
개요
본 블로그 포스팅은 수도권 ICT 이노베이션 스퀘어에서 진행하는 인공지능 고급-시각 강의의 CNN알고리즘 강좌 내용을 필자가 다시 복기한 내용에 관한 것입니다.
1. ResNet 배경
 ResNet은 ILSVRC15와 COCO15에서 우승을 차지한 마이크로소프트 연구팀이 개발한 네트워크로 Inception Module이란 개념으로 설계된 GoogLeNet과는 다른 방식으로 Residual Block(Skip connection)이란 개념을 도입하여 Depth가 깊은 네트워크를 효과적으로 훈련하는 방법을 제시하였다.
ResNet은 ILSVRC15와 COCO15에서 우승을 차지한 마이크로소프트 연구팀이 개발한 네트워크로 Inception Module이란 개념으로 설계된 GoogLeNet과는 다른 방식으로 Residual Block(Skip connection)이란 개념을 도입하여 Depth가 깊은 네트워크를 효과적으로 훈련하는 방법을 제시하였다.
1.1 Residual block
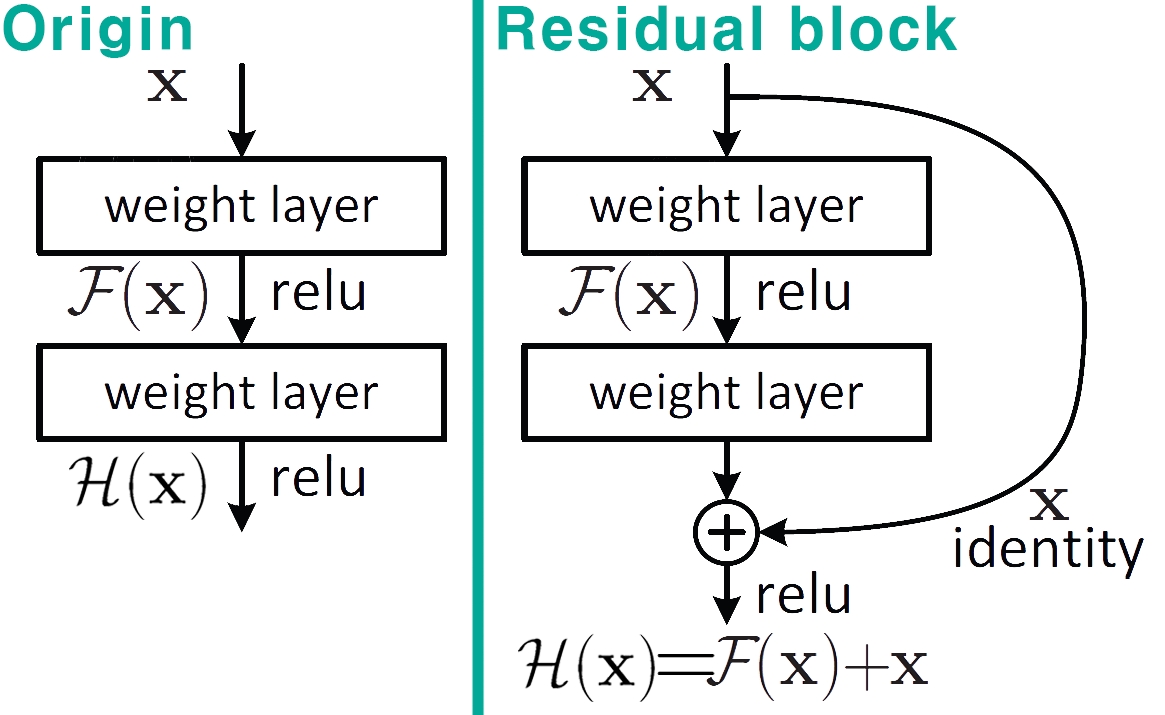 기존 신경망의 구조는
기존 신경망의 구조는 Origin과 같이 입력 데이터 가 weight layer의 블록 연산을 통과하여 Sequential하게 , 의 출력 데이터로 변한다면, Residual block는 Skip connection이란 개념을 도입하여 입력 데이터 를 블록 연산을 건너 뛰고 중간 연산 출력 에 더해 최종 출력 를 생성하는 방식이다.
이 Residual block구조의 도입으로 깊은 구조의 네트워크를 설계하더라도 기울기 소실(vanishing gradient)현상의 발현을 억제하는 역할을 수행한다. 따라서 깊은 네트워크에 Residual block을 도입 시 학습성능이 유지되거나 향상되는 것을 확인하였다.
흔히 Residual block의 도입을 통해 기울기 소실 문제가 해결되었다 라고 설명을 진행하는 블로그가 많으나, 원 논문에서도 언급되었듯이 기울기 소실 문제는 BatchNormalization, 이미지 정규화를 통해 대부분 해결되었다 설명하고 있다.
그러나 네트워크의 깊이가 증가하면 이상하게, 알 수 없는 이유로 모델의 Accuracy성능이 하락하는 현상이 발생하며, 이는 과적합(Overfitting)문제도 아닌것으로 논문에서 증명했다.
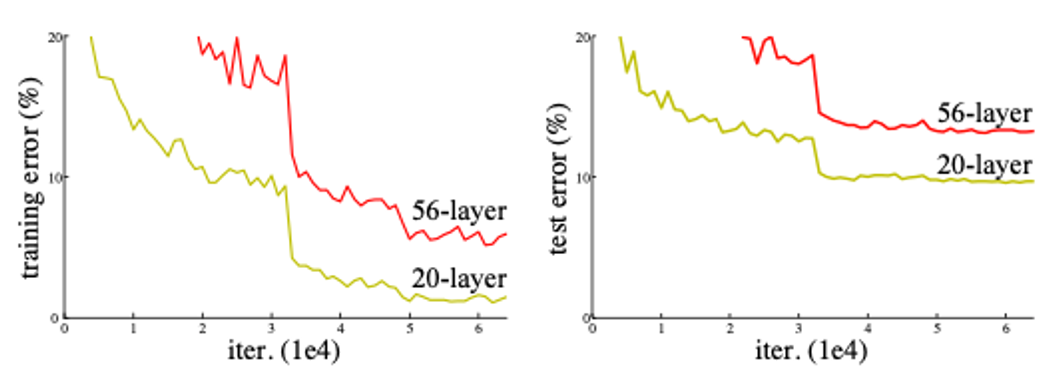 레이어의 깊이가 깊은 모델이 레이어의 깊이가 얕은 모델 대비 성능이 낮으며, 모든 훈련 epoch단계에서 동일하게 발생하는 것으로 보아 이는 과적합 문제가 아님을 증명하는 그래프
레이어의 깊이가 깊은 모델이 레이어의 깊이가 얕은 모델 대비 성능이 낮으며, 모든 훈련 epoch단계에서 동일하게 발생하는 것으로 보아 이는 과적합 문제가 아님을 증명하는 그래프
따라서 이 알 수 없는 성능 저하 문제
(Degradation problem)의 원인을 찾아내고, 해결한 것이 ResNet의 Residual connection이라 보면 된다.
논문에서는 Degradation problem을 3가지 원인으로 보고 있다.
-
Optimization Difficulty : 네트워크 깊어지면서 모델의 복잡도가 높아짐 → 학습이 제대로 수행되지 않음
-
Vanishing Gradient : 깊은 네트워크에 경사하강법 적용 시, 역전파 과정에서 Gradient가 점점 작아지기에 초기 층(모델의 앞단)까지 학습 신호가 잘 전달되지 않음 → 학습이 제대로 수행되지 않음
-
Information Loss : 네트워크가 깊어질 수록 입력 데이터에 포함된 정보가 여러 층을 거치면서 왜곡&소실 가능성이 높아짐 → 이 오염정보가 계속 누정되는 문제로 성능이 저하됨
위 3가지 문제를 Residual connection도입으로 해결한 것이며
- 층 사이의 직접연결 Path를 구성해 Optimizer가 모델을 더 쉽게 학습함
- 그래디언트 역전파의 경로를 단축 & 그래디언트의 보존력을 높임
- 직접 연결 Path로 오염 정도를 보정
의 효과를 만들어 냈다
따라서 Residual connection이 단순히 vanishing gradient만을 해소한 것은 아니며,
위 3가지 문제를 해결해 냄으로써 모델의 깊이를 깊게 쌓을 수 있는 지평을 열어냈다 로 보는것이 더 옳은 시각이다.
1.2 Bottleneck
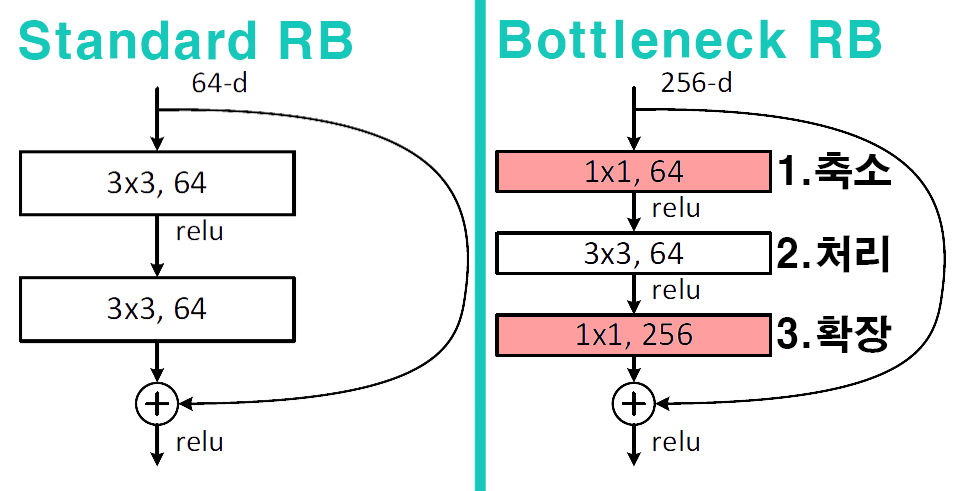 다음으로 ResNet에 도입된 기법은
다음으로 ResNet에 도입된 기법은 Bottleneck 구조로 Residual block의 맨 앞단, 뒷단 레이어에 각각 1x1 Conv Layer을 추가한 구조를 말한다.
Bottelneck는 크게 3단계로 구조를 나누어 볼 수 있으며
1) 축소단계 : 입력 채널 수를 줄여 연산량을 줄이는 효과를 발생
2) 처리단계 : 공간적 특징을 추출
3) 확장 단계 : 줄어든 채널 수를 원래대로 복원하여 입력출력 전체 과정의 채널 수를 일치
의 3단계 과정을 거친다.
이 과정에서 정보 손실의 가능성이 있으나, 이 구조를 도입함으로써 얻는 연산량 감소의 효과가 더 크기에 논문에서 제안하는 ResNet-50, ResNet-101, ResNet-152에 해당 구조가 적용되었다.
2. ResNet-101 아키텍쳐
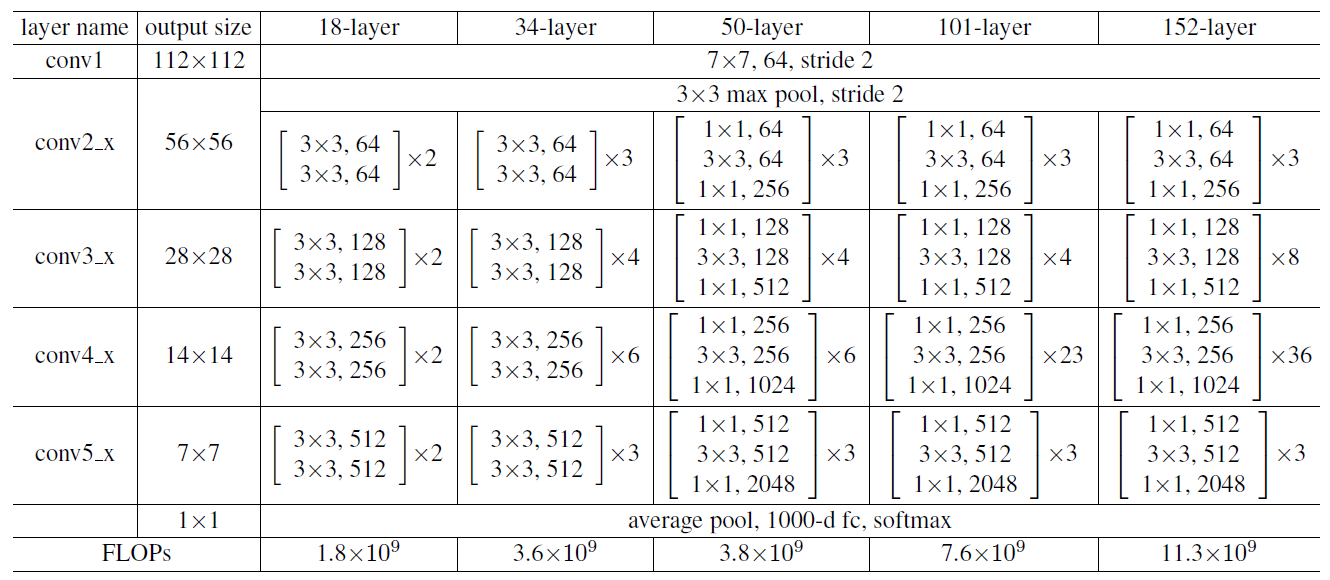 ResNet은 [224x224x3] 입력을 받으며, 5개의 Conv block, 1개의 Dense block로 구성되어 있으며, 각각의 블록 내부에는 기본 블록단위가 반복하여 쌓이는 구조를 취하고 있다.
ResNet은 [224x224x3] 입력을 받으며, 5개의 Conv block, 1개의 Dense block로 구성되어 있으며, 각각의 블록 내부에는 기본 블록단위가 반복하여 쌓이는 구조를 취하고 있다.
각 아키텍쳐 별 코드 설계를 본다면
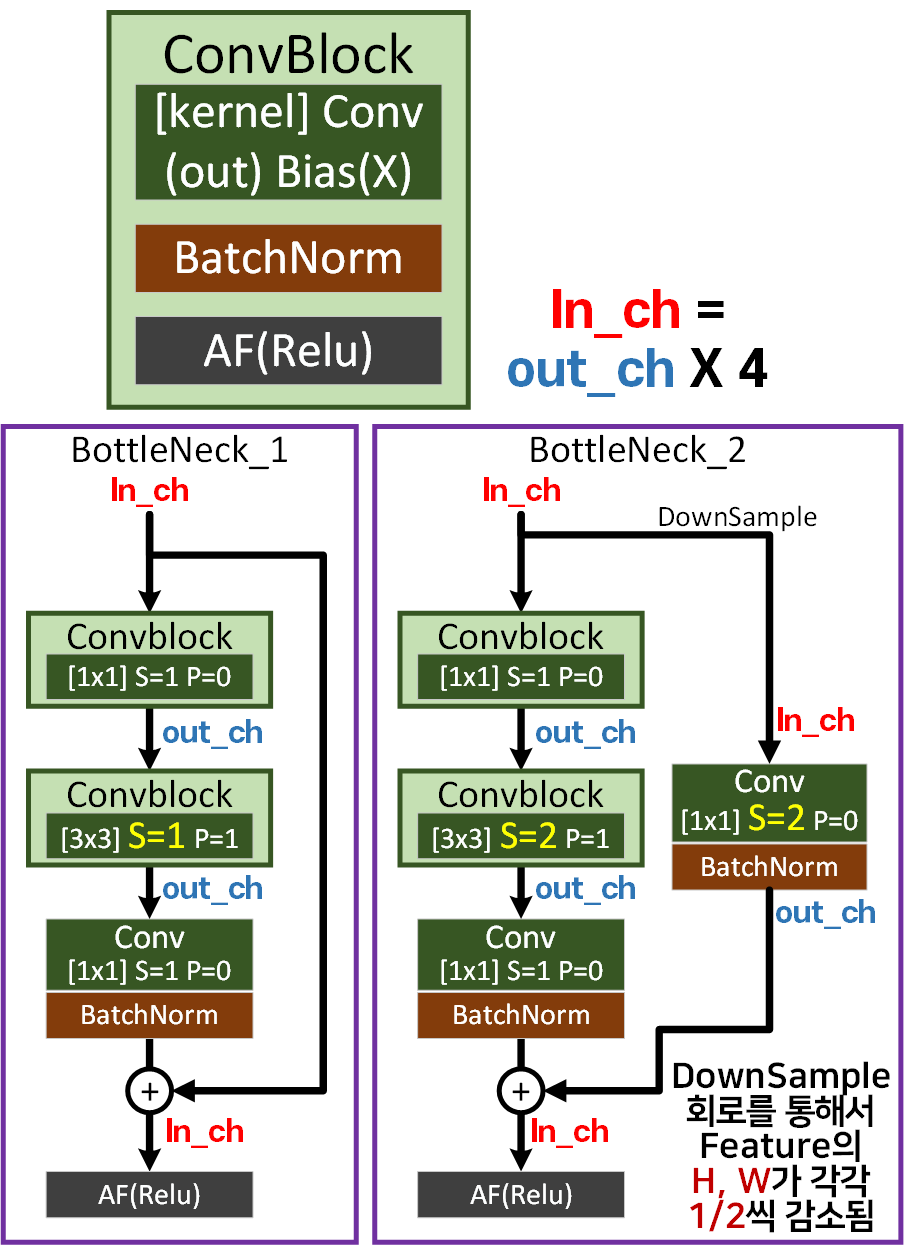 첫번째로 설명하고자 하는건 ResNet의 기본 블록에 해당하는 ConvBlock, BottleNeck Residual Block의 버전1 버전2이다.
첫번째로 설명하고자 하는건 ResNet의 기본 블록에 해당하는 ConvBlock, BottleNeck Residual Block의 버전1 버전2이다.
ResNet의 가장 기본이 되는 블럭은
Conv BN AF 이 3개의 레이어가 하나로 묶여서 동작하는 ConvBlock이 있고
이 ConvBlock이 포함되어 BottleNeck Residual Block이 구성된다.
이때 버전1과 버전2가 있는데 기능상의 차이가 크게 발생하는 것은 아니고 버전 2의 경우 입력되는 채널과 출력되는 채널의 차원을 맞추기 위해 Skip connection의 우회로에 해당하는 DownSample Path에 Conv BN이 붙는다 생각하면 된다.
이 DownSample Path는 Feature의 차원이
(bs, ch, h, w)라 할 때
Stride=1일 때는 크게 문제가 없으나(BottelNeck_1)
Stride=2일 때는 h, w가 각각 1/2씩 감소하게 된다. 따라서 이 Feature의 h, w가 감소된것을
우회로에서 맞추기 위해 DownSample Path가 적용된다. (BottelNeck_2)
위 기본블록을 모두 적용한 ResNet-101의 최종 구조는 아래와 같다.
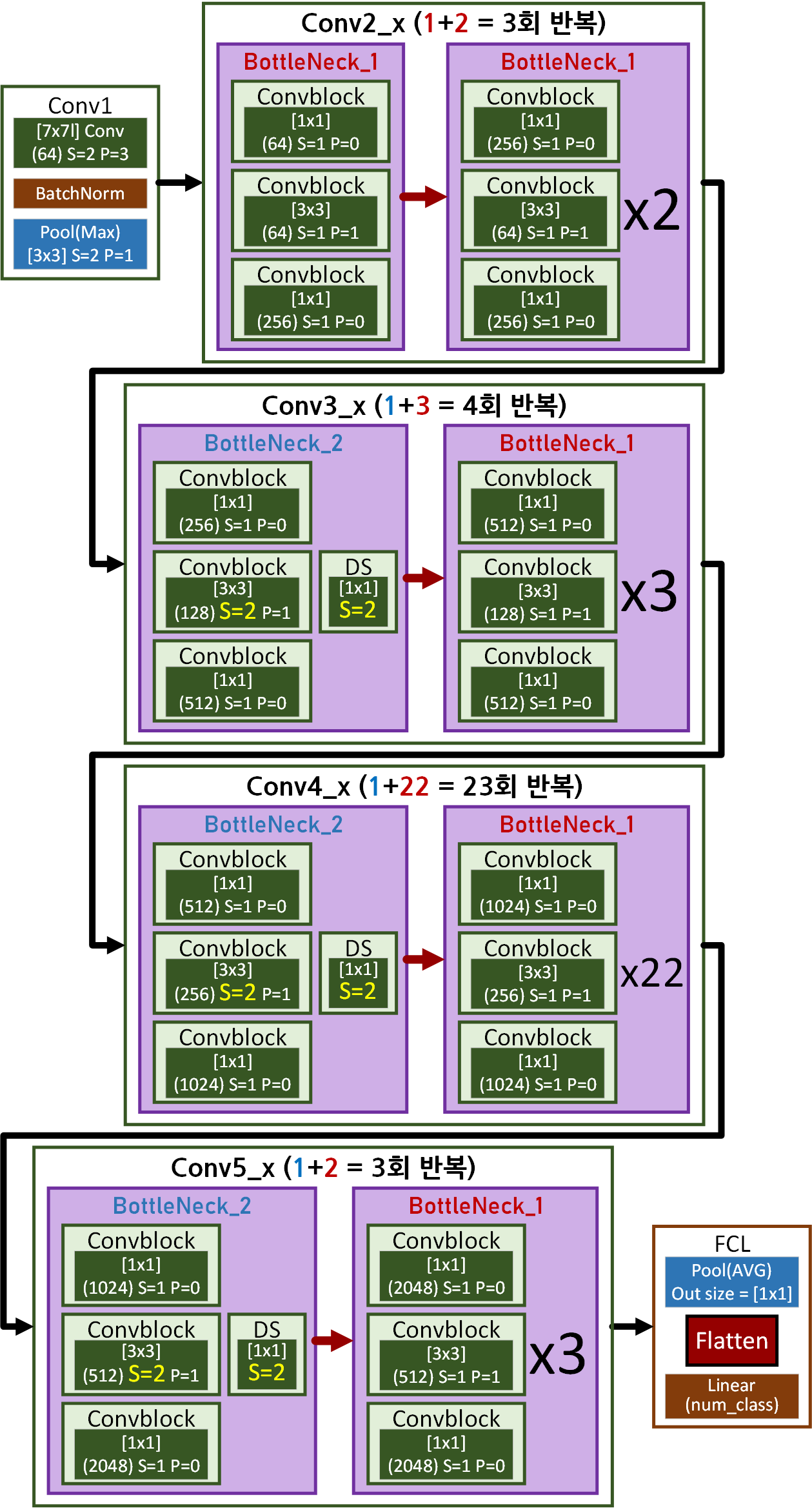
conv[i]_x block의 내부 반복 블럭 중 맨 앞에 해당하는 블럭은 상황에 따라 BottleNeck 2나 1이 붙고, 나머지는 버전1이 반복되는 형상이라 보면 된다.
위 네트워크 구조를 각각 코드로 구현하면 아래와 같다.
import torch
import torch.nn as nnclass BasicConv(nn.Module):
def __init__(self, in_ch, out_ch, relu=False, **kwargs):
super(BasicConv, self).__init__()
self.conv = nn.Conv2d(in_ch, out_ch, **kwargs, bias=False)
self.bn = nn.BatchNorm2d(out_ch)
self.relu = relu
if relu: #여기서 Relu가 있고/없고를 결정하는게 코드짜기 더 편함
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
if self.relu:
x = self.relu(x)
return xclass BottleNeck(nn.Module):
expansion = 4
def __init__(self, in_ch, out_ch, stride=1):
super(BottleNeck, self).__init__()
#축소단계
self.conv1 = BasicConv(in_ch, out_ch, kernel_size=1,
stride=1, padding=0, relu=True)
#처리단계
self.conv2 = BasicConv(out_ch, out_ch, kernel_size=3,
stride=stride, padding=1, relu=True)
#확장단계 extension 계수를 붙여서 채널을 4배 확장
self.conv3 = BasicConv(out_ch, out_ch*self.expansion, kernel_size=1,
stride=1, padding=0, relu=False)
self.relu = nn.ReLU()
self.downsample = None
#ch, h, w의 변화에 유연하게 대응하기 위한 우회로의 Downsample Path설계
if in_ch != out_ch*self.expansion or stride != 1:
self.downsample = BasicConv(in_ch, out_ch*self.expansion, kernel_size=1,
stride=stride, relu=False)
def forward(self, x):
if self.downsample is not None:
identity = self.downsample(x)
else:
identity = x
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out += identity #여기가 Residual connection
out = self.relu(out)
return outclass ResNet(nn.Module):
def __init__(self, layers, num_classes=1000):
super(ResNet, self).__init__()
self.in_ch = 64
self.conv1 = nn.Sequential(
BasicConv(3, self.in_ch, kernel_size=7, stride=2, padding=3, relu=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.conv2_x = self._make_layer(64, layers[0])
self.conv3_x = self._make_layer(128, layers[1], stride=2)
self.conv4_x = self._make_layer(256, layers[2], stride=2)
self.conv5_x = self._make_layer(512, layers[3], stride=2)
self.classifier = nn.Sequential(
#AdaptiveAvgPool = Feature의 H, W를 인자값에 맞춰서 축소
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
#마지막 FCL은 (2048, num_classes)가 된다.
nn.Linear(512 * BottleNeck.expansion, num_classes)
)
def _make_layer(self, out_ch, num_block, stride=1):
layers = []
#BottleNeck 버전 2 또는 1이 적용됨(한번만)
layers.append(BottleNeck(self.in_ch, out_ch, stride))
#다음 BottleNeck는 버전 1이 적용됨(stride=1)
self.in_ch = out_ch * BottleNeck.expansion
for _ in range(1, num_block):
layers.append(BottleNeck(self.in_ch, out_ch))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.conv2_x(x)
x = self.conv3_x(x)
x = self.conv4_x(x)
x = self.conv5_x(x)
x = self.classifier(x)
return x위 3가지 블럭에 대한 설계도를 바탕으로 ResNet-50, ResNet-101, ResNet-152를 유연하게 설계할 수 있으며,
논문에서 언급된 ResNet-18, ResNet-34는 BottleNeck Residual Block이 아닌 Residual Block이 기본블럭으로 들어가서 이 네트워크까지 설계되게끔 더 동적으로 설계하다가는 머리가 터질거 같아서 Skip했다.
# ResNet-50 객체화
model_50 = ResNet([3, 4, 6, 3], num_classes=1000)
# ResNet-101 객체화
model_101 = ResNet([3, 4, 23, 3], num_classes=1000)
# ResNet-152 객체화
model_152 = ResNet([3, 8, 36, 3], num_classes=1000)각 모델의 초기화는 위 코드처럼 블록 당 레이어 반복횟수를 리스트 인자값으로 넘겨주면 된다.
from torchsummary import summary #설계한 모델의 요약본 출력 모듈
summary(model_101, input_size=(3, 224, 224), device='cpu')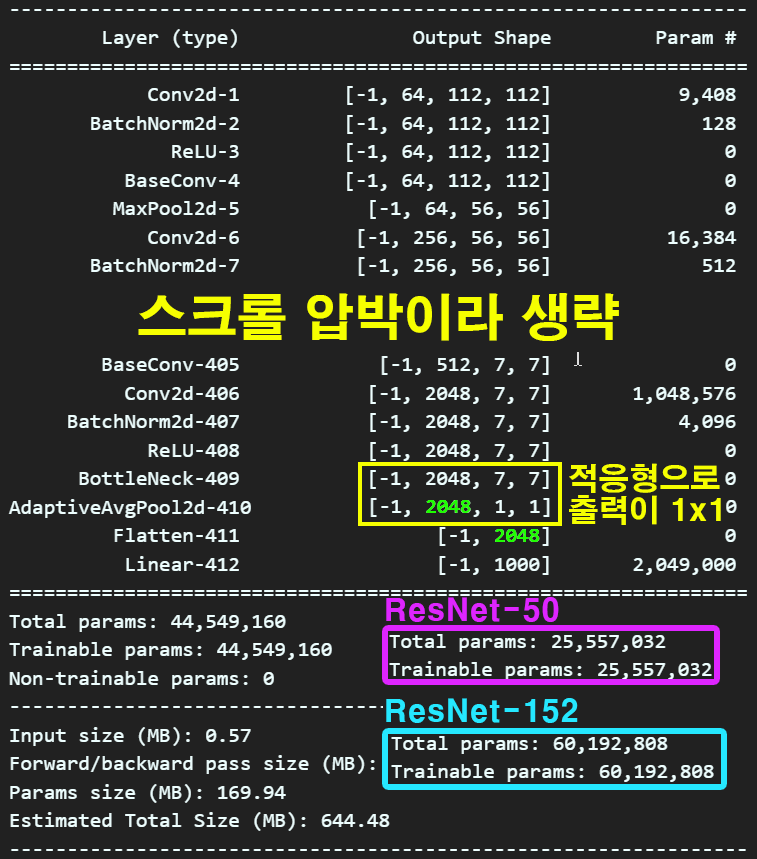 네트워크의 깊이 별로 파생된 버전인
네트워크의 깊이 별로 파생된 버전인 ResNet-50, ResNet-101, ResNet-152을 살펴보면 파라미터의 개수가 각각 2천5백만, 4천4백만, 6천만으로 이전 포스팅의 VGG19 보다 레이어의 깊이는 깊으면서, 전체 파라미터의 양은 적은 것을 확인할 수 있다.
3. 데이터셋 설정
이전 포스팅15. 이미지 데이터셋에서 생성한 STL10의 커스텀 버전 데이터셋을 활용해 보려 한다.
솔직하게 고해를 하자면 이전 포스팅에서 완성한 데이터 전처리는 반쪽짜리 데이터 전처리를 수행한 것이다.
바로 라벨 데이터가 범주형 데이터라는 문제이다.
이범주형 데이터를 One hot encoding을 통해서 정석대로 숫자 배열 데이터로 변환해 주던가
아니면 PyTorch이 소화 가능한 torch.int64자료형으로 변환을 해줘야 한다.
변환은 train_test_split으로 데이터를 분기한 이후에 진행하는 코드를 첨부하여 수행하겠다.
import os
from sklearn.model_selection import train_test_split
dir_path = './../00_pytest_img/stl10/data/raw_img_data'
files=[f for f in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, f))]
# 이미지 파일과 라벨 추출
images = []
labels = []
for file in files:
label = file.split('_')[0]
# 파일 이름에서 라벨 추출 (예: 'airplane_0073.png' -> 'airplane')
images.append(os.path.join(dir_path, file))
labels.append(label)
# train_test_split을 사용하여 데이터 분리
train_images, test_images, train_labels, test_labels = train_test_split(
images, labels, test_size=0.2, stratify=labels우선 첫번째로 이전 포스팅의 데이터 분기하는 코드까지 불러와서 실행해
train_images, test_images,
train_labels(범주형 데이터), test_labels(범주형 데이터)
4개의 변수를 생성한 뒤
from sklearn.preprocessing import LabelEncoder
#현재 train_labels, test_labels는 범주형 데이터임
unique_labels = list(set(train_labels))
print(unique_labels, type(unique_labels))
e = LabelEncoder() # LabelEncoder 객체를 생성
e.fit(unique_labels) #labelEncoder을 '라벨 정보'로 학습시킴
# 학습시킨 labelEncoder를 train_labels, test_labels에 적용해
# 범주형 데이터 -> 정수형 데이터 로 변환 시킴
train_labels_encoded = e.transform(train_labels)
test_labels_encoded = e.transform(test_labels)위 코드를 수행하면
['bird', 'horse', 'car', 'dog', ...] -> 초기의 범주형 데이터
[2 7 0 ... 2 6 5] -> 변환 후 정수형 데이터와 같이 범주형 데이터가 쓸 수 있는
정수형 데이터가 된다.
PyTorch는 여기까지 진행해줘도 된다.
원래 정석대로라면 One hot encoding를 도입해야 하지만
PyTorch는 CrossEntropyLoss함수가 정수형 라벨을 받아도 적합하게 손실값을 계산해 낼 수 있다.
여기까지 수행했다고 끝나는 것이 아니다. 이 정수형 데이터의 데이터 타입도 변환을 해줘야 한다.
from torch.utils.data import Dataset
from PIL import Image
class CustomDataset(Dataset):
def __init__(self, image_paths, labels, transform=None):
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
return len(self.image_paths)
def __getitem__(self, idx):
image_path = self.image_paths[idx]
image = Image.open(image_path).convert("RGB")
label = self.labels[idx]
if self.transform:
image = self.transform(image)
label = torch.tensor(label, dtype=torch.int64)
# 라벨을 torch.int64로 변환
return image, label
@property
def label(self):
return self.labels위 코드를 보면 데이터 전처리 수행의 트리거인
if self.transform:
image = self.transform(image)
label = torch.tensor(label, dtype=torch.int64)항목에 진입할 때 이미지 데이터의 전처리도 수행하지만
라벨데이터의 자료형을 int32에서 torch.int64로 변환한다.
이거까지 해야 딥러닝 모델을 구동하는데 CrossEntropyLoss함수가 재대로 동작한다.
https://discuss.pytorch.org/t/crossentropyloss-longtensor-error/3553
 문서 상으로는 확인이 어려웠지만 커뮤니티의 답변을 보면
문서 상으로는 확인이 어려웠지만 커뮤니티의 답변을 보면
라벨 데이터는 LongTensor = torch.int64이어야 만 한다...
이렇게 범주형 데이터 정수형 데이터 torch.int64까지 해준 뒤에
# Custom Dataset 생성
train_dataset = CustomDataset(train_images, train_labels_encoded)
test_dataset = CustomDataset(test_images, test_labels_encoded)데이터셋 생성을 완료하고
from torchvision.transforms import v2
# STL-10 데이터셋의 mean과 std 값
STL10_VAL = [[0.4467, 0.4398, 0.4066], [0.2603, 0.2566, 0.2713]]
#전처리 방법론 설계
train_transformation = v2.Compose([
#훈련데이터용 데이터 증강기법
v2.RandomResizedCrop((224,224)),
v2.RandomHorizontalFlip(p=0.5),
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=STL10_VAL[0], std=STL10_VAL[1]) #데이터셋 정규화
])
test_transforamtion = v2.Compose([
v2.Resize((224, 224)), #이미지 크기를 224x224로
v2.ToImage(), # 이미지를 Tensor 자료형으로 변환
v2.ToDtype(torch.float32, scale=True), #텐서 자료형을 [0~1]로 스케일링
v2.Normalize(mean=STL10_VAL[0], std=STL10_VAL[1]) #데이터셋 정규화
])
#전처리 방법론 적용
train_dataset.transform = train_transformation
test_dataset.transform = test_transforamtion설계한 전처리 방법론을 적용하고
from torch.utils.data import DataLoader
BATCH_SIZE = 128
#전처리가 완료된 데이터셋을 Mini-batch가 생성가능한 dataloader로 변환
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True)
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False)딥러닝 모델에 입력가능한 데이터로더 자료형을 생성한다.
# 데이터로더 정보를 출력하는 함수
def print_dataloader_info(dataloader, loader_name):
print(f"\n{loader_name} 정보:")
for batch_idx, (images, labels) in enumerate(dataloader):
print(f"배치 인덱스: {batch_idx}")
print(f"이미지 크기: {images.size()}")
if isinstance(labels, torch.Tensor):
print(f"라벨 크기: {labels.size()}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
print(f'라벨의 데이터타입 : {labels[0].dtype}')
else:
print(f"라벨 크기: {len(labels)}")
print(f"첫 번째 이미지의 라벨: {labels[0]}")
print(f'라벨의 데이터타입 : {type(labels[0])}')
if batch_idx == 0: # 첫 번째 배치 정보만 출력
break
# train_loader 정보 출력
print_dataloader_info(train_loader, "Train Loader")
# test_loader 정보 출력
print_dataloader_info(test_loader, "Test Loader")업데이트한 데이터 자료형 확인 코드를 통해 데이터로더의 정보를 확인한다면
Train Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 224, 224])
라벨 크기: torch.Size([128])
첫 번째 이미지의 라벨: 8
라벨의 데이터타입 : torch.int64
Test Loader 정보:
배치 인덱스: 0
이미지 크기: torch.Size([128, 3, 224, 224])
라벨 크기: torch.Size([128])
첫 번째 이미지의 라벨: 5
라벨의 데이터타입 : torch.int64훌륭하게 데이터로더 자료형이 잘 생성된 것을 확인할 수 있다.
4. 하이퍼 파라미터 설정
하이퍼 파라미터 설정 전 ResNet-101을 객체화 하고 이를 GPU에서 학습/검증을 수행하기 위해 모델을 GPU로 넘기는 작업을 먼저 수행하자, 그리고 넘기기 전 STL10의 라벨 개수가 10개이니 이를 인자값으로 재대로 넘겨준다.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = ResNet([3, 4, 23, 3], num_classes=10)
model.to(device) #모델을 GPU로
summary(model, input_size=(3, 224, 224), device=device.type)4.1 논문의 하이퍼 파라미터
ResNet의 발표당시 논문의 하이퍼 파라미터는 아래와 같다.
# 하이퍼파라미터 설정
learning_rate = 0.1
momentum = 0.9
weight_decay = 0.0001
# 옵티마이저 설정
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum, weight_decay=weight_decay)
# 학습률 스케줄러 설정
scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[30, 60, 90], gamma=0.1)4.2 실습 설정
from torch import optim
#LossFn, Optimizer, scheduler 정의
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=75)5. 훈련/검증/실행
훈련 / 검증 / 실행의 코드는 이전 포스팅에서도 반복하여 기재했지만
역시 다시 반복하여 기재한다.
나는 시리즈로 포스팅을 하지만 독자들은 필요한 정보만 취합하기에 스크롤 압박이 있더라도 완성된 코드를 전부 포스팅하는게 옳은 것 같다.
(경험담이다...)
from tqdm import tqdm #훈련 진행상황 체크
#tqdm 시각화 도구 출력 사이즈 조절 변수
epoch_step = 5def model_train(model, data_loader,
loss_fn, optimizer_fn, scheduler_fn,
processing_device, epoch):
model.train() # 모델을 훈련 모드로 설정
global epoch_step
# loss와 accuracy를 계산하기 위한 임시 변수를 생성
run_size, run_loss, correct = 0, 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar:
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 전사 과정 수행
output = model(image)
loss = loss_fn(output, label)
#backward과정 수행
optimizer_fn.zero_grad()
loss.backward()
optimizer_fn.step()
# 스케줄러 업데이트
scheduler_fn.step()
#argmax = 주어진 차원에서 가장 큰 값을 가지는 요소의 인덱스를 반환
pred = output.argmax(dim=1) #예측값의 idx출력
correct += pred.eq(label).sum().item()
#현재까지 수행한 loss값을 얻어냄
run_loss += loss.item() * image.size(0)
run_size += image.size(0)
#tqdm bar에 추가 정보 기입
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar.set_description('[Training] loss: ' +
f'{run_loss / run_size:.4f}, accuracy: ' +
f'{correct / run_size:.4f}')
avg_accuracy = correct / len(data_loader.dataset)
avg_loss = run_loss / len(data_loader.dataset)
return avg_loss, avg_accuracydef model_evaluate(model, data_loader, loss_fn,
processing_device, epoch):
model.eval() # 모델을 평가 모드로 전환 -> dropout 기능이 꺼진다
# batchnormalizetion 기능이 꺼진다.
global epoch_step
# gradient 업데이트를 방지해주자
with torch.no_grad():
# 여기서도 loss, accuracy 계산을 위한 임시 변수 선언
run_loss, correct = 0, 0
# 특정 에폭일 때만 tqdm 진행상황 바 생성
if (epoch + 1) % epoch_step == 0 or epoch == 0:
progress_bar = tqdm(data_loader)
else:
progress_bar = data_loader
for image, label in progress_bar: # 이때 사용되는 데이터는 평가용 데이터
# 입력된 데이터를 먼저 GPU로 이전하기
image = image.to(processing_device)
label = label.to(processing_device)
# 평가 결과를 도출하자
output = model(image)
pred = output.argmax(dim=1) #예측값의 idx출력
# 모델의 평가 결과 도출 부분
# 배치의 실제 크기에 맞추어 정확도와 손실을 계산
correct += torch.sum(pred.eq(label)).item()
run_loss += loss_fn(output, label).item() * image.size(0)
accuracy = correct / len(data_loader.dataset)
loss = run_loss / len(data_loader.dataset)
return loss, accuracy훈련/검증에 대한 함수 설계를 완료했으니 실행코드를 수행하자
# 학습과 검증 손실 및 정확도를 저장할 리스트
his_loss, his_accuracy = [], []
num_epoch = 50
for epoch in range(num_epoch):
# 훈련 손실과 정확도를 반환 받습니다.
train_loss, train_acc = model_train(model, train_loader,
criterion, optimizer, scheduler,
device, epoch)
# 검증 손실과 검증 정확도를 반환 받습니다.
test_loss, test_acc = model_evaluate(model, test_loader,
criterion, device, epoch)
# 손실과 정확도를 리스트에 저장
his_loss.append((train_loss, test_loss))
his_accuracy.append((train_acc, test_acc))
#epoch가 특정 배수일 때만 출력하기
if (epoch + 1) % epoch_step == 0 or epoch == 0:
print(f"epoch {epoch+1:03d}, Training loss: " +
f"{train_loss:.4f}, Training accuracy: {train_acc:.4f}")
print(f"Test loss: {test_loss:.4f}, Test accuracy: {test_acc:.4f}")훈련/검증은 시간관계상 50epoch만 수행했다.
import matplotlib.pyplot as plt
# 손실 그래프
train_losses, val_losses = zip(*his_loss)
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_losses, label='train')
plt.plot(val_losses, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Loss')
plt.legend()
plt.title('Train-Val Loss')
# 정확도 그래프
train_accuracies, val_accuracies = zip(*his_accuracy)
plt.subplot(1, 2, 2)
plt.plot(train_accuracies, label='train')
plt.plot(val_accuracies, label='val')
plt.xlabel('Training Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.title('Train-Val Accuracy')
plt.tight_layout()
plt.show()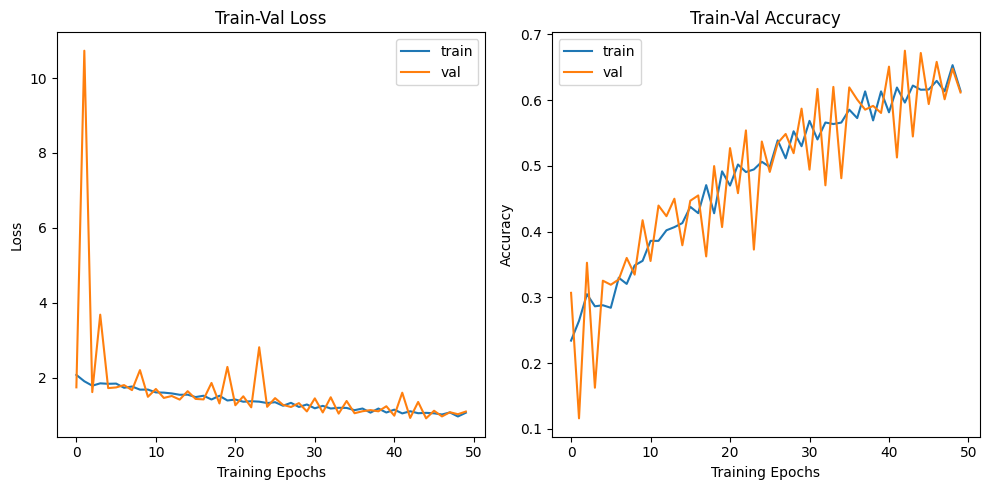
 오늘도 만족스럽게
오늘도 만족스럽게 ResNet + 커스텀 데이터셋을 깨버렷다.
