_dir, 'train_y.bin'))
save_images(train_images, train_labels, data_dir, 'train_images')
# 테스트 데이터 로드 및 저장
test_images = read_stl10_binary(os.path.join(data_dir, 'test_X.bin'), 96, 3)
test_labels = read_labels(os.path.join(data_dir, 'test_y.bin'))
save_images(test_images, test_labels, data_dir, 'test_images')
# 언레이블 데이터 로드 및 저장
unlabeled_images = read_stl10_binary(os.path.join(data_dir, 'unlabeled_X.bin'), 96, 3)
for i, img in enumerate(unlabeled_images):
img_path = os.path.join(unlabeled_dir, f'image_{i}.png')
plt.imsave(img_path, img)
print("이미지 저장이 완료되었습니다.")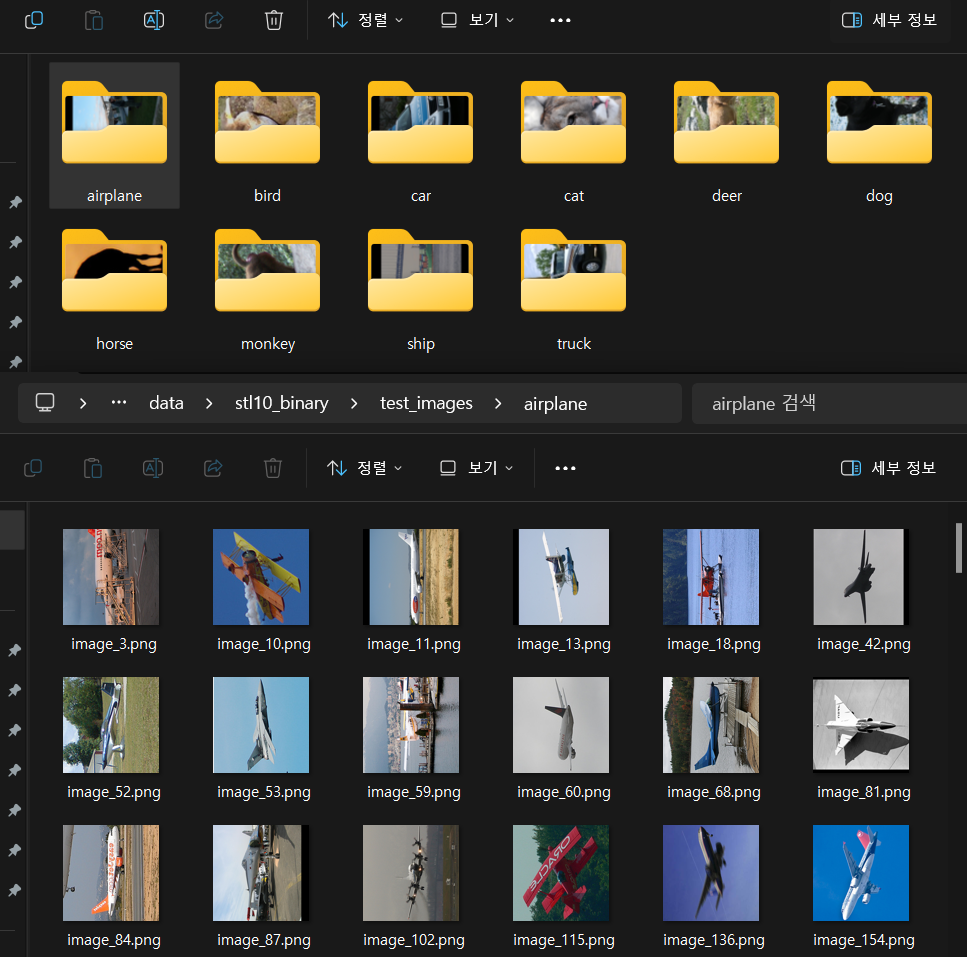 설계한 함수를 불러오면
설계한 함수를 불러오면 unlabeled_images폴더를 제외한 test_images와 train_images폴더에는 위 사진처럼 10개의 라벨명에 맞는 서브 폴더가 생성되고, 각각의 서브 폴더에는 image_{i}.png 규칙으로 이미지 파일이 생성된다.
여기까지 수행 후 각각의 폴더에서 이미지 파일을 다 가져와서 한번에 섞는 작업을 수행하고자 한다.
먼저 image_{i}.png규칙으로 명명된 이미지를
 위와 같이 이름을 변경하고자 한다.
위와 같이 이름을 변경하고자 한다.
data_dir = './stl10_binary/'
train_dir = os.path.join(data_dir, 'train_images')
test_dir = os.path.join(data_dir, 'test_images')
def rename_images(base_dir, prefix_digit):
for class_name in os.listdir(base_dir):
class_dir = os.path.join(base_dir, class_name)
if os.path.isdir(class_dir):
images = sorted(os.listdir(class_dir))
for idx, image_name in enumerate(images):
old_path = os.path.join(class_dir, image_name)
new_image_name = f"{class_name}_{prefix_digit}{idx+1:03d}.png"
new_path = os.path.join(class_dir, new_image_name)
os.rename(old_path, new_path)# train_images 폴더의 파일 이름 변경
rename_images(train_dir, '0')
# test_images 폴더의 파일 이름 변경
rename_images(test_dir, '1')
print("이미지 파일 이름 변경이 완료되었습니다.")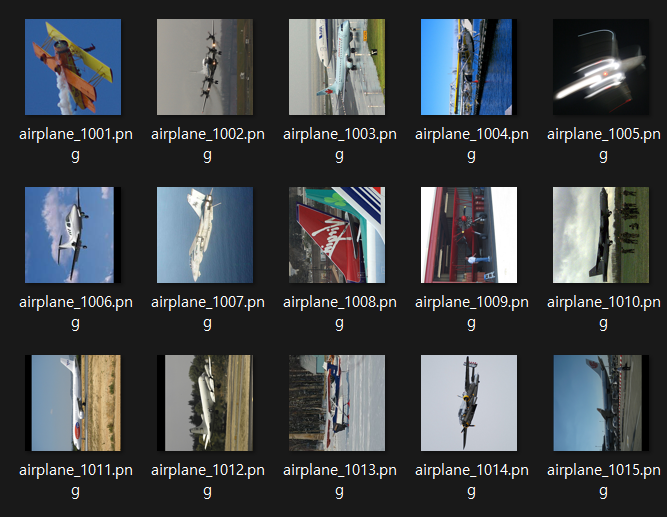 각 폴더별로 파일이름이 변경된 것을 확인했으니
각 폴더별로 파일이름이 변경된 것을 확인했으니
한 폴더에 모든 이미지 파일을 몰아 넣는 작업까지 수행하고
여기서부터 실습을 진행하고자 한다.
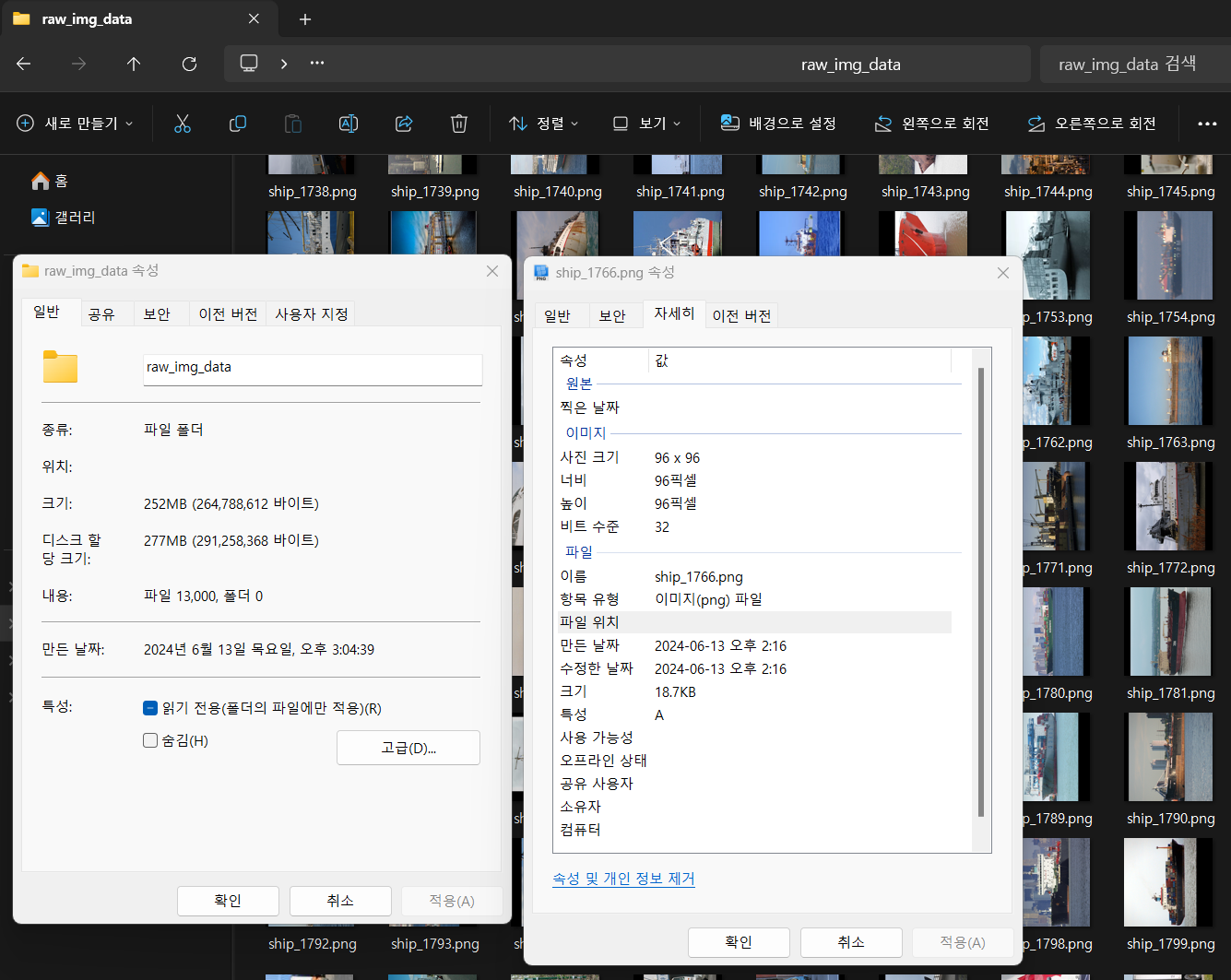 위 사진처럼
위 사진처럼 raw_img_data폴더를 하나 만들고 거기에 train 데이터(5000장), test 데이터(8000)장을 하나의 폴더에 다 때려 넣었다.
1. 이미지 파일의 변환
파이썬 라이브러리에서 이미지 데이터를 분석 및 처리할 수 있는 라이브러리는 PIL(Python Imaging Labray)와 Opencv(Open Source Computer Vision Library) 두가지가 있으며, 두 라이브러리의 장단점을 간단히 요약하면 아래와 같다.
요약
| 특성 | PIL (Pillow) | OpenCV |
|---|---|---|
| 장점 | 사용이 간편함, 다양한 이미지 포맷 지원 | 고성능, 풍부한 기능, 다양한 언어 지원 |
| 단점 | 성능 제약, 제한된 고급 기능 | 초기 학습 곡선이 가파름, 제한된 이미지 포맷 지원 |
| 데이터 형식 | PIL.Image.Image 객체 | NumPy 배열 (BGR 포맷) |
| 주요 용도 | 간단한 이미지 편집, 웹 애플리케이션 | 실시간 비디오 처리, 컴퓨터 비전 애플리케이션 |
두 라이브러리의 설치는 아래의 코드를 실행하면 된다
!pip install pillow -> PIL라이브러리 설치!pip install opencv-python -> opencv라이브러리 설치참고로 opencv 라이브러리는 옛날에는 설치가 매우 어려웠으나, 지금은 pip명령어로 쉽고 완전히 설치가 가능하게 바뀌었다.
뭐 cmake키고 빌드하고 어쩌구저쩌구 하는 과정은 이미 화석이 되어버린 설치 방법론이니 잊으면 된다.
여기서 가끔씩 마음을 두근거리게 만드는게 opencv의 추가 라이브러리 설치인데 opencv-contrib-python와 opencv-python-headless 이다.
이것에 대한 요약 정보도 아래에 기재하도록 하겠다.
| 패키지 이름 | 설명 | 포함된 기능 | 설치 명령어 |
|---|---|---|---|
| opencv-python | OpenCV의 핵심 모듈만 포함한 기본 패키지 | 이미지 처리, 비디오 캡처 등 기본 모듈 | pip install opencv-python |
| opencv-contrib-python | OpenCV의 모든 공식 모듈을 포함한 패키지 | 추가 고급 알고리즘과 기능을 포함 (opencv_contrib 모듈) | pip install opencv-contrib-python |
| opencv-python-headless | GUI 기능이 제거된 OpenCV 패키지 | GUI 기능 없이 이미지 처리, 비디오 캡처 등 기본 모듈 | pip install opencv-python-headless |
| opencv-contrib-python-headless | GUI 기능이 제거된 opencv-contrib-python 패키지 | GUI 없이 추가 고급 모듈 포함 | pip install opencv-contrib-python-headless |
결론만 이야기 하자면 opencv-python만 설치해도 무방하며, 본인이 서버 환경에서 Opencv를 쓴다면 opencv-python-headless이 패키지를 설치하는 것이니 왠만한 경우에는 설치할 필요가 없다.
아무튼 각각의 라이브러리를 설치하고 기본적인 이미지 출력을 수행하고자 한다.
이미지의 출력은 위 챕터에서 실습을 위해 준비한 STL 이미지 폴더에서 랜덤하게 이미지를 불러오는 식으로 코드를 작성한다.
from PIL import Image
import cv2
import numpy as np
import osdir_path = '[stl10의 raw image data폴더 경로]'
files=[f for f in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, f))]
print(f"찾아낸 이미지 파일 개수 : {len(files)}")찾아낸 이미지 파일 개수 : 13000이렇개 13000개의 이미지를 찾아내야 정상이고
코드에 대해 설명을 하자면
os.listdir : 지정한 디렉토리(폴더) 내 모든 파일 및 디렉토리 이름을 '리스트'로 출력
os.path.isfile : 입력된 경로가 '파일' 이면 True, '폴더' 면 False
따라서 files변수의 리스트 컴프리핸션 구문은 폴더 내 모든 파일 및 디렉토리 리스트를 저장하는데, 디렉토리에 해당하는 항목을 거르고 파일 항목만 골라서 저장하겠다는 뜻이다.
import random
#랜덤으로 하나의 파일 선택하기
file_choice = random.choice(files)
img_path = os.path.join(dir_path, file_choice)
#PIL 라이브러리로 이미지 열기 및 출력
pil_img = Image.open(img_path)
pil_img.show()
#opencv 라이브러리로 이미지 열기 및 출력
cv2_img = cv2.imread(img_path)
cv2.imshow('opencv img', cv2_img)
cv2.waitKey(0)
cv2.destroyAllWindows()위 코드를 실행하면 아래의 그림처럼 display가 될 것이다.
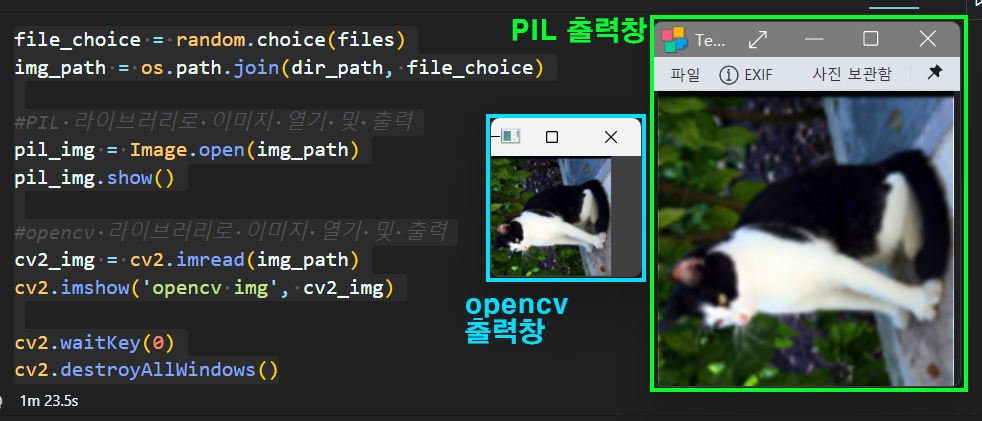 pil라이브로리로 이미지를 디스플레이 하면 윈도우에서 현재 사용중인 이미지 출력 기본 프로그램(필자의 경우 반디뷰를 기본 출력 프로그램으로 사용)으로 이미지를 출력하며,
pil라이브로리로 이미지를 디스플레이 하면 윈도우에서 현재 사용중인 이미지 출력 기본 프로그램(필자의 경우 반디뷰를 기본 출력 프로그램으로 사용)으로 이미지를 출력하며,
opencv는 독립적인 실행창을 생성하여 이미지를 출력한다.
이때 이미지의 픽셀 사이즈 그대로 맞춰서 출력하기에 STL10이미지 데이터셋의 픽셀사이즈인 [96x96]에 맞춰서 이미지를 출력한다.
# PIL 이미지 정보 출력
print("type:", type(pil_img)) # PIL이미지 자료형 type: <class 'PIL.PngImagePlugin.PngImageFile'>
print("Format:", pil_img.format) # 이미지 파일 포맷 Format: PNG
print("Size:", pil_img.size) # (width, height) 튜플로 반환 Size: (96, 96)
print("Mode:", pil_img.mode) # 이미지 모드 (예: "RGB", "L") Mode: RGBA
print("Width:", pil_img.width) # 이미지 너비 Width: 96
print("Height:", pil_img.height) # 이미지 높이 Height: 96
# 채널 수 계산
channels = len(pil_img.getbands()) # 채널 수 (예: "RGB" 모드는 3, "L" 모드는 1)
print("Channels:", channels) # Channels: 4# OpenCV 이미지 정보 출력
print("type:", type(cv2_img)) # opencv 자료형 type: <class 'numpy.ndarray'>
print("Shape:", cv2_img.shape) # (height, width, channels) 튜플 Shape: (96, 96, 3)
print("Width:", cv2_img.shape[1]) # 이미지 너비 Width: 96
print("Height:", cv2_img.shape[0]) # 이미지 높이 Height: 96
print("Channels:", cv2_img.shape[2]) # 채널 수 Channels: 3
# 이미지 데이터 타입 출력
print("Data type:", cv2_img.dtype) #Data type: uint8각 라이브러리 별로 이미지파일을 로드하여 객체화 했고 객체에 대한 정보를 확인 했으니 이제 두 라이브러리 간 이미지 변환을 수행하고자 한다.
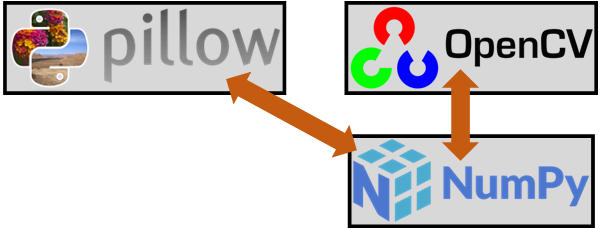 그림으로 표현하면 위 사진처럼 표현이 가능한데
그림으로 표현하면 위 사진처럼 표현이 가능한데
Opencv 라이브러리로 객체화된 변수의 기본 자료형은 numpy.ndarray 이기에 거의 따지고 보면 Opencv는 Numpy라이브러리 위에 올려진 패키지라 보면 되고
PIL은 독립적인 이미지 처리 라이브러리 이기에
PIL to Numpy 작업을 수행해야 한다.
1.1 PIL to Opencv
#PIL이미지 데이터를 Numpy 자료형으로 변환
pil_img_array = np.array(pil_img)
#numpy의 모양 출력 -> PNG파일일 경우 마지막 배열이 4임
print(pil_img_array.shape) #(96, 96, 4)
# 채널 수 확인 (4채널인 경우 알파 채널 제거)
if pil_img_array.shape[2] == 4: # RGBA 형식인 경우
rgb_array = pil_img_array[..., :3] # 알파 채널 제거
else:
rgb_array = pil_img_array
# RGB에서 BGR로 변환ㄴ
bgr_array = rgb_array[..., [2, 1, 0]]
bgr_array = cv2.resize(bgr_array, dsize=(0,0), fx=3, fy=3)
#리사이징 -> 보기 편하게 3배 늘리기
# OpenCV로 이미지 표시
cv2.imshow('Converted Image', bgr_array)
cv2.waitKey(0)
cv2.destroyAllWindows()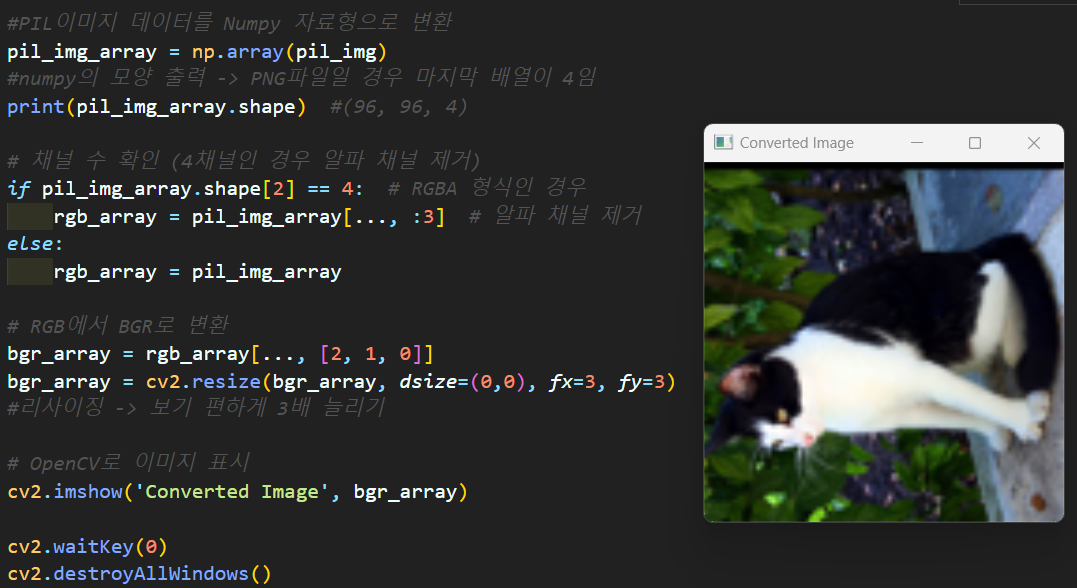
1.2 Opencv to PIL
# OpenCV 이미지를 RGB로 변환
cv2_img_rgb = cv2.cvtColor(cv2_img, cv2.COLOR_BGR2RGB)
# NumPy 배열을 PIL 이미지로 변환
pil_img = Image.fromarray(cv2_img_rgb)
# PIL 이미지 표시
pil_img.show()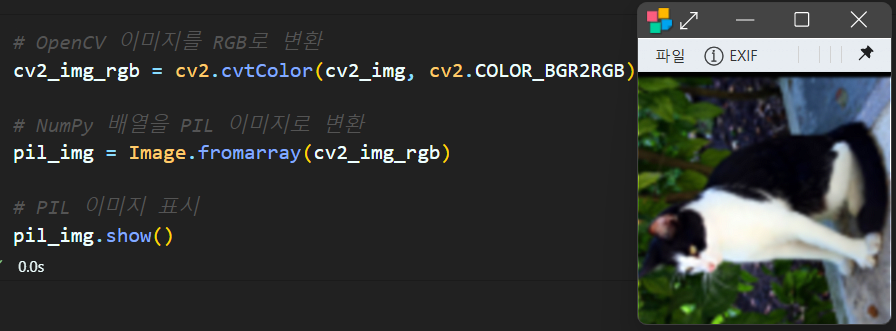
2. 데이터셋 만들기
이미지 파일에 대한 변환 과정을 학습했으니 STL10의 raw image파일 묶음을 딥러닝 모델에 입력 가능한 훈련/검증 데이터셋으로 변환하는 작업을 수행하고자 한다.
# 이미지 파일과 라벨 추출
images = []
labels = []
for file in files:
label = file.split('_')[0]
# 파일 이름에서 라벨 추출 (예: 'airplane_0073.png' -> 'airplane')
images.append(os.path.join(dir_path, file))
labels.append(label)첫번째로 앞서 이미지의 리스트가 저장된 files변수에 이미지의 파일 경로정보 / 이미지의 라벨정보를 추출하는 코드를 작성한 뒤
from sklearn.model_selection import train_test_split
# train_test_split을 사용하여 데이터 분리
train_images, test_images, train_labels, test_labels = train_test_split(
images, labels, test_size=0.2, stratify=labels
)위 코드를 사용하여 데이터를 분리하는 작업을 수행한다.
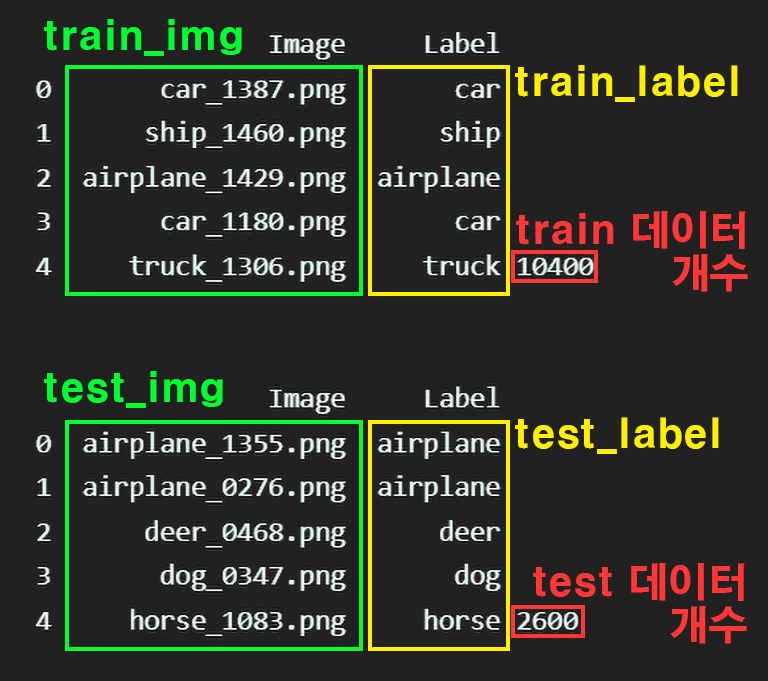 분리한 작업물을 위와 같은 구성으로
분리한 작업물을 위와 같은 구성으로 이미지, 라벨정보 그리고 test용, train용데이터로 분리가 잘 이뤄졌음을 확인할 수 있다.
2.1 데이터셋 클래스 설계
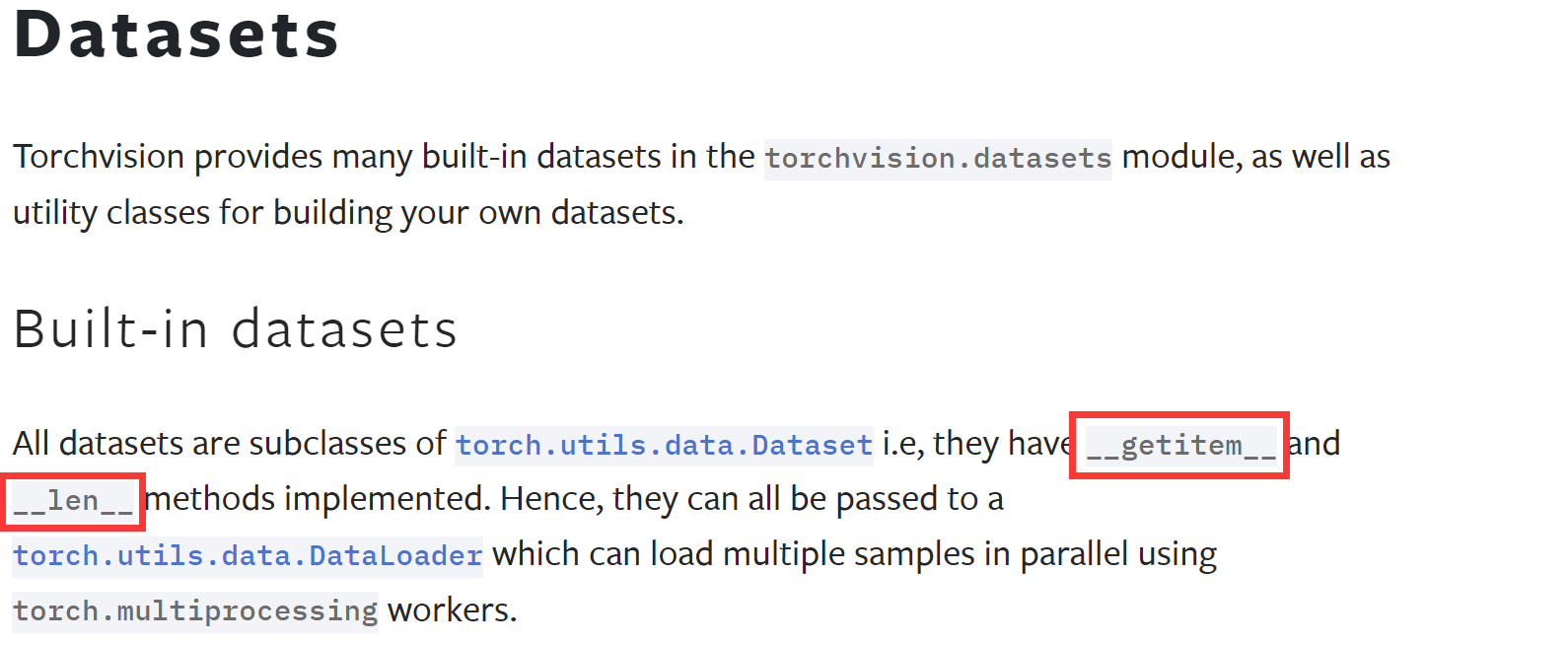 우선
우선 torch.utils.data.Dataset 라이브러리를 통해 제공되는 모든 데이터셋은 위 사진처럼
클래스 내부에 __getitem__, __len__ 두개의 매직 메서드가 포함된 클래스로 설계되어 있다 한다.
이를 그대로 따라해서 커스텀 데이터셋 클래스를 설계하고
train_images, test_images, train_labels, test_labels 4개의 변수를 넣어서 자료변환을 수행하면 된다.
import torch
from torch.utils.data import Dataset
class CustomDataset(Dataset):
def __init__(self, image_paths, labels, transform=None):
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
image = Image.open(image_path).convert("RGB")
label = self.labels[idx]
if self.transform:
image = self.transform(image)
return image, label
@property
def label(self):
return self.labels클래스의 설계는 이미지, 라벨두개의 정보를 받아서
객체화 된 데이터셋의 길이정보 출력 -> __len__
객체화된 데이터셋이 데이터로더에 잘 적용될 수 있도록 입력받은 이미지 정보의 간단한 전환
image = Image.open(image_path).convert("RGB")거기에 인덱싱이 가능하게 조정 -> __getitem__
객체화된 데이터셋은 전처리가 가능해야 하니
if self.transform:
image = self.transform(image)마지막 구문
@property
def label(self):
return self.labels이 부분은
이 영상을 참조하는게 옳을 듯 하다.
결론만 말하자면
위 설계한 CustomDataset을 바탕으로
# Custom Dataset 생성
train_dataset = CustomDataset(train_images, train_labels)
test_dataset = CustomDataset(test_images, test_labels)이렇게 객체화 시켰을 때
train_dataset.labels
test_dataset.labels 와 같이 .labels 메서드를 붙이면 라벨 정보를 추출하는 기능을 수행할 수 있게 만들어 준다는 것이다.
원래 def label(self): 이렇게 설계된 메서드는
train_dataset.labels() 이렇게 메서드를 붙여야 하지만, 마지막 ()를 빼주는게 @property이라 보면 된다.
아무튼 설계한 CustomDataset 클래스로 성공적으로
train_dataset, test_dataset객체를 만들어 냈다.
from torchvision.transforms import v2
# STL-10 데이터셋의 mean과 std 값
STL10_VAL = ((0.4467, 0.4398, 0.4066), (0.2603, 0.2566, 0.2713))
#전처리 방법론 설계
transformation = v2.Compose([
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=STL10_VAL[0], std=STL10_VAL[1])
])
#전처리 방법론 적용
train_dataset.transform = transformation
test_dataset.transform = transformation위 코드로 train_dataset, test_dataset객체의 전처리 방법론을 torchvision.transforms.v2API를 통해 수행하고
BATCH_SIZE = 128
#데이터로더 생성
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)딥러닝 모델에 입력가능한 데이터로더 자료형으로 변환한다.
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
if isinstance(labels, torch.Tensor):
print(f"라벨 크기: {labels.size()}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
else:
print(f"라벨 크기: {len(labels)}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break# train_loader 정보 출력
print_dataloader_info(train_loader, "Train Loader")Train Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 224, 224])
라벨 크기: 128
첫 번째 이미지의 라벨: deer# test_loader 정보 출력
print_dataloader_info(test_loader, "Test Loader")Test Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 224, 224])
라벨 크기: 128
첫 번째 이미지의 라벨: deer정상적으로 Dataloader 자료형까지 변환이 완료된 것을 확인할 수 있다.
3. 범주형 데이터 관리
위 과정까지 수행하여 Dataloader을 생성하여 이를 입력하면 딥러닝 모델의 구동이 불가능하다.
이유는 딥러닝 모델은 대부분
x(독립변수)에 속하는 데이터는 torch.flaot32 형태
y(종속변수)에 속하는 데이터는 torch.int64형태로 받아야 한다.
예를 들어 CNN을 본다면
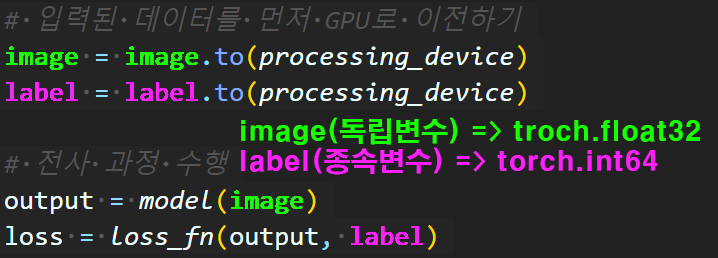 위 사진처럼
위 사진처럼
image(독립변수) 데이터는 torch.float32
label(종속변수) 데이터는 torch.int64
로 받아야 한다.
따라서
import os
dir_path = './../00_pytest_img/stl10/data/raw_img_data'
#폴더 경로 가져오기
files=[f for f in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, f))]
#폴더 경로 내 '이미지'파일 만 찾아서 리스트로 저장from sklearn.model_selection import train_test_split
# 이미지 파일과 라벨 추출
images = []
labels = []
for file in files:
label = file.split('_')[0]
# 파일 이름에서 라벨 추출 (예: 'airplane_0073.png' -> 'airplane')
images.append(os.path.join(dir_path, file))
labels.append(label)
# train_test_split을 사용하여 데이터 분리
train_images, test_images, train_labels, test_labels = train_test_split(
images, labels, test_size=0.2, stratify=labels
)여기까지 수행하여 얻은 train_labels, test_labels데이터를 확인 해 봤을 때
['cat', 'monkey', 'dog'....'dog', 'horse']
<class 'list'> -> labels 데이터 타입
<class 'str'> -> labels의 원소 데이터타입라벨 데이터 타입이 str 즉, 범주형 데이터이니 정수형 데이터로 전환을 해줘야 한다.
1) Unique 라벨 추출
#범주형 데이터에서 Unique 리스트 추출
unique_labels = list(set(train_labels))
print(unique_labels)['truck', 'airplane', 'car', 'cat', 'horse', 'bird', 'ship', 'dog', 'deer', 'monkey']일단 첫번째로 Unique 라벨 데이터만을 먼저 추출한다
STL10데이터셋에 포함되어 있는 class_names.txt텍스트 파일을 이용하는 것도 방법이긴 하지만 파일 접근보다는 변수 데이터를 정제하는 식으로 라벨 데이터를 추출했다.
2) LabelEncoder
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.LabelEncoder.html
다음으로는 sklearn 라이브러리 (머신러닝 및 데이터 분석에 편의성을 제공하는 라이브러리)
의 LabelEncoder 클래스를 사용하고자 한다.
해당 클래스는 4개의 주요 메서드를 제공하고 있으며, 그 기능은 아래와 같다.
| 메서드 | 설명 |
|---|---|
fit(y) | 주어진 데이터 y를 학습하여 각 고유 값에 대한 인코딩을 설정합니다. |
transform(y) | 학습된 인코딩을 바탕으로 주어진 데이터 y를 변환합니다. |
fit_transform(y) | fit과 transform을 동시에 수행합니다. |
inverse_transform(y) | 인코딩된 정수 데이터를 원래의 범주형 데이터로 변환합니다. |
여기서 필자는 fit(), transform() 두 메서드르 사용하여 범주형 데이터 정수형 데이터전환을 수행하고자 한다.
e = LabelEncoder() # LabelEncoder 객체를 생성
e.fit(unique_labels) #labelEncoder을 '라벨 정보'로 학습시킴
print(e.classes_) #학습된 LabelEncoder 정보를 확인하기 위한 용도
#학습된 LabelEncoder로 Label데이터셋의 정수형 데이터 전환
train_labels_encoded = e.transform(train_labels)
test_labels_encoded = e.transform(test_labels)-> print(e.classes_) 출력 결과 :
['airplane' 'bird' 'car' 'cat' 'deer' 'dog' 'horse' 'monkey' 'ship' 'truck']print(train_labels_encoded)
print(train_labels)[3 7 5 ... 2 8 0]
['cat', 'monkey', 'dog' ... 'car', 'ship', 'airplane']위와 같은 방식으로 범주형 데이터 정수형 데이터전환을 완료했다.
2-1) 선택사항 : One-Hot-Encoding
여기까지 수행하면 정수형 데이터로 전환이 되어 어느정도 사용이 가능한 데이터이긴 하지만
딥러닝 모댈의 입력에 따라 One-Hot-Encoding까지 해줘야 하는 경우가 있다.
이를 그림으로 표현하면 아래와 같다.
 위 One-Hot 인코딩 과정은 아래의 코드를 수행하여 데이터 전환을 할 수 있다.
위 One-Hot 인코딩 과정은 아래의 코드를 수행하여 데이터 전환을 할 수 있다.
import torch
import torch.nn.functional as F
#정수형 데이터를 Tensor 자료형으로 변환
train_lables_tensor = torch.tensor(train_labels_encoded, dtype=torch.long)
test_labels_tensor = torch.tensor(test_labels_encoded, dtype=torch.long)
#고유 라벨 개수 추출 -> 이후 텐서 자료형 변환
num_classes = torch.tensor(len(unique_labels))
#One-Hot 인코딩 수행
train_labels_one_hot = F.one_hot(train_lables_tensor, num_classes=num_classes)
test_labels_tensor = F.one_hot(test_labels_tensor, num_classes=num_classes)tensor([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 1, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 1, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 1, 0],
[1, 0, 0, ..., 0, 0, 0]])이 One-Hot-Encoding 및 정수형 라벨 데이터는 딥러닝 모델에 입력 가능한 데이터 자료형으로 변환하는 데이터 전처리 과정의 첫번째 스탭이니 잊지말고 반복하여 체화 하자
3) 데이터셋, Dataloader 만들기
데이터 전처리가 완료된 변수들에 대하여 DataLoader 자료형을 만들 때 입력 가능한 자료형으로 다시 또 만들어줘야 한다.
그것에 대한 코드는 데이터셋 전처리를 수행하는 클래스를 설계하여 해결한다
from torch.utils.data import Dataset
from PIL import Image
class CustomDataset(Dataset):
def __init__(self, image_paths, labels, transform=None):
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
image = Image.open(image_path).convert("RGB")
label = self.labels[idx]
if self.transform:
image = self.transform(image)
label = torch.tensor(label, dtype=torch.int64)
# 라벨을 torch.int64로 변환
return image, label
@property
def label(self):
return self.labelsDataLoader 자료형을 만들려면 입력받는 데이터셋은
1) 자료형이 길이 추출이 가능해야 하고(len() 메서드가 먹혀야함)
2) 자료형이 인덱싱이 가능해야함(자료객체[idx]가 되야함)
위 두 기능이 동작해야 한다
파이썬 클래스에서 위 기능이 동작하게 하려면 __len__, __getitem__ 매직메서드의 기능구현을 해주면 된다.
그것에 대한 코드가 위 class CustomDataset(Dataset):의 설계이다.
그리고 Tensor 자료형으로 전환하는 데이터 전처리 코드(transform)로 해당 데이터셋을 전환 할때
if self.transform:
image = self.transform(image)
label = torch.tensor(label, dtype=torch.int64)위 코드가 동작하여
독립변수 데이터(Image)는 이미지 텐서 자료형으로 전환되고
종속변수 데이터(Label)은 데이터 타입이 torch.int64로 전환되도록 설계한다.
따라서
# Custom Dataset 생성
train_dataset = CustomDataset(train_images, train_labels_encoded)
test_dataset = CustomDataset(test_images, test_labels_encoded)from torchvision.transforms import v2
from torch.utils.data import DataLoader
# STL-10 데이터셋의 mean과 std 값
STL10_VAL = ((0.4467, 0.4398, 0.4066), (0.2603, 0.2566, 0.2713))
#텐서 자료형 전환 전처리 방법론 설계
transformation = v2.Compose([
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=STL10_VAL[0], std=STL10_VAL[1])
])
#텐서 자료형 전환 전처리 방법론 적용
train_dataset.transform = transformation
test_dataset.transform = transformation까지 수행하면 안정적으로 아래의 최종 코드
BATCH_SIZE = 128
#데이터로더 생성
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)DataLoader 자료형을 생성하고 이 생성된 데이터셋이 딥러닝 모델의 입력 인자 조건을 충족한다.
4) 데이터 검토
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
if isinstance(labels, torch.Tensor):
print(f"라벨 크기: {labels.size()}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
print(f'라벨의 데이터타입 : {labels[0].dtype}')
else:
print("데이터셋이 잘못됬으니 검토 바람")
print(f"라벨 크기: {len(labels)}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
print(f'라벨의 데이터타입 : {type(labels[0])}')
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break설계한 데이터셋을 검토하는 코드를 사용하여 정보를 확인하자.
# train_loader 정보 출력
print_dataloader_info(train_loader, "Train Loader")
# test_loader 정보 출력
print_dataloader_info(test_loader, "Test Loader")Train Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 224, 224])
라벨 크기: torch.Size([128])
첫 번째 이미지의 라벨: 7
라벨의 데이터타입 : torch.int64
Test Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 224, 224])
라벨 크기: torch.Size([128])
첫 번째 이미지의 라벨: 8
라벨의 데이터타입 : torch.int64이런 식으로 데이터 디버깅까지 수행을 진행하자
